
Lab3 页表
预备知识
SATP寄存器
SATP 寄存器:SATP(Supervisor Address Translation and Protection)寄存器是控制地址转换的关键寄存器,用来表示当前的寻址模式。
- mode(高4位)用于控制 CPU 使用的页表模式,当 mode 设置为 8(1000)时,分页机制被开启且选用 SV39 分页机制,为0时表示直接映射;
- asid(mode后的12位)地址空间标识符,用于帮助地址空间转换,我的理解是不同的进程有不同的地址空间和页表,在页表切换时会用到;
- ppn (低44位)存放的是根页表所在的物理页号,CPU 以此为基础开始地址转换。
基于Sv39 RSIC-V的页表
页表是操作系统为每个进程提供私有地址空间和内存的机制。页表决定了内存地址的含义,以及物理内存的哪些部分可以访问。它们允许xv6隔离不同进程的地址空间,并将它们复用到单个物理内存上。页表还提供了一层抽象,这允许xv6执行一些特殊操作:映射相同的内存到不同的地址空间中,并用一个未映射的页面保护内核和用户栈区。
RISC-V指令(用户和内核指令)使用的是虚拟地址,而机器的RAM或物理内存是由物理地址索引的。
RISC-V页表硬件通过将每个虚拟地址映射到物理地址来为这两种地址建立联系,并且以4096字节(4KB)的页为单位进行转换和管理。
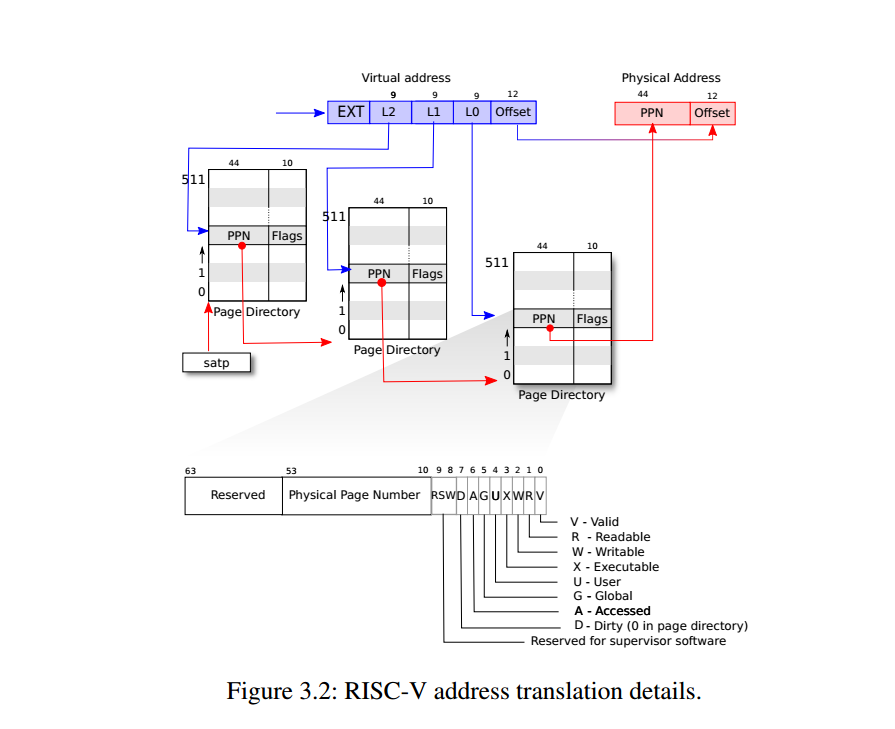
如图所示,实际在Sv39中,页表是一个三级树型结构,每一级都是一个4K大小的页,每个页表中都有512(4096/(64/8))个页表条目(PTE)。每个PTE都是64位,其中高10位保留,其余的则记录了下一级页表的物理地址的高44位(PPN)和一些标志,最后一级页表的PPN则是物理地址的PPN。
一些实验会用到的标志位:
V: 表示该页是否有效;
X/W/R:指示进程对该页的权限(可执行/可写/可读)。置位规则及含义如下

U:指示该页用户模式下是否可以访问;
G:全局页面标识,指示该由多个进程共享;。
A:指示该页被清零后,已被访问/未被可访问(为1时);
D:指示该页被清零后,被写/未被写(为1时);
N:用于Svnapot扩展
具体的映射过程:64位虚拟地址的低39位用于地址寻址,其中的L2,L1,L0各占9位(2^9=512),表示是各级页表的索引。低12位是页内偏移量,与最后物理地址的PPN进行组合得到56位的物理地址。
因此对一个虚拟地址进行物理寻址需要三次访存,最后还要访问一次访存来获取物理地址中的数据。为了节省访存次数,对最近的虚拟地址到物理地址的映射进行缓存,也就是Translation Lookaside Buffer(TLB,又称快表)。由于进程之间虚拟地址的隔离性,每当进程切换时,都需要将TLB进行清空。
内核地址空间与用户地址空间,及其映射
内核地址空间
Xv6运行在基于QEMU模拟的计算机上,QEMU模拟了一台计算机,它包括RAM(物理内存),从物理地址0x8000000开始,至少持续到0x86400000,Xv6称之为PHYSTOP。
QEMU模拟还包括I/O设备,将设备接口作为位于物理地址空间中低于0x80000000的内存映射控制寄存器暴露给软件。内核可以通过读取或写入这些特殊的物理地址直接与设备硬件进行交互。
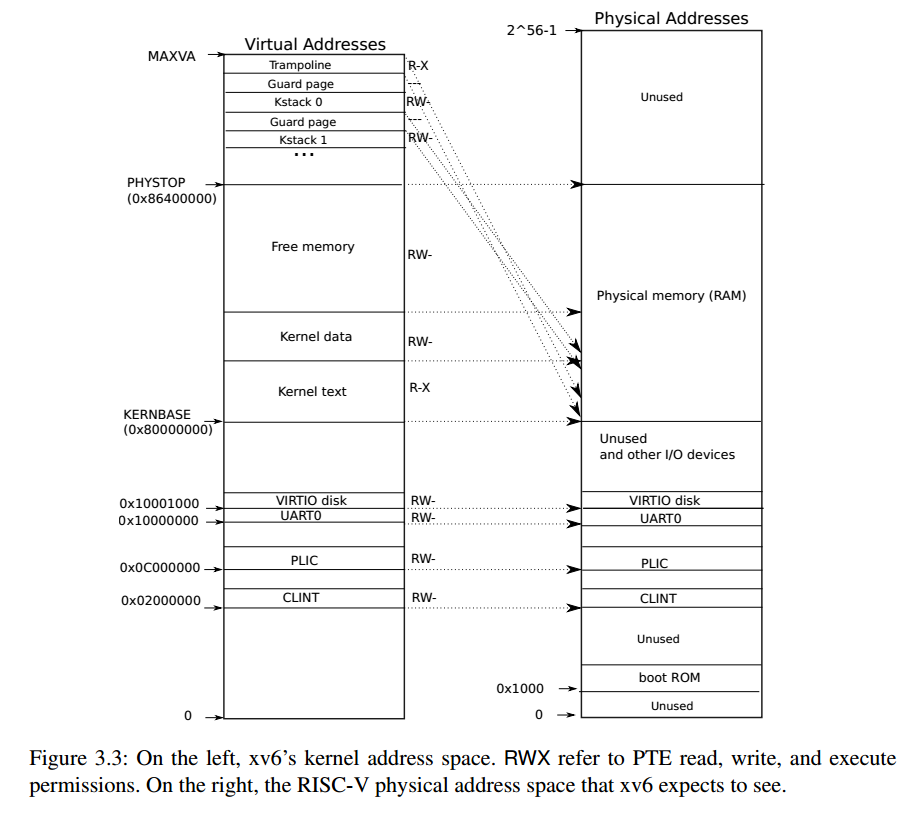
可以看到,内核对RAM与内存映射的设备寄存器使用直接映射,即将这些资源映射到和它们物理地址相同的虚拟地址上,直接映射简化了读写物理内存的内核代码。
但是有两个内核虚拟地址不是直接映射
- tramponline页:具体功能在第四章中会解释
- 内核栈页:kernel stack在虚拟内存中的地址很靠后,同时在它之下有一个未被映射的Guard page,这个Guard page对应的PTE的Valid标志位没有设置,这样,如果kernel stack耗尽了,它会溢出到Guard page,但是因为Guard page的PTE中Valid标志位未设置,会导致立即触发page fault,这样的结果好过内存越界之后造成的数据混乱。溢出时立即触发一个panic(也就是page fault)。同时为了避免浪费物理内存给Guard page,Guard page不会映射到任何物理内存,它只是占据了虚拟地址空间的一段靠后的地址。同时,kernel stack被映射了两次,在靠后的虚拟地址映射了一次,在PHYSTOP下的Kernel data中又映射了一次,但是实际使用的时候用的是上面的部分,因为有Guard page会更加安全。
Free memory :这段地址存放用户进程的page table(页表),text(代码段)和data(数据段)。如果运行了非常多的用户进程,某个时间点会耗尽这段内存,这个时候fork或者exec会返回错误。当kernel创建了一个进程,针对这个进程的page table也会从Free memory中分配出来。内核会为用户进程的页表分配几个page,并填入PTE。在某个时间点,当内核运行了这个进程,内核会将进程的根页表的地址加载到SATP中。从那个时间点开始,处理器会使用内核为那个进程构建的虚拟地址空间。
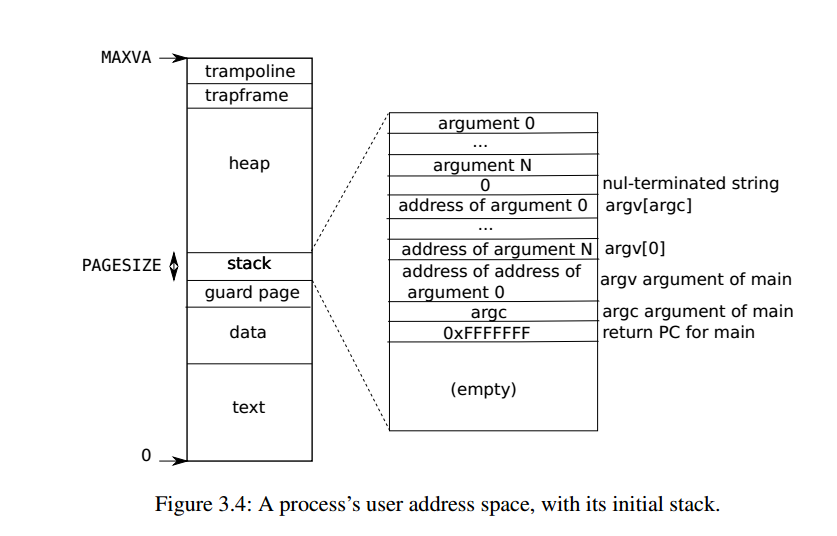
用户地址空间
每个进程都有一个单独的页表,进程切换时页表也会随之切换。不同进程的页表将用户地址转换为物理内存的不同页,因此每个进程都有私有用户内存。每个进程都将其内存视为具有从零开始的连续虚拟地址,而进程的物理内存可以是不连续的。
这里需要注意:
- 固定在用户地址空间的顶部(MAXVA)映射A具有tramponline的页面,因此在内核进程和所有用户进程中,tramponline的虚拟地址都是一致的。
- 为了检测用户堆栈溢出分配的堆栈内存,xv6在堆栈下面放置一个无效的保护页。如果用户堆栈溢出,并且进程试图使用堆栈下面的地址,硬件将生成一个页面错误异常。
![image]()
部分Xv6源码解析
虚拟地址解析到物理地址: walk()
模拟硬件MMU查找页表的过程,返回以pagetable为根页表,经过多级索引之后va这个虚拟地址所对应的页表项,如果alloc != 0,则在需要时创建新的页表页。
// kernel/riscv.h
//pagetable_t是一个指向uint64类型的指针,既可以作为内核页表也可以作为进程页表
typedef uint64 pte_t;
typedef uint64 *pagetable_t; // 512 PTEs
//
// 从虚拟地址中提取各级页表中目的页表项索引的操作
#define PXMASK 0x1FF // 9 bits
#define PXSHIFT(level) (PGSHIFT+(9*(level))) //PIGSHIFT为12,表示最低12位的偏移量
#define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK)
// kernel/vm.c
//vm->pm:地址映射函数 walk()
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
//MAXVA是最大的虚拟地址,检查虚拟地址是否有效
if(va >= MAXVA)
panic("walk");
//遍历三级页表
for(int level = 2; level > 0; level--) {
//获取这一级页表的PTE项
pte_t *pte = &pagetable[PX(level, va)];
//通过检查标志位确认PTE是否有效
if(*pte & PTE_V) {
//有效的的话就计算出下一级页表的地址
//#define PTE2PA(pte) (((pte) >> 10) << 12),右移十位再左移12位得到56位的物理地址(54-10+12)
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
//无效的话说明这一级的页表未分配
//alloc = 1:执行kalloc
//alloc = 0:语句直接为真。只做查询
//因此只有当l2,l1两级页表页不存在且不需要分配时,walk函数会返回0
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
//将申请的页填满并置有效位位1
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
//返回最后一级页表的pte
return &pagetable[PX(0, va)];
}
页表递归释放:freewalk()
//实验一提示参考
// kernel/freewalk
// Recursively free page-table pages.free页表
// All leaf mappings must already have been removed.注意这里强调了所有的叶子结点应该已经被free了
void
freewalk(pagetable_t pagetable)
{
// there are 2^9 = 512 PTEs in a page table.
//遍历所有PTE
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
//根据下方的英文注释,这里是判断pte是否是指向更底层的页表,也就是它是页表的PPN还是物理地址的PPN
//前一部分是根据有效位V来判断页表是否有效,很好理解:有效位应该为1
//第二部分就是判断是指向下一级页表还是物理内存
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
//对于非叶子结点递归调用freewalk释放
uint64 child = PTE2PA(pte);
freewalk((pagetable_t)child);
//释放后置为0,表示无效的PTE
pagetable[i] = 0;
} else if(pte & PTE_V){
//如果是一个有效的叶子结点,唤起一个panic
panic("freewalk: leaf");
}
}
//最后free本身所占的内存
kfree((void*)pagetable);
}
虚拟地址到物理地址的映射:mappages()
mappages函数在给定页表中建立从虚拟地址(va)到物理地址(pa)的连续映射,映射的区间大小为 size 。它逐页地建立映射关系。va 和 size 可以未对齐到页面边界。成功时返回 0,如果 walk() 无法分配所需的页面表页面,则返回 -1。
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
//由于是按页分配,因此页表中保存的都是每一页的起始地址
a = PGROUNDDOWN(va); // 起始虚拟地址所在的页起始地址
//这里size不能为0
last = PGROUNDDOWN(va + size - 1);//结束虚拟地址所在的页起始地址
for(;;){
//walk返回0,说明kalloc分配页失败,大概率是内存耗尽
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
//重复映射
if(*pte & PTE_V)
panic("remap");
//分配完毕后建立起 pa到相应pte的映射关系,并设置标志位
*pte = PA2PTE(pa) | perm | PTE_V;
//建立映射关系完毕
if(a == last)
break;
//处理下一页
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
解除映射函数:uvmunmap()
删除从虚拟地址 va 开始的 npages 个xi映射。va 必须是页面对齐的。这些映射必须存在,可选地释放物理内存。
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
uint64 a;
pte_t *pte;
//检查是否对齐了页面
if((va % PGSIZE) != 0)
panic("uvmunmap: not aligned");
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
//alloc=0的情况下,walk函数返回0
//说明中间页表不存在
if((pte = walk(pagetable, a, 0)) == 0)
panic("uvmunmap: walk");
//walk()查找到的pte无效
//说明没有没有构造到物理内存页的映射
if((*pte & PTE_V) == 0)
panic("uvmunmap: not mapped");
//除了有效位剩下的全0
//RWX全0说明指向的是下一级页表
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
//是否需要释放物理内存
if(do_free){
uint64 pa = PTE2PA(*pte);
kfree((void*)pa);
}
//重置pte保存的物理内存地址,完成解除映射
*pte = 0;
}
}
Print a page table
实现一个名为vmprint()的函数,输入一个pagetable_t类型的参数, 要求递归地打印出它所映射到的3层page table下所有存在的PTE。要求在 kernel/exec.c中exec函数的 return argc 之前插入 if(p->pid==1)vmprint(p->pagetable),以打印第一个进程的页表。更具体的实验要求和提示查看实验指导书。
// kernel/defs.h 添加函数声明
//vm.c
int vmprint(pagetable_t pagetable);
//kernel/exec.c 将函数插入指定位置
//exe()
...
if(p->pid == 1)
vmprint(p->pagetable);
return argc; // this ends up in a0, the first argument to main(argc, argv)
//kernel/vm.c 实现vmprint
int print_pte(pagetable_t pagetable, int depth){
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
//叶子页表和非叶子页表都要打印输出
if( pte & PTE_V ){
for(int j = 0; j <= depth; j++)
printf("..");
printf("%d: pte %p pa %p\n", i, pte,PTE2PA(pte));
//非叶子页表递归处理
if( (pte & (PTE_R|PTE_W|PTE_X)) == 0 ){
uint64 child = PTE2PA(pte);
print_pte( (pagetable_t)child, depth+1);
}
}
}
return 0;
}
int vmprint(pagetable_t pagetable){
printf("page table %p\n",pagetable);
return print_pte(pagetable, 0);
}
//打分
make: “kernel/kernel”已是最新。
== Test pte printout == pte printout: OK (0.8s)
A kernel page table per process
在目前的xv6操作系统中,用户态下的每个用户进程都使用各自的用户态页表。但是进入内核态之后就会使用所有进程共享的内核态页表。本实验的任务是修改内核,使每个进程在内核中执行时使用其自己的内核页表副本。修改 struct proc 为每个进程维护一个内核页表,并修改调度器在切换进程时切换内核页表。在此步骤中,每个进程的内核页表应与现有的全局内核页表完全相同。
思路:
- 修改进程结构体,使其拥有独占的内核页表属性,这里会涉及到进程初始化函数、进程销毁函数、进程切换函数的修改
大概思路就先这样,具体的细节在实现时根据实验提示一步步优化
创建进程独立内核页表和内核栈
//kernel/proc
//struct proc
//修改进程结构体,添加自己的内核页表
...
pagetable_t pagetable; // User page table
pagetable_t unique_kernelpagetable; //每个进程独占的内核页表
接下来就是修改原来的内核页表初始化函数kvminit(),内核需要依赖内核页表内一些固定的映射的存在才能正常工作,例如 UART 控制、硬盘界面、中断控制等。现在每一个进程都需要自己的内核页表。因此将这个函数抽象出来作为一个可以供用户进程、内核调用的初始化函数。
// kernel/vm.c
//kvmmap的任意页表版本
//将虚拟地址映射到物理地址
void kvmmap(pagetable_t pagetable, uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(pagetable, va, sz, pa, perm) != 0)
panic("kvmmap");
}
//修改后的全局内核页表初始化
void kvminit(){
kernel_pagetable = kvminit_repgt();
}
//创建一个页表并初始化,然后返回它
pagetable_t kvminit_repgt()
{
pagetable_t pagetable = (pagetable_t) kalloc();
memset(pagetable, 0, PGSIZE);
kvminit_pgt(pagetable);
return pagetable;
}
//修改后的页表映射函数
void
kvminit_pgt(pagetable_t pagetable)
{
// uart registers
kvmmap(pagetable, UART0,UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(pagetable, VIRTIO0,VIRTIO0, PGSIZE, PTE_R | PTE_W);
// CLINT
kvmmap(pagetable, CLINT,CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
kvmmap(pagetable, PLIC,PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(pagetable, KERNBASE,KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(pagetable,(uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(pagetable, TRAMPOLINE,(uint64)trampoline, PGSIZE, PTE_R | PTE_X);
}
//在头文件中声明
// kernel/def.h
void kvmmap(pagetable_t, uint64, uint64,uint64,int);
pagetable_t kvminit_repgt();
void kvminit_pgt(pagetable_t);
现在系统创建的进程都拥有了自己独立内核页表,但是还需要处理内核栈。 在原本的 xv6 设计中,所有处于内核态的进程都共享同一个页表,即意味着共享同一个地址空间。由于 xv6 支持多核/多进程调度,同一时间可能会有多个进程处于内核态,所以需要对所有处于内核态的进程创建其独立的内核栈,供给其内核态代码执行过程。在 xv6 原来的设计中,所有进程共用一个内核页表,所以需要为不同进程创建多个内核栈,并 map 到不同位置。这是因为由于只有一个内核页表,对于不同的内核栈中的的相同的虚拟地址,也会寻址到同一个物理地址(不同栈内的同一虚拟地址,通过统一的页表映射,指向同一个物理内存)。而在我们的新设计中,每一个进程都会有自己独立的内核页表,所以可以将所有进程的内核栈 map 到其各自内核页表内的固定位置(不同栈内的同一虚拟地址,通过各自的独立页表映射,指向不同物理内存)
根据实验提示,所有内核栈都在 procinit 中设置。需要将部分或全部此功能移至 allocproc。
// kernel/proc.c
void
procinit(void)
{
struct proc *p;
initlock(&pid_lock, "nextpid");
for(p = proc; p < &proc[NPROC]; p++) {
initlock(&p->lock, "proc");
//这一部分就是为进程分配内核栈
// Allocate a page for the process's kernel stack.
// Map it high in memory, followed by an invalid
// guard page.
//char *pa = kalloc();
//if(pa == 0)
// panic("kalloc");
//int64 va = KSTACK((int) (p - proc));
//kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
//p->kstack = va;
//注释掉这一部分
}
kvminithart();
}
// kernel/proc.c
//allocproc()
...
// An empty user page table.
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
//为新进程创建独立的内核页表
p->unique_kernelpagetable = kvminit_repgt();
char *pa = kalloc();
if(pa == 0)
panic("kalloc");
uint64 va = KSTACK((int)0); //这里映射到固定的虚拟地址即可,不需要考虑进程之间的影响
kvmmap_pgt(p->unique_kernelpagetable ,va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
p->kstack = va; //记录内核栈的虚拟地址
//新增部分结束
进入内核态的切换
在调度器将 CPU 交给进程执行之前,切换到该进程对应的内核页表。
提示说参考kvminithart()函数,在sheduler()中修改
// kernel/vm.c
// Switch h/w page table register to the kernel's page table,
// and enable paging.
void
kvminithart()
{
w_satp(MAKE_SATP(kernel_pagetable)); //将SATP寄存器的PPN设置为指定页表物理页号
sfence_vma(); //刷新TLB缓存
}
//kernel/proc.c
//sheduler()
...
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
//切换到进程自己的内核页表
w_satp(MAKE_SATP(p->unique_kernelpagetable));
//切换页表后要刷新TLB
sfence_vma();
swtch(&c->context, &p->context);//可以看出这一行应该是执行进程,因此切换应该在这里之前
//这里记得执行完毕后要切换回全局内核页表
kvminithart();
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
found = 1;
释放独占页表与内核栈
直接看代码
// kernel/proc.c
//freeproc
// free a proc structure and the data hanging from it,
// including user pages.
// p->lock must be held.
static void
freeproc(struct proc *p)
{
if(p->trapframe)
kfree((void*)p->trapframe);
p->trapframe = 0;
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
p->pagetable = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->chan = 0;
p->killed = 0;
p->xstate = 0;
p->state = UNUSED;
//创建顺序:独占页表->内核栈
//释放顺序:内核栈->独占页表
//释放内核栈
void* kstack_pa = (void *)kvmpa(p->unique_kernelpagetable, p->kstack);
kfree(kstack_pa);
p->kstack = 0;
//释放独占页表,仿照freewalk
free_kernelpgt(p->unique_kernelpagetable);
p->unique_kernelpagetable = 0;
p->state = UNUSED;
}
// kernel/defs.h
void free_kernelpgt(pagetable_t);
// kernel/vm.c
void free_kernelpgt(pagetable_t pagetable){
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
uint64 child = PTE2PA(pte);
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
free_kernelpgt((pagetable_t)child);
pagetable[i] = 0;
}
}
kfree((void*)pagetable);
}
//这里修改kvmpa函数
// kernel/defs.h
uint64 kvmpa(pagetable_t,uint64);
//kernel/vm.c
//kvmpa的任意页表版本
uint64
kvmpa(pagetable_t pagetable, uint64 va){
uint64 off = va % PGSIZE;
pte_t *pte;
uint64 pa;
pte = walk(pagetable, va, 0);
if(pte == 0)
panic("kvmpa");
if((*pte & PTE_V) == 0)
panic("kvmpa");
pa = PTE2PA(*pte);
return pa+off;
}
//这一修改影响了 virtio 磁盘驱动中 virtio_disk.c, 调用了 kvmpa() 用于将虚拟地址转换为物理地址
//kernel/virtio_disk.c
#inlcude "proc.c" //新增进程相关头文件
void
virtio_disk_rw(struct buf *b, int write)
{
// ...
disk.desc[idx[0]].addr = (uint64) kvmpa(myproc()->kernelpgtbl, (uint64) &buf0); // 调用 myproc(),获取进程内核页表
// ...
}
最后执行测试,make qemu运行,然后输入usertests,最后显示ALL TESTS PASSED,说明通过实验。
Simplify copyin/copyinstr
这个实验的任务是,在进程的内核态页表中维护一个用户态页表映射的副本,以便 copyin(以及相关的字符串函数 copyinstr)能够直接解引用用户指针。这样做相比原来 copyin 的实现的优势是,原来的 copyin 是通过软件模拟访问页表的过程获取物理地址的,而在内核页表内维护映射副本的话,可以利用 CPU 的硬件寻址功能进行寻址,效率更高并且可以受快表加速。
具体来说就是:复制用户态页表到进程的内核态页表中,同时也要同步对用户态页表的修改。
替换原函数
使用kernel/vmcopyin.c中的函数即可
// kernel/vm.c
//通过新的函数进行处理
int copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len){
return copyin_new(pagetable, dst, srcva, len);
}
int copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max){
return copyinstr_new(pagetable, dst, srcva, max);
}
// kernel/defs.h
int copyin_new(pagetable_t, char*, uint64, uint64);
int copyinstr_new(pagetable_t, char*, uint64, uint64);
实现同步映射
// kernel/vm.c
//将用户态页表user_pgt中从begin到end的虚拟地址的映射拷贝到内核页表中
int
kvmcopypgtu2k(pagetable_t user_pgt, pagetable_t ker_pgt, uint64 begin, uint64 end){
pte_t *pte;
uint64 pa, i;
uint flags;
for(i = begin; i < end; i += PGSIZE){
if((pte = walk(user_pgt, i, 0)) == 0)
panic("uvmmap_copy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmmap_copy: page not present");
pa = PTE2PA(*pte);
// 映射的时候需要去除页表项中的 PTE_U 标志,内核态同样不能访问用户态的页表
flags = PTE_FLAGS(*pte) & (~PTE_U);
// 调用mappages函数
if(mappages(ker_pgt, i, PGSIZE, pa, flags) != 0){
//如果失败了需要回滚,解除之前的所有映射。用于映射用户态页表的内核页表虚拟地址从0开始
uvmunmap(ker_pgt, 0, i / PGSIZE, 0);
return -1;
}
}
return 0;
}
//kernel/defs.h
int kvmcopypgtu2k(pagetable_t, pagetable_t, uint64, uint64);
PLIC限制
根据实验提示,内核启动后,能够用于映射程序内存的地址范围是从0到PLIC, 但是在这个范围之内还有一个CLINT(核心本地中断器)的映射。这样就会造成冲突。不过 CLINT 仅在内核启动的时候需要使用到,而用户进程在内核态中的操作并不需要使用到该映射。
因此将CLINT映射只在全局内核页表中进行映射,而对于进程的内核页表则去除这一映射。
// kernel/vm.c
void kvminit(){
kernel_pagetable = kvminit_repgt();
kvmmap(kernel_pagetable, CLINT,CLINT, 0x10000, PTE_R | PTE_W);
}
void
kvminit_pgt(pagetable_t pagetable)
{
// uart registers
kvmmap(pagetable, UART0,UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(pagetable, VIRTIO0,VIRTIO0, PGSIZE, PTE_R | PTE_W);
// CLINT
//kvmmap(pagetable, CLINT,CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
kvmmap(pagetable, PLIC,PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(pagetable, KERNBASE,KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(pagetable,(uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(pagetable, TRAMPOLINE,(uint64)trampoline, PGSIZE, PTE_R | PTE_X);
}
同步fork(), exec(), sbrk()中对进程用户页表的修改
// kernel/proc.c
//fork()
//...
np->sz = p->sz;
//将子进程的用户页表映射拷贝到内核页表中
if( kvmcopypgtu2k(np->pagetable, np->unique_kernelpagetable, 0, np->sz) < 0 ){
freeproc(np);
release(&np->lock);
return -1;
}
//kernel/exec.c
safestrcpy(p->name, last, sizeof(p->name));
//exec的作用是替换进程,因此要先去除原来的映射
uvmunmap(p->unique_kernelpagetable, 0, PGROUNDDOWN(oldsz)/PGSIZE,0);
kvmcopypgtu2k(pagetable, p->unique_kernelpagetable, 0, sz);
// Commit to the user image.
//kernel/proc.c
// growproc(),sbrk()系统调用是调用了这个函数
// Grow or shrink user memory by n bytes.
// Return 0 on success, -1 on failure.
int
growproc(int n)
{
uint sz;
struct proc *p = myproc();
sz = p->sz;
//检查是否超出PLIC
if(n > 0 && sz + n >= PLIC)
return -1;
uint64 oldsz = sz;
if(n > 0){
if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
return -1;
}
//同步扩容
kvmcopypgtu2k(p->pagetable, p->unique_kernelpagetable, PGROUNDDOWN(oldsz), sz);
} else if(n < 0){
//回收用户页,使得进程的内存大小从第二个参数变为第三个参数的大小
//不一定页对齐,新内存也可以更大
sz = uvmdealloc(p->pagetable, sz, sz + n);
//同步缩减
uvmunmap(p->pagetable, PGROUNDDOWN(sz), (PGROUNDDOWN(oldsz) - PGROUNDDOWN(sz))/PGSIZE, 0);
}
p->sz = sz;
return 0;
}
// kernel/proc.c
// userinit
//...
uvminit(p->pagetable, initcode, sizeof(initcode));
p->sz = PGSIZE;
kvmcopypgtu2k(p->pagetable, p->unique_kernelpagetable,0 , p->sz);
打分
== Test count copyin ==
$ make qemu-gdb
count copyin: OK (0.5s)
== Test usertests ==
$ make qemu-gdb
(56.7s)
== Test usertests: copyin ==
usertests: copyin: OK
== Test usertests: copyinstr1 ==
usertests: copyinstr1: OK
== Test usertests: copyinstr2 ==
usertests: copyinstr2: OK
== Test usertests: copyinstr3 ==
usertests: copyinstr3: OK
== Test usertests: sbrkmuch ==
usertests: sbrkmuch: OK
== Test usertests: all tests ==
usertests: all tests: OK

 浙公网安备 33010602011771号
浙公网安备 33010602011771号