


CeiT:Incorporating Convolution Designs into Visual Transformers
将CNN提取low-level特征,强化局部特征提取的能力,与Transformer获取long-range信息的能力相结合提高模型性能。
Step1 : image-->tokens 利用卷积提取浅层特征信息
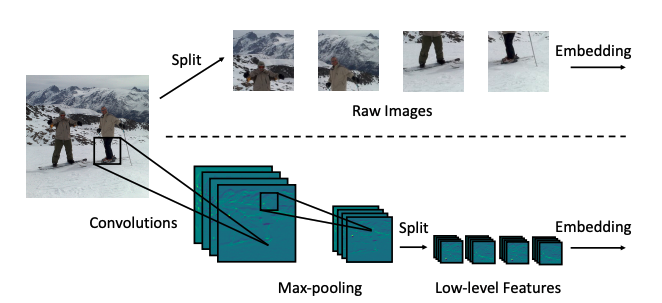
Vit将输入图像直接split成patch; CeiT利用conv+BN+Max-pooling提取浅层特征
Step 2 : 在空间维度上促进相邻token的相关性
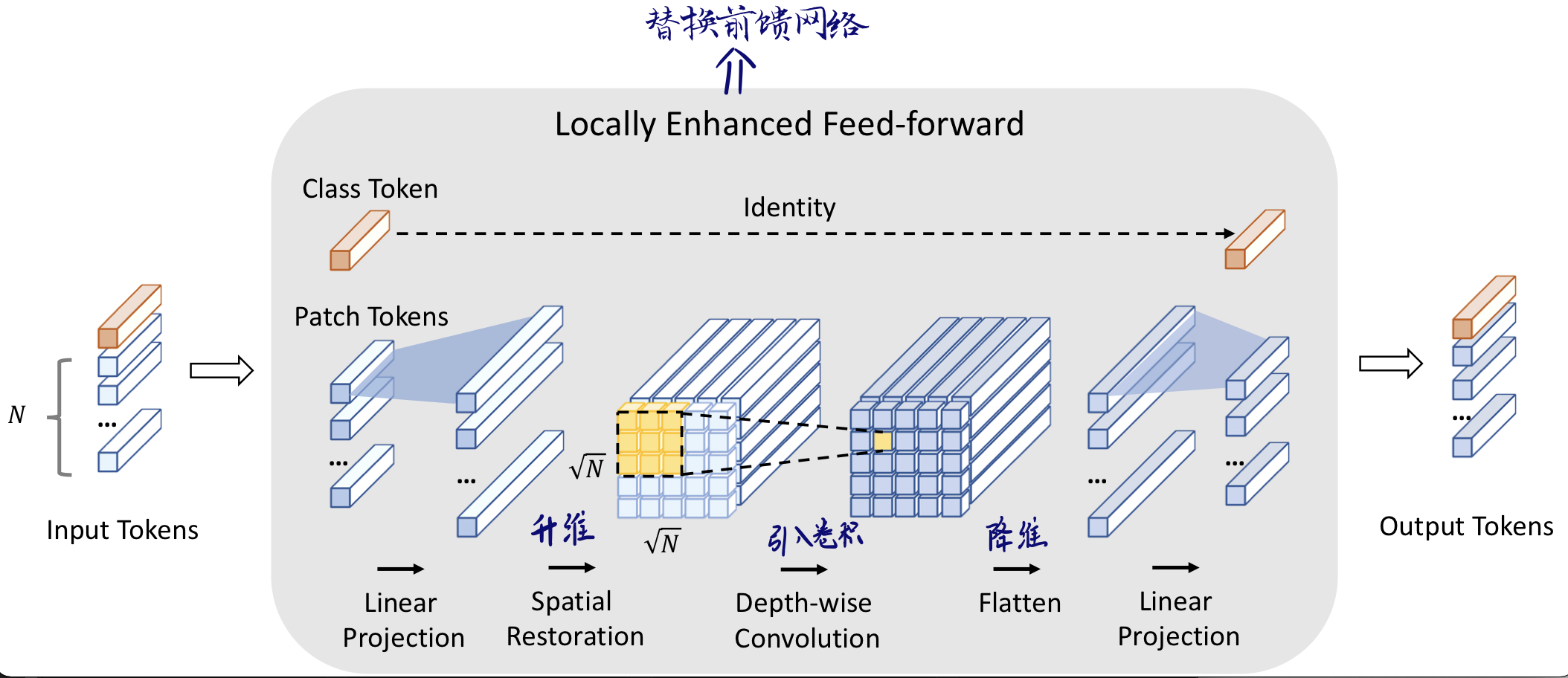
Step3: 综合不同层的信息,提出Layer-wise Class token Attention模块计算每层的class token的相互关系
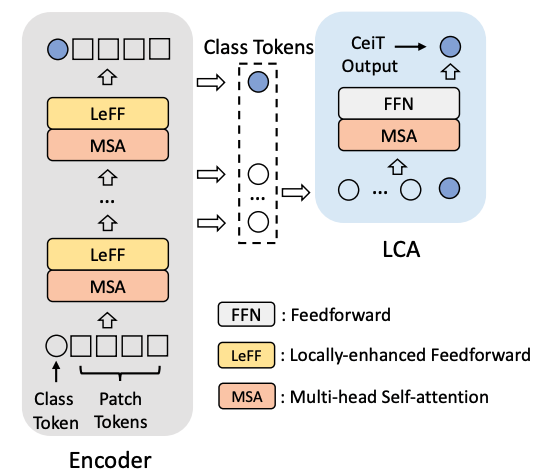
LCA模块的输入是不同层的class token

 浙公网安备 33010602011771号
浙公网安备 33010602011771号