


idea上的maven中的pom.xml文件<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.it18zhang</groupId>
<artifactId>HdfsDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-resourcemanager</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.anarres.lzo</groupId>
<artifactId>lzo-hadoop</artifactId>
<version>1.0.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
</dependencies>
</project>
mapper
package com.it18zhang.hdfs.mr.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
*
* Mapper
* */
public class WorldMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text keyOut = new Text();
IntWritable valueOut = new IntWritable();
String[] arr = value.toString().split(" ");
for (String s : arr){
keyOut.set(s);
valueOut.set(1);
context.write(keyOut,valueOut);
}
}
}
reducer
package com.it18zhang.hdfs.mr.mr; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /* * Reducer * */ public class Worldreducer extends Reducer<Text,IntWritable,Text,IntWritable> { protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0 ; for (IntWritable iw : values){ count = count + iw.get() ; } context.write(key,new IntWritable(count)); } }
worldcount
package com.it18zhang.hdfs.mr.mr; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WorldApp { public static void main(String[] args) throws Exception { Configuration conf = new Configuration() ; //conf.set("fs.defaultFS","file:///"); Job job = Job.getInstance(conf); if(args.length > 1) { FileSystem.get(conf).delete(new Path(args[1])); } //设置job的各种属性 job.setJobName("WorldApp"); //作业名称 job.setJarByClass(WorldApp.class);//搜索类 job.setInputFormatClass(TextInputFormat.class);//设置输入格式 //添加输入路径 FileInputFormat.addInputPath(job,new Path(args[0])); //添加输出路径 FileOutputFormat.setOutputPath(job,new Path(args[1])); job.setMapperClass(WorldMapper.class); //Mapper类 job.setReducerClass(Worldreducer.class); //Reduce类 job.setNumReduceTasks(1); //reduce个数 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.waitForCompletion(true); } }
本地模式 需要将
//conf.set("fs.defaultFS","file:///");
前面的//去掉 需要设置文件位置
我的文件输入输出位置是在
![]()

words.txt里面的内容
hello world tom
hello tom world
tom hello world
how are you
开始设置文件输入输出位置,先运行一下WorldApp.java
再点击Run--->edit Configurations
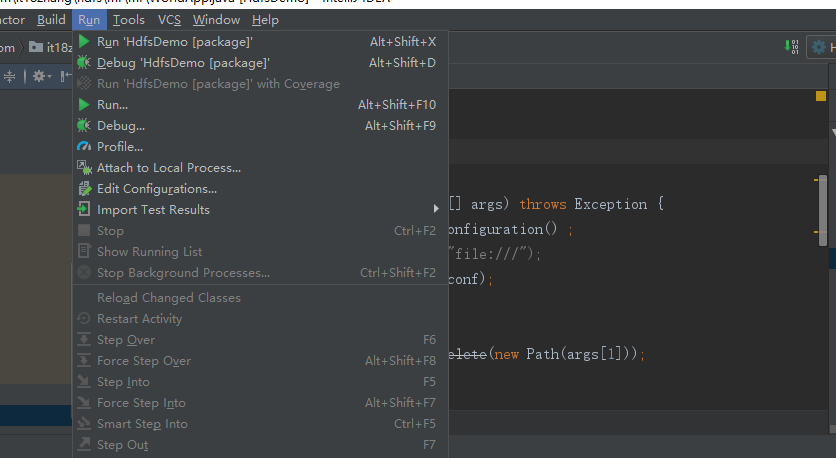
左侧applications下是WorldApp ,在Program arguments 输入你的文件位置,格式见下图 (注意不应该出现中文字符)
开始两个bug的调试
第一个bug是指在windows上出现 ,具体如下 为防止链接丢失 粘贴点关键信息
https://www.linuxidc.com/wap.aspx?cid=9&cp=2&nid=96531&p=4&sp=753
2013-9-3019:25:02 org.apache.hadoop.security.UserGroupInformation doAs
严重: PriviledgedActionExceptionas:Administrator cause:java.io.IOException: Failed to set permissions of path:\tmp\hadoop-Administrator\mapred\staging\Administrator1702422322\.staging to0700
Exception inthread "main" java.io.IOException: Failed to set permissions of path:\tmp\hadoop-Administrator\mapred\staging\Administrator1702422322\.staging to0700
atorg.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:689)
atorg.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:662)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509)
atorg.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344)
atorg.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116)
atorg.apache.hadoop.mapred.JobClient$2.run(JobClient.java:856)
atorg.apache.hadoop.mapred.JobClient$2.run(JobClient.java:850)
atjava.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
atorg.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121)
atorg.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:850)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:824)
atorg.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1261)
atorg.conan.myhadoop.mr.WordCount.main(WordCount.java:78)
这个错误是win中开发特有的错误,文件权限问题,在Linux下可以正常运行。
解决方法是,修改/hadoop-1.2.1/src/core/org/apache/hadoop/fs/FileUtil.java文件
688-692行注释,然后重新编译源代码,重新打一个hadoop.jar的包。
685private static void checkReturnValue(boolean rv, File p,
686 FsPermissionpermission
687 )throws IOException {
688 /*if (!rv) {
689 throw new IOException("Failed toset permissions of path: " + p +
690 " to " +
691 String.format("%04o",permission.toShort()));
692 }*/
693 }
注:为了方便,我直接在网上下载的已经编译好的hadoop-core-1.2.1.jar包
我们还要替换maven中的hadoop类库。
~cp lib/hadoop-core-1.2.1.jarC:\Users\licz\.m2\repository\org\apache\hadoop\hadoop-core\1.2.1\hadoop-core-1.2.1.jar
至于修改好的hadoop-core-1.2.1.jar ,我用的是https://download.csdn.net/download/yunlong34574/7079951
我分享一下
链接:https://pan.baidu.com/s/1pswB27oOnlWCXR5iRn_qKA
提取码:p1v6
第二个bug是没有设置VM options 类似以下
http://mail-archives.apache.org/mod_mbox/hadoop-mapreduce-user/201406.mbox/%3C1530609F-0168-4933-AC87-8F78395C83BB%40gmail.com%3E
解决办法,看以下VM options 的配置 hadoop-2.7.3.tar.gz解压后的文件在里面去找native
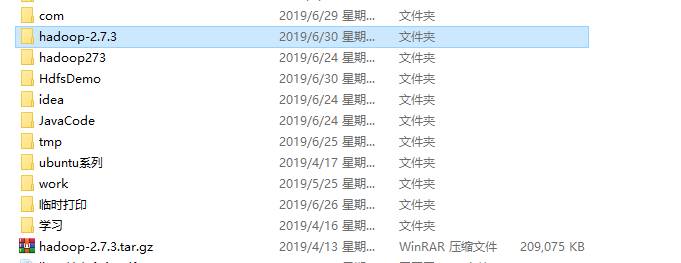
我在运行时就出现这两个问题比较难解决
运行结果如下
运行会出现的警告忽视类似于
六月 30, 2019 11:01:08 上午 org.apache.hadoop.util.NativeCodeLoader <clinit>
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
六月 30, 2019 11:01:08 上午 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
六月 30, 2019 11:01:08 上午 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
六月 30, 2019 11:01:08 上午 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
六月 30, 2019 11:01:08 上午 org.apache.hadoop.io.compress.snappy.LoadSnappy <clinit>
警告: Snappy native library not loaded
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local425271598_0001
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.LocalJobRunner$Job run
信息: Waiting for map tasks
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable run
信息: Starting task: attempt_local425271598_0001_m_000000_0
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.MapTask runNewMapper
信息: Processing split: file:/d:/mr/words.txt:0+64
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: io.sort.mb = 100
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: data buffer = 79691776/99614720
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>
信息: record buffer = 262144/327680
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local425271598_0001_m_000000_0 is done. And is in the process of commiting
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local425271598_0001_m_000000_0' done.
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable run
信息: Finishing task: attempt_local425271598_0001_m_000000_0
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.LocalJobRunner$Job run
信息: Map task executor complete.
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 134 bytes
六月 30, 2019 11:01:09 上午 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local425271598_0001_r_000000_0 is done. And is in the process of commiting
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local425271598_0001_r_000000_0 is allowed to commit now
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local425271598_0001_r_000000_0' to file:/d:/mr/out
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local425271598_0001_r_000000_0' done.
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local425271598_0001
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Counters: 17
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=24
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=138
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=12
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Map input records=4
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=86
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=108
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=6
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=6
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Map output records=12
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=385875968
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=64
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=103142
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=546
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
六月 30, 2019 11:01:10 上午 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=52
Process finished with exit code 0
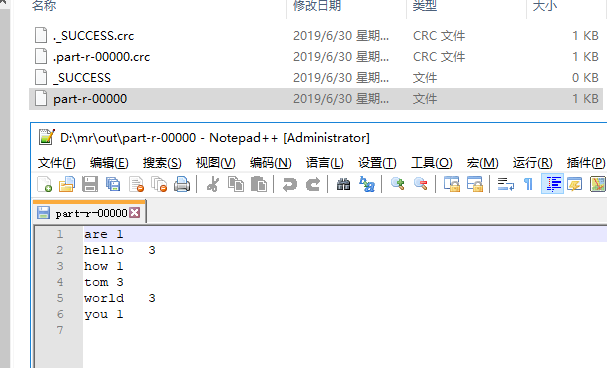
输出 out文件夹里面的内容如下
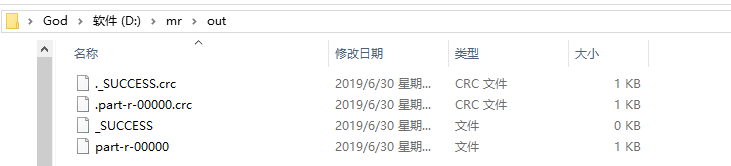
查看part-r-00000
hadoop模式
//conf.set("fs.defaultFS","file:///");
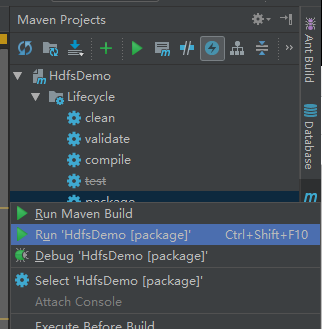
将文件打包(右上角有个闪电图标,我点了,跳过Test文件夹)
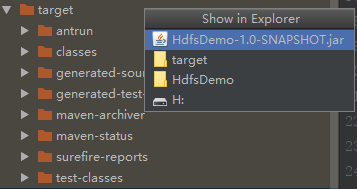
左侧target下会发现你打包好的jar包

右击HdfsDemo-1.0-Snapshot.jar 点击 file path 点击HdfsDemo-1.0-Snapshot.ja

将这个jar包通过xshell 的下xftp传到虚拟机上

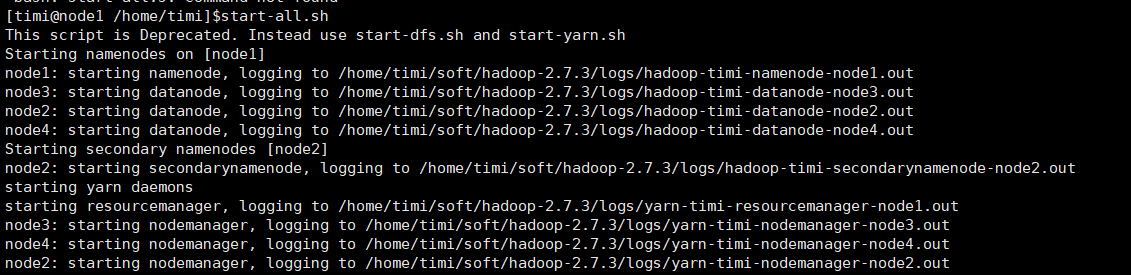
启动集群
创建输出输出的放置位置

写文件并传上去
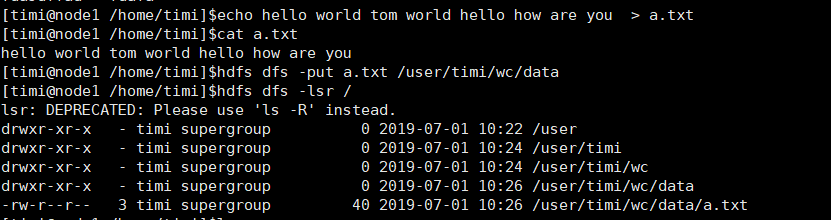
执行WorldApp

19/07/01 10:31:36 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.72.111:8032
19/07/01 10:31:39 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your applica
tion with ToolRunner to remedy this.19/07/01 10:31:41 INFO input.FileInputFormat: Total input paths to process : 1
19/07/01 10:31:42 INFO mapreduce.JobSubmitter: number of splits:1
19/07/01 10:31:42 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1561947478859_0001
19/07/01 10:31:45 INFO impl.YarnClientImpl: Submitted application application_1561947478859_0001
19/07/01 10:31:45 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1561947478859_0001/
19/07/01 10:31:45 INFO mapreduce.Job: Running job: job_1561947478859_0001
19/07/01 10:32:33 INFO mapreduce.Job: Job job_1561947478859_0001 running in uber mode : false
19/07/01 10:32:33 INFO mapreduce.Job: map 0% reduce 0%
19/07/01 10:33:04 INFO mapreduce.Job: map 100% reduce 0%
19/07/01 10:33:27 INFO mapreduce.Job: map 100% reduce 100%
19/07/01 10:33:29 INFO mapreduce.Job: Job job_1561947478859_0001 completed successfully
19/07/01 10:33:29 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=94
FILE: Number of bytes written=237037
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=141
HDFS: Number of bytes written=40
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=25599
Total time spent by all reduces in occupied slots (ms)=19918
Total time spent by all map tasks (ms)=25599
Total time spent by all reduce tasks (ms)=19918
Total vcore-milliseconds taken by all map tasks=25599
Total vcore-milliseconds taken by all reduce tasks=19918
Total megabyte-milliseconds taken by all map tasks=26213376
Total megabyte-milliseconds taken by all reduce tasks=20396032
Map-Reduce Framework
Map input records=1
Map output records=8
Map output bytes=72
Map output materialized bytes=94
Input split bytes=101
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=94
Reduce input records=8
Reduce output records=6
Spilled Records=16
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=762
CPU time spent (ms)=5310
Physical memory (bytes) snapshot=297164800
Virtual memory (bytes) snapshot=4157005824
Total committed heap usage (bytes)=141647872
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=40
File Output Format Counters
Bytes Written=40
打开8088端口看一下

因为我执行了两次 ,所以出现两次记录 正常的应该是

查看结果
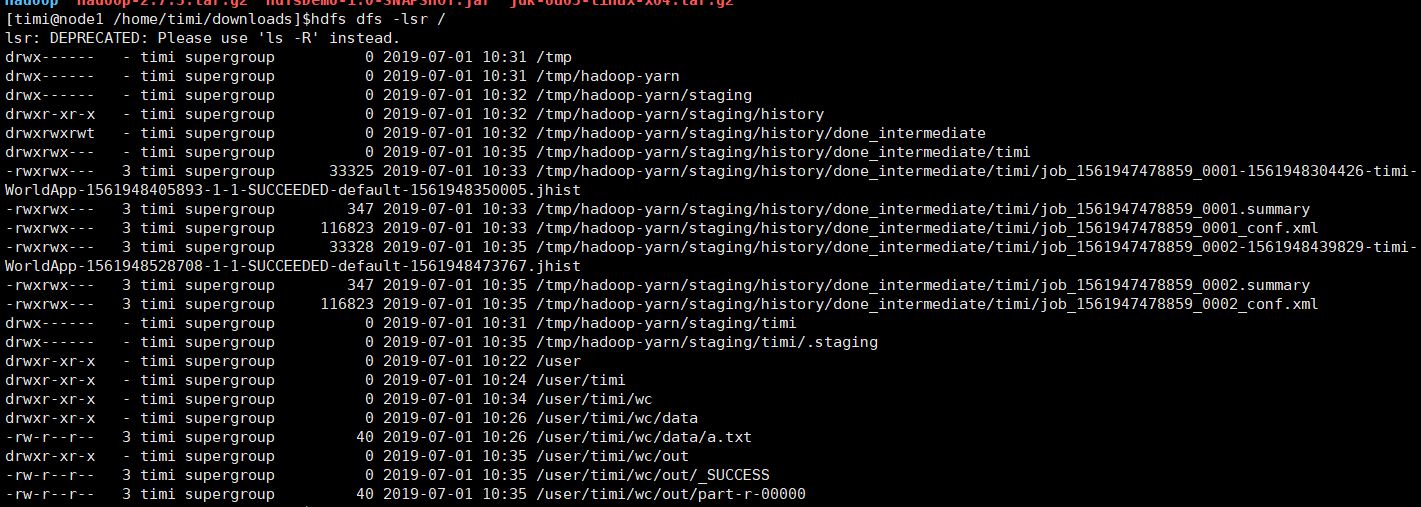


 浙公网安备 33010602011771号
浙公网安备 33010602011771号