软件质量与测试第四周作业:wordCountPro
项目github地址:https://github.com/Asfalas/wcPro
1、PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
20 |
20 |
|
Estimate |
估计这个任务现需多少时间 |
5 |
5 |
|
Development |
开发 |
4天 |
5天 |
|
Analysis |
需求分析(包括学习新技术) |
60 |
90 |
|
Design Spec |
生成设计文档 |
30 |
30 |
|
Design Review |
设计复审(和同事审核文档) |
15 |
15 |
|
Coding Standard |
代码规范(为目前的开发制定合适的规范) |
15 |
10 |
|
Design |
具体设计 |
40 |
60 |
|
Coding |
具体编码 |
60 |
90 |
|
Code Review |
代码复审 |
20 |
20 |
|
Test |
测试(自我测试,修复代码,提交修改) |
60 |
120 |
|
Reporting |
报告 |
30 |
60 |
|
Test Report |
测试报告 |
20 |
40 |
|
Size Measurement |
计算工作量 |
5 |
10 |
|
Postmortem & Process Improvement Plan |
事后总结,并提出改进计划 |
5 |
10 |
|
|
合计 |
4天 |
5天 |
2、所负责接口的实现
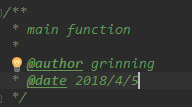
Main函数部分,创建输入类实例读取文件->创建处理过程实例处理文件->创建结果数据结构记录输出结果->创建输出实例将结果输出
/**
* main function
*
* @author grinning
* @date 2018/4/5
*/
public class Main {
public static void main(String[] args)
{
wcInput wci = new wcInput();
String inputFile = wci.judgeInput(args);
try {
wci.readFileContent();
} catch (IOException e) {
System.out.println("该文件不存在");
return;
}
String fileContent = wci.getFileContent();
wcMainProcess wcmp = new wcMainProcess(fileContent);
Map<String, Integer> result = wcmp.countWordFrequency();
wcOutput wco = new wcOutput();
wco.output(result);
for(Map.Entry<String, Integer> r : result.entrySet())
{
System.out.println("K: "+r.getKey()+",V: "+r.getValue());
}
}
}
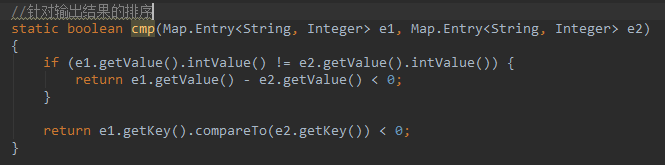
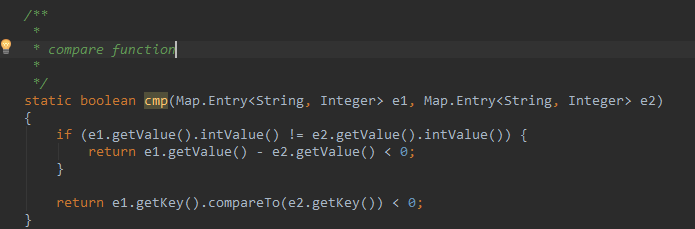
在输出部分,cmp方法负责比较两个词的排序大小,若前一词的值小于后一词的值则返回true
/**
*
* compare function
*
*/
static boolean cmp(Map.Entry<String, Integer> e1, Map.Entry<String, Integer> e2)
{
if (e1.getValue().intValue() != e2.getValue().intValue()) {
return e1.getValue() - e2.getValue() < 0;
}
return e1.getKey().compareTo(e2.getKey()) < 0;
}
还是在wcOutput类中,swap方法将两个词的排序序号交换
public static void swap(Map.Entry<String, Integer> a[], int e1, int e2)
{
Map.Entry<String, Integer> t = a[e1];
a[e1] = a[e2];
a[e2] = t;
}
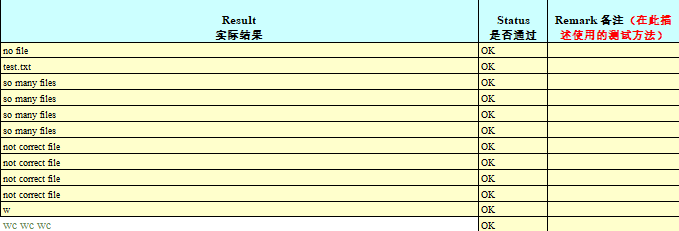
3、测试用例的设计
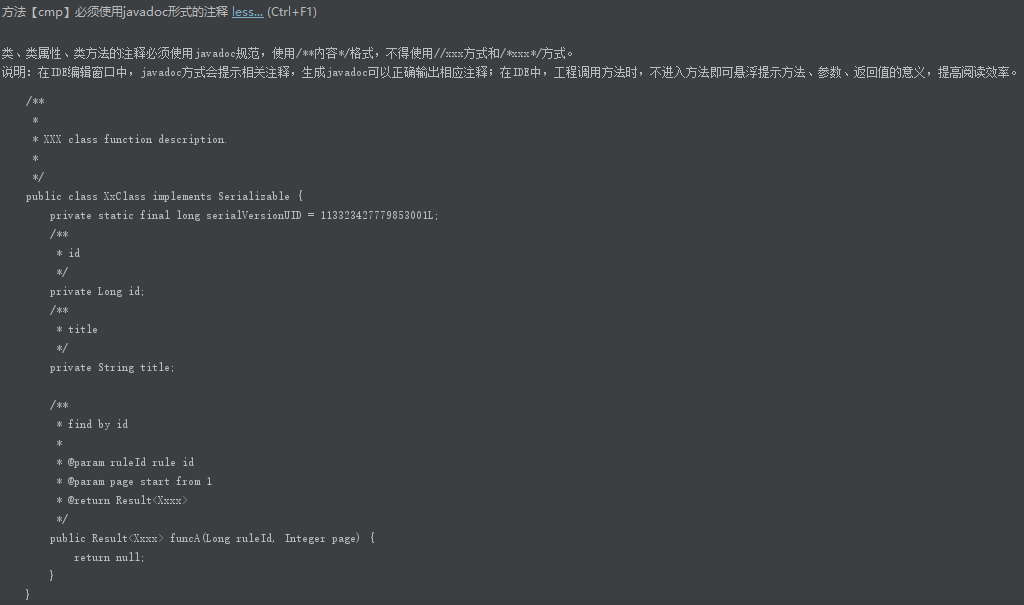
测试需求分析阶段,我们只有需求文档,所以编写测试用例的唯一依据就是需求文档,因此在进行用例编写之前一定要进行需求分析,需求分析的主要工作就是:了解需求的整个实现背景;分析需求的合理性;明确需求的范围,挖掘需求文档中隐藏的需求;在通过需求交底的过程,确定开发的初步实现思路和方法,随着测试需求分析的深入,列出需求的框架,包括测试范围即各个功能点,测试的场景等;确定一些测试可以提前介入的工作等;需要说明的是对于需求中的问题一定要记录下来,找需求确认,需求漏掉的或者存在问题的地方,开发和测试更容易漏掉,而且遗漏的需求很有可能会使得项目整体业务逻辑发生变化,一定要及时提前确认。
根据测试需求分析得到的需求框架,梳理细化测试点,这里的测试点虽然粗,但是不应该有遗漏,这是进行测试点细化的前提。根据测试点,细化出具体的测试用例,要注意各个点的组合测试的情况,还要注意各个测试点的反向测试的情况。
在细化测试点的时候,我们可以要参考以前写好的公共测试用例,甚至可以直接引用,这样既可以避免一些不必要的时间浪费,但是参考不等于照搬,在引用的同时,也一定要思考本次需求自己特有的测试点。
另外需要考虑的就是测试点细化到什么程度的问题,也就是一个度的问题,我们要把握好测试点细化的一个度的问题,太粗的测试点没有指导意义,太细的测试点容易让我们纠的太细,忽略整体的测试,反而也起不到一个指导的效果,所以一定要把握好测试点细化的度。
4、测试质量和被测模块的质量
因为本次任务代码量并不大,测试用例需要达到人均20的最低数量要求,所以针对所有的测试点,测试用例基本都覆盖到了,所以测试质量经评定属于较高水准。
而被测试模块的测试结果与预期都相符合,被测模块的质量也符合期望。

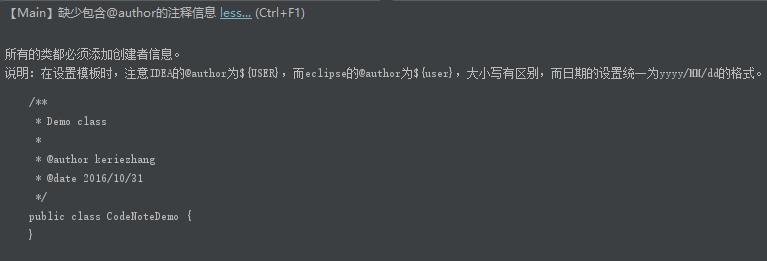
5、扩展任务:静态测试
①在IDEA安装alibaba Java coding guidelines,settings->browse repositories->alibaba Java coding guidelines install。
②重启IDEA后,得到扫描结果。
修改后:
第二个扫描结果:
修改后:
6、高级功能
6.1 测试数据集设计思路
使用文件大小比较大的数据集来对本程序进行压力测试。我使用了英文的电子书籍《了不起的盖茨比》作为构造测试集,分别构造出了大小为500k,1m,2m,4m,8m,16m的数据集,同时使用了参数化方法对Main函数进行集成的多次测试,观察运行时间。
6.2 优化前性能指标
程序的大小以及对应的时间消耗
6.3 同行评审过程
小组成员:张付俊(U201517046)、孙帅(U201517043)、张瑞祺(U201517049)、文宇凡(U201517053)
人员角色分工:张付俊(作者、讲解员)、孙帅(作者,评审员)、张瑞祺(作者,主持人)、文宇凡(作者、评审员)
评审目的:确保要发布质量可靠的代码,发现各种类型的错误,提高代码质量、规范性、一致性和可维护性,提高代码效能。
评审意见:
孙帅:主要对于程序的代码规范角度与部分功能模块角度提出意见
文宇凡:主要对于代码的功能实现角度提出意见
评审结论:
孙帅:(1)代码注释部分较少。可读性较差。
(2)针对输出测试类方法代码存在大量冗余,需要改进。
文宇凡:
(1)将输入字符串传入核心处理模块导致两遍扫描文本,可能会使效率下降,可以一边读文本一边进行排序工作。
(2)代码规范性存在许多问题需要改进。
总体结论:代码需要作者做进一步改进
本次评审的不足:
(1)由于时间较为紧凑,部分细节的评审并未做到面面俱到。
(2)因为代码量较少,评审内容有限,不能发现作者的隐藏问题。
7、自己的小组贡献分
因为个人事务的原因,本次结队作业承担任务相较队友来说确实较少,但也全程参与了,所以给自己打0.22的小组贡献分
8、参考链接
静态代码工具检查 http://www.cnblogs.com/ningjing-zhiyuan/p/7928911.html
IDEA插件安装README(中文版) https://github.com/alibaba/p3c/blob/master/idea-plugin/README_cn.md

 浙公网安备 33010602011771号
浙公网安备 33010602011771号