结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
一、实验要求
结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
- 以fork和execve系统调用为例分析中断上下文的切换
- 分析execve系统调用中断上下文的特殊之处
- 分析fork子进程启动执行时进程上下文的特殊之处
- 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
二、实验过程
1.fork系统调用
- 负值:创建子进程失败。
- 零:返回到新创建的子进程。
- 正值:返回给父亲或调用者。该值包含新创建子进程的进程ID。
fork()函数又叫计算机程序设计中的分叉函数,它可以建立一个新进程,把当前的进程分为父进程和子进程,新进程称为子进程,而原进程称为父进程。fork调用一次,返回两次,这两个返回分别带回它们各自的返回值,其中在父进程中的返回值是子进程的PID,而子进程中的返回值则返回 0。因此,可以通过返回值来判定该进程是父进程还是子进程。还有一个很奇妙的是:fork函数将运行着的程序分成2个(几乎)完全一样的进程,每个进程都启动一个从代码的同一位置开始执行的线程。这两个进程中的线程继续执行,就像是两个用户同时启动了该应用程序的两个副本。
编写如下代码运行,测试fork函数
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc, char * argv[]) { int pid; /* fork another process */ pid = fork(); if (pid < 0) { /* error occurred */ fprintf(stderr,"Fork Failed!"); exit(-1); } else if (pid == 0) { /* child process */ printf("This is Child Process!\n"); } else { /* parent process */ printf("This is Parent Process!\n"); /* parent will wait for the child to complete*/ wait(NULL); printf("Child Complete!\n"); } }
结果如下:
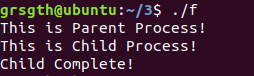
可以看到父进程先执行,然后阻塞自己,等待子进程执行结束后再继续运行。
Linux下用于创建进程的API有三个fork,vfork和clone,这三个函数分别是通过系统调用sys_fork,sys_vfork以及sys_clone实现的。而且这三个系统调用,都是通过do_fork来实现的,只是传入了不同的参数。
下面我们来重点看看do_fork的代码:
long do_fork(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct kernel_clone_args args = { .flags = (clone_flags & ~CSIGNAL), .pidfd = parent_tidptr, .child_tid = child_tidptr, .parent_tid = parent_tidptr, .exit_signal = (clone_flags & CSIGNAL), .stack = stack_start, .stack_size = stack_size, }; if (!legacy_clone_args_valid(&args)) return -EINVAL; return _do_fork(&args); }
long _do_fork(struct kernel_clone_args *args) { ... p = copy_process(NULL, trace, NUMA_NO_NODE, args); add_latent_entropy();
... trace_sched_process_fork(current, p); pid = get_task_pid(p, PIDTYPE_PID); nr = pid_vnr(pid); wake_up_new_task(p); ... put_pid(pid); return nr; }
通过copy_process创建子进程,然后用wake_up_new_task将⼦进程添加到就绪队列,最后返回进程id。

总结来说,进程的创建过程⼤致是⽗进程通过fork系统调⽤进⼊内核_do_fork函数,如下图所示复制进程描述符及相关进程资源(采⽤写时复制技术)、分配⼦进程的内核堆栈并对内核堆栈和thread等进程关键上下⽂进⾏初始化,最后将⼦进程放⼊就绪队列, fork系统调⽤返回;⽽⼦进程则在被调度执⾏时根据设置的内核堆栈和thread等进程关键上下⽂开始执⾏。
2.execve系统调用
execve() 系统调用的作用是运行另外一个指定的程序。它会把新程序加载到当前进程的内存空间内,当前的进程会被丢弃,它的堆、栈和所有的段数据都会被新进程相应的部分代替,然后会从新程序的初始化代码和 main 函数开始运行。同时,进程的 ID 将保持不变。
execve() 系统调用通常与 fork() 系统调用配合使用。从一个进程中启动另一个程序时,通常是先 fork() 一个子进程,然后在子进程中使用 execve() 变身为运行指定程序的进程。 例如,当用户在 Shell 下输入一条命令启动指定程序时,Shell 就是先 fork() 了自身进程,然后在子进程中使用 execve() 来运行指定的程序。
编写如下代码进行测试:
processimage.c
//用来替换进程映象的程序 #include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <unistd.h> int main(int args,char *argv[],char **environ) { int i; printf("I am a process image!\n"); printf("My pid = %d,parentId = %d\n",getpid(),getppid()); printf("uid = %d,gid = %d\n",getuid(),getgid()); for(i=0;i<args;i++) { printf("argv[%d]:%s\n",i,argv[i]); } }
execve.c
//execve程序实例,这里使用execve函数 #include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <unistd.h> int main(int args,char *argv[],char **environ) { pid_t pid; int stat_val; printf("Exec example!\n"); pid = fork(); switch(pid) { case -1: perror("Process Creation failed!\n"); exit(1); case 0: printf("Child process is running\n"); printf("My pid = %d,parentId = %d\n",getpid(),getppid()); printf("uid = %d,gid = %d\n",getuid(),getgid()); execve("processimage",argv,environ); printf("process never go to here!\n"); exit(0); default: printf("Parent process is running!\n"); break; } wait(&stat_val); exit(0); }
如下执行:
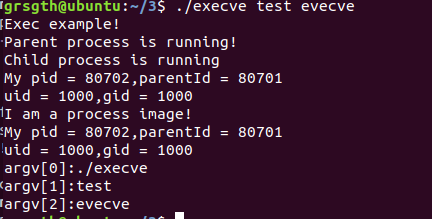
从执行的结果中可以看出,新进程保持了原来进程的ID,父进程ID,实际用户ID,实际组ID。同时我们还可以发现当调用新的程序后,原有的子程序的镜像被替代,不被执行了。
三、实验总结
进程调用fork()创建一个新的进程,新进程复制了父进程的task_struct(PCB,process control block,进程控制块),以及task_struct中的各个子模块,比如内核堆栈等,然后对各个子模块做了修改。系统调用通过eax寄存器保存返回值,fork()系统调用结束后从内核态返回两次,一次是父进程返回,一次是子进程返回,区分父子进程的方法就是看返回值是否为0,若为0,说明返回的是新进程,不为0返回的是父进程。
而调用execve()解析ELF文件,把ELF文件装入内存,修改进程的数据段代码段,修改进程的用户态堆栈(主要是把命令行参数和shell上下文加入到用户态堆栈)。修改进程内核堆栈(特别是内核堆栈的ip指针),进程从execve返回到用户态后ip指向ELF文件的main函数地址,用户态堆栈中包含了命令行参数和shell上下文环境。
exec系列的系统调用是把当前程序替换成要执行的程序,而fork用来产生一个和当前进程一样的进程(虽然通常执行不同的代码流)。通常运行另一个程序,而同时保留原程序运行的方法是,fork+exec。
Linux系统的整体运⾏过程,最基本和⼀般的场景是:正在运⾏的⽤户态进程X切换到⽤户态进程Y的过程。
1.正在运⾏的⽤户态进程X。
2.发⽣中断(包括异常、系统调⽤等), CPU完成以下动作。
save cs:eip/ss:esp/eflags:当前CPU上下⽂压⼊进程X的内核堆栈。
load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack):加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执⾏路径的起点。
3.SAVE_ALL,保存现场,此时完成了中断上下⽂切换,即从进程X的⽤户态到进程X的内核态。
4.中断处理过程中或中断返回前调⽤了schedule函数,其中的switch_to做了关键的进程上下⽂切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程(本例假定为进程Y)的内核堆栈,并完成了进程上下⽂所需的EIP等寄存器状态切换。详细过程⻅前述内容。
5.标号1,即前述3.18.6内核的swtich_to代码第50⾏“”1:\t“ ”(地址为switch_to中的“$1f”),之后开始运⾏进程Y(这⾥进程Y曾经通过以上步骤被切换出去,因此可以从标号1继续执⾏)。
6.restore_all,恢复现场,与(3)中保存现场相对应。注意这⾥是进程Y的中断处理过程中,⽽(3)中保存现场是在进程X的中断处理过程中,因为内核堆栈从进程X切换到进程Y了。
7.iret - pop cs:eip/ss:esp/eflags,从Y进程的内核堆栈中弹出(2)中硬件完成的压栈内容。此时完成了中断上下⽂的切换,即从进程Y的内核态返回到进程Y的⽤户态。
8.继续运⾏⽤户态进程Y。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号