CART算法原理及实现
1.算法介绍
分类回归树算法:CART(Classification And Regression Tree)算法采用一种二分递归分割的技术,将当前的样本集分为两个子样本集,使得生成的的每个非叶子节点都有两个分支。因此,CART算法生成的决策树是结构简洁的二叉树。
分类树两个基本思想:第一个是将训练样本进行递归地划分自变量空间进行建树的想法,第二个想法是用验证数据进行剪枝。
建树:在分类回归树中,我们把类别集Result表示因变量,选取的属性集attributelist表示自变量,通过递归的方式把attributelist把p维空间划分为不重叠的矩形,具体建树的基本步骤参见:http://baike.baidu.com/view/3075445.htm。
CART算法是怎样进行样本划分的呢?它检查每个变量和该变量所有可能的划分值来发现最好的划分,对离散值如{x,y,x},则在该属性上的划分有三种情况({{x,y},{z}},{{x,z},y},{{y,z},x}),空集和全集的划分除外;对于连续值处理引进“分裂点”的思想,假设样本集中某个属性共n个连续值,则有n-1个分裂点,每个“分裂点”为相邻两个连续值的均值 (a[i] + a[i+1]) / 2。将每个属性的所有划分按照他们能减少的杂质(合成物中的异质,不同成分)量来进行排序,杂质的减少被定义为划分前的杂质减去划分之后每个节点的杂质量*划分所占样本比率之和,目前最流行的杂质度量方法是:GINI指标,如果我们用k,k=1,2,3……C表示类,其中C是类别集Result的因变量数目,一个节点A的GINI不纯度定义为:
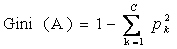
其中,Pk表示观测点中属于k类得概率,当Gini(A)=0时所有样本属于同一类,当所有类在节点中以相同的概率出现时,Gini(A)最大化,此时值为(C-1)C/2。
对于分类回归树,A如果它不满足“T都属于同一类别or T中只剩下一个样本”,则此节点为非叶节点,所以尝试根据样本的每一个属性及可能的属性值,对样本的进行二元划分,假设分类后A分为B和C,其中B占A中样本的比例为p,C为q(显然p+q=1)。则杂质改变量:Gini(A) -p*Gini(B)-q*Gini(C),每次划分该值应为非负,只有这样划分才有意义,对每个属性值尝试划分的目的就是找到杂质该变量最大的一个划分,该属性值划分子树即为最优分支。
剪枝:在CART过程中第二个关键的思想是用独立的验证数据集对训练集生长的树进行剪枝。
分析分类回归树的递归建树过程,不难发现它实质上存在着一个数据过度拟合问题。在决策树构造时,由于训练数据中的噪音或孤立点,许多分枝反映的是训练数据中的异常,使用这样的判定树对类别未知的数据进行分类,分类的准确性不高。因此试图检测和减去这样的分支,检测和减去这些分支的过程被称为树剪枝。树剪枝方法用于处理过分适应数据问题。通常,这种方法使用统计度量,减去最不可靠的分支,这将导致较快的分类,提高树独立于训练数据正确分类的能力。
决策树常用的剪枝常用的简直方法有两种:事前剪枝和事后剪枝,CART算法经常采用事后剪枝方法:该方法是通过在完全生长的树上剪去分枝实现的,通过删除节点的分支来剪去树节点。最下面未被剪枝的节点成为树叶。
CART用的成本复杂性标准是分类树的简单误分(基于验证数据的)加上一个对树的大小的惩罚因素。惩罚因素是有参数的,我们用a表示,每个节点的惩罚。成本复杂性标准对于一个数来说是Err(T)+a|L(T)|,其中Err(T)是验证数据被树误分部分,L(T)是树T的叶节点树,a是每个节点的惩罚成本:一个从0向上变动的数字。当a=0对树有太多的节点没有惩罚,用的成本复杂性标准是完全生长的没有剪枝的树。在剪枝形成的一系列树中,从其中选择一个在验证数据集上具有最小误分的树是很自然的,我们把这个树成为最小误分树。
2.算法实现
本文根据一个样本集,进行了CART算法的简单实现。该样本集中每个样本有十六个特征属性和一个结果属性,为了降低划分的难度,每个特征属性取两个不同的离散值,结果属性有两个离散值:Yes和No。
数据结构定义:在该算法中定义了三种数据结构:存储样本属性名称及取值的Node属性,存储单个样本的EXampleSet属性,树的节点属性dataNode;存放在DataStructure.h中,代码如下:
- <span style="font-size: 18px;">typedef struct tagNode
- {//存储属性
- string name;//属性的名称
- string value;//属性取值
- }Node;
- typedef struct tagExampleSet
- {//样本存储
- string example[16];//样本的每个属性上的属性值
- string decision;//样本的结果类
- }ExampleSet;
- typedef struct Data_Node{
- //节点的数据结构,结果分为两类yes类和No类
- int Yesnum;//类yes得样本数目
- int Nonum;//类no得样本数
- vector<ExampleSet> myVector;//存储样本
- Data_Node *LeftNode;//左子树
- Data_Node *RightNode;//右子树
- int Property;//划分选取的属性
- string Proper_value;//所选的属性的值
- int nodenum;//标示节点
- bool leavenode;//标示叶节点
- }dataNode;</span>
- <span style="font-size:18px;">typedef struct tagNode
- {//存储属性
- string name;//属性的名称
- string value;//属性取值
- }Node;
- typedef struct tagExampleSet
- {//样本存储
- string example[16];//样本的每个属性上的属性值
- string decision;//样本的结果类
- }ExampleSet;
- typedef struct Data_Node{
- //节点的数据结构,结果分为两类yes类和No类
- int Yesnum;//类yes得样本数目
- int Nonum;//类no得样本数
- vector<ExampleSet> myVector;//存储样本
- Data_Node *LeftNode;//左子树
- Data_Node *RightNode;//右子树
- int Property;//划分选取的属性
- string Proper_value;//所选的属性的值
- int nodenum;//标示节点
- bool leavenode;//标示叶节点
- }dataNode;</span>
样本读取及处理:用两个文件分别存储样本的属性及所有样本。文件t存储样本的十六个自变量属性、类别属性的名称和离散值集合,文件t1是所有样本的集合,用ReadFile类读取文件,并把它们分别存储在两个向量中。建树的过程在MySufan类中,该类地方法列表如下:
- <span style="font-size: 18px;">MySuanfa();
- ~MySuanfa();
- void Method();//调用建树、剪枝方法
- void BuildTree(Data_Node*thisNode);//建树方法,每次调用DeviceTree对非叶节点进行划分
- void DeviceTree(Data_Node*thisNode,int i);//对非叶结点进行划分,分出左节点,有节点
- int Choose_Property(Data_Node* thisNode);//返回选择的属性值
- double pure(int i1,int i2,int i3);//纯度计算函数,每次计算最优划分时用
- void Deal(Data_Node* d);//剪枝函数,此函数对建好的树用测试样本进行剪枝
- void levelorder(Data_Node * p);//层次遍历,此方法按曾给决策点分配序号,用于剪枝
- void inorder(Data_Node *p);//中序遍历,和建树的前序遍历用于确定树的结构
- void BuildTest(Data_Node *d,int t);//此方法用于计算当取不同决策点时,建树样本的错误样本数,t为决策点数目
- void CutTree(Data_Node *d,int k,int t);//k为单个样本,t为决策点数,根据决策点对测试样本集进行测试
- void ClassOfNode(vector<ExampleSet>);//本方法用于切割原始样本集,将样本分为测试样本和建树样本</span>
- <span style="font-size:18px;">MySuanfa();
- ~MySuanfa();
- void Method();//调用建树、剪枝方法
- void BuildTree(Data_Node*thisNode);//建树方法,每次调用DeviceTree对非叶节点进行划分
- void DeviceTree(Data_Node*thisNode,int i);//对非叶结点进行划分,分出左节点,有节点
- int Choose_Property(Data_Node* thisNode);//返回选择的属性值
- double pure(int i1,int i2,int i3);//纯度计算函数,每次计算最优划分时用
- void Deal(Data_Node* d);//剪枝函数,此函数对建好的树用测试样本进行剪枝
- void levelorder(Data_Node * p);//层次遍历,此方法按曾给决策点分配序号,用于剪枝
- void inorder(Data_Node *p);//中序遍历,和建树的前序遍历用于确定树的结构
- void BuildTest(Data_Node *d,int t);//此方法用于计算当取不同决策点时,建树样本的错误样本数,t为决策点数目
- void CutTree(Data_Node *d,int k,int t);//k为单个样本,t为决策点数,根据决策点对测试样本集进行测试
- void ClassOfNode(vector<ExampleSet>);//本方法用于切割原始样本集,将样本分为测试样本和建树样本</span>
递归建树:建树按照递归方式进行建树,采用全部样本的2/3进行建树,首先找到一个划分值,如果不存在返回-1,然后判断一个树是否为叶子节点,不为叶子节点按照划分值进行划分,关键代码如下:
- <span style="font-size: 18px;">void MySuanfa::BuildTree(Data_Node* thisNode)
- {
- if(thisNode!=NULL){// //节点不为空
- nodenum++;
- thisNode->nodenum=nodenum;
- int getProperty=Choose_Property(thisNode);//找到划分
- thisNode->Property=getProperty;
- if((thisNode->Yesnum*thisNode->Nonum==0)||getProperty==-1)
- {//如果划分为-1,则无法再次划分
- thisNode->Property=-1;
- thisNode->leavenode=true;
- }
- else
- {//递归建树
- thisNode->leavenode=false;
- DeviceTree(thisNode,getProperty);//将父节点按照划分属性进行划分
- BuildTree(thisNode->LeftNode);//递归建立左子树
- BuildTree(thisNode->RightNode);//递归建立右子树
- }
- }
- }</span>
- <span style="font-size:18px;">void MySuanfa::BuildTree(Data_Node* thisNode)
- {
- if(thisNode!=NULL){// //节点不为空
- nodenum++;
- thisNode->nodenum=nodenum;
- int getProperty=Choose_Property(thisNode);//找到划分
- thisNode->Property=getProperty;
- if((thisNode->Yesnum*thisNode->Nonum==0)||getProperty==-1)
- {//如果划分为-1,则无法再次划分
- thisNode->Property=-1;
- thisNode->leavenode=true;
- }
- else
- {//递归建树
- thisNode->leavenode=false;
- DeviceTree(thisNode,getProperty);//将父节点按照划分属性进行划分
- BuildTree(thisNode->LeftNode);//递归建立左子树
- BuildTree(thisNode->RightNode);//递归建立右子树
- }
- }
- }</span>
分析上面代码,Choose_Property(thisNode);函数的作用是将thisNode中的样本尝试进行最优划分,划分的依据就是杂质最大该变量,如果划分成功返回属性下标,否则返回-1,我们在样本中每个属性默认取两个离散值。注意到方法中对书中定义的leavenode和nodenum两个变量的操作,他们的用途是什么呢?nodenum的第一个作用是树的遍历,将每一个节点赋予一个唯一的值,建树的过程是前序建树,建树结束后根据树的中序遍历可以唯一确定树的结构,nodenum的第二个作用和leavenode的作用将会在剪枝过程中用到,后面将会提到。
当建树结束后,树的前序即为nodenum从小到大的排序,然后通过调用中序遍历函数输出树的中序序列,确定树的结构。该树含有17个决策点(非叶子节点),18个叶子节点。
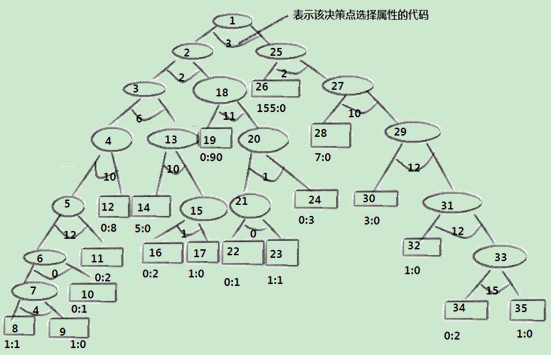
图1. 结构
树中决策点的划分代码对应的属性名称:
0————handicapped-infants ; 1————water-project-cost-sharing
2————adoption-of-the-budget-resolution ; 3————physician-fee-freeze
4————el-salvador-aid ; 5————religious-groups-in-schools
6————anti-satellite-test-ban; 7————aid-to-nicaraguan-contras
8————mx-missile ; 9————immigration
10————synfuels-corporation-cutback ; 11————education-spending
12————superfund-right-to-sue ; 13————crime
14————duty-free-exports ; 15—export-administration-act-south-africa
按照递归分类的算法,最终生成的树的叶子节点中或者同属一类或者只有一个样本,分析树的结构我们可以发现,有两个叶子节点8和23不符合这种情况,却成了叶子节点。这与所选样本有关,在这两个叶节点中两个样本的十六个特征属性值都相同,只有所属类别不同,所以无法根据递归算法进行分类。另当选取physician-fee-freeze 和adoption-of-the-budget-resolution两种属性进行决策时,样本所属的类别已经基本判定,造成这种情况我们可认为这两种属性在样本中所占的权重很大,只要确定这两种情况,树的大部分样本的分类就已确定。
剪枝:用训练样本建树结束后,就是进行树的剪枝阶段,本算法采用样本集的后1/3作为测试进行剪枝。
树的决策点:如果一个节点为非叶节点,则称该节点为一个树的决策点。树的剪枝就是减去过分拟合给树带来的的冗余,用尽可能少的决策点、尽可能低的树高获取尽可能大的正确率。
如何获取树的决策点?逐层确定树的决策点,并根据决策点数目进行剪枝是剪枝的关键。
根据二叉树的特性可知树的非叶节点=叶节点-1;所以可以从树的节点数中得知树种非叶结点的数量。本程序根据这一特性将树的决策点逐层赋值,根节点赋值1,根节点的左节点赋值2……,这一过程通过层次遍历实现。并将该值赋给nodenum,对于叶子节点nodenum为0关键代码如下:
- <span style="font-size: 18px;">void MySuanfa::levelorder(Data_Node* p)
- {
- int node=1;
- list<Data_Node *>q;
- if(p)q.push_back(p);
- p->nodenum=node;
- while(!q.empty())
- {
- p=q.front();
- q.pop_front();
- if(p->LeftNode)
- {
- if(p->LeftNode->leavenode)
- {//如果该节点的左节点是子节点,则将nodenum赋0
- p->LeftNode->nodenum=0;
- }
- else
- {//否则将该节点赋一个node值,该值表示此决策点的顺序
- node++;
- p->LeftNode->nodenum=node;
- q.push_back(p->LeftNode);
- }
- }
- if(p->RightNode)
- {
- if(p->RightNode->leavenode)//
- {//如果该节点的右节点是子节点,则将nodenum赋0
- p->RightNode->nodenum=0;
- }
- else
- {//否则将该节点赋一个node值,该值表示此决策点的顺序
- node++;
- p->RightNode->nodenum=node;
- q.push_back(p->RightNode);
- }
- }
- }
- }
- </span>
- <span style="font-size:18px;">void MySuanfa::levelorder(Data_Node* p)
- {
- int node=1;
- list<Data_Node *>q;
- if(p)q.push_back(p);
- p->nodenum=node;
- while(!q.empty())
- {
- p=q.front();
- q.pop_front();
- if(p->LeftNode)
- {
- if(p->LeftNode->leavenode)
- {//如果该节点的左节点是子节点,则将nodenum赋0
- p->LeftNode->nodenum=0;
- }
- else
- {//否则将该节点赋一个node值,该值表示此决策点的顺序
- node++;
- p->LeftNode->nodenum=node;
- q.push_back(p->LeftNode);
- }
- }
- if(p->RightNode)
- {
- if(p->RightNode->leavenode)//
- {//如果该节点的右节点是子节点,则将nodenum赋0
- p->RightNode->nodenum=0;
- }
- else
- {//否则将该节点赋一个node值,该值表示此决策点的顺序
- node++;
- p->RightNode->nodenum=node;
- q.push_back(p->RightNode);
- }
- }
- }
- }
- </span>
遍历结束后,每一个决策点数目可以确定一个树,我们就可以根据树的决策点数对训练样本和测试样本的误差进行统计,怎样根据决策点数确定树的结构?可以将树的前序遍历进行改进,对于t个决策点,节点为0或大于t的都是叶子节点,一旦确定叶子节点,树的结构就清楚了,下图为重新赋值后的树,在该图中,如当有3个决策点时,2的子节点和3的子节点都是叶子节点,当用改进的前序遍历便立时会输出有3个决策点:(1,2,3);4个叶子节点(4,5,0,6)的子树:
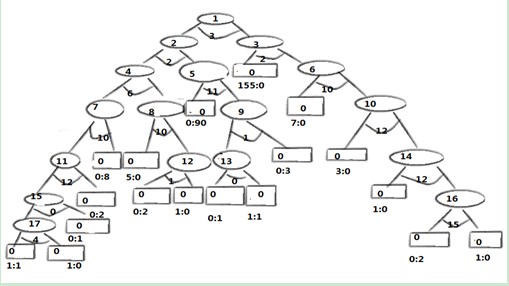
图2给树的节点重新赋值
不同决策点可对应不同子树,通过前序遍历可以将叶子节点中的错误样本统计出来计算该树情况下错误样本的个数,然后再用测试样本遍历树,统计测试样本再改树下错误样本个数最后得出结果集如下:
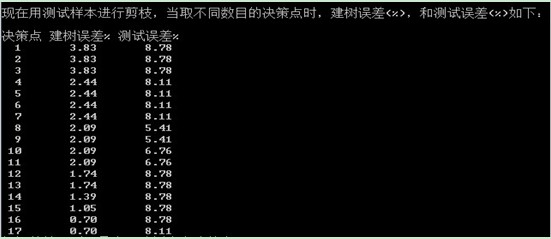
图3 不同决策点时建树误差与测试误差
通过比较可知当树有8和9个决策点时,测试误差最小,我们取8,因为此时树比9个决策点简单,我们取含有8个决策点为最小误分树。最小误分树结构如下:
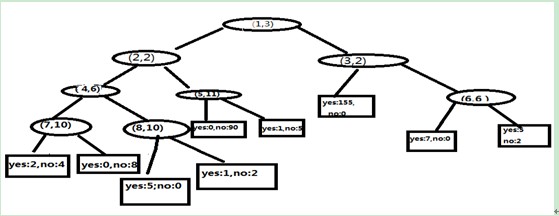
图4 最小误分树
上图中最小误分树非叶节点中的两个值,第一个表示决策点表示,第二个表示选择的属性的代码,叶子节点中两数表示每一类的数目。
我们定义最优剪枝的方法是在剪枝序列中含有误差在最小误差树的一个标准差之内的最小树,算出的最小误差率被砍做一个带有标准差等于 的随机变量的观测值,其中Emin对最小误差树的错误率,Nval是验证集的个数:Emin=5.41%,Nval=148,所以到当树有4个决策点时,为最优剪枝。
的随机变量的观测值,其中Emin对最小误差树的错误率,Nval是验证集的个数:Emin=5.41%,Nval=148,所以到当树有4个决策点时,为最优剪枝。

图5 最优剪枝树

 浙公网安备 33010602011771号
浙公网安备 33010602011771号