


End-to-End Object Detection with Transformers
paper: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2005.12872
project: https://github.com/facebookresearch/detr
Highlight: 端到端的目标检测,实现了真正的end-to-end,把检测问题视作是一个set prediction problem
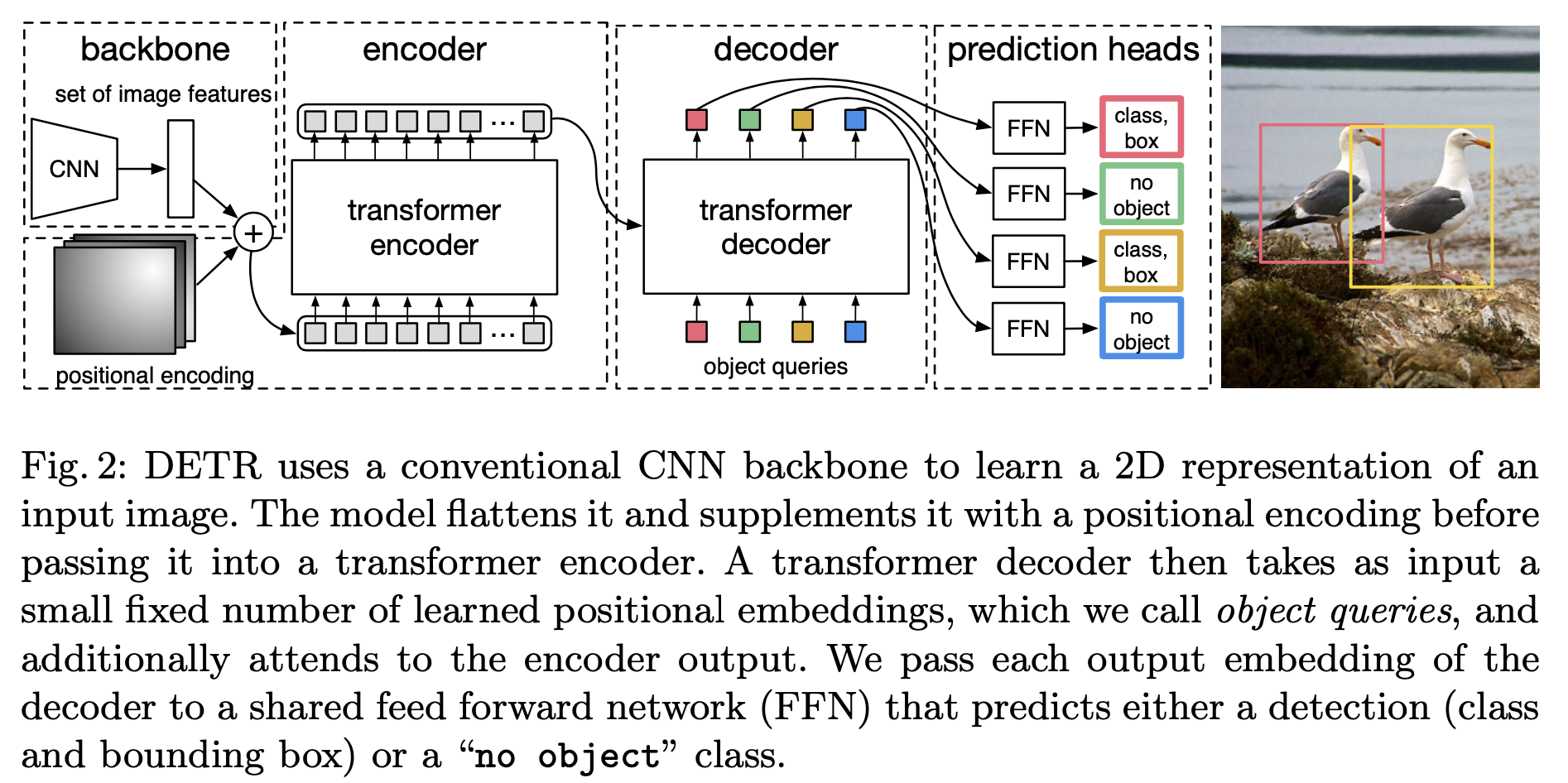
Step1: 利用CNN获取浅层特征(feature map)与位置编码进行相加,作为encoder的输入
Step2: Decoder一次性处理全部的object queries,即一次性输出全部的预测。而不像原始的Transformer从左到右一个词一个词地输出。
Decoder的输入由两部分组成:encoder的输出和object queries ;object queries是一个可学习的张量,矩阵内部通过学习建模了100个物体之间的全局关系,在推理的时候就可以利用全局注意力进行更好的解码预测输出
训练:训练集里面的一张图像,通过模型产生100个预测框,但这张图像内只有3个GT框,利用匈牙利算法(找到最优匹配关系)计算得到这3个GT框对应的label,并计算Loss;把所有的图片按照这个模式进行训练
训练完以后,模型学习到了一种能力,即:模型产生的100个预测框,它知道某个预测框该对应什么 ;个人理解其实训练的过程就是学习object queries矩阵的过程,训练结束之后,此时的Object queries看成100个格子,每个格子是个256维的向量。训练完以后,这100个格子里面注入了不同
的位置信息和类别信息。比如第1个格子里面的这个256维的向量代表着某个物体这种
的位置信息,这种信息是通过训练,考虑了所有图片的某个位置附近的该物体编码特征,属于和位置有关的全局统计信息。
可以将测试想象成匹配问题,Q想要寻找某个物体的特征,然后与获取到输入图像的特征(也就是K和V)进行匹配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号