
Prometheus+grafana+alertmanager监控告警系统安装部署
Prometheus是基于go语言开发的,可以支持多种语言客户端
Prometheus下载:https://prometheus.io/download/

1、安装Prometheus
~]# wget https://github.com/prometheus/prometheus/releases/download/v2.37.6/prometheus-2.37.6.linux-amd64.tar.gz ~]# tar xf prometheus-2.37.6.linux-amd64.tar.gz -C /approot1/prometheus/
修改配置文件 prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.53.180:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "conf/rules/*.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: 'node-exporter'
file_sd_configs:
- files:
- 'conf/json/node-exporter-*.json'
- job_name: 'redis-exporter'
file_sd_configs:
- files:
- 'conf/json/redis-exporter-*.json'
- job_name: 'mysql-exporter'
file_sd_configs:
- files:
- 'conf/json/mysql-exporter-*.json'
- job_name: 'nginx-exporter'
file_sd_configs:
- files:
- 'conf/json/nginx-exporter-*.json'
- job_name: 'blackbox-exporter'
metrics_path: /probe
params:
module: [tcp_connect]
file_sd_configs:
- files:
- 'conf/json/blackbox-exporter-*.json'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.53.181:9006 # Blackbox Exporter 的 IP:端口
- job_name: 'jmx-exporter'
file_sd_configs:
- files:
- 'conf/json/jmx-exporter-*.json'
- job_name: 'docker-exporter'
file_sd_configs:
- files:
- 'conf/json/docker-exporter-*.json'
- job_name: 'api-exporter'
scrape_interval: 15s
metrics_path: /actuator/prometheus
file_sd_configs:
- files:
- 'conf/json/api-exporter-*.json'
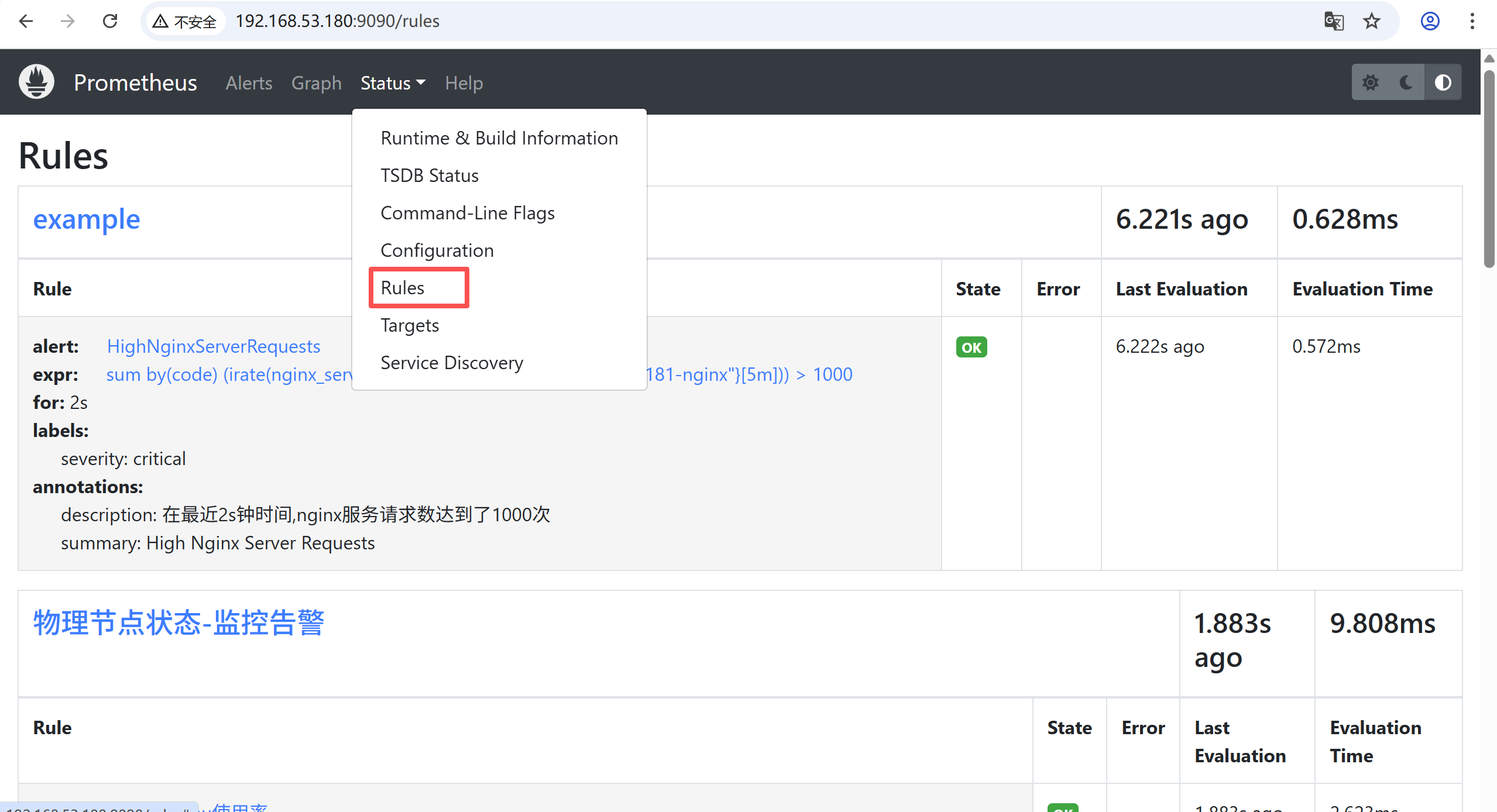
告警规则配置文件:
普通告警模板:
https://awesome-prometheus-alerts.grep.to/rules#host-and-hardware
k8s告警模板:
https://awesome-prometheus-alerts.grep.to/rules#kubernetes
[root@k8s-master1 prometheus-2.37.6.linux-amd64]# mkdir -p conf/{json,rules}
[root@k8s-master1 prometheus-2.37.6.linux-amd64]# cd conf/rules/
[root@k8s-master1 prometheus-2.37.6.linux-amd64]# vim node-rule.ymlnode-rule.yml
groups:
- name: example
rules:
- alert: HighNginxServerRequests
expr: sum(irate(nginx_server_requests{instance="181-nginx", code="2xx"}[5m])) by (code)>1000
for: 2s
labels:
severity: critical
annotations:
summary: "High Nginx Server Requests"
description: "在最近2s钟时间,nginx服务请求数达到了1000次"
- name: 物理节点状态-监控告警
rules:
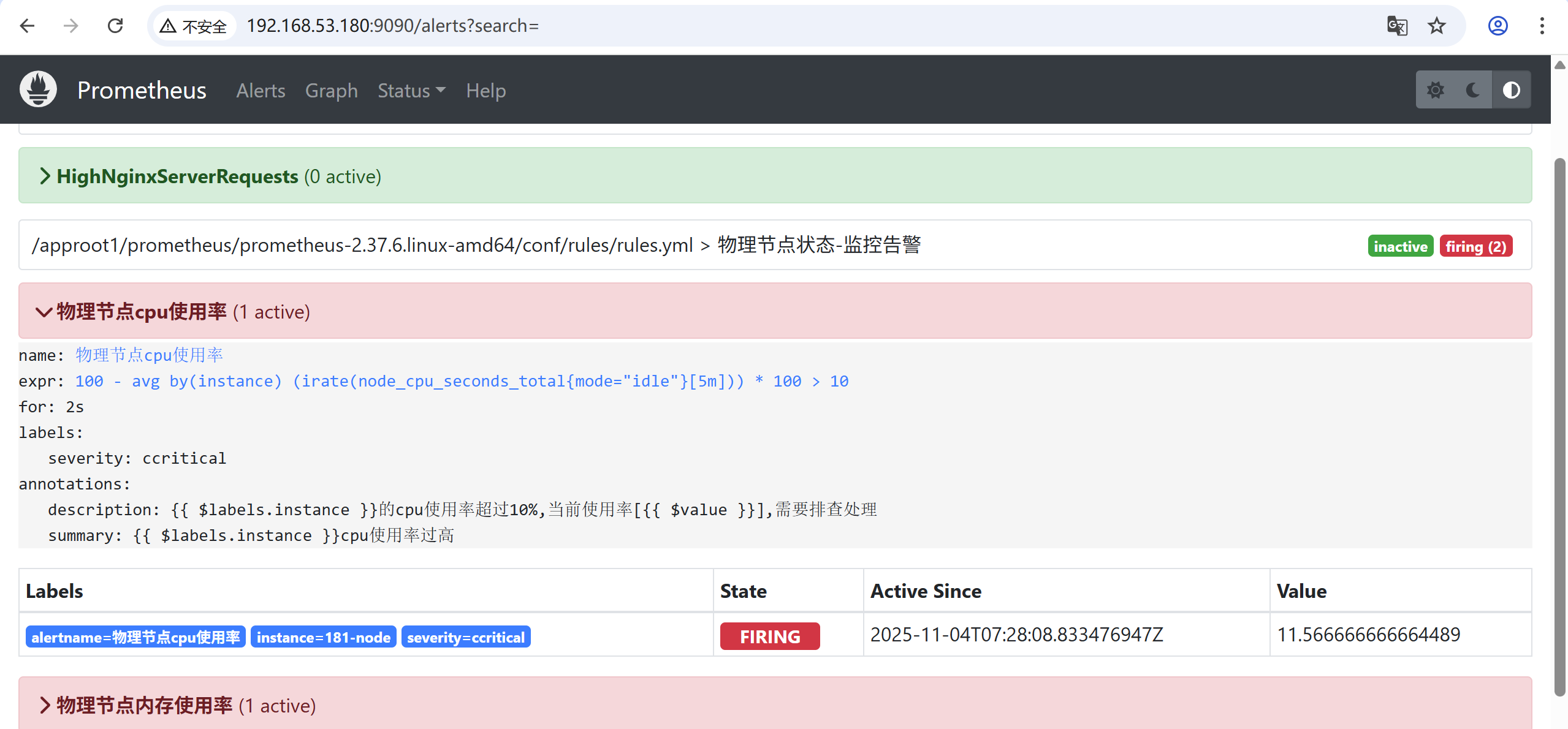
- alert: 物理节点cpu使用率
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 10
for: 2s
labels:
severity: ccritical
annotations:
summary: "{{ $labels.instance }}cpu使用率过高"
description: "{{ $labels.instance }}的cpu使用率超过10%,当前使用率[{{ $value }}],需要排查处理"
- alert: 物理节点内存使用率
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 20
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}内存使用率过高"
description: "{{ $labels.instance }}的内存使用率超过20%,当前使用率[{{ $value }}],需要排查处理"
- alert: InstanceDown
expr: up == 0
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}: 服务器宕机"
description: "{{ $labels.instance }}: 服务器延时超过2分钟"
- alert: 物理节点磁盘的IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 入网流量带宽
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽过高!"
description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: 出网流量带宽
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽过高!"
description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
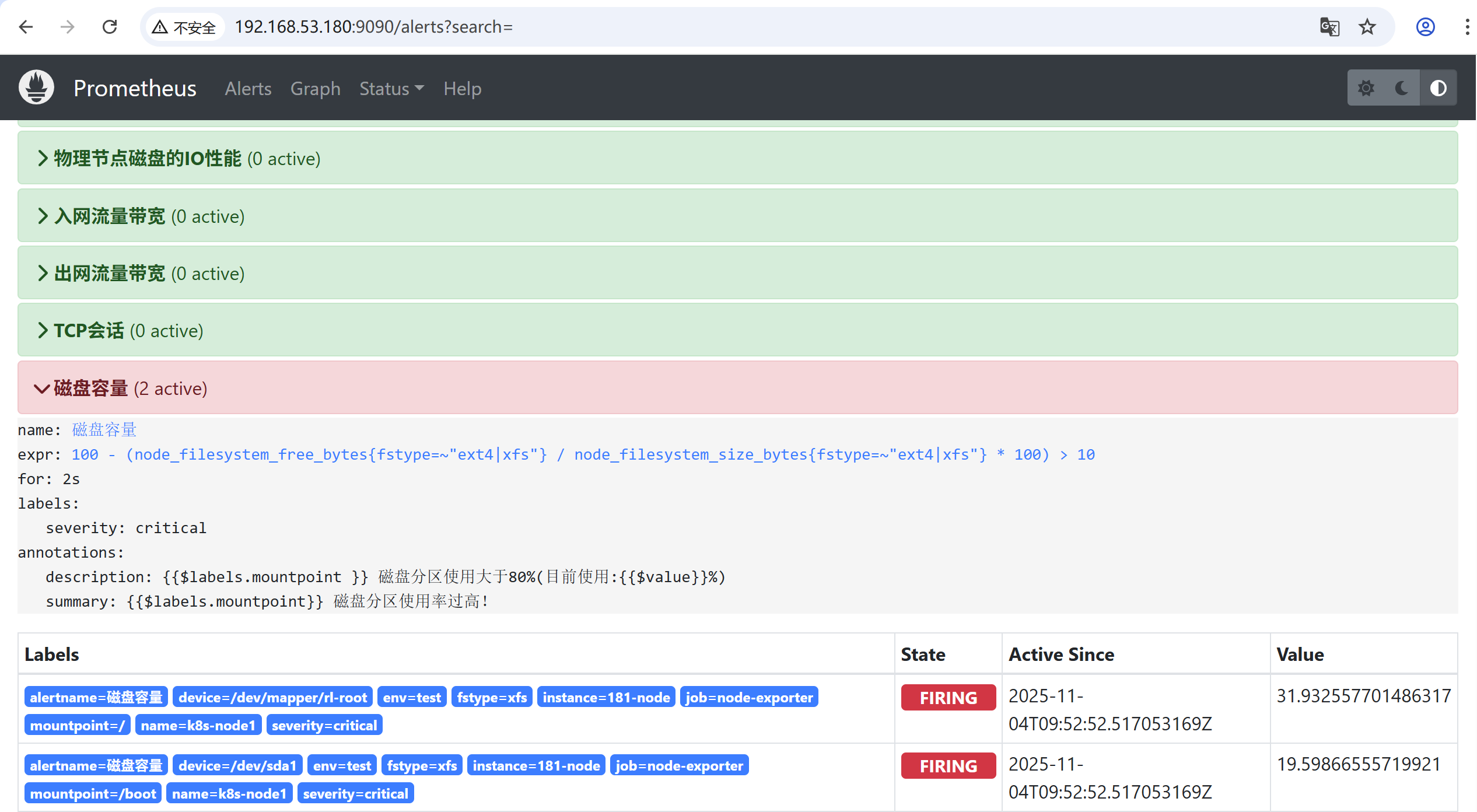
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
创建prometheus服务启停程序文件,并启动服务:
/usr/lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus Monitoring
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
ExecStart=/approot1/prometheus/prometheus-2.37.6.linux-amd64/prometheus \
--config.file=/approot1/prometheus/prometheus-2.37.6.linux-amd64/prometheus.yml \
--web.listen-address=:9090 \
--web.enable-lifecycle \
--storage.tsdb.path=/approot1/prometheus/prometheus-2.37.6.linux-amd64/data \
--storage.tsdb.retention.time=15d
Restart=always
[Install]
WantedBy=multi-user.target# 如果需要启用Prometheus热加载配置,需要添加:--web.enable-lifecycle 开启生命周期管理,不然无法通过 /-/reload 接口触发热加载
重载配置
# systemctl daemon-reload启动prometheus服务
# systemctl start promethues配置开机自启动
# systemctl enable prometheus.service

2、安装被监控端安装node_exporter(默认系统监控项),可以根据监控需求安装相对应得exporter
官网下载安装包:https://prometheus.io/download/
安装node_exporter,并启动程序
[root@k8s-node1 ~]# mkdir exporter
[root@k8s-node1 ~]# cd exporter
[root@k8s-node1 exporter]# tar xvf node_exporter-1.1.2.linux-amd64.tar.gz
[root@k8s-node1 exporter]# cd node_exporter-1.1.2.linux-amd64/
[root@k8s-node1 node_exporter-1.1.2.linux-amd64]# ./node_exporter --web.listen-address=:9004 &#启动命令说明
./node_exporter #启动node_exporter
--web.listen-address=:9004 #prometheus获取node_exporter数据端口,已指定。
启动之后,通过ps -ef | grep node_exporter 查询是否有相应的进程
创建prometheus自动发现的json文件
文件格式与prometheus.yml中file_sd_configs.files要一致:conf/json/node-exporter-*.json
[root@k8s-master1 ~]# cd /approot1/prometheus/prometheus-2.37.6.linux-amd64/conf/json
[root@k8s-master1 json]# cat node-exporter-test-2025.json
[
{
"labels": {
"env": "test",
"name": "k8s-node1",
"instance": "181-node"
},
"targets": [
"192.168.53.181:9004"
]
},
{
"labels": {
"env": "test",
"name": "k8s-node2",
"instance": "182-node"
},
"targets": [
"192.168.53.182:9004"
]
}
]web页面查看监控节点信息,我只有一个节点,182没有启动(只是为了演示多节点的配置)

把182节点信息从node-exporter-test-2025.json删除

web页面重新查看
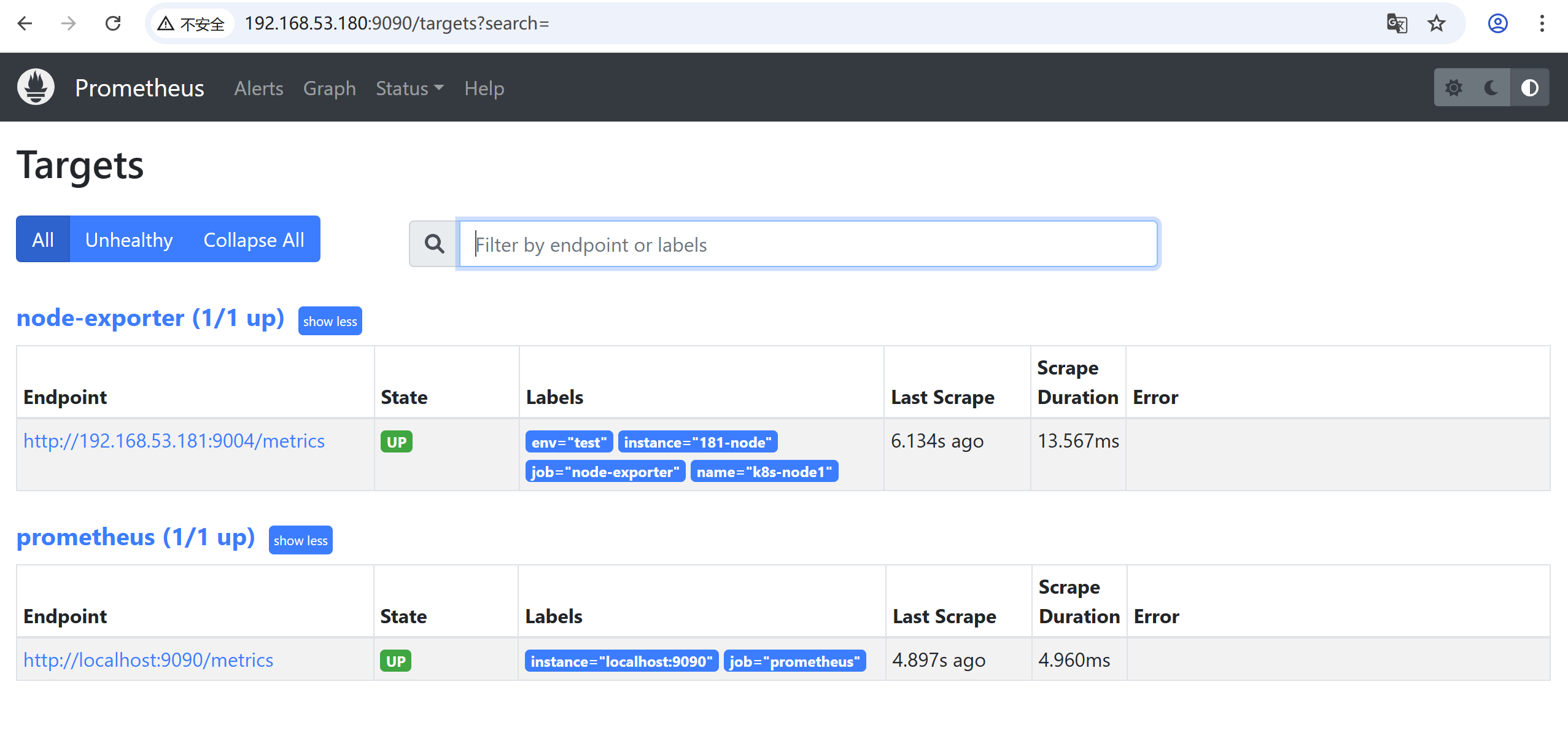
3、安装grafana
默认得Prometheus页面没有那么直观,安装grafana是为了页面显示更加直观
下载地址1:https://grafana.com/grafana/download?pg=graf&plcmt=deploy-box-1
下载地址2:https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm/Package/
[root@k8s-master1 prometheus]# yum install -y ./grafana-9.3.6-1.x86_64.rpm
启动grafana
[root@xianchaomaster1 ~]# systemctl start grafana-server
[root@xianchaomaster1 ~]# systemctl enable grafana-server默认端口:3000
默认用户名/密码:admin/admin
添加数据源


导入监控看板
监控面板下载地址:https://grafana.com/grafana/dashboards/
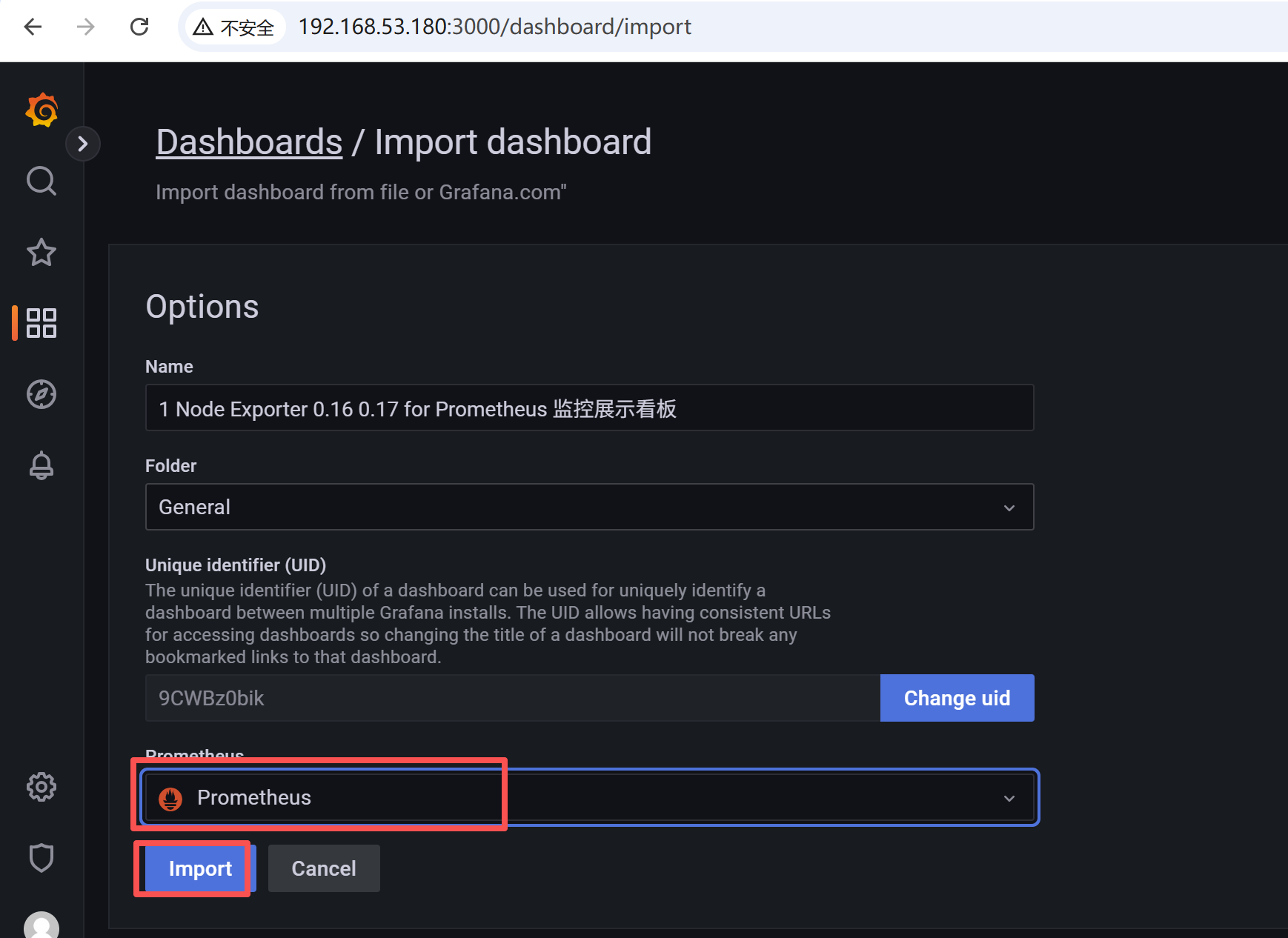

监控面板labels添加说明:
面板导入之后可以看到上面有以下信息:
interval 环境 主机名 节点
这写内容是读取的node-exporter-test-2025.json文件中的labels内容
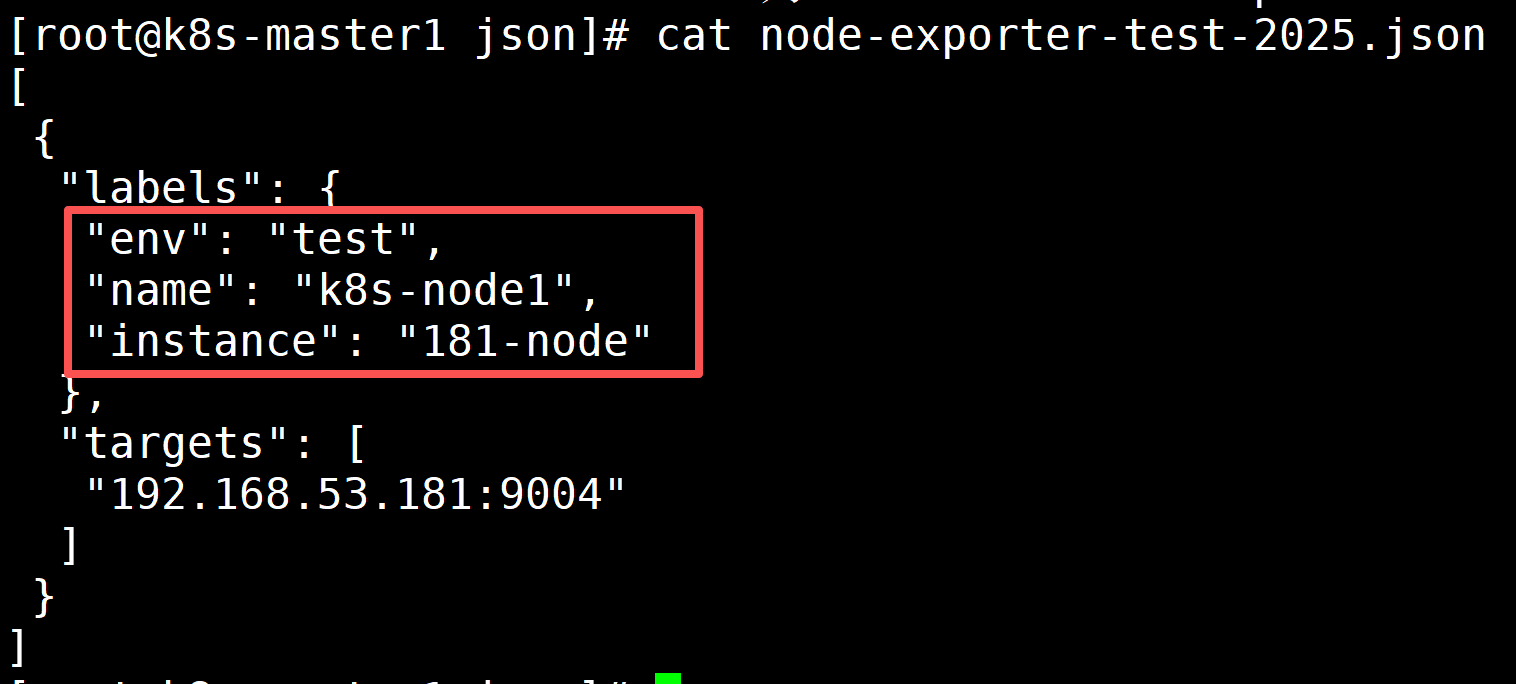
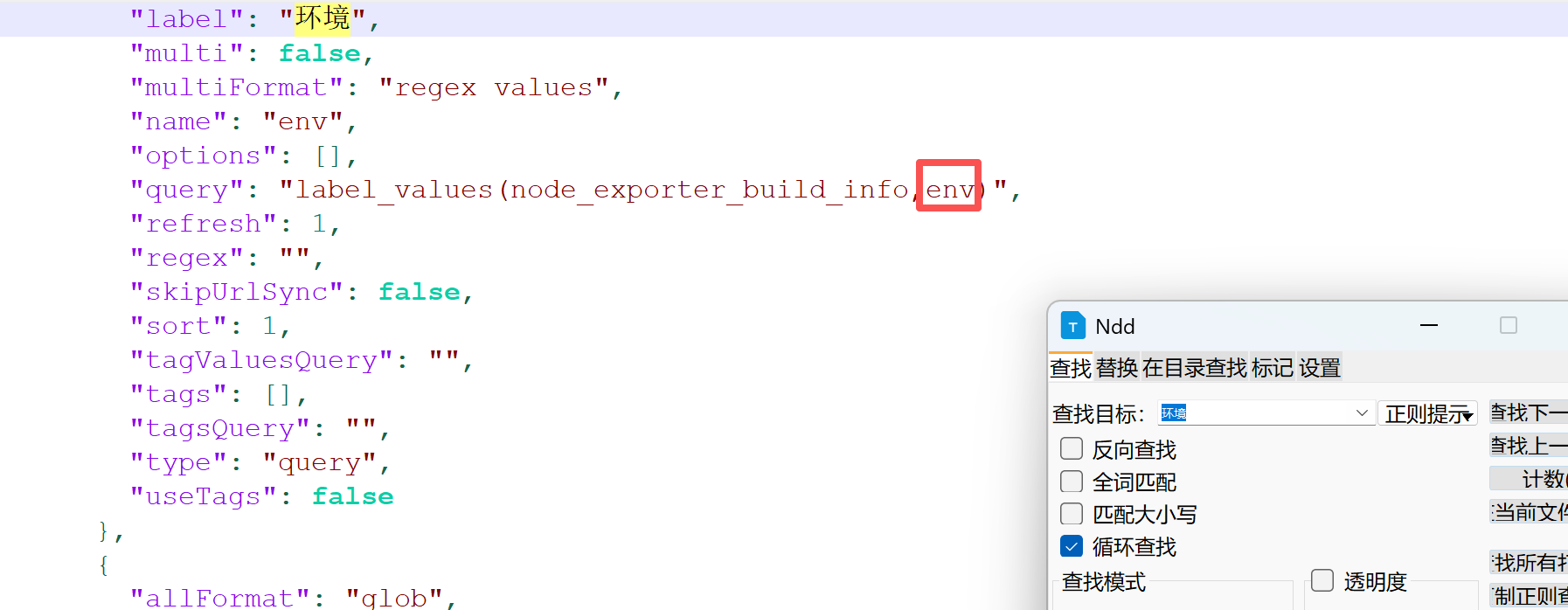
如果不知道labels中的key是什么可以打开面板的json文件搜索,比如:
环境:
主机名:

然后再去修改node-exporter-test-2025.json,配置对应的labels就可以了
4、配置发送告警服务alertmanager
Alertmanager下载地址:https://github.com/prometheus/alertmanager/releases
开启163邮箱smtp

新增授权密码
安装alertmanager
[root@k8s-master1 prometheus]# tar xvf alertmanager-0.25.0.linux-386.tar.gz
[root@k8s-master1 prometheus]# cd alertmanager-0.25.0.linux-386/
[root@k8s-master1 alertmanager-0.25.0.linux-386]# cp alertmanager.yml{,.bak}
[root@k8s-master1 alertmanager-0.25.0.linux-386]# vim alertmanager.ymlalertmanager.yml
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '发件人@163.com'
smtp_auth_username: '发件人@163.com'
smtp_auth_password: '授权码'
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: default-receiver
receivers:
- name: 'default-receiver'
email_configs:
- to: '收件邮箱'
send_resolved: trueglobal(全局发件参数)
| 字段 | 值 | 含义 |
| resolve_timeout | 1m | 警报从 触发→解除 的最大等待时间;1m 表示 1 分钟内若 Prometheus 没标记 resolved,Alertmanager 就认为是“仍着火” |
| smtp_smarthost | 'smtp.163.com:25' | 163 邮箱的 SMTP 服务器:端口; • 25 = 明文; • 465 = SSL; • 587 = STARTTLS(推荐,防拦截) |
| smtp_from | '发件人@163.com' | 发件人(必须是你 163 账号的同域地址) |
| smtp_auth_username | '发件人@163.com' | SMTP 登录账号(163 要求 = 发件人) |
| smtp_auth_password | '******************' | 163 授权码(不是登录密码! 在 163 邮箱 → 设置 → POP3/SMTP → 生成授权码 |
| smtp_require_tls | false | 关闭 TLS(25 端口常被拦截/限速,建议改 587 + true) |
route(路由规则)
| 字段 | 值 | 含义 |
|---|---|---|
| group_by | [alertname] | 把 同名警报 聚成一条通知(避免轰炸) |
| group_wait | 10s | 第一批警报到达后 等 10 秒 看有没有同名警报,一起发 |
| group_interval | 10s | 同一组 下一次通知的间隔(10s 内不再重复发) |
| repeat_interval | 10m | 相同组 若一直未解除,每 10 分钟 再发一次提醒 |
| receiver | default-receiver | 指向下面 receivers.name 的引用 |
receivers(收件人列表)
| 字段 | 值 | 含义 |
|---|---|---|
| name | default-receiver | 被 route.receiver 引用的名字 |
| email_configs.to | 收件人@163.com | 最终收件人(可以是任意邮箱 |
| send_resolved | true | 警报 解除后 也发一封“已恢复”邮件 |
创建alertmanager.service服务启停控制文件
端口要和prometheus.yml文件中alerting下配置的一致
cat /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager
After=network.target
[Service]
User=root
Group=root
ExecStart=/approot1/prometheus/alertmanager-0.25.0.linux-386/alertmanager \
--config.file=/approot1/prometheus/alertmanager-0.25.0.linux-386/alertmanager.yml \
--storage.path=/approot1/prometheus/alertmanager-0.25.0.linux-386/alertmanager-0.25.0.linux-386/ \
--web.listen-address=":9093"
Restart=always
RestartSec=3
[Install]
WantedBy=multi-user.target重载systemd配置并启动服务
systemctl daemon-reload
systemctl start alertmanager
添加开机自启动:
systemctl enable alertmanager浏览器访问验证:http://192.168.53.180:9093/
5、模拟出发告警发送通知
因为服务器配置不高,已经触CPU发告警了
告警邮件发送成功

prometheus UI页面查看也能看到触发告警
手动模拟告警
修改node-rules.yml
让磁盘容量使用率大于10%就告警
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 10
重启prometheus服务让告警规则快速更新成我们修改后的值

查看prometheus可以看到告警已触发
告警邮件

告警恢复测试
把刚刚修改的node-rules.yml内容的值改回80,热加载配置:curl -X POST http://192.168.53.180:9090/-/reload

告警恢复邮件


 浙公网安备 33010602011771号
浙公网安备 33010602011771号