OO第三单元总结
设计策略
在本次作业中,对于规格的实现分为以下几个步骤
理解语义
相信很多同学和我一样,看到JML的一瞬间是蒙的,因为并不知道它都在说些什么,后来了解语法后发现和离散数学的合式公式也大差不差。在设计时的第一步骤就是读得懂它要做些什么,有些方法的语义非常简单,代码几乎直接按照JML书写就可以,比如下文的这种getter方法。
/*@ public normal_behavior
@ requires contains(id);
@ ensures \result == getPerson(id).getReceivedMessages();
@ also
@ public exceptional_behavior
@ signals (PersonIdNotFoundException e) !contains(id);
@*/
public /*@pure@*/ List<Message> queryReceivedMessages(int id) throws PersonIdNotFoundException;
还有的方法语义则非常复杂,比如sendIndirectMessage()(JML内容从略)。对于这些复杂的方法方法就需要通读一遍规格,基于类中各数据本来的语义(value,acquaintance等),将规格转换为自然语——在联通块上不相连的两点之间求解最短路,然后再转换为我们常见的如Dijikstra算法求解。
选取容器和算法
这容器留在第三部分去说,主要是JML中所有的容器都被抽象成了线性表,如果确实用数组实现在性能上会有较大问题,根据主要场景来选取。而关于算法的选取,只要针对问题对症下药就可以,比如在单源最短路等。
考虑潜作用
我觉得这是实现规格最关键的一点,代码中的规格只是提供了对自己定义的变量形式化的约束,但是我们的实现和规格并不完全一致,自己实现的成员变量同样有自己隐藏的的不变式。对于部分方法,除了方法规格中产生的影响,还要关心它对其他规格之外自己维护的内容的作用。如addPerson的规格如下所示:
/*@ public normal_behavior
@ requires !(\exists int i; 0 <= i && i < people.length; people[i].equals(person));
@ assignable people;
@ ensures people.length == \old(people.length) + 1;
@ ensures (\forall int i; 0 <= i && i < \old(people.length);
@ (\exists int j; 0 <= j && j < people.length; people[j] == (\old(people[i]))));
@ ensures (\exists int i; 0 <= i && i < people.length; people[i] == person);
@ also
@ public exceptional_behavior
@ signals (EqualPersonIdException e) (\exists int i; 0 <= i && i < people.length;
@ people[i].equals(person));
@*/
public void addPerson(Person person) throws EqualPersonIdException;
从语义上来说,其中只表达了记录人群的容器中加入了person,但是我的实际代码如下:
public void addPerson(Person person) throws EqualPersonIdException {
if (contains(person.getId())) {
throw new MyEqualPersonIdException(person.getId());
} else {
people.put(person.getId(), person);
hidden.add((MyPerson) person);
}
HashSet<Person> temp = new HashSet<>();
temp.add(person);
block.put(person.getId(), temp);
blockCount++;
}
在我的算法中我记录了blocksum维护了连通块的个数,同时block中维护了联通块中的节点全体,因此在addPerson的时候必须要全部加入其中。这些属性和它们的不变式是规格中没有说明的,要在选用属性时就构思好该属性的增删查改路线和需要保证的不变式,对途径上进行操作的方法多加留心。
注意异常
注意exceptional_behavior中的异常要注意发生的条件,一般在类的开头直接判断绝大部分异常情况并抛出对应异常。
coding
想了这么多,写就完了。
测试的方法和策略
JUNIT
JUNIT是常见的单元测试框架,用于对类中的每一个方法进行单元测试,正好适用于本作业每个方法提供的JML规格,校验每一条规格的实现情况,这是我写的两个单元测试实例:
@Test()
void addPersonNormal() {
Person person1=new MyPerson(1926,"he",95);
assertDoesNotThrow(()->network.addPerson(person1));
assertTrue(network.contains(1926));
assertTrue(network.getPerson(1926).equals(person1));
assertThrows(MyEqualPersonIdException.class,()->network.addPerson(person1));
}
@Test
void addRelation() {
Person person1=new MyPerson(1926,"he",95);
Person person2=new MyPerson(1927,"he",94);
assertDoesNotThrow(()->network.addPerson(person1));
assertDoesNotThrow(()->network.addPerson(person2));
assertDoesNotThrow(()->network.addRelation(1926,1927,123));
assertTrue(person1.isLinked(person2));
assertThrows(MyEqualRelationException.class,()->network.addRelation(1926,1926,123));
assertThrows(MyPersonIdNotFoundException.class,()->network.addRelation(1925,1926,123));
assertThrows(MyPersonIdNotFoundException.class,()->network.addRelation(1926,1923,123));
}
这两个Test方法分别对addRelation和addPerson做了测试,其中测试了正常情况:在第一个测试中表现为添加一个人,检验它确实被网络包含在内,网络内的人确实就是他。也测试了异常情况:在第二个测试中两个人ID没有找到,两个人的关系已经存在等。
主要设计的思路是,使用JUNIT中的@before方法准备数据,再用@Test方法进行测试。测试的过程中将JML提供的规格进行翻译,针对边界情况、压力数据、普通情况进行测试。测试中使用assert语句判断条件是否得到满足,以及对应的异常是否被正常抛出。
就个人使用的体验而言,针对规格引用JUNIT进行的测试并不美妙。所有的测试并不能自动生成,而根据个人对JML的理解撰写而成。虽然这样的方式至少保证我们能读上两遍JML,但是人总会犯错,人工生成的测试总会有或多或少的错误或疏漏,而第一次理解的固有印象往往使第二次阅读收效甚微,因此这种单元测试的效果需要打上一个问号。
评测机
在我个人的理解中,评测机属于集成测试的内容,也就是你的程序接受了上千条输入,输出了上千条,校验程序在其中有没有出现错误。而我们的JML规格主要基于方法层面,不能给全局的集成测试提供条件(事实上如上文所说,连给单个方法测试都有些捉襟见肘),,因此全局测试中主要依赖于输入数据的限制。而令人高兴的是,本次输入的数据除了规模没有限制(可以减少很多异常的处理),因此评测机的集成测试通过生成多种类型的数据(稀疏图,连通图,强化某一指令等)来对本单元代码进行测试。
容器选择和使用的经验
想要选取合适的容器,首先要知道有哪些容器和它们都有什么特点,窃取别人博客中的一张图,其中列举了JAVA中的常见容器和关系。
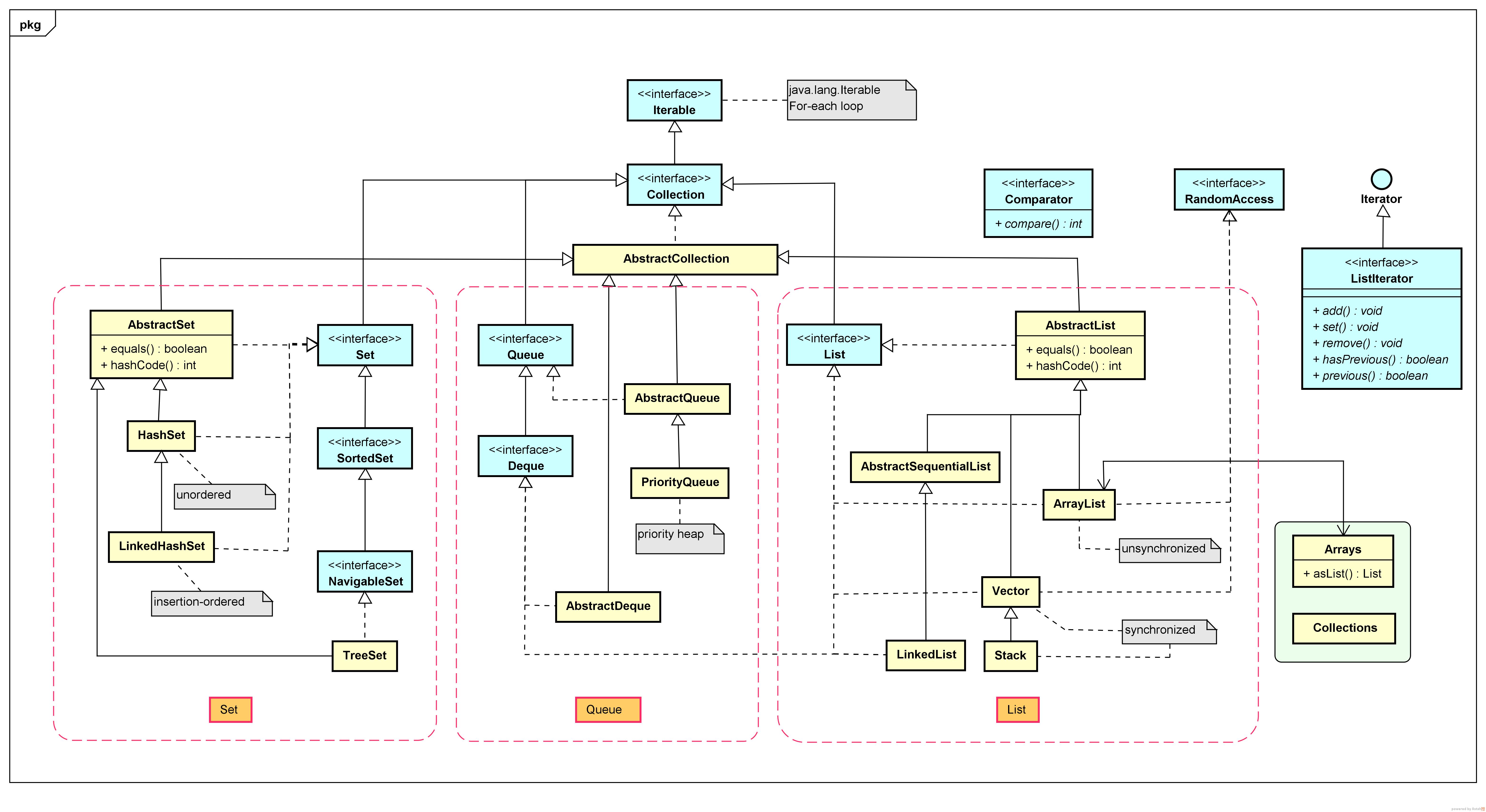
总的来说有三种大的种类List,Set,queue和Map。前三种同属于collection,个人理解可以翻译成“合集”,和map的KV对有明显的区别
List的特点为线性表,也就是我们通俗意义上的数组ArrayList是最普通的数组,支持\(O(1)\)的尾插入,随机访问和\(O(n)\)的删除。如果对于数据的要求仅仅是存下来,不需要做删除,只要后续进行随机访问或遍历等操作,ArrayList是最好的选择。本次作业中没有这种简单的需求,没有采用。LinkedList是链表,支持\(O(1)\)的插入,\(O(n)\)的插入删除。由于需要便捷的插入头部,本次作业中的消息队列选用链表实现- Vector是线程安全的数组,stack是先进后出的栈,本次作业均没有用上。
- 自建容器,在本次作业中我实现了
SizedBalancedTree作为平衡树来实现\(O(log n)\)的名称排序查询。
- Set的特点为集合,其中每个对象都不一样,对于Hash系列由hashcode决定,而Tree系列由比较大小决定。
HashSet,支持平均\(O(1)\)的插入删除查询,最坏情况\(O(logn)\),由于java的实现机制决定,当Hashset中的一个Hash值元素过多时,该点会退化为TreeSet,此时是上述的最坏情况。也就是说,HashSet的性能是全面由于TreeSet的,除了下文中特殊需要。基于HashSet的以上特性,我在本次作业中需要多次查找是否存在容器上选择了HashSet,例如Dijkstra算法中,为了标记已经到达的点的集合,我就用该容器进行存储,主要利用\(O(1)\)的插入和查找。LinkedHashSet相比于HashSet确定了遍历的顺序,没有突出特点。
TreeSet。支持\(O(logn)\)的入删除查询,上文中的特殊需要指需要按从小到大的顺序进行遍历时,TreeSet较优。本次代码中的queryNameRank理论上可以依靠TreeSet,但是并不能从复杂度上得到提升,个人选择了其他容器,因此没有用上TreeMap。
Queue的特点是队列,可以时单向队列也可以时双向队列,还可以是特殊情况如:PriorityQueue:支持\(O(1)\)查找最小值,\(O(logn)\)插入。在查找,删除等操作上性能堪忧。主要用于维护最小值这一特殊情景,本次作业中适用Dijkstra算法。
Map主要维护的是KV对,需求场景是根据Key查找Value这一关系型查找HashMap,LinkedHashMap,TreeMap的特点和它们的集合版本如出一辙(因为set版本内部就是用map实现的)。本次实验中大量使用了HashMap去完成一些查找场景的使用,如people这一JML中的容器就是HashMap,可以方便的根据人的ID来查询人。
所有的容器选取都依靠着业务要求而来,问自己这些问题就可以帮助自己情动地确定答案:
- 我们要维护一个关系(Map)还是维护一个集合(Collection)
- 我们的主要操作是什么,查找?插入?删除?
- 操作有没有限制,随机访问?需要头插?
- 有没有特殊要求,维护最小值?要有序(输入顺序,大小排序)遍历?
性能问题
本次作业中并没有出现性能问题。主要是在实现每个方法时都首先估计一下复杂度,以第三次作业为例,总共有10000条指令,其中实际起效的指令大约有5000条(考虑要addPerson和addRelation等操作)。这样的数据规模,对于单次\(O(n)\),总计\(O(n^2)\)的操作是可以hold住的,对于\(O(n^2logn)\)也问题不大。估计复杂度这活我们大一都学过,就不再赘述了。当发现一些方法复杂度过高时可以有以下几个优化的常见的优化角度供我们进行思考:
- 换用更好的算法,这是直接治本的方法,比如qci指令就应该用并查集实现,性能近乎\(O(1)\),完胜dfs。
- 进行局部优化
- 引入cache机制 如果没有更改就直接返回上次的值,但这样的方法不能改变最坏复杂度。
- 在cache的基础上可以引入缓存——更新机制 如
queryValueSum单次查询\(n^2\),但在addPerson时利用\(O(n)\)的增量更新来方便之后\(O(1)\)的查询。 - 进行微调
Dijistra进行堆优化,对并查集按秩合并等。 - 扣细节,比如for循环比stream流性能占优等。
作业架构设计
本次作业没有做太多的架构设计,第三次作业的UML类图如下所示:

其中的类的继承关系只有MyRedEnvelopeMessag类和MyEmojiMessage类继承了MyMessage类。而从具体实现角度而言,其实我的社交网络几乎所有的任务都承担在了NetWork类中,其中实现了大量的算法(如并查集,Dijistra等)和关系维护(发消息等),整个类占了项目代码的一半。这样的载荷很不合理,究其原因是我们的作业中提供了JML规格,因此个人实现时就偷懒没有注意自己再去设计,而只是在规格中的每个类中实现了每个方法和其实现细节。
在这推荐一位学长的博客。主要还是老生常谈的机制和策略分离,将上层应用和底层实现解耦,同时底层也支持泛型机制,这样就可以做到应用和底层之间的灵活适配,平滑切换。就以我个人实例而谈,我的MyContainer容器实现的是一个平衡二叉树,其中支持查找nameRank,但是和朴素的TreeMap实现并不兼容,故代码中甚至有一段用注释包裹的对TreeMap遍历求取rank的代码。个人认为比较理想的一个设计是将它们都封装成一个接口,支持addPerson和queryNameRank,两种实现(TreeMap和SizedBalancedTree)都来实现它,这样我们的社交网络类中就可以直接调用不同的容器,而不用关注实现细节。再如sendMessage方法,应该直接取出Message后就直接调用Message的一个send方法,通过每个信息自身来决定自己的发送策略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号