
Python机器学习算法之K近邻算法
1.数据预处理
a.标准化
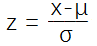
b.归一化

2.计算欧式距离
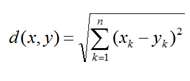
3.
<bound method NDFrame.head of accommodates bedrooms bathrooms beds price minimum_nights \ 0 4 1.0 1.0 2.0 $160.00 1 1 6 3.0 3.0 3.0 $350.00 2 2 1 1.0 2.0 1.0 $50.00 2 3 2 1.0 1.0 1.0 $95.00 1 4 4 1.0 1.0 1.0 $50.00 7 5 4 2.0 1.0 4.0 $99.00 1 6 4 2.0 2.0 2.0 $100.00 3 7 2 1.0 1.0 1.0 $100.00 1 8 2 1.0 1.5 1.0 $38.00 2 9 2 1.0 NaN 1.0 $71.00 2 10 4 2.0 1.5 2.0 $97.00 4 11 1 1.0 1.0 1.0 $55.00 3 12 2 1.0 1.0 1.0 $50.00 2 13 2 0.0 1.0 1.0 $99.00 7 14 2 1.0 NaN 1.0 $60.00 2 15 2 1.0 1.0 1.0 $52.00 1 16 1 1.0 1.0 1.0 $23.00 1 17 2 1.0 1.0 2.0 $200.00 1
3.算法实现
import pandas as pd
from sklearn.preprocessing import StandardScaler
from scipy.spatial import distance
dc_listings = pd.read_csv('listings.csv')
features = ['accommodates','bedrooms','bathrooms','beds','price','minimum_nights','maximum_nights','number_of_reviews']
dc_listings = dc_listings[features]
dc_listings['price'] = dc_listings.price.str.replace("\$|,",'').astype(float)
# 处理缺失值
dc_listings = dc_listings.dropna()
dc_listings[features] = StandardScaler().fit_transform(dc_listings[features]) #数据归一化
normalized_listings = dc_listings
# print(dc_listings.shape)
# normalized_listings.head()
# 分割训练集、测试集
norm_train_df = normalized_listings.copy().iloc[0:2792]
norm_test_df = normalized_listings.copy().iloc[2792:]
# print(norm_train_df.shape)
# print(norm_test_df.shape)
# 计算两个样本的欧氏距离
first_listing = normalized_listings.iloc[0][['accommodates','bathrooms']]
fifth_listing = normalized_listings.iloc[20][['accommodates','bathrooms']]
first_fifth_distance = distance.euclidean(first_listing,fifth_listing)
def predict_price_multivariate(new_listing_value,feature_columns):
temp_df = norm_train_df
temp_df['distance'] = distance.cdist(temp_df[feature_columns],[new_listing_value[feature_columns]]) #计算测试集合中某一个和训练集的欧式距离(多个属性)
temp_df = temp_df.sort_values('distance')
knn_5 = temp_df.price.iloc[:5] #取前5个最近邻,计算平均价格(预测)
predicted_price = knn_5.mean()
return(predicted_price)
cols = ['accommodates','bathrooms']
norm_test_df['predicted_price'] = norm_test_df[cols].apply(predict_price_multivariate,feature_columns=cols,axis=1)
norm_test_df['squared_error'] = (norm_test_df['predicted_price']-norm_test_df['price'])**2 #预测价格和真实价格对比
mse = norm_test_df['squared_error'].mean()
rmse = mse**(1/2)
print(rmse)
# 利用sklearn来实现KNN
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error
cols = ['accommodates','bathrooms']
knn = KNeighborsRegressor()
knn.fit(norm_train_df[cols],norm_train_df['price'])
two_features_predictions = knn.predict(norm_train_df[cols])
two_features_mse = mean_squared_error(norm_train_df['price'],two_features_predictions)
two_features_rmse = two_features_mse**(1/2)
print(two_features_rmse)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号