
银行分控模型的建立
- cm_polt函数
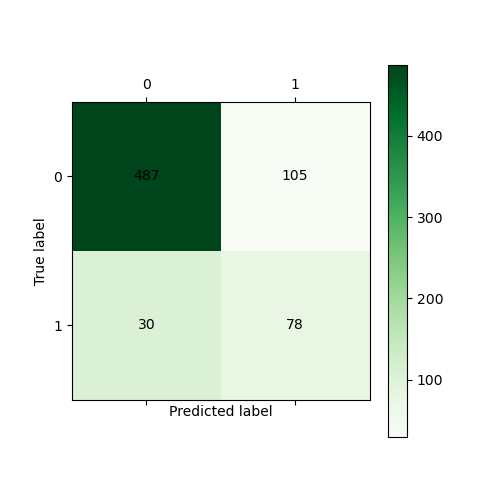
1 # -*- coding: utf-8 -*- 2 3 def cm_plot(y, yp): 4 from sklearn.metrics import confusion_matrix # 导入混淆矩阵函数 5 6 cm = confusion_matrix(y, yp) # 混淆矩阵 7 8 import matplotlib.pyplot as plt # 导入作图库 9 plt.matshow(cm, cmap=plt.cm.Greens) # 画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。 10 plt.colorbar() # 颜色标签 11 12 for x in range(len(cm)): # 数据标签 13 for y in range(len(cm)): 14 plt.annotate(cm[x, y], xy=(x, y), horizontalalignment='center', verticalalignment='center') 15 16 plt.ylabel('True label') # 坐标轴标签 17 plt.xlabel('Predicted label') # 坐标轴标签 18 return plt
- ANNS算法实现
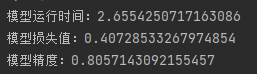
1 # -*- coding: utf-8 -*- 2 3 import pandas as pd 4 import numpy as np 5 #导入划分数据集函数 6 from sklearn.linear_model import LogisticRegression as LR 7 from sklearn.model_selection import train_test_split 8 #读取数据 9 datafile = '../data/bankloan.xls'#文件路径 10 data = pd.read_excel(datafile) 11 x = data.iloc[:,:8] 12 y = data.iloc[:,8] 13 #划分数据集 14 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=100) 15 #导入模型和函数 16 from tensorflow.keras.models import Sequential 17 from tensorflow.keras.layers import Dense,Dropout 18 #导入指标 19 from tensorflow.keras.metrics import BinaryAccuracy 20 #导入时间库计时 21 import time 22 start_time = time.time() 23 #-------------------------------------------------------# 24 model = Sequential() 25 model.add(Dense(input_dim=8,units=800,activation='relu'))#激活函数relu 26 model.add(Dropout(0.5))#防止过拟合的掉落函数 27 model.add(Dense(input_dim=800,units=400,activation='relu')) 28 model.add(Dropout(0.5)) 29 model.add(Dense(input_dim=400,units=1,activation='sigmoid')) 30 31 model.compile(loss='binary_crossentropy', optimizer='adam',metrics=[BinaryAccuracy()]) 32 model.fit(x_train,y_train,epochs=100,batch_size=128) #调参 epochs:训练次数,此处为100次 33 loss,binary_accuracy = model.evaluate(x,y,batch_size=128) 34 #--------------------------------------------------------# 35 end_time = time.time() 36 run_time = end_time-start_time#运行时间 37 38 print('模型运行时间:{}'.format(run_time)) 39 print('模型损失值:{}'.format(loss)) 40 print('模型精度:{}'.format(binary_accuracy)) 41 42 yp = model.predict(x).reshape(len(y)) 43 yp = np.around(yp,0).astype(int) #转换为整型 44 from cm_plot import * # 导入自行编写的混淆矩阵可视化函数 45 46 cm_plot(y,yp).show() # 显示混淆矩阵可视化结果
运行结果
![]()
![]()
- SVM算法实现
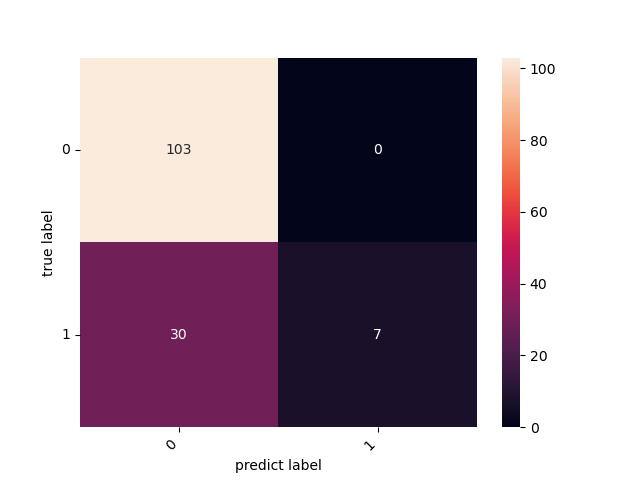
1 # -*- coding: utf-8 -*- 2 3 from sklearn import svm 4 from sklearn.metrics import accuracy_score 5 from sklearn.metrics import confusion_matrix 6 from matplotlib import pyplot as plt 7 import seaborn as sns 8 import pandas as pd 9 import numpy as np 10 from sklearn.model_selection import train_test_split 11 data_load = "../data/bankloan.xls" 12 data = pd.read_excel(data_load) 13 data.describe() 14 data.columns 15 data.index 16 ## 转为np 数据切割 17 X = np.array(data.iloc[:,0:-1]) 18 y = np.array(data.iloc[:,-1]) 19 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1, train_size=0.8, test_size=0.2, shuffle=True) 20 svm = svm.SVC() 21 svm.fit(X_test,y_test) 22 y_pred = svm.predict(X_test) 23 accuracy_score(y_test, y_pred) 24 print(accuracy_score(y_test, y_pred)) 25 cm = confusion_matrix(y_test, y_pred) 26 heatmap = sns.heatmap(cm, annot=True, fmt='d') 27 heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right') 28 heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right') 29 plt.ylabel("true label") 30 plt.xlabel("predict label") 31 plt.show()
运行结果
![]()
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号