selenium-详细解读8种元素定位方式
访问百度的小Demo
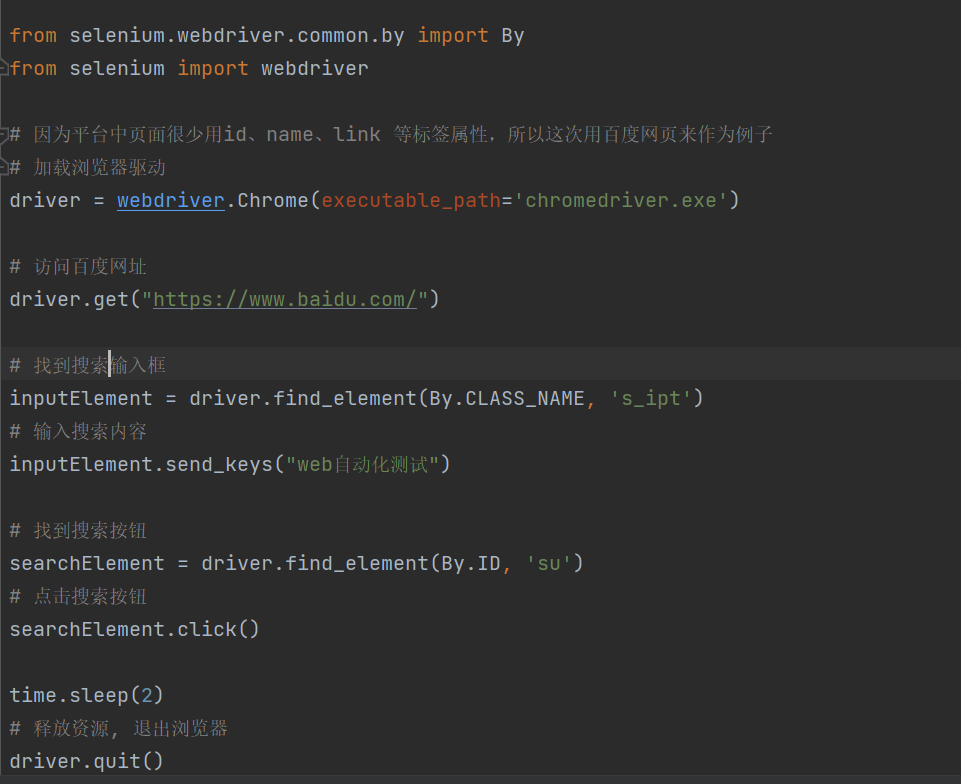
可以看到,流水账式写Web自动化测试代码的顺序就是:
加载驱动 - 访问链接 - 页面操作 - 关闭浏览器
演示动图:

方式一:通过元素的id-By.ID
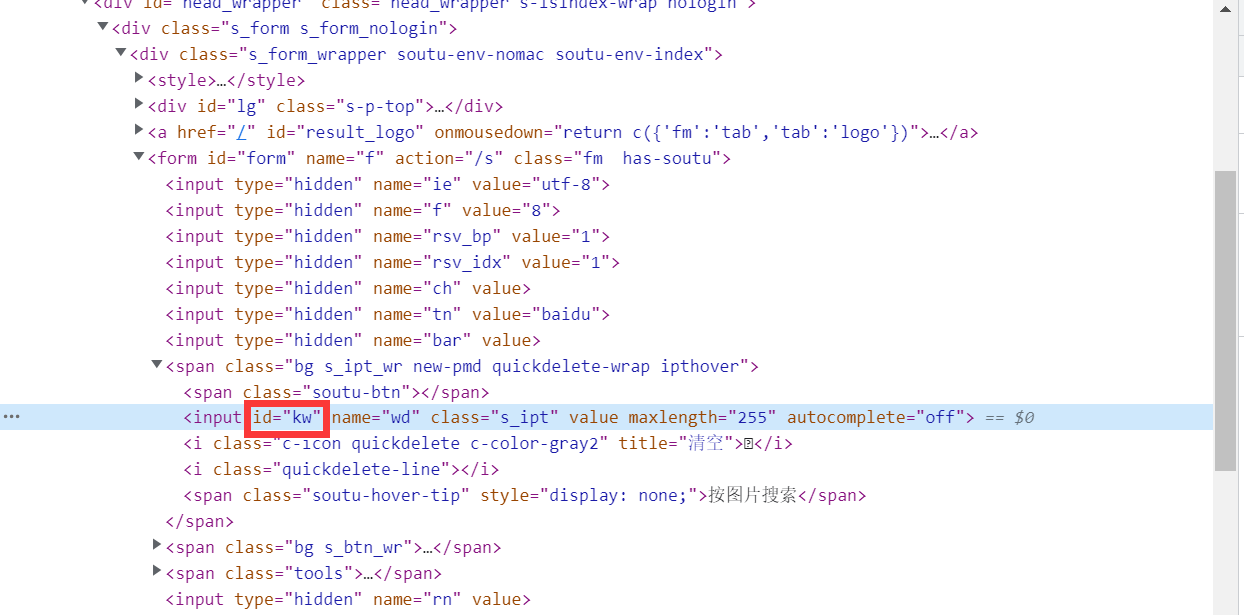
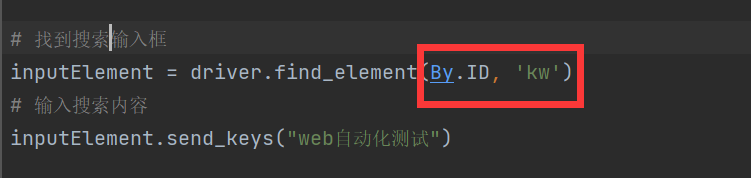
在前端,一般一个id值是唯一的,只属于一个元素
方式二:通过元素的class-By.CLASS_NAME
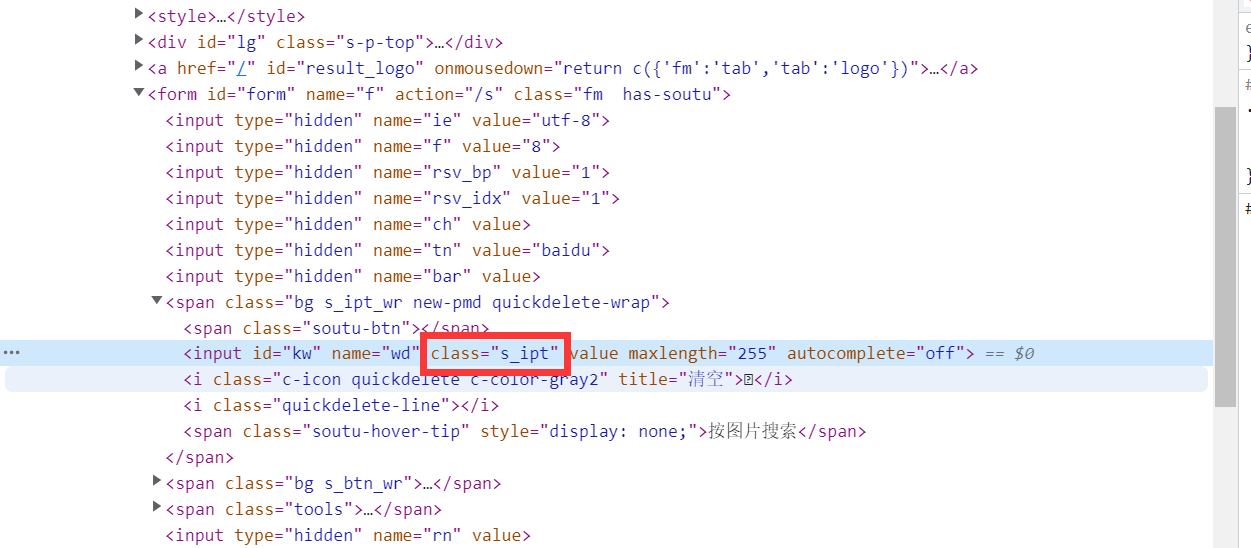
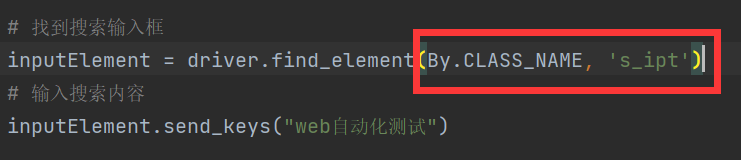
在前端,一般多个元素共用一个class
但 find_element 方法只返回第一个匹配到class的元素
坏处:当找不到元素则报错
如果想返回所有匹配到class的元素,可使用find_elements方法
返回的是一个元素列表,若只匹配到一个也是列表 通过列表下标的方式操作自己需要的元素
好处:当没有找到元素时不会报错,而是返回空列表 []
方式三:通过元素的name-BY.NAME
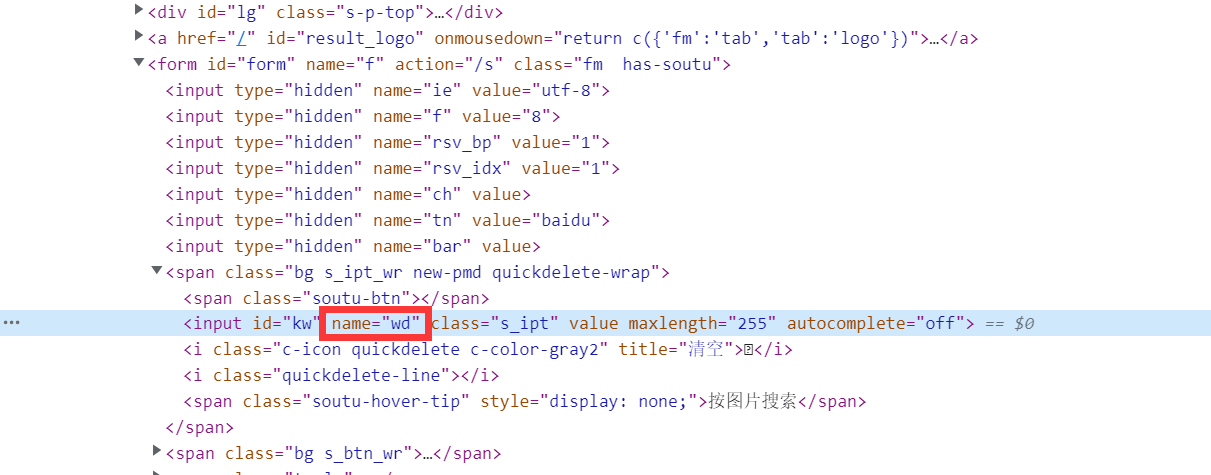
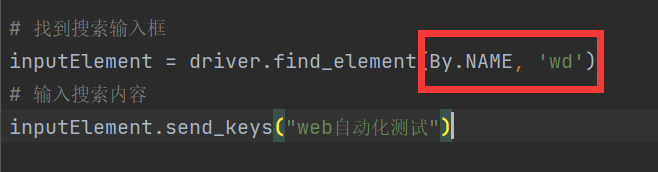
和class一样,也有可能有多个元素共用一个name
但 find_element 只返回第一个匹配到name的元素
想返回多个的话,和class一样,需要调用 find_elements 方法,这里不再赘述,写法和上面一致
方式四:通过元素标签-BY.TAG_NAME
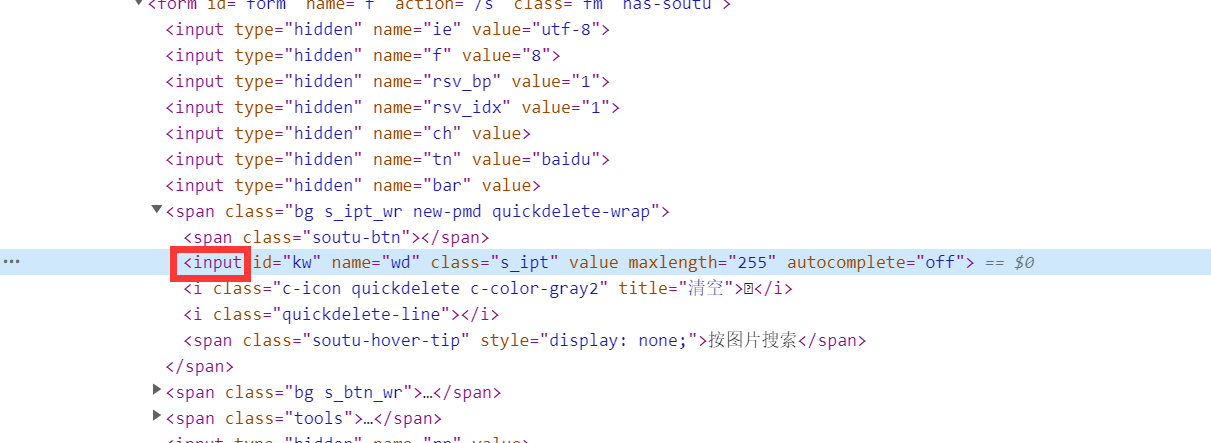
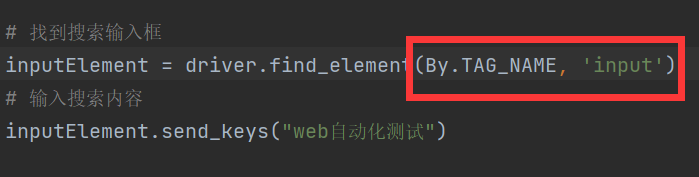
多个元素同种HTML标签见怪不怪了
同样的, find_element 返回第一个匹配到标签的元素
find_elements 可以返回所有匹配到标签的元素
方式五:通过超链接文本-BY.LINK_TEXT

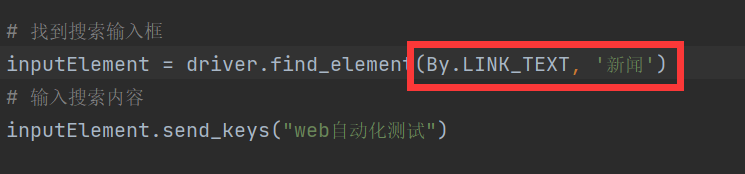
find_element 是精确匹配,需要文本完全相同才能匹配
若需要返回全部匹配到的元素,也需要用 find_elements
方式六:通过超链接文本(模糊匹配)-BY.PARTIAL_LINK_TEXT

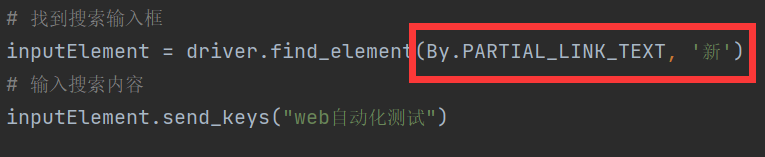
支持模糊匹配,包含文本则匹配成功
若需要返回全部匹配到的元素,也需要用 find_elements
方式七:通过xpath(万能,重点)
传送门:https://www.cnblogs.com/grysandefox/p/17274450.html
方式八:通过css选择器(万能,重点)
传送门:https://www.cnblogs.com/grysandefox/p/17274466.html
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号