


CvT: Introducing Convolutions to Vision Transformers
Paper:https://arxiv.org/pdf/2103.15808.pdf
Code:https://github.com/rishikksh20/convolution-vision-transformers/
Motivation:在相似尺寸下,VIT的性能要弱于CNN架构;VIT所需的训练数据量要远远大于CNN模型
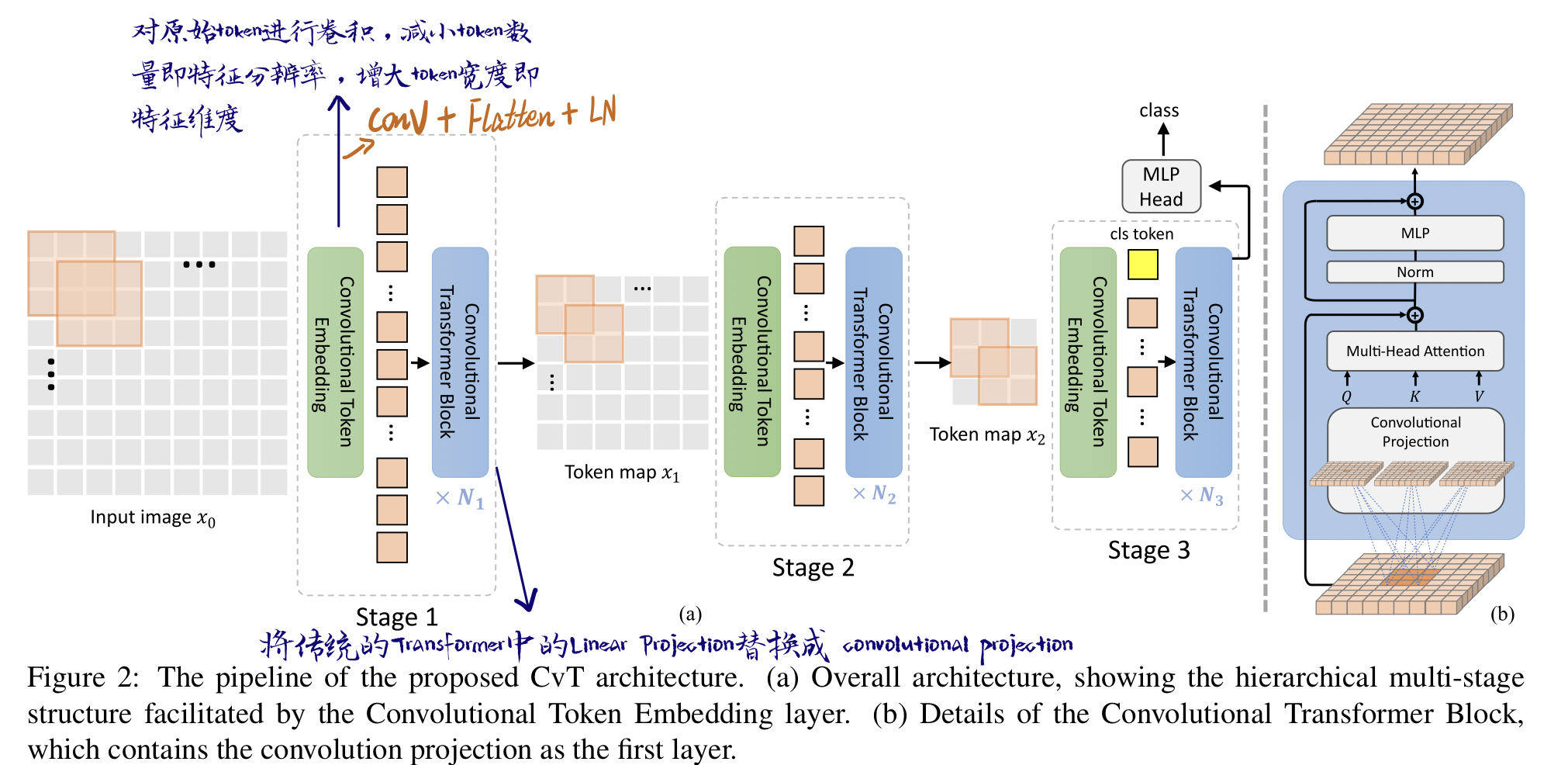
CvT将卷积引入Transformer,总架构是一个multi-stage的hierarchical的结构:
首先embedding的方式变成了卷积操作,在每个Multi-head self-attention之前都进行Convolutional Token Embedding。其次在 Self-attention的Projection操作不再使用传统的Linear Projection,而是使用Convolutional Projection。
Linear Projection->convolutional Projection
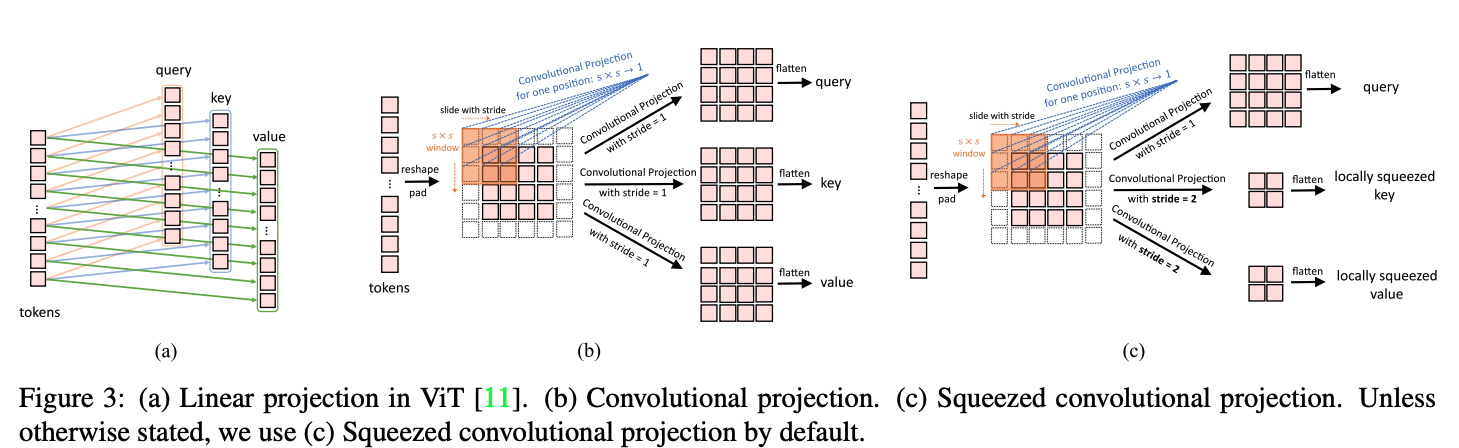
(c)这一步可以补偿分辨率下降的损失
为什么不用位置编码:卷机操作的zero-padding暗含位置信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号