oracle学习笔记
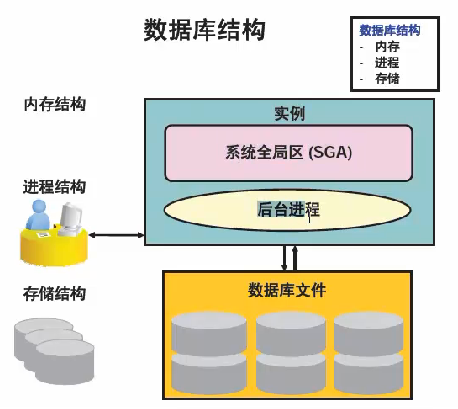
ORACLE实例 = 进程 + 进程所使用的内存(SGA),是一个临时性的东西,你也可以认为它代表了数据库某一时刻的状态! 数据库 = 重做文件 + 控制文件 + 数据文件 + 临时文件。数据库是永久的,是文件的集合。
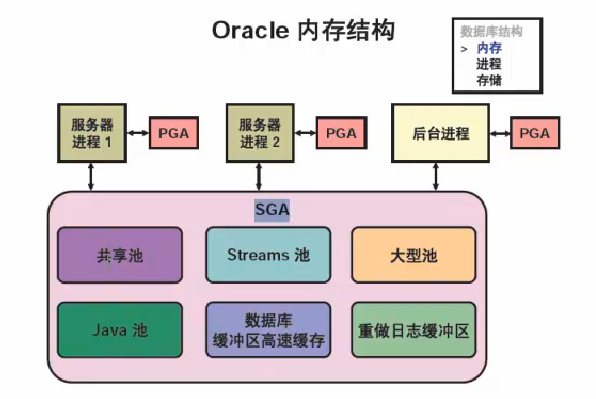
Oracle内存结构
与oracle实例关联的基本内存结构包括
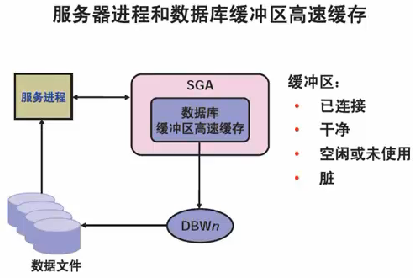
系统全局区SGA:由多有服务器进程和后台进程共享(包含实例的数据和控制信息)
程序全局区PGA:专用于每一个服务器进程或后台进程,每一个进程使用一个PGA
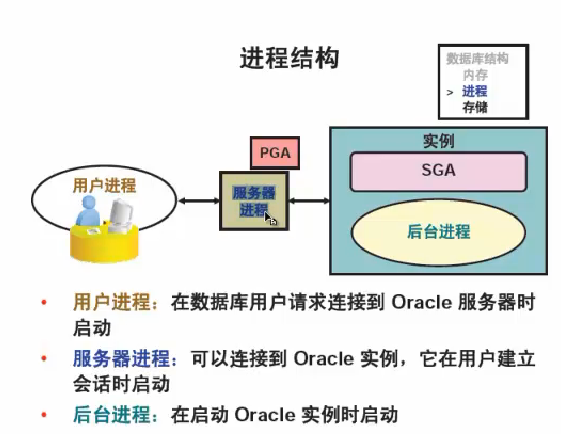
用户进程: 在数据库用户请求连接到oracle服务器时启动
服务器进程: 可以连接到oracle实例,它在用户建立会话时启动 (oracleecology (DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq))))
后台进程: 在启动oracle实例时启动 (一堆进程)
 |
 |
 |
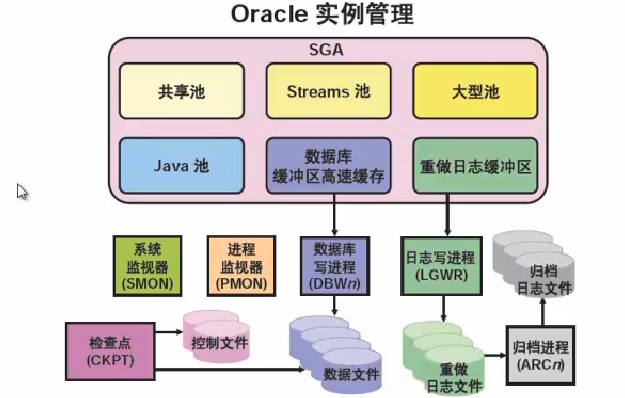 |
| 系统监视器SMON---- 出现故障后,在启动实例时执行崩溃恢复任务。SGA内部清理整合 进程监视器PMON---- 用户进程失败时执行进程清理任务。server process 维护 |
|
| shared pool主要有三块区域 free cache 存放空闲信息 (硬解析时发生,会产生小内存碎片,或不能使用,导致4031错误) select * from v$sgastat a where a.pool='shared pool' and a.NAME='free memory'; library cache 存放sql语句及sql语句对应的执行计划 select * from v$sgastat a where a.NAME='library cache'; row chche 存放数据字典信息 select * from v$sgastat a where a.NAME='row cache'; |
|
buffer cache 缓存dbf数据 (修改也先读到内存) |
|
|
检查点进程CKPT |
|
|
 |
SQL语句的执行过程
当发布一条SQL或PL/SQL命令时,Oracle会自动寻找该命令是否存在于共享池中来决定对当前的语句使用硬解析或软解析。
通常情况下,SQL语句的执行过程如下:
a.SQL代码的语法(语法的正确性)及语义检查(对象的存在性与权限)。
b.将SQL代码的文本进行哈希得到哈希值。
c.如果共享池中存在相同的哈希值,则对这个命令进一步判断是否进行软解析,否则到e步骤。
d.对于存在相同哈希值的新命令行,其文本将与已存在的命令行的文本逐个进行比较。这些比较包括大小写,字符串是否一致,空格,注释等,如果一致,则对其进行软解析,转到步骤f。否则到d步骤。 e.硬解析,生成执行计划。
f.执行SQL代码,返回结果。 (如果是增删改, LGWR写日志,DBW将修改的数据写回磁盘)
SQL> select count(*) from x$ksmsp; shared pool里chunk数
COUNT(*)
----------
27814
SQL> select count(*) from dba_indexes; 发生硬解析
COUNT(*)
----------
4790
SQL> select count(*) from x$ksmsp; shared pool里chunk数增加
COUNT(*)
----------
27879
查看软硬解析具体情况
SQL> select name,value from v$sysstat where name like 'parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4377
parse time elapsed 5683
parse count (total) 127961
parse count (hard) 73673
parse count (failures) 281
parse count (describe) 64
SQL> alter system flush shared_pool; 无法根本解决硬解析导致的4031错误 (共享sql解决)
通过共享sql/绑定变量解减少硬解析
SQL> select /*hello*/ count(*) from t1 where OBJECT_ID=1; SQL> select /*hello*/ count(*) from t1 where OBJECT_ID=2; SQL> select /*hello*/ count(*) from t1 where OBJECT_ID=1; SQL> select sql_id,sql_text,executions from v$sql where sql_text like '%hello%'; 4zj8791gxaafp select /*hello*/ count(*) from t1 where OBJECT_ID=1; gwunm630jqjrr select /*hello*/ count(*) from t1 where OBJECT_ID=2; dkxtdpmw5ztxm select /*hello*/ count(*) from t1 where OBJECT_ID=1; ==>sql ID都不相同
共享SQL----需要完全一抹一样
绑定变量
declare v_sql varchar2(50);
begin for i in 1..10000 loop
v_sql :='insert /*hello*/' into test values (:1)';
execute immediate v_sql using i;
end loop;
commit;
end;
找出不能共享cursor的sql
SQL> show parameter cursor; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ cursor_sharing string EXACT cursor_space_for_time boolean FALSE open_cursors integer 300 session_cached_cursors integer 50
在v$sql查找执行次数较小的sql语句,观察这些sql语句是否经常被执行
select SQL_FULLTEXT from v$sql where EXECUTIONS=1 and sql_text like '%from t%';
select SQL_FULLTEXT from v$sql where EXECUTIONS=1 order by sql_text;
命中率
SQL> select sum(pinhits)/sum(pins)*100 from v$librarycache;
增加shared pool空间 SQL> select component,current_size from v$sga_dynamic_components; COMPONENT CURRENT_SIZE ---------------------------------------------------------------- ------------ shared pool 155189248 large pool 4194304 java pool 4194304 streams pool 0 DEFAULT buffer cache 222298112 KEEP buffer cache 0 RECYCLE buffer cache 0 DEFAULT 2K buffer cache 0 DEFAULT 4K buffer cache 0 DEFAULT 8K buffer cache 0 DEFAULT 16K buffer cache 0 COMPONENT CURRENT_SIZE ---------------------------------------------------------------- ------------ DEFAULT 32K buffer cache 0 Shared IO Pool 0 ASM Buffer Cache 0 SQL> show parameter sga_target; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sga_target big integer 0 SQL> show parameter sga_max_size; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sga_max_size big integer 600M SQL> alter system set shared_pool_size=150M scope=both; System altered. SQL> select component,current_size from v$sga_dynamic_components; COMPONENT CURRENT_SIZE ---------------------------------------------------------------- ------------ shared pool 188743680
oracle管理工具(windows) 1)在开始->程序->oracle orachome90->application development->sql*plus 2)在运行栏中输入: sqlplusw即可 3)在开始->程序->oracle orahome90->applicaiton development->sql*plus worksheet 4)pl/sql developer
oracle默认有2个用户sys和system,sys比system的权限大
sys默认口令: change_on_install
system默认口令: manager
解锁scott
SQL>alter user scott account unlock;
SQL>alter user scott identified by tiger;
$ sqlplus sys/rootabcd as sysdba (当用特权用户连接时,必须带as sysdba或as sysoper)
SQL> show user;
USER is "SYS"
[oracle@nodedata ~]$ sqlplus /nolog 只登陆SQL
SQL*Plus: Release 11.2.0.1.0 Production on Sat Sep 2 01:21:45 2017
Copyright (c) 1982, 2009, Oracle. All rights reserved.
SQL> conn / as sysdba
Connected.
SQL> show user
USER is "SYS"
conn命令
conn username/password@netservice [特权用户带上as sysdba或as sysoper]
SQL>password 修改密码 (修改其他密码需要sys或sysdba)
文件操作命令
start和@
sql>@ d:\a.sql 或 sql>start d:\a.sql
sql>edit d:\a.sql
spool的用法
SQL> spool /tmp/a.txt SQL> show user USER is "SYS" SQL> spool off
[oracle@data1 ~]$ cat /tmp/a.txt
SQL> show user
USER is "ECOLOGY"
SQL> spool off
SQL> show linesize 行宽度 linesize 80 SQL> show pagesize pagesize 14 SQL> set linesize 90 每页显示的行数
用户创建与删除 create user uname identified by password; 新创建的用户无任何权限,包括登陆数据库权限,密码以数字开头 drop user uname #(如果用户已经创建了表,那么需要加cascade,表一并删除) 更改口令 方法一、password username
方法二、alter user uname identified by newpass
权限授予与回收
grant SQL>grant connect to username; connect是个角色(其他常用角色:dba角色、resource角色)
revoke
角色
预定义角色
自定义角色
权限
系统权限:用户对数据库的相关权限,建库、建表、索引、登陆数据库、修改密码等
对象权限:用户对其他用户的数据对象访问操作的权限。数据对象指表、索引、存储过程、函数、触发器等(select、insert、update、delete、create index==all)
SQL>conn scott/password
SQL>grant select on emp to userame;(with grant option 可以权限传递,如果是系统权限 with admin option)
SQL>conn username/password
SQL>select * from scott.emp (方案),表以用户为单位,所以可以有同名表
使用profile管理用户口令
profile是口令限制,资源限制的命令集合,当建立数据库时,oracle会自动建立名称为default的profile。当建立用户没有指定profile选项,那oracle就会将default分配给用户
账户锁定
a、最多3次尝试,锁定时间2天,自定义名称为lock_account的profile
sql>create profile lock_account limit failed_login_attempts 3 password_lock_time 2;
sql>alter user username profile lock_account; 解锁:sql>alter user username account unlock;
b、每隔30天修改密码,宽限期2天
sql>create profile myprofile limit password_life_time 30 password_grace_time 2
sql>alter user username profile myprofile;
口令历史:用户修改密码时,oracle将新密码与旧密码比对,相同时提示重新输入
建立profile
sql>create profile password_history limit password_life_time 30 password_grace_time 2 password_refuse_time 10 (10天后可以重用)
sql>alter user username profile password_history;
删除profile
sql>drop profile password_history cascade
oracle表管理 表命名 必须以字母开头 长度不能超过30字符 不能使用oracle保留字 只能使用如下字符 A-Z,a-z,0-9,$,#
oracle支持的数据类型
字符型
char
varchar2
clob
数字类型
number number(5,2) 5位有效位,2位小数
number(5) -99999~999999
日期类型
date
timestamp
图片
blob 二进制、图片、声音、4G
添加一个字段: alter table student add (classID number(2));
修改字段长度: alter table student modify (xm varchar2(30));
修改数据类型或名字(不能有数据):alter table student modify (xm char(30));
删除一个字段: alter table student drop column sal;
修改表名: rename student to stu;
删除表: drop table studnet;
insert
insert into students values ('','','01-5月-05','') 默认日期输入格式
#oracle中默认的日期格式为‘DD-MM-YY’
所以可以修改为
alter session set nls_date_format='yyyy-mm-dd'
insert into students values ('','','2005-05-01','')
insert into students (a,b,c)values ('','','');
空值为null 查询条件 is null能查出上句的情况
update
update student set sal=sal/2,classid=3 where sex='男'
delete
删除数据
delete from table_name 删除所有记录,速度慢,写日志,可恢复
savepoint a; 操作前可以先设置保存点
......
rollback to a;
truncate table student 删除所有记录,速度快,不写日志,无法恢复
drop table tablename 删除表
set timing on; 打开查询操作时间
表查询
查看表结构 SQL> desc dept;
显示记录数 SQL> select count(*) from emp;
去除重复行 SQL> select distinct deptno,job from emp;
查询年工资
SQL> select sal*12 "年工资",ename from emp; 别名
SQL> select sal*12+comm*12 "年工资",ename from emp; oracle表达式中有空值,整个值为空
SQL> select sal*12+nvl(comm,0)*12 "年工资",ename from emp; nvl函数作用: 如果是空值就用0替代
年工资 ENAME
---------- --------------------
SMITH
22800 ALLEN
21000 WARD
JONES
31800 MARTIN
................
如何处理null
SQL> select * from emp where HIREDATE>'01-MAY-86'; 后
SQL> select ename,sal from emp where sal>=2000 and sal<3000;
like
% 任意0个到多个字符
_ 任意单个字符
SQL> select * from emp where ename like 'S%';
SQL> select * from emp where ename like '__O%';
in
SQL> select * from emp where deptno in (20,30,40);
null
SQL> select * from emp where mgr is null;
SQL> select * from emp where (sal>500 or job='MANAGER') and ename like 'J%';
SQL> select * from emp order by sal asc; (desc)
部门号升序,员工收入降序
SQL> select * from emp order by DEPTNO asc,sal desc;
SQL> select ename,sal*12 as "年薪" from emp order by "年薪";
max/min/avg/sum/count
SQL> select max(sal) as "最高工资",min(sal) from emp;
SQL> select ename,sal from emp where sal=(select max(sal) from emp);
group by/having (分组的字段一定要出现在select)
SQL> select max(sal),max(sal),avg(sal),deptno from emp group by deptno;
SQL> select max(sal),min(sal),avg(sal),deptno,job from emp group by deptno,job; 每个部门每种岗位的
SQL> select avg(sal),max(sal),deptno from emp group by deptno having avg(sal)>2000; 平均工资高于2000的部门
对数据分组的总结
1、分组函数只能出现在选择列表、having、order by子句种
2 、如果在select 语句种同时包含有group by ,having ,order by 那么他们的顺序是group by , having , order by
3 在选择列种如果有列、表达式、和分组函数,那么这些列和表达式必须有一个出现在group by 子句中,否则就会出错
如select deptno,avg(sal),max(sal) from emp group by deptno having avg(sal)<2000; 这里deptno就一定要出现在 group by 中
多表查询 条件不能小于表的个数减1,否则出现笛卡尔积
SQL> select a1.ename,a1.sal,a2.dname from emp a1,dept a2 where a1.deptno=a2.deptno;
SQL> select a1.dname,a2.ename,a2.sal from dept a1,emp a2 where a1.deptno=a2.deptno and a1.deptno=10;
显示各个员工的姓名、工资、及其工资的级别
SQL> select a1.ename,a1.sal,a2.grade from emp a1,salgrade a2 where a1.sal between a2.losal and a2.hisal;
显示员工姓名、工资、及所在部门名称,并按照部门排序
SQL> select a1.ename,a2.dname,a1.sal from emp a1,dept a2 where a1.deptno=a2.deptno order by a1.deptno;
自连接
SQL> select worker.ename,boss.ename from emp worker,emp boss where worker.mgr=boss.empno;
子查询
和SMITH同部门的员工
SQL> select * from emp where deptno=(select deptno from emp where ename='SMITH');
查询和部门10的工作相同的雇员的名字、岗位、工资、部门号
SQL> select * from emp where job in (select distinct job from emp where deptno=10);
显示工资比部门30的所有员工工资高的员工的姓名、工资、部门号
SQL> select ename,sal,deptno from emp where sal>(select max(sal) from emp where deptno=30);
SQL> select ename,sal,deptno from emp where sal> all (select sal from emp where deptno=30);
SQL> select ename,sal,deptno from emp where sal> any (select sal from emp where deptno=30); 只要比其中一个高的都显示
==SQL> select ename,sal,deptno from emp where sal>(select min(sal) from emp where deptno=30);
显示与smith的部门和岗位完全相同的所有雇员
SQL> select * from emp where (deptno,job)=(select deptno,job from emp where ename='SMITH');
显示高于部门平均工资的员工
SQL> select a2.ename,a2.sal,a2.deptno,a1.mysal from emp a2, (select deptno,avg(sal) mysal from emp group by deptno) a1 where
a2.deptno=a1.deptno and a2.sal>a1.mysal;
==>在from子句中使用子查询
该子查询会被作为一个视图来对待,因此脚内嵌视图,当在from中使用子查询时,必须给予子查询指定别名。
表别名不加as,列别名加as
oracle分页
1、rownum
SQL> select a1.*,rownum rn from (select * from emp) a1 where rownum<=10; 不能加and,between,再截需要再做一次.rownum是oracle分配的
SQL> select * from (select a1.*,rownum rn from (select * from emp) a1 where rownum<=10) where rn >=6;
SQL> select * from (select a1.*,rownum rn from (select ename,sal from emp) a1 where rownum<=10) where rn >=6;
SQL> select * from (select a1.*,rownum rn from (select ename,sal from emp order by sal) a1 where rownum<=10) where rn >=6;
==>a、指定列,只需修改最里层的子查询
b、如何排序,只需修改最里层的子查询
用查询结果创建新表
SQL> create table mytable (id,name,sal,job,deptno) as select empno,ename,sal,job,deptno from emp;
合并查询
为了合并多个select语句的结果,可以使用union,union all(不取消重复),intersect(交集),minus(差集)
union
该操作符用于取得两个结果集的并集,会自动去掉结果集中的重复行
SQL> select ename,sal,job from emp where sal>2500 union select ename,sal,job from emp where job='MANAGER';
ENAME SAL JOB
-------------------- ---------- ------------------
BLAKE 2850 MANAGER
CLARK 2450 MANAGER
FORD 3000 ANALYST
JONES 2975 MANAGER
KING 5000 PRESIDENT
SCOTT 3000 ANALYST
创建数据库的方法
dbca
手工命令
to_datey
使用此函数插入带有日期的表 to_date('1988-01-01','yyyy-mm-dd')
用子查询插入数据
SQL> create table test2 (myid number(4),myname varchar2(50),mydept number(5)); SQL> insert into test2 (myid,myname,mydept) select empno,ename,deptno from emp where deptno=20;
用子查询更新数据
SQL> update emp set (JOB,SAL,COMM)=(select JOB,SAL,COMM from emp where ENAME='SMITH') where ename='SCOTT';
事务
保存点是事务中的一点,用于取消部分事务,当结束事务时,会自动的删除该事务所定义的所有保存点,当执行rollback时,通过指定保存点可以回退到指定的点
commit提交事务,会确认事务的变化,结束事务,删除保存点,释放锁,当使用commit语句结束事务之后,其他会话将可以查看到事务变化后的新数据
提交事务
当执使用commit语句可以提交事务.当执行了commit语句后,会确认事务的变化、结束事务、删除保存点、释放锁,
当使用commit语句结束事务子后,其它会话将可以查看到事务变化后的新数据
SQL> commit;
SQL> savepoint a1;
SQL> delete from emp where empno=7369;
SQL> savepoint a2;
SQL> delete from emp where empno=7499;
SQL> rollback to a2;
SQL> rollback to a1;
exit后也会自动提交
rollback 取消全部事务
只读事务
是指只允许执行查询的操作,而不允许执行任何其他dml操作的事务,使用制度事务可以确保用户只能取得某一时刻的数据,假定机票代售点每天18点开始统计今天的销售情况
这时可以使用只读事务,之后尽管其他会话可能会提交新的事务,但是只读事务将不会取得最新数据的变化,从而可以保证取得特定时间点的数据信息
设置只读事务
set transaction read only
字符函数 lower(char) SQL> select lower(ename),job from emp; upper(char) length(char) SQL> select * from emp where length(ename)=4; substr(char,m,n) 第m位开始,取n个
SQL> select upper(substr(ename,1,1)) from emp;
SQL>select lower(substr(ename,2,length(ename)-1)) from emp;
===>SQL> select upper(substr(ename,1,1)) || lower(substr(ename,2,length(ename)-1)) from emp;
替换
SQL> select replace (ename,'A','hello') from emp;
数学函数介绍
数学函数的输入参数和返回值的数据类型都是数字类型的.数学函数包括cos,cosh,exp,ln,log,sin,sinh,sqrt,
tan, tanh,acos,asin,atan,round,我们讲最常用的 :
round(n,[m]) 该函数用于执行四舍五入,如果省掉m,则四舍五入到整数;如果m是正数,则四舍五入到小数点的m位后.如果m是负数,则四舍五入到小数点的m位前
trunc(n,[m]) 该函数用于截取数字.如果省掉m,就截去小数部分,如果m是正数就截取到小数点的m位后,如果m是负数,则截取到小数点的前m位
mod(m,n)
floor(n) 返回小于或是等于n的最大整数 55.5->55
ceil(n) 返回大于或是等于n的最小整数 55.5->56
对数字的处理,在财务系统或银行系统中用的最多,不同的处理方法,对财务报表有不同的结果。
其它的数学函数
abs(n) 返回数字n的绝对值
select abs(-13) from dual;
acos(n) :返回数字的反余旋值
asin(n): 返回数字的反正旋值
atan(n): 返回数字的反正切
cos(n)
exp(n): 返回e的n次幂
log(m,n)返回对数值
power(m,n):返回m的n次幂
oracle管理员的职责
主要职责
1、安装和升级
2、建库、表、表空间、视图、索引等
3、制定并实施备份与恢复计划
4、数据库权限管理、调优、故障排除
5、对于高级dba、要求能参与项目开发,会编写sql语句、存储过程、触发器、规则、约束、包
sys && system
sys
所有oracle的数据字典的基表和视图都存放在sys用户中,对于oracle的运行是至关重要的,由数据库自己维护,任何用户都不能手动更改
sys用户拥有dba、sysdba、sysoper角色或权限、是oracle权限最高的用户
system
用于存放次一级的内部数据,如oracle的一些特性或工具的管理信息,system用户拥有dba、sysdba角色或系统权限,没有sysoper权限
其次的区别:权限的不同
sys用户必须以as sysdba或as sysoper形式登陆,不能以normal方式登录数据库
system如果正常登陆,其实就是一个普通的dba用户,但是如果以as sysdba登陆,其结果实际上是作为sys用户登陆,从登陆信息可以看出来
| sysdba | sysoper |
| startup | startup |
| shutdown | shutdown |
| alter database open/mount/backup | alter database open/mount/backup |
| 改变字符集 | 不能 |
| create database(创建数据库) | 不能 |
| drop database(删除数据库) | 不能 |
| create spfile | create spfile |
| alter database archivelog(归档日志) | alter database archivelog(归档日志) |
| alter database recover(恢复数据库) | 只能完全恢复,不能执行不完全恢复 |
| 拥有restricted session(会话限制)权限 | 拥有restricted session(会话限制)权限 |
| 可以让用户作为sys用户连接 | 可以进行一些基本的操作,但不能查看用户数据 |
| 登录之后用户是sys | 登录之后用户是public |
sysdba>sysoper>dba
dba权限的用户
是指具有dba角色的数据库用户,特权用户可以执行启动实例,关闭实例等特殊操作,而dba用户只有在启动数据库后才能执行各种管理工作
oracle初始化参数
用于设置实例或是数据库的特征,提供了200多个初始化参数,并且每个初始化参数都有默认值
SQL> show parameter;
文件:/u01/app/oracle/admin/ecology/pfile
数据库(表)的逻辑备份与恢复导出表
逻辑备份是指利用工具export将数据对象的结构和数据导出到文件的过程,逻辑恢复是指当数据库对象被误操作或其他原因损坏后使用import工具将备份的文件进行导入数据库的过程
物理备份可以在数据库open的状态下进行,也可以在close的状态下
逻辑备份的备份与还原只能在open的状态下进行
导出
三种模式:
a.用户模式: 导出用户所有对象以及对象中的数据;(方案)
b.表模式: 导出用户所有表或者指定的表;
c.整个数据库: 导出数据库中所有对象。
userid 用于指定执行导出操作的用户名、口令、连接字符串
tables 用于指定执行导出操作的表
owner 用于指定执行导出操作的方案
full=y 用于指定执行导出操作的数据库
inctype 用于指定执行导出操作的增量类型
rows 用于指定执行导出操作是否要导出表中的数据
file 用于指定导出的文件名
(1)导出自己的表
exp userid=scott/tiger@myora1 tables=(emp) file=d:\e1.dmp #linux下不用小括号
(2)导出其它方案的表,如果用户要导出其它方案的表,则需要dba的权限或是exp_full_database的权限, 比如system就可以导出scott的表
exp userid=system/manager@myora1 tables=(scott.emp) file=d:\e2.dmp
(3)导出表的结构
exp userid=scott/tiger@accp tables=(emp) file=d:\e3.dmp rows=n
(4)使用直接导出方式
exp userid=scott/tiger@accp tables=(emp) file=d:\e3.dmp direct=y
这种方式比默认的常规方式速度要快,当数据量大时,可以考虑使用这样的方法这时需要数据库的字符集要与客户端字符集完全一致,否则会报错...
导出方案
导出方案是指使用export 工具导出一个方案或是多个方案中的所有对象(表,索引,约束..)和数据.并存放到文件中.
(1)导出自己的方案
exp scott/tiger@myora1 owner=scott file=d:\scott.dmp
(2)导出其它方案 如果用户要导出其它方案,则需要dba的权限或是exp_full_database的权限,例如system用户就可以导出任何方案
exp system/manager@myor owner=(system,scott) file=d:\system.dmp
导出数据库
导出数据库是指利用export导出所有数据库中的对象及数据.,要求该用户具有dba的权限或是exp_full_database权限
exp userid=system/manager@myor full=y inctype=complete file=x.dmp
介绍
导入就是使用工具import 将文件中的对象和数据导入到数据库中,但是导入要使用的文件必须是export所导出的文件.与导出相似,导入也分为导入表,导入方案,导入数据库三中方式.
imp常用的选项:
userid: 用于指定执行导入操作的用户名,口令,连接字符串
tables: 用于指定执行导入操作的表
formuser: 用于指定源用户
touser: 用于指定目标用户
file: 用于指定导入文件名
full=y: 用于指定执行导入整个文件
inctype: 用于指定执行导入操作的增量类型
rows: 指定是否要导入表行(数据)
ignore: 如果表存在,则只导入数据
导入表
(1)导入自己表
imp userid=scott/tiger@myor tables=(emp) file=d:\xx.dmp
(2)导入表到其它用户要求该用户具有dba的权限,或是imp_full_database
imp userid=system/manager@myor tables=(emp) file=d:\xx.dmp touser=scott
(3)导入表的结构只导入表的结构而不导入数据
imp userid=soctt/tiger@myor tables=(emp) file=d:\xxx.dmp rows=n
(4)导入数据,如果对象(如比表)已经存在可以只导入表的数据
imp userid=scott/tiger@myor tables=(emp) file=d:\xxx.dmp ignore=y
导入方案
导入方案是指使用import工具将文件中的对象和数据导入到一个或是多个方案中。如果要导入其它方案,要求该用户具有dba的权限,或是imp_full_database
(1)导入自身的方案
imp userid=scott/tiger file=d:\xxx.dmp
(2)导入其它方案 要求该用户具有dba的权限
imp userid=system/manager file=d:\xxx.dmp fromuser=system touser=scott
导入数据库
在默认情况下,当导入数据库时,会导入所有对象结构和
数据,案例如下:
imp userid=system/manager full=y file=d:\xxx.dmp
数据字典是oracle数据库中最重要的组成部分,它提供了数据库的一些系统信息。
动态性能视图记载了例程启动后的相关信息。
数据字典
数据字典记录了数据库的系统信息,它是只读表和视图的集合,数据字典的所有者为sys用户。
用户只能在数据字典上执行查询操作(select语句),而其维护和修改是由系统自动完成的.
数据字典的组成:
1、数据字典基表 基表存储数据库的基本信息,存放静态数据,普通用户不能直接访问数据字典的基表
2、数据字典视图 数据字典视图是基于数据字典基表所建立的视图,普通用户可以通过查询数据字典视图取得系统信息.数据字典视图主要包括user_xxx , all_xxx, dba_xxx三种类型.
user_tables; 用于显示当前用户所拥有的所有对象,它只返回用户所对应方案的所有对象.
比如: select table_name from user_tables;
all_tables 用于显示当前用户可以访问的所有对象.它不仅会返回当前用户方案的所有对象,还会返回当前用户可以访问的其它方案的对象;
比如: select table_name from all_tables;
dba_tables 它会显示所有方案拥有的数据库对象.但是查询这种数据库字典视图,要求用户必须是dba角色或是有select any table系统权限.
例如: 当用system用户查询数据字典视图dba_tables时,会返回system,sys,scott...方案所对应的数据库对象.
用户名,权限,角色
在建立用户时,oracle会把用户的信息存放到数据字典中,当给用户授予权限或是角色时,oracle会将权限和角色的信息存放到数据字典.
1、通过查询dba_users可以显示所有数据库用户的详细信息;
2、通过查询数据字典视图dba_sys_privs,可以显示用户所具有的系统权限;
3、通过查询数据字典视图dba_tab_privs可以显示用户具有的对象权限;
4、通过查询数据字典dba_col_privs可以显示用户具有的列权限;
5、通过查询数据库字典视图dba_role_privs可以显示用户所具有的角色.
例如:要查看scott具有的角色,可查询dba_role_privs,SQL> select * from dba_role_privs where GRANTEE='SCOTT';
//查询oracle中所有的系统权限,一般是dba
select * from system_privilege_map order by name;
//查询oracle中所有的角色,一般是dba
select * from dba_roles;
//查询oracle中所有对象权限,一般是dba
select distinct privilege from dba_tab_privs;
//查询数据库的表空间
select tablespace_name from dba_tablespaces;
//查询某个用户具有怎样的角色
select * from dba_role_privs where grantee='用户名'
//查看某个角色包括哪些系统权限。
select * from dba_sys_privs where grantee='DBA'
或者是:select * from role_sys_privs where role='DBA';
//查看某个角色包括的对象权限
select * from dba_tab_privs where grantee='角色名'
\\显示当前用户可以访问的所有数据字典视图.
select * from dict where comments like '%grant%';
\\显示当前数据库的全称
select * from global_name;
其它说明
数据字典记录有oracle数据库的所有系统信息.通过查询数据字典可以取得以下系统信息:比如
(1)对象定义情况
(2)对象占用空间大小
(3)列信息
(4)约束信息
…
这些个信息,可以通过pl/sql developer工具查询得到
动态性能视图
用于记录当前例程的活动信息,当启动oracle server时,系统会建立动态性能视图;
当停止oracle server时,系统会删除动态性能视图.oracle的所有动态性能视图都是以v_$开始的,并且oracle为每个动态性能视图都提供了相应的同义词,并且其同义词是以V$开始的,例如v_$datafile的同义词为v$datafile;动态性能视图的所
有者为sys,一般情况下,由dba或是特权用户来查询动态性能视图。
管理表空间个数据文件
表空间是数据库的逻辑组成部分.
从物理上讲,数据库数据存放在数据文件中;
从逻辑上讲,数据库则是存放在表空间中,表空间由一个或是多个数据文件组成
oracle中逻辑结构包括表空间、段、区和块。
数据库<==表空间<==段<==区<==oracle块 可以提高数据库的效率。
表空间用于从逻辑上组织数据库的数据.数据库逻辑上是由一个或是多个表空间组成的。
通过表空间可以达到以下作用:
(1)控制数据库占用的磁盘空间
(2)dba可以将不同数据类型部署到不同的位置,这样有利于提高i/o性能,同时利于备份和恢复等管理操作
建立表空间
建立表空间是使用create tablespace 命令完成的 ,需要注意是,一般情况下,建立表空间是特权用户或是dba来执行的,
如果用其它用户来创建表空间,则用户必须要具有create tablespace 的系统权限.
在建立数据库后,为便于管理表,最好建立自己的表空间
create tablespace data01 datafile 'd:\test\data01.dbf' size 20m uniform size 128k
说明: 执行完上述命令后,会建立名称为data01的表空间,并为该表空间建立名称为data01.dbf的数据文件,区的大小为128k
使用数据表空间
create table mypart(deptno number(4),dname varchar2(14),loc varchar2(13)) tablespace data01;
改变表空间的状态
当建立表空间时,表空间处于联机的(online)状态,此时该表空间是可以访问的,并且该表空间是可以读写的,即可以查询该表空间的数据,而且还可以在表空间执行各种语句。
但是在进行系统维护或是数据维护时,可能需要改变表空间的状态。一般情况下,
由特权用户或是dba来操作.
(1)使表空间脱机
alter tablespace users offline;
(2)使表空间联机
alter tablespace users online;
(3)只读表空间
当建立表空间时,表空间可以读写,如果不希望在该表空间上执行update ,delete,insert操作,那么可以将表空间修改为只读
alter tablespace query_data read only 【read write】
1)知道表空间名,显示该表空间包括的所有表
select * from all_tables where tablespace_name='表空间名'
2)知道表名,查看该表属于那个表空间
select tablespace_name ,table_name from user_tables where table_name='EMP';
scott.emp是在system这个表空间上,现在我们可以将system改为只读的但是我们不会成功,因为system是系统表空间,如果是普通表空间,那么我们就可以将其设为只读
删除表空间
一般情况下,由特权用户或是dba来操作,如果是其它用户操作,那么要求用户具有drop tablespace系统权限.
drop tablespace ‘表空间’ including contents and datafiles;
说明: including contents 表示删除表空间时,删除该空间的所有数据库对象,而datafiles表示将数据库文件也删除.
扩展表空间
表空间是由数据文件组成的,表空间的大小实际上就是数据文件相加后的大小。那么我们可以想象,假定表employee存放data01表空间上,初始大小就是2m,当数据满2m空间后,
如果在向employee表插入数据,这样就会显示空间不足的错误.
案例说明:
1.建立一个表空间 sp01
2.在该表空间上建立一个普通表 mydment 其结构和dept一样
3.向该表中加入数据 insert into mydment select * from dept;
4.当一定时候就会出现无法扩展的问题,怎么办?
5.就扩展该表空间,为其增加更多的存储空间。有三种方法:
扩展表空间
(1)增加数据文件
sql>alter tablespace sp01 add datafile 'd:\test\sp01.dbf' size 20m
(2)增加数据文件的大小
sql>alter tablespace 表空间名 'd:\test\sp01.dbf' resize 50m;
这里需要注意的是数据文件的大小不要超过500m
(3)设置文件的自动增长.
sql>alter tablespace 表空间名、 'd:\test\sp01.dbf' autoextend on next 10m maxsize 500m;
移动数据文件
有时,如果你的数据文件所在的磁盘损坏时,该数据文件将不能再使用,为了能够重新使用,需要将这些文件的副本移动到其它的磁盘,然后恢复.
下面以移动数据文件sp01.dbf为例来说明:
1)确定数据文件所在的表空间
select tablespace_name from dba_data_files where file_name='d:\test\sp01.dbf';
2)使表空间脱机确保数据文件的一致性,将表空间转变为offline的状态.
alter tablespace sp01 offline;
3)使用命令移动数据文件到指定的目标位置
sql>host move d:\test\sp01.dbf c:\test\sp01.dbf
移动数据文件
4)执行alter tablespace 命令
在物理上移动了数据后,还必须执行alter tablespace 命令对数据库文件进行逻辑修改:
sql>alter tablespace sp01 rename datafile 'd:\test\sp01.dbf' to 'c:\test\sp01.db';
5)使的表空间联机
在移动了数据文件后,为了使用户可以访问该表空间,必须将其转变为online状态:
sql>alter tablespace sp01 online;
显示表空间信息,查询数据字典视图dba_tablespaces,显示表空间的信息:
select tablespace_name from dba_tablespaces;
显示表空间所包含的数据文件查询数据字典视图dba_data_files,可显示表空间所包含的数据文件,如下:
select file_name,bytes from dba_data_files where tablespace_name=‘表空间名';
其它表空间
除了最常用的数据表空间外,还有其它类型表空间:
(1)索引表空间
(2)undo表空间
(3)临时表空间
(4)非标准块的表空间
数据的完整性用于确保数据库数据遵从一定的商业和逻辑规则。在oracle中,数据完整性可以使用约束、触发器、应用程序(过程、函数)三种方法来实现,
在这三种方法中,因为约束易于维护,并且具有最好的性能,所以作为维护数据完整性的首选.
约束 约束用于确保数据库数据满足特定的商业规则。在oracle中,约束包括:
not null(非空)
如果在列上定义了not null,那么当插入数据时,必须为列提供数据。
unique(唯一)
当定义了唯一约束后,该列值是不能重复的.但是可以为null。
primary key(主键)
用于唯一的标示表行的数据,当定义主键约束后,该列不但不能重复而且不能为null。
需要说明的是:一张表最多只能有一个主键,但是可以有多个unqiue约束。
foreign key(外键)
用于定义主表和从表之间的关系.外键约束要定义在从表上,主表则必须具有主键约束或是unique约束.,当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为null
check
用于强制行数据必须满足的条件,假定在sal列上定义了check约束,并要求sal列值在1000~2000之间如果不再1000~2000之间就会提示出错。
商店售货系统表设计案例
现有一个商店的数据库,记录客户及其购物情况,由下面三个表组成:
商品goods(商品号goodsId,商品名goodsName,单价unitprice,商品类别category,供应商provider);
客户customer(客户号customerId,姓名name,住址address,电邮email性别sex,身份证cardId);
购买purchase(客户号customerId,商品号goodsId,购买数量nums);
请用SQL语言完成下列功能:
1 建表,在定义中要求声明:
(1)每个表的主外键;
(2)客户的姓名不能为空值;
(3)单价必须大于0,购买数量必须在1到30之间;
(4)电邮不能够重复;
(5)客户的性别必须是 男 或者 女,默认是男
create table goods (
goodsId char(8) primary key,
goodsName varchar2(30),
unitprice number(10,2) check (unitprice >0),
catagory varchar2(8),
provider varchar2(30));
create table customer (
customerId char(8) primary key,
name varchar2(20) not null,
address varchar2(30),
email varchar2(30) unique,
sex char(4) default 'man' check (sex in('man','fman')) ,
cardId char(18));
create table purchase (
customerId char(8) references customer(customerId),
goodsId char(8) references goods(goodsId),
nums number(10) check (nums between 1 and 30),
primary key (customerId,goodsId));
商店售货系统表设计案例(2)
如果在建表时忘记建立必要的约束,则可以在建表后使用alter table命令为表增加约束.
但是要注意: 增加not null约束时,需要使用modify选项,而增加其它四种约束使用add选项。
(1)每个表的主外码;
(2)客户的姓名不能为空值;--增加商品名也不能为空 SQL> alter table goods modify goodsName not null;
(3)单价必须大于0,购买数量必须在1到30之间;
(4)电邮不能够重复;--增加身份证也不重复 SQL> alter table customer add constraint cardunique(约束名) unique(cardID);
(5)客户的性别必须是 男 或者 女,默认是男
(6)增加客户的住址只能是 ‘shanghai‘ ’beijing‘ SQL> alter table customer add constraint addresscheck check (address in ('shanghai','beijing'));
删除约束
当不再需要某个约束时,可以删除.
alter table 表名 drop constraint 约束名称;
在删除主键约束的时候,可能有错误,比如:
alter table 表名 drop primary key ;
这是因为如果在两张表存在主从关系,那么在删除主表的主键约束时,必须带上 cascade 选项 如象
alter table 表名 drop primary key cascade;
显示约束信息
1.显示约束信息
通过查询数据字典视图user_constraints,可以显示当前用户所有的约束的信息.
select constraint_name,constraint_type ,status,validated from user_constraints where table_name=‘表名';
2.显示约束列
通过查询数据字典视图user_cons_columns,可以显示约束所对应的表列信息.
select column_name,position from user_cons_columns where constraint_name=‘约束名';
3.直接用pl/sql developer查看即可。
列级定义
列级定义是在定义列的同时定义约束.如在department 表定义主键约束
create table department4
(dept_id number(2) constraint pk_department primary key,
name varchar2(12),
loc varchar2(12));
表级定义
表级定义是指在定义了所有列后,再定义约束.这里需要注意: not null约束只能在列级上定义.
以在建立employee2表时定义主键约束和外键约束为例:
create table employee2
(emp_id number(4),name varchar2(15),dept_id number(2),
constraint pk_employee primary key (emp_id) ,
constraint fk_department foreign key (dept_id)
references department4(dept_id));
索引
索引是用于加速数据存取的数据对象.合理的使用索引可以大大降低i/o次数,从而提高数据访问性能。索引有很多种我们主要介绍常用的几种:
单列索引
单列索引是基于单个列所建立的索引,比如:
create index 索引名 on 表名(列名)
复合索引
复合索引是基于两列或是多列的索引。在同一张表上可以有多个索引,但是要求列的组合必须不同,比如:
create index emp_idx1 on emp (ename,job);
create index emp_idx1 on emp (job,ename);
使用原则
①在大表上建立索引才有意义
②在where子句或是连接条件上经常引用的列上建立索引
③索引的层次不要超过4层
索引缺点分析
1:建立索引,系统要占用大约为表的1.2倍的硬盘和内存空间来保存索引。
2:更新数据的时候,系统必须要有额外的时间来同时对索引进行更新,以维持数据和索引的一致性。
实践表明,不恰当的索引不但于事无补,反而会降低系统性能。因为大量的索引在进行插入、修改和删除操作时比没有索引花费更多的系统时间。
比如在如下字段建立索引应该是不恰当的:
1、很少或从不引用的字段;
2、逻辑型的字段,如男或女(是或否)等。综上所述,提高查询效率是以消耗一定的系统资源为代价的,索引不能盲目的建立,这是考验一个DBA是否优秀的很重要的指标
按照数据存储方式,可以分为B*树、反向索引、位图索引;
按照索引列的个数分类,可以分为单列索引、复合索引;
按照索引列值的唯一性,可以分为唯一索引和非唯一索引.
此外还有函数索引,全局索引,分区索引…
对于索引
在不同的情况我们会在不同的列上建立索引,甚至建立不同种类
的索引,请记住,技术是死的,人是活的。比如:
B*-树索引建立在重复值很少的列上,而位图索引则建立在重复值很多、
不同值相对固定的列上。
显示表的所有索引
在同一张表上可以有多个索引,通过查询数据字典视图dba_indexs 和 user_indexs
dba_indexs 用于显示数据库所有的索引信息,
user_indexs用于显示当前用户的索引信息:
显示索引列
通过查讯数据字段视图user_ind_columns,可以显示索引对应的列
的信息
select table_name,column_name from user_ind_columns where index_name='IND_ENAME';
你也可以通过 ql/sql developer工具查看索引信息
权限
权限是指执行特定类型sql命令或是访问其它方案对象的权利,当刚刚建立用户时,用户没有任何权限,也不能执行任何操作(一个用户可理解为一个方案,包括各种数据对象)
系统权限 如果要执行某种特定的数据库操作,则必须为其授予系统的权限;例如能不能创建数据库,能不能创建表,能不能连接等
对象权限 如果用户要访问其它方案的对象,则必须为其授予对象的权限.
==>为了简化权限的管理,可以使用角色。(一个角色包含多个权限)
系统权限介绍
系统权限是指执行特定类型sql命令的权利.它用于控制用户可以执行的一个或是一组数据库操作.例如
当用户具有create table权限时,可以在其方案中建表
当用户具有create any table权限时,可以在任何方案中建表.
oracle提供了100多中系统权限。常用的有:
create session 连接数据库
create table 建表
create view 键视图
create public synonym 键同义词
create procedure 建过程、函数、包
create trigger 建触发器
create cluster 建簇
而且oracle的版本越高,提供的系统权限就越多,我们可以查询数据字典视图system_privilege_map,可以显示所有系统权限
select * from system_privilege_map order by name;
授予系统权限
一般情况,授予系统权限是有dba完成的,如果用其它用户来授予系统权限,则要求该用户必须具有grant any
privilege的系统权限在授予系统权限时,可以带有with admin
option选项,这样,被授予权限的用户或是角色还可以将该系统权限授予其它的用户或是角色。为了让大家快速理解,我们举例说明:
1.创建两个用户 ken , tom.初始阶段他们没有任何权限,如果登陆就会给出错误的信息
SQL>create user ken identified by ken
SQL>create user tom identified by tom
2.给用户ken授权
SQL>grant create session,create table to ken with admin option;
grant create view to kenSQL>
3.给用户tom授权
我们可以通过ken给tom授权,因为with admin option是加上的。
当然也可以通过dba给tom授权,我们就用ken给tom授权:
SQL>grant create session,create table to tom;
SQL>grandt create view to tom; 报错
回收系统权限
一般情况下,回收系统权限是dba来完成的,如果其它的用户来回收系统权限,要求该用户必须具有相应系统权限及转授系统权限的选项(with admin option)。回收系统权限使用revoke来完成
当回收了系统权限后,用户就不能执行相应的操作了,但是请注意,系统权限级联收回问题?[不是级联回收!]
system--------------->ken------------->tom
(create session) (create session)(create session)
用system执行如下操作:
revoke create session from ken; 请思考 tom还能登录?
//查询oracle中所有的系统权限,一般是dba
SQL> select * from system_privilege_map order by name
//查询oracle中所有的角色,一般是dba
SQL> select * from dba_roles;
//查询oracle中所有对象权限,一般是dba
SQL> select * from dba_tab_privs;
//查询数据库的表空间
SQL> select tablespace_name from dba_tablespaces;
TABLESPACE_NAME
------------------------------------------------------------
SYSTEM
SYSAUX
UNDOTBS1
TEMP
USERS
//查询某个用户具有怎样的角色
SQL> select * from dba_role_privs where grantee='SYS'; 此处需要大写
//查看某个角色包括哪些系统权限。
select * from dba_sys_privs where grantee='DBA'
或者是:select * from role_sys_privs where role='DBA';
//查看某个角色包括的对象权限
select * from dba_tab_privs where grantee='DBA'
对象权限回收对象权限
指访问其它方案对象的权利,用户可以直接访问自己方案的对象,但是如果要访问别的方案的对象,则必须具有对象的权限.
比如smith用户要访问scott.emp表(scott:方案,emp :表)则必须在scott.emp表上具有对象的权限。
常用的有:
alter 修改 delete 删除 select 查询 insert 添加
update 修改 index 索引 references 引用 execute 执行
显示对象权限
通过数据字段视图可以显示用户或是角色所具有的对象权限.
视图为 dba_tab_privs
sql>conn system/manger
sql>select distinct privilege from dba_tab_privs;
sql>select grantor,owner,table_name,privilege from dba_tab_privs where grantee='BLAKE';
授予对象权限
在oracle9i前,授予对象权限是由对象的所有者来完成的,如果用其它的用户来操作,则需要用户具有相应的(with grant option )权限,从oracle9i开始,dba用户
(sys,system)可以将任何对象上的对象权限授予其它用户.授予对象权限是用grant命令来完成的.
对象权限可以授予用户,角色,和public.在授予权限时,如果带有with grant option 选项,则可以将该权限转授给其它用户。但时要注意 with grant option选项不能被授予角色,
1.monkey用户要操作scott.emp表,则必须授予相应的对象权限
①希望monkey可以查询scott.emp的表数据,怎样操作?
grant select on emp to monkey
②希望monkey可以修改scott.emp的表数据,怎样操作?
grant update on emp to monkey
③希望monkey可以删除scott.emp的表数据,怎样操作?
grant delete on emp to monkey
④有没有更加简单的方法,一次把所有权限赋给monkey?
grant all on emp to monkey
2.能否对monkey访问权限更加精细控制.(授予列权限)
①希望monkey只可以修改scott.emp的表的sal字段,怎样操作?
grant update on emp(sal) to monkey
②希望monkey只可查询scott.emp的表的ename,sal数据,怎样操作?
grant select on emp(ename,sal) to monkey
3.授予alter权限
如果black用户要修改scott.emp表的结构,则必须授予alter对象权限
sql>conn scott/tiger
sql>grant alter on emp to blake;
4.授予execute权限
如果用户想要执行其它方案的包/过程/函数,则须有execute权限.比如为了让ken可以执行包dbms_transaction,可以授execute权限
sql>conn system/manager
sql>grant execute on dbms_transaction to ken;
5.授予index权限
如果想在别的方案的表上建立索引,则必须具有index对象权限,如为了让black可以在 scott.emp上建立索引,就给其index的对象权限
sql>conn scott/tiger
sql>grant index on scott.emp to blake
6.使用with grant option选项
该选项用于转授对象权限.但是该选项只能被授予用户,而不能授予角色
sql>conn scott/tiger
sql>grant select on emp to blake with grant option
sql>conn black/shunping
sql>grant select on scott.emp to jones
在oracle9i中,收回对象的权限可以由对象的所有者来完成,也可以用dba用户(sys,system)来完成
这里要说明的时:收回对象权限后,用户就不能执行相应的sql命令,但是要注意的是对象的权限是否会被级联收回?[级联回收]和系统权限不一样
如:
scott------------->blake---------------->jones
select on emp select on emp select on emp
sql>conn scott/tiger@accp
sql>revoke select on emp from blake
请大家思考,jones能否查询scott.emp表数据.
角色就是相关权限的命令集合,使用角色的主要目的就是为了简化权限的管理.假定有用户a,b,c为了让他们都拥有权限
①连接数据库
②在scott.emp表上select,insert,update
如果采用直接授权操作,则需要进行12次授权。
我们如果采用角色就可以简化:
首先将create session , select on scott.emp,insert on scott.emp,update on scott.emp授予角色,
然后将该角色授予a,b,c用户,这样就可以三次授权搞定.
角色分为预定义和自定义角色两类:
预定义角色
预定义角色是指oracle所提供的角色,每种角色都用于执行一些特定的管
理任务,下面我们介绍常用的预定义角色connect,resource,dba
㈠connect角色
connect角色具有一般应用开发人员需要的大部分权限,当建立了一个用户后,多数情况下,只要给用户授予connect和resource角色就够了,那么connect角色具有哪些系统权限呢?
alter session
create cluster
create database link
create sesssion
create table
create view
create sequence
预定义角色
㈡resource角色
resource角色具有应用开发人员所需要的其它权限,比如建立
存储过程、触发器等。这里需要注意的是resource角色隐含了
unlimited tablespace系统权限。
resource角色包含以下系统权限:
create cluster
create indextype
create table
create sequence
create type
create procedure
create trigger
预定义角色
㈢dba角色
dba角色具有所有的系统权限,及with admin option选项,默认的dba用户为sys和system他们可以将任何系统权限授予其它用户.但是要注意的是dba角色不具备sysdba和sysoper的特权(启动和关闭数据库)
自定义角色
顾名思义就是自己定义的角色,根据自己的需要来定义.一般是dba来建立,如果用的别的用户来建立,则需要具有create role的系统权限.在建立角色时可以指定验证方式(不验证,数据库验证等)
㈠建立角色(不验证)
如果角色是公用的角色,可以采用不验证的方式建立角色.
create role 角色名 not identified;
㈡建立角色(数据库验证)
采用这样的方式时,角色名、口令存放在数据库中。当激活该角色时,必须提供口令.在建立这种角色时,需要为其提供口令
create role 角色名 identified by password
角色授权
当建立角色时,角色没有任何权限,为了使得角色完成特定任务,必须为其授予相应的系统权限和对象权限。
㈠给角色授权
给角色授予权限和给用户授权没有太多区别,但是要注意,系统权限的 unlimited tablespace 和对象权限的with grant option 选项是不能授予角色的。
sql>conn system/manger
sql>grant create session to 角色名 with admin option
sql>conn scott/tiger@myora1
sql>grant select on scott.emp to 角色名
sql>grant insert,update,delete on scott.emp to 角色名
通过上面的步骤,就给角色授权了.
㈡分配角色给某个用户
一般分配角色是由dba来完成的,如果要以其它用户身份分配角色,则要求用户必须具有grant any role的系统权限。
sql>conn system/manager
sql>grant 角色名 to blake with admin option
因为我给了with admin option 选项所以,blake可以把system分配给它的角色分配给别的用户.
删除角色
使用drop role,一般是dba来执行,如用其它用户则要求该用户具有drop any role系统权限
sql>conn system/manager
sql>drop role rolename ===>拥有该角色的用户丢失此权限
显示角色信息
①显示所有角色
sql>select * from dba_roles;
②显示角色具有的系统权限
sql>select privilege,admin_option from role_sys_privs where role=‘角色名';
③显示角色具有的对象权限
通过查询数据字典视图dba_tab_privs可以查看角色具有的对象权限或是列的权限。
④显示用户具有的角色,及默认角色
当以用户的身份连接到数据库时,oracle会自动的激活默认的角色,通过查询数据字典视图dba_role_privs可以显示某个用户具有的所有角色及当前默认的角色
sql>select granted_role,default_role from dba_role_privs where grantee=‘用户名';
SQL> select granted_role,default_role from dba_role_privs where grantee='SCOTT';
GRANTED_ROLE DEF
------------------------------ ---
RESOURCE YES
CONNECT YES
精细访问控制
是指用户可以使用函数、策略实现更加细微的安全访问控制。如果使用精细访问控制,则当在客户端发出sql语句(select ,insert,update,delete)时,
oracel会制动在sql语句后追加谓词(where子句),并执行新的sql语句。通过这样的控制,可以使得不同的数据库用户在访问相同表时,返回不同的数据信息,如图
用户: scott blake jones
策略 emp_access
表emp
如上图所示:通过策略emp_access,用户scott,black,jones在执行相同
的sql语句时,可以返回不同的结果.例如,当执行select ename from emp;时,根据实际情况可以返回不同的结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号