(六)DQL——聚合函数
聚集函数,它是对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值。
1. 聚集函数
SQL中的聚集函数一共包括5个:
COUNT(role_assist)会忽略值为NULL的数据行,而COUNT(*)只是统计数据行数,不管某个字段是否为NULL。- AVG、MAX、MIN等聚集函数会自动忽略值为NULL的数据行
- MAX和MIN函数也可以用于字符串类型数据的统计,如果是英文字母,则按照A—Z的顺序排列,越往后,数值越大。如果是汉字则按照全拼拼音进行排列
查询最大生命值大于6000的英雄数量。
select count(*) from heros where hp_max > 6000
查询最大生命值大于6000,且有次要定位的英雄数量,需要使用COUNT函数。
select count(role_assist) from heros where hp_max > 6000
查询射手(主要定位或者次要定位是射手)的最大生命值的最大值是多少,需要使用MAX函数。
select max(dp_max) from heros where role_main = '射手' or role_assist = '射手'
射手(主要定位或者次要定位是射手)的英雄数、平均最大生命值、法力最大值的最大值、攻击最大值的最小值,以及这些英雄总的防御最大值等汇总数据。
select count(*), max(hp_max), avg(hp_max), min(attack_max), sum(defense_max) from heros where role_main = '射手' or role_assist = '射手'
统计最大名字和最小名字
select min(convert(name using gbk)), min(convert(name using gbk)) from heros
统计不同生命最大值英雄的平均生命最大值,保留小数点后两位。
select round(avg(distinct hp_max), 2) from heros
2. having和group by
group by: 对数据进行分组,并进行聚集统计, 如果字段为NULL,也会被列为一个分组。
Having: 根据条件过滤分组。
having vs where
HAVING的作用和WHERE一样,都是起到过滤的作用,只不过WHERE是用于数据行,而HAVING则作用于分组。
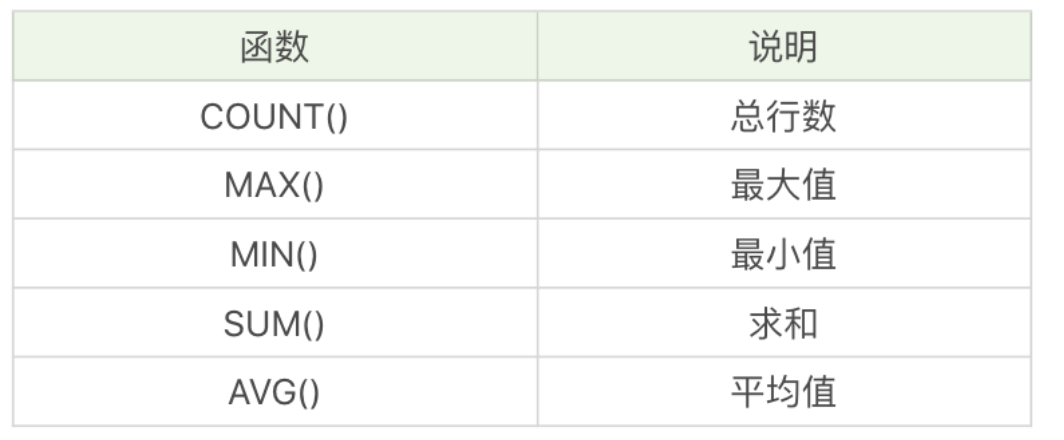
对英雄按照次要定位进行分组,并统计每组英雄的数量。
select count(*), role_assist from heros group by role_assist
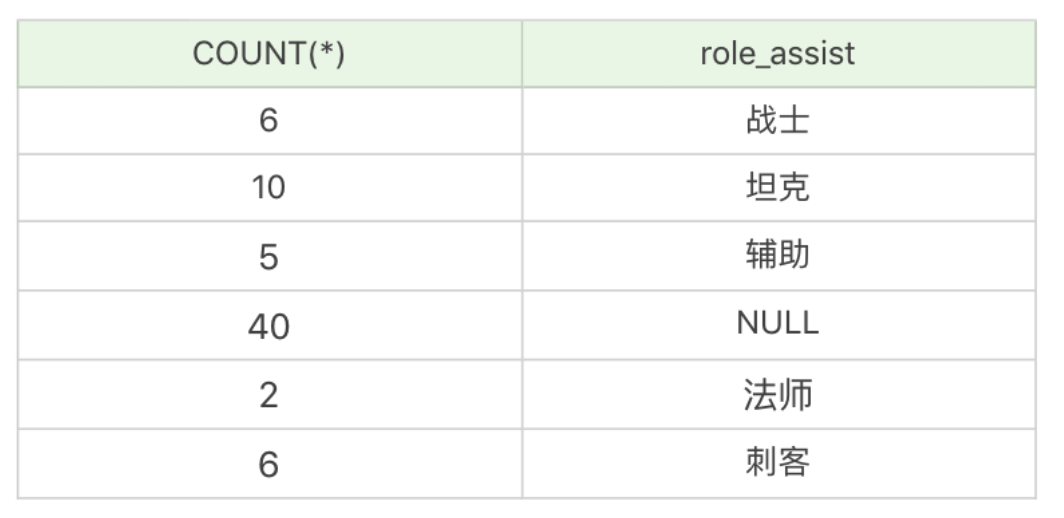
我们想要按照英雄的主要定位、次要定位进行分组,查看这些英雄的数量,并按照这些分组的英雄数量从高到低进行排序。
select count(*) as num, role_main, role_assist from heros group by role_main, role_assist order by num desc
要获取的是英雄的数量、主要定位和次要定位,然后按照英雄的主要定位和次要定位进行分组,同时我们要对分组中的英雄数量进行筛选,选择大于5的分组,然后按照英雄数量从高到低进行排序
select count(*) as num, role_main, role_assist from heros group role_main, role_assist having num > 5 order by num desc
要获取的是英雄的数量、主要定位和次要定位,筛选最大生命值大于6000的英雄,按照主要定位、次要定位进行分组,并且显示分组中英雄数量大于5的分组,按照数量从高到低进行排序。
select count(*) as num, role_main, role_assist from heros where hp_max > 6000 group role_main, role_assist having num >5 order by num desc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号