Java 多线程(六):容器
Java 多线程(六):容器
作者:Grey
原文地址:
Vector/HashTable
这两个都加了锁,一般不推荐使用。
ConcurrentHashMap
ConcurrentHashMap 写效率未必比 HashMap,HashTable 高,但是读效率比这两者要高。
示例代码:
package git.snippets.juc;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
/**
* ConcurrentHashMap写效率未必比HashMap,HashTable高,但是读效率比这两者要高
*/
public class HashTableVSCHM {
public static final int COUNT = 1000000;
public static final int THREAD_COUNT = 100;
static UUID[] keys = new UUID[COUNT];
static UUID[] values = new UUID[COUNT];
static {
for (int i = 0; i < COUNT; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
enum TYPE {
HASHTABLE, CHM, HASHMAP
}
public static Map<UUID, UUID> choose(TYPE type) {
switch (type) {
case HASHMAP:
Collections.synchronizedMap(new HashMap<>());
case HASHTABLE:
return new Hashtable<>();
default:
return new ConcurrentHashMap<>();
}
}
public static void main(String[] args) {
System.out.println("...use hashtable....");
benchmark(choose(TYPE.HASHTABLE));
System.out.println("...use HashMap....");
benchmark(choose(TYPE.HASHMAP));
System.out.println("...use ConcurrentHashMap....");
benchmark(choose(TYPE.CHM));
}
public static void benchmark(Map<UUID, UUID> hashtable) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for (int i = 0; i < threads.length; i++) {
threads[i] = new MyThread(i * COUNT / THREAD_COUNT, hashtable);
}
Arrays.stream(threads).forEach(thread -> thread.start());
Arrays.stream(threads).forEach(thread -> {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.currentTimeMillis();
System.out.println("size : " + hashtable.size());
System.out.println("write cost " + (end - start) + "ms");
start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 10000000; j++) {
hashtable.get(keys[10]);
}
});
}
Arrays.stream(threads).forEach(thread -> thread.start());
Arrays.stream(threads).forEach(thread -> {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
end = System.currentTimeMillis();
System.out.println("read cost " + (end - start) + "ms");
}
static class MyThread extends Thread {
int start;
int gap = COUNT / THREAD_COUNT;
Map<UUID, UUID> map;
MyThread(int start, Map<UUID, UUID> map) {
this.start = start;
this.map = map;
}
@Override
public void run() {
for (int i = start; i < start + gap; i++) {
map.put(keys[i], values[i]);
}
}
}
}
输出:
...use hashtable....
size : 1000000
write cost 349ms
read cost 28322ms...
use HashMap....
size : 1000000
write cost 203ms
read cost 27590ms...
use ConcurrentHashMap....
size : 1000000
write cost 739ms
read cost 785ms
关于ConcurrentHash和HashMap的一些分析,可以参考这篇文章
ConcurrentLinkedQueue
ConcurrentLinkedQueue底层用的是CAS操作。比Vector效率高。
代码示例见:
package git.snippets.juc;
import java.util.Vector;
import java.util.concurrent.ConcurrentLinkedQueue;
/**
* ConcurrentLinkedQueue底层用的是CAS操作。比Vector效率高,
*
* @author Grey
*/
public class ConcurrentLinkedQueueVSVector {
public static void main(String[] args) {
ConcurrentLinkedQueue<String> tickets = new ConcurrentLinkedQueue<>();
Vector<String> tickets2 = new Vector<>();
for (int i = 0; i < 10000; i++) {
tickets.add("票编号:" + i);
tickets2.add("票编号:" + i);
}
useConcurrentLinkedQueue(tickets);
useVector(tickets2);
}
public static void useConcurrentLinkedQueue(ConcurrentLinkedQueue<String> tickets) {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
while (true) {
String s = tickets.poll();
if (s == null) {
break;
} else {
System.out.println("销售了--" + s);
}
}
}).start();
}
}
public static void useVector(Vector<String> tickets) {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
while (tickets.size() > 0) {
System.out.println("销售了--" + tickets.remove(0));
}
}).start();
}
}
}
CopyOnWriteList
1.CopyOnWriteList内部也是通过数组来实现的,在向CopyOnWriteList添加元素时会复制一个新的数组,写数据时在新数组上进行,读操作在原数组上进行。
2.写操作会加锁,防止出现并发写入丢失数据的问题。
3.写操作结束之后会把原数组指向新数组。
4.CopyOnWriteList允许在写操作时来读取数据,大大提高了读的性能,因此适合读多写少的应用场景,CopyOnWriteList会比较占内存,同时可能读到的数据不是实时最新的数据,所以不适合实时性要求很高的场景。
代码示例见
package git.snippets.juc;
import java.util.*;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* 写时复制容器 copy on write
* 多线程环境下,写时效率低,读时效率高
* 适合写少读多的环境
* !!!! 好像和Vector执行的时间差不多
*
* @author zenghui
* @date 2020/3/24
*/
public class CopyOnWriteListVSVector {
static final Random random = new Random();
static List<Integer> list = null;
private enum TYPE {
VECTOR, COPYONWRITELIST
}
public static List<Integer> choose(TYPE type, ArrayList<Integer> list) {
switch (type) {
case VECTOR:
return new Vector<>(list);
case COPYONWRITELIST:
return new CopyOnWriteArrayList<>(list);
default:
return new CopyOnWriteArrayList<>(list);
}
}
public static void main(String[] args) {
useVector();
useCopyOnWriteList();
}
public static void useCopyOnWriteList() {
System.out.println("use CopyOnWriteList...");
List<Integer> list = initData(TYPE.COPYONWRITELIST);
getData(list);
}
public static List<Integer> initData(TYPE type) {
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < (100 * 100000); i++) {
arrayList.add(i);
}
return choose(type, arrayList);
}
public static void useVector() {
System.out.println("use vector...");
List<Integer> list = initData(TYPE.VECTOR);
getData(list);
}
public static void getData(List<Integer> list) {
//----------------读数据--------------
long start2 = System.currentTimeMillis();
Thread[] threads = new Thread[100];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 100000; j++) {
list.get(random.nextInt(9999));
}
});
}
Arrays.asList(threads).forEach(t -> t.start());
Arrays.asList(threads).forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end2 = System.currentTimeMillis();
System.out.println("time is :" + (end2 - start2));
}
}
ConcurrentSkipListMap/TreeMap
-
ConcurrentSkipListMap:高并发且排序,底层是跳表实现
-
TreeMap:底层是红黑树,排序
Queue VS List
-
Queue 中
offer和add方法区别在于:offer方法成功与否用返回值判断,add方法如果加不进会抛异常 -
Queue 中,
poll是取并remove这个元素put方法:如果满,阻塞。take方法:如果空,阻塞。底层用的是park/unpark -
Queue 提供了对线程友好的API:
offer,peek,poll -
BlockingQueue 中的
put和take方法是阻塞的。
示例代码如下
package git.snippets.juc;
import java.util.Random;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
/**
* @author zenghui
* @date 2020/3/26
*/
public class BlockingQueueUsage {
static final Random random = new Random();
// static BlockingQueue<String> queue = new LinkedBlockingQueue<>();
static BlockingQueue<String> queue = new ArrayBlockingQueue<>(100);
public static void main(String[] args) {
new Thread(() -> {
for (int i = 0; i < 100; i++) {
try {
queue.put("a" + i); //如果满了,就会等待
TimeUnit.MILLISECONDS.sleep(random.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "p1").start();
for (int i = 0; i < 5; i++) {
new Thread(() -> {
for (; ; ) {
try {
System.out.println(Thread.currentThread().getName() + " take -" + queue.take()); //如果空了,就会等待
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "c" + i).start();
}
}
}
DelayQueue
用于按时间进行任务调度。
示例代码如下
package git.snippets.juc;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
/**
* @author zenghui
* @date 2020/3/26
*/
public class DelayQueueUsage {
static BlockingQueue<MyTask> tasks = new DelayQueue<>();
public static void main(String[] args) throws InterruptedException {
long now = System.currentTimeMillis();
MyTask t1 = new MyTask("t1", now + 1000);
MyTask t2 = new MyTask("t2", now + 2000);
MyTask t3 = new MyTask("t3", now + 1500);
MyTask t4 = new MyTask("t4", now + 2500);
MyTask t5 = new MyTask("t5", now + 500);
tasks.put(t1);
tasks.put(t2);
tasks.put(t3);
tasks.put(t4);
tasks.put(t5);
System.out.println(tasks);
for (int i = 0; i < 5; i++) {
System.out.println(tasks.take());
}
}
static class MyTask implements Delayed {
String name;
long runningTime;
MyTask(String name, long rt) {
this.name = name;
this.runningTime = rt;
}
@Override
public int compareTo(Delayed o) {
return Long.compare(this.getDelay(TimeUnit.MILLISECONDS), o.getDelay(TimeUnit.MILLISECONDS));
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(runningTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
@Override
public String toString() {
return name + " " + runningTime;
}
}
}
SynchronousQueue
SynchronousQueue 也是一个队列,但它的特别之处在于它内部没有容器,一个生产线程,当它生产产品(即put的时候),如果当前没有人想要消费产品(即当前没有线程执行take),此生产线程必须阻塞,等待一个消费线程调用take操作,take操作将会唤醒该生产线程,同时消费线程会获取生产线程的产品(即数据传递)
示例代码如下
package git.snippets.juc;
import java.util.concurrent.SynchronousQueue;
/**
* @author zenghui
* @date 2020/3/26
*/
public class SynchronousQueueUsage {
public static void main(String[] args) throws InterruptedException {
final SynchronousQueue<Integer> queue = new SynchronousQueue<>();
Thread producer = new Thread(() -> {
System.out.println("put thread start");
try {
queue.put(1);
} catch (InterruptedException e) {
}
System.out.println("put thread end");
});
Thread consumer = new Thread(() -> {
System.out.println("take thread start");
try {
System.out.println("take from putThread: " + queue.take());
} catch (InterruptedException e) {
}
System.out.println("take thread end");
});
producer.start();
Thread.sleep(1000);
consumer.start();
}
}
输出结果如下
put thread start
take thread start
put thread end
take from putThread: 1
take thread end
从结果可以看出,生产者线程执行put(1)后就被阻塞了,只有消费线程线程进行了消费,put线程才可以返回。可以认为这是一种线程与线程间一对一传递消息的模型。
更多内容参考:SynchronousQueue原理解析
PriorityQueue
默认是小根堆
如有需要,可以自己实现比较器
TransferQueue
transfer方法是执行然后等待取走
示例代码见:
package git.snippets.juc;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedTransferQueue;
public class TransferQueueUsage {
static LinkedTransferQueue<String> lnkTransQueue = new LinkedTransferQueue<>();
public static void main(String[] args) {
ExecutorService exService = Executors.newFixedThreadPool(2);
Producer producer = new Producer();
Consumer consumer = new Consumer();
exService.execute(producer);
exService.execute(consumer);
exService.shutdown();
}
static class Producer implements Runnable {
@Override
public void run() {
for (int i = 0; i < 3; i++) {
try {
System.out.println("Producer is waiting to transfer...");
lnkTransQueue.transfer("A" + i);
System.out.println("producer transferred element: A" + i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class Consumer implements Runnable {
@Override
public void run() {
for (int i = 0; i < 3; i++) {
try {
System.out.println("Consumer is waiting to take element...");
String s = lnkTransQueue.take();
System.out.println("Consumer received Element: " + s);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
多线程打印A1B2C3
可以用如下方式实现:
使用wait,notify
使用LockSupport
使用volatile
使用BlockingQueue
使用ReentrantLock的Condition
使用TransferQueue
代码如下
package git.snippets.juc;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedTransferQueue;
import java.util.concurrent.TransferQueue;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.LockSupport;
import java.util.concurrent.locks.ReentrantLock;
/**
* 要求线程打印A1B2C3
*
* @author <a href="mailto:410486047@qq.com">Grey</a>
* @date 2021/4/25
* @since
*/
public class A1B2C3 {
private static final char[] a = {'A', 'B', 'C', 'D', 'E'};
private static final char[] b = {'1', '2', '3', '4', '5'};
private volatile static boolean flag = false;
private static Thread t1;
private static Thread t2;
public static void main(String[] args) {
useTransferQueue();
useCondition();
useBlockingQueue();
useVolatile();
useWaitNotify();
useLockSupport();
}
private static void useTransferQueue() {
System.out.println("use transfer queue..");
TransferQueue<Character> queue = new LinkedTransferQueue<>();
t1 = new Thread(() -> {
for (int i = 0; i < a.length; i++) {
queue.offer(a[i]);
try {
System.out.print(queue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2 = new Thread(() -> {
for (int i = 0; i < b.length; i++) {
try {
System.out.print(queue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
queue.offer(b[i]);
}
});
t1.start();
t2.start();
join();
}
/**
* 使用ReentrainLock的Condition
*/
private static void useCondition() {
System.out.println("use condition...");
ReentrantLock lock = new ReentrantLock();
Condition condition = lock.newCondition();
t1 = new Thread(() -> {
lock.lock();
for (int i = 0; i < a.length; i++) {
System.out.print(a[i]);
condition.signal();
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
condition.signal();
lock.unlock();
});
t2 = new Thread(() -> {
lock.lock();
for (int i = 0; i < b.length; i++) {
System.out.print(b[i]);
condition.signal();
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
condition.signal();
lock.unlock();
});
t1.start();
t2.start();
join();
}
/**
* 使用BlockingQueue
*/
private static void useBlockingQueue() {
System.out.println("use blocking queue...");
BlockingQueue<Character> q1 = new ArrayBlockingQueue<>(1);
BlockingQueue<Character> q2 = new ArrayBlockingQueue<>(1);
t1 = new Thread(() -> {
for (int i = 0; i < a.length; i++) {
q2.offer(a[i]);
try {
System.out.print(q1.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2 = new Thread(() -> {
for (int i = 0; i < b.length; i++) {
try {
System.out.print(q2.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
q1.offer(b[i]);
}
});
t1.start();
t2.start();
join();
}
/**
* 使用volatile
*/
public static void useVolatile() {
System.out.println("use volatile...");
t1 = new Thread(() -> {
for (int i = 0; i < a.length; i++) {
while (flag) {
}
System.out.print(a[i]);
flag = !flag;
}
});
t2 = new Thread(() -> {
for (int i = 0; i < b.length; i++) {
while (!flag) {
}
System.out.print(b[i]);
flag = !flag;
}
});
t1.start();
t2.start();
join();
}
/**
* 使用wait和notify
*/
public static void useWaitNotify() {
System.out.println("use wait and notify");
final Object o = new Object();
t1 = new Thread(() -> {
synchronized (o) {
for (int i = 0; i < a.length; i++) {
System.out.print(a[i]);
o.notify();
try {
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
});
t1.start();
t2 = new Thread(() -> {
synchronized (o) {
for (int i = 0; i < b.length; i++) {
System.out.print(b[i]);
o.notify();
try {
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
});
t2.start();
join();
}
/**
* 使用LockSupport
*/
public static void useLockSupport() {
System.out.println("use LockSupport...");
t1 = new Thread(() -> {
for (int i = 0; i < a.length; i++) {
System.out.print(a[i]);
LockSupport.unpark(t2);
LockSupport.park();
}
LockSupport.unpark(t2);
});
t1.start();
t2 = new Thread(() -> {
for (int i = 0; i < b.length; i++) {
System.out.print(b[i]);
LockSupport.unpark(t1);
LockSupport.park();
}
LockSupport.unpark(t1);
});
t2.start();
join();
}
public static void join() {
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println();
}
}
容器依赖图
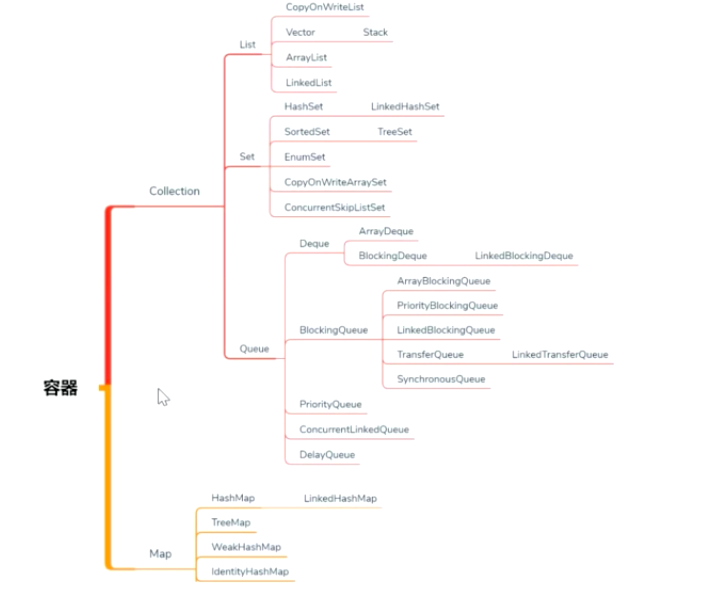
说明
本文涉及到的所有代码和图例
更多内容见:Java 多线程
参考资料
本文来自博客园,作者:Grey Zeng,转载请注明原文链接:https://www.cnblogs.com/greyzeng/p/14176141.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号