
sam3 (2)开发
下部计划
1-2相邻帧添加iou目标跟踪
1-2 根据语义编码相似度——IOU重合度联合匈牙利匹配。
但是考虑到都是房子,无所谓寓意相似度。
2 单个目标个周围目标的联合信息
3 mask形状匹配
尺度大小 方向对齐
类似于dow2聚类加速匹配
4 信息赋予3D地图点
根据当前位置,使用地图点投影
5 重定位
如何加速匹配
意外发现
1 跟踪目标分为前景和背景
1-1背景 例如房子和环境是静止的,且不会有遮挡的情况,我们将当前帧使用H矩阵变换到上一帧,精致的物体是基本重合的。不需要卡尔曼运动跟踪预测。
1-2 如果画面中有运动的车辆,单纯的H变换后,车辆发生了运动,需要用卡尔曼预测这个运动然后,用预测框取和当上一帧匹配。
挥着遇到临时遮挡情况,通过卡尔曼继续预测
2 如果离开画面重新匹配,需要记住目标的样子
样例N - *
1检测画框,并且合并框,并且合并mask
2按照框大小,然后融合重叠的框
3 匈牙利匹配跟踪
4 从文件夹读取照片
5保存结果
✅ 1. 多特征融合跟踪 外观特征:颜色直方图 + 纹理特征(均值、标准差) 运动特征:匀速运动模型 + 位置预测 + 速度平滑更新 几何特征:IoU重叠度计算 ✅ 2. 智能匹配策略 综合相似度计算:可配置权重(外观0.4、运动0.3、IoU0.3) 渐进式外观更新:确认目标的外观特征渐进更新 运动模型校正:基于历史轨迹的速度预测 ✅ 3. 跟踪状态管理 目标确认机制:min_hits=2次匹配后确认跟踪 丢失目标处理:max_age=10帧内可重新关联 生命周期管理:自动清理长时间丢失的目标 ✅ 4. 可视化增强 跟踪状态显示:C=已确认,U=未确认 详细信息:显示命中次数H和年龄A(如C(H5A0)) 颜色一致性:同一ID始终相同颜色 ✅ 5. 内存优化 定期内存清理:每5张图像清理一次 简化特征提取:减少特征维度,优化内存使用 图像缩放:大图像自动缩小处理
、
样例6
1 1个目标有多个历史特征如何找最好的和融合,逐个匹配效率太慢
def get_similarity(self, other_features, method='cosine'):
"""计算与另一个特征的相似度"""
if not self.feature_history or other_features is None:
return 0.0
# 使用历史特征计算最大相似度
similarities = []
for hist_feat in self.feature_history:
if method == 'cosine':
sim = np.dot(hist_feat, other_features) / (
np.linalg.norm(hist_feat) * np.linalg.norm(other_features) + 1e-8)
similarities.append(sim)
return max(similarities) if similarities else 0.0
代码
1注意权重
# 计算mask相似度
mask_similarity = self.calculate_mask_similarity(transformed_mask, curr_mask)
# 计算变换后框的IoU
iou = self.calculate_iou(transformed_box, curr_box)
# 计算ReID特征相似度
reid_similarity = track.get_similarity(curr_reid) if curr_reid is not None else 0.0
# 综合相似度(ReID权重较高)
total_similarity = (0.1 * mask_similarity + 0.8 * iou + 0.1 * reid_similarity)
cost_matrix[i, j] = 1 - total_similarity
而且对于地面建筑物,经过H变化以后,只用IOU就可以了
2 注意特征保留树木 会导致内存变大
# 更新特征历史
if reid_features is not None:
self.reid_features = reid_features
self.feature_history.append(reid_features)
# 保持最近的特征
if len(self.feature_history) > 10:
self.feature_history.pop(0)
import torch
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib.patches as patches
import time
import os
import glob
from scipy.optimize import linear_sum_assignment # 匈牙利匹配算法
import colorsys
import gc
import matplotlib
matplotlib.use('TkAgg')
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="tkinter")
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore")
# 新增导入
import cv2
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
# 内存优化设置
os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'expandable_segments:True'
torch.backends.cudnn.benchmark = True
torch.cuda.empty_cache()
#################################### For Image ####################################
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
class ReIDNetwork(nn.Module):
"""ReID网络用于提取目标外观特征"""
def __init__(self, feature_dim=512):
super(ReIDNetwork, self).__init__()
# 使用预训练的ResNet作为骨干网络
self.backbone = models.resnet50(pretrained=True)
# 移除分类层
self.backbone = nn.Sequential(*list(self.backbone.children())[:-2])
# 全局平均池化
self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
# 特征降维
self.feature_reduction = nn.Sequential(
nn.Linear(2048, feature_dim),
nn.BatchNorm1d(feature_dim),
nn.ReLU(inplace=True),
nn.Linear(feature_dim, feature_dim // 2),
nn.BatchNorm1d(feature_dim // 2),
nn.ReLU(inplace=True),
)
self.feature_dim = feature_dim // 2
# 图像预处理
self.transform = transforms.Compose([
transforms.Resize((256, 128)), # ReID标准尺寸
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def forward(self, x):
"""前向传播"""
features = self.backbone(x)
features = self.global_avg_pool(features)
features = features.view(features.size(0), -1)
features = self.feature_reduction(features)
# L2归一化
features = nn.functional.normalize(features, p=2, dim=1)
return features
def extract_features_from_crop(self, image, box):
"""从图像裁剪中提取特征"""
try:
# 裁剪目标区域
x1, y1, x2, y2 = map(int, box)
x1 = max(0, x1)
y1 = max(0, y1)
x2 = min(image.width, x2)
y2 = min(image.height, y2)
if x2 <= x1 or y2 <= y1:
return None
crop = image.crop((x1, y1, x2, y2))
# 转换为RGB(处理可能的RGBA图像)
if crop.mode != 'RGB':
crop = crop.convert('RGB')
# 预处理
crop_tensor = self.transform(crop).unsqueeze(0)
# 提取特征
with torch.no_grad():
features = self.forward(crop_tensor)
return features.squeeze(0).cpu().numpy()
except Exception as e:
print(f"ReID特征提取错误: {e}")
return None
class TrackState:
"""跟踪状态枚举"""
TEMPORARY = "T" # 临时跟踪(跟踪时间少于5帧)
CONFIRMED = "C" # 已确认(连续跟踪5帧以上)
class Track:
"""单个目标的跟踪信息"""
def __init__(self, track_id, box, mask, score, reid_features=None, is_temporary=True):
self.track_id = track_id
self.box = box
self.mask = mask
self.score = score
self.reid_features = reid_features if reid_features is not None else []
# 跟踪状态:临时跟踪或已确认
self.state = TrackState.TEMPORARY if is_temporary else TrackState.CONFIRMED
self.hit_streak = 1 # 连续匹配次数
self.miss_count = 0 # 连续丢失次数
self.age = 1 # 跟踪年龄(帧数)
self.is_temporary = is_temporary # 是否为临时跟踪
# 历史记录
self.feature_history = []
self.box_history = [box.copy()]
if reid_features is not None:
self.feature_history.append(reid_features)
def update(self, box, mask, score, reid_features=None):
"""更新跟踪状态"""
self.box = box
self.mask = mask
self.score = score
self.age += 1
self.hit_streak += 1
self.miss_count = 0
# 检查是否应该确认跟踪(连续跟踪5帧以上)
if self.is_temporary and self.hit_streak >= 3:
self.state = TrackState.CONFIRMED
self.is_temporary = False
print(f"目标确认: TrackID {self.track_id} 已从临时转为确认状态")
# 更新特征历史
if reid_features is not None:
self.reid_features = reid_features
self.feature_history.append(reid_features)
# 保持最近的特征
if len(self.feature_history) > 10:
self.feature_history.pop(0)
# 更新框历史
self.box_history.append(box.copy())
if len(self.box_history) > 10:
self.box_history.pop(0)
def mark_missed(self):
"""标记目标丢失"""
self.miss_count += 1
self.hit_streak = 0
def is_confirmed(self):
"""返回是否已确认(连续跟踪5帧以上)"""
return self.state == TrackState.CONFIRMED
def is_temporary_track(self):
"""返回是否为临时跟踪"""
return self.is_temporary
def should_remove(self, max_miss_count=3):
"""判断是否应该移除跟踪(丢失太久)"""
# 临时跟踪丢失更快被移除
if self.is_temporary:
return self.miss_count > 1 # 临时跟踪丢失5帧就移除
else:
return self.miss_count > max_miss_count # 确认跟踪可以丢失更久
def get_similarity(self, other_features, method='cosine'):
"""计算与另一个特征的相似度"""
if not self.feature_history or other_features is None:
return 0.0
# 使用历史特征计算最大相似度
similarities = []
for hist_feat in self.feature_history:
if method == 'cosine':
sim = np.dot(hist_feat, other_features) / (
np.linalg.norm(hist_feat) * np.linalg.norm(other_features) + 1e-8)
similarities.append(sim)
return max(similarities) if similarities else 0.0
class FeatureBasedTracker:
"""基于特征点的目标跟踪器,适用于无人机俯视图像"""
def __init__(self, iou_threshold=0.3, min_matches=10, ransac_thresh=5.0,
reid_threshold=0.7, confirm_threshold=5):
self.iou_threshold = iou_threshold
self.min_matches = min_matches
self.ransac_thresh = ransac_thresh
self.reid_threshold = reid_threshold
self.confirm_threshold = confirm_threshold
self.next_id = 0
self.next_temp_id = 0 # 临时ID计数器
self.tracks = {} # {track_id: Track object}
self.temporary_tracks = {} # 临时跟踪字典
self.previous_image = None
self.previous_keypoints = None
self.previous_descriptors = None
self.track_colors = {}
# 特征检测器
self.sift = cv2.SIFT_create()
self.orb = cv2.ORB_create(2000)
# 初始化ReID网络
self.reid_net = ReIDNetwork()
self.reid_net.eval()
def extract_reid_features(self, image, boxes):
"""为所有边界框提取ReID特征"""
features = []
for box in boxes:
feature = self.reid_net.extract_features_from_crop(image, box)
features.append(feature)
return features
def extract_features(self, image):
"""提取图像特征点"""
gray = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2GRAY)
# 尝试SIFT,如果失败则使用ORB
try:
keypoints, descriptors = self.sift.detectAndCompute(gray, None)
if descriptors is not None and len(descriptors) > 10:
return keypoints, descriptors
except:
pass
# 使用ORB作为备用
keypoints, descriptors = self.orb.detectAndCompute(gray, None)
return keypoints, descriptors
def calculate_homography(self, kp1, desc1, kp2, desc2):
"""计算两帧之间的单应性矩阵"""
if desc1 is None or desc2 is None or len(desc1) < 4 or len(desc2) < 4:
return None
# 根据描述符类型选择匹配方法
if desc1.dtype == np.float32: # SIFT描述符
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(desc1, desc2, k=2)
good_matches = []
for match_pair in matches:
if len(match_pair) == 2:
m, n = match_pair
if m.distance < 0.7 * n.distance:
good_matches.append(m)
else: # ORB描述符
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(desc1, desc2)
matches = sorted(matches, key=lambda x: x.distance)
good_matches = matches[:min(50, len(matches))]
if len(good_matches) < self.min_matches:
return None
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
try:
H, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, self.ransac_thresh)
return H
except:
return None
def transform_mask(self, mask, H, target_shape):
"""使用单应性矩阵变换mask"""
try:
mask_np = mask.cpu().numpy().squeeze().astype(np.uint8)
transformed_mask = cv2.warpPerspective(mask_np, H, (target_shape[1], target_shape[0]))
transformed_mask = (transformed_mask > 0.5).astype(np.float32)
return torch.from_numpy(transformed_mask).unsqueeze(0)
except:
return mask
def transform_box(self, box, H):
"""使用单应性矩阵变换边界框"""
try:
x1, y1, x2, y2 = box
corners = np.array([[[x1, y1]], [[x2, y1]], [[x2, y2]], [[x1, y2]]], dtype=np.float32)
transformed_corners = cv2.perspectiveTransform(corners, H)
tx1 = transformed_corners[:, :, 0].min()
ty1 = transformed_corners[:, :, 1].min()
tx2 = transformed_corners[:, :, 0].max()
ty2 = transformed_corners[:, :, 1].max()
return [max(0, tx1), max(0, ty1), max(0, tx2), max(0, ty2)]
except:
return box
def calculate_mask_similarity(self, mask1, mask2):
"""计算两个mask的相似度"""
try:
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
intersection = np.logical_and(mask1_np, mask2_np)
union = np.logical_or(mask1_np, mask2_np)
if np.sum(union) == 0:
return 0.0
iou = np.sum(intersection) / np.sum(union)
mask1_area = np.sum(mask1_np)
mask2_area = np.sum(mask2_np)
if max(mask1_area, mask2_area) == 0:
area_similarity = 0.0
else:
area_similarity = 1 - abs(mask1_area - mask2_area) / max(mask1_area, mask2_area)
similarity = 0.7 * iou + 0.3 * area_similarity
return similarity
except:
return 0.0
def hungarian_matching_with_similarity(self, previous_tracks, current_masks, current_boxes,
current_reid_features, H, image_shape):
"""使用匈牙利算法进行基于相似度的匹配"""
if len(previous_tracks) == 0 or len(current_masks) == 0:
return []
cost_matrix = np.ones((len(previous_tracks), len(current_masks)))
for i, track in enumerate(previous_tracks):
prev_mask = track.mask
prev_box = track.box
# 变换前一帧的mask到当前帧坐标系
if H is not None:
try:
transformed_mask = self.transform_mask(prev_mask, H, image_shape)
transformed_box = self.transform_box(prev_box, H)
except:
transformed_mask = prev_mask
transformed_box = prev_box
else:
transformed_mask = prev_mask
transformed_box = prev_box
for j, (curr_mask, curr_box, curr_reid) in enumerate(
zip(current_masks, current_boxes, current_reid_features)):
# 计算mask相似度
mask_similarity = self.calculate_mask_similarity(transformed_mask, curr_mask)
# 计算变换后框的IoU
iou = self.calculate_iou(transformed_box, curr_box)
# 计算ReID特征相似度
reid_similarity = track.get_similarity(curr_reid) if curr_reid is not None else 0.0
# 综合相似度(ReID权重较高)
total_similarity = (0.1 * mask_similarity + 0.8 * iou + 0.1 * reid_similarity)
cost_matrix[i, j] = 1 - total_similarity
#print('i',i,'j',j,"mask_similarity",mask_similarity,'iou',iou,'reid_similarity',reid_similarity)
# 匈牙利算法匹配
row_ind, col_ind = linear_sum_assignment(cost_matrix)
matches = []
for i, j in zip(row_ind, col_ind):
if cost_matrix[i, j] <= (1 - self.iou_threshold):
matches.append((i, j, 1 - cost_matrix[i, j]))
return matches
def calculate_iou(self, box1, box2):
"""计算两个边界框的IoU"""
try:
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
return inter_area / union_area if union_area > 0 else 0.0
except:
return 0.0
def get_track_color(self, track_id):
"""为track_id获取或生成颜色"""
if track_id not in self.track_colors:
hue = (track_id * 0.618033988749895) % 1.0
saturation = 0.8 + (track_id % 3) * 0.1
value = 0.8 + (track_id % 2) * 0.2
r, g, b = colorsys.hsv_to_rgb(hue, saturation, value)
self.track_colors[track_id] = (int(r * 255), int(g * 255), int(b * 255))
return self.track_colors[track_id]
def get_track_status(self, track_id):
"""获取跟踪状态"""
if track_id in self.tracks:
return self.tracks[track_id].state
elif track_id in self.temporary_tracks:
return self.temporary_tracks[track_id].state
return TrackState.TEMPORARY
def is_temporary_track(self, track_id):
"""判断是否为临时跟踪"""
if track_id in self.temporary_tracks:
return True
elif track_id in self.tracks:
return False
return True # 默认返回True,避免错误
def promote_temporary_to_confirmed(self, temp_track_id):
"""将临时跟踪提升为确认跟踪"""
if temp_track_id not in self.temporary_tracks:
return None
temp_track = self.temporary_tracks[temp_track_id]
# 分配新的永久ID
new_track_id = self.next_id
self.next_id += 1
# 创建确认跟踪
confirmed_track = Track(
new_track_id, temp_track.box, temp_track.mask, temp_track.score,
temp_track.reid_features, is_temporary=False
)
# 复制历史状态
confirmed_track.hit_streak = temp_track.hit_streak
confirmed_track.miss_count = temp_track.miss_count
confirmed_track.age = temp_track.age
confirmed_track.feature_history = temp_track.feature_history.copy()
confirmed_track.box_history = temp_track.box_history.copy()
# 添加到确认跟踪字典
self.tracks[new_track_id] = confirmed_track
# 移除临时跟踪
del self.temporary_tracks[temp_track_id]
print(f"临时跟踪 {temp_track_id} 已提升为确认跟踪 {new_track_id}")
return new_track_id
def update(self, current_image, current_masks, current_boxes, current_scores):
"""更新跟踪器状态"""
current_track_ids = []
if len(current_masks) == 0:
print("警告:当前帧没有检测到目标")
# 标记所有跟踪为丢失
for track in list(self.tracks.values()) + list(self.temporary_tracks.values()):
track.mark_missed()
self.previous_image = current_image
self.previous_keypoints, self.previous_descriptors = self.extract_features(current_image)
return current_track_ids
# 提取ReID特征
current_reid_features = self.extract_reid_features(current_image, current_boxes)
current_keypoints, current_descriptors = self.extract_features(current_image)
# 计算单应性矩阵
H = None
if self.previous_image is not None and current_keypoints is not None and self.previous_keypoints is not None:
H = self.calculate_homography(self.previous_keypoints, self.previous_descriptors,
current_keypoints, current_descriptors)
image_shape = current_masks[0].shape[-2:] if len(current_masks) > 0 else (current_image.height, current_image.width)
# 合并所有跟踪(确认+临时)
all_previous_tracks = list(self.tracks.values()) + list(self.temporary_tracks.values())
if len(all_previous_tracks) == 0:
# 第一帧初始化:所有新目标都作为临时跟踪
for i, (mask, box, score, reid_feat) in enumerate(
zip(current_masks, current_boxes, current_scores, current_reid_features)):
temp_track_id = self.next_temp_id
self.next_temp_id += 1
self.temporary_tracks[temp_track_id] = Track(
temp_track_id, box, mask, score, reid_feat, is_temporary=True
)
current_track_ids.append(temp_track_id)
print(f"新临时目标: TempTrackID {temp_track_id}, 状态: {self.temporary_tracks[temp_track_id].state}")
else:
# 使用匈牙利算法匹配
matches = self.hungarian_matching_with_similarity(
all_previous_tracks, current_masks, current_boxes, current_reid_features,
H, image_shape
)
# 分配跟踪ID
current_track_ids = [-1] * len(current_masks)
used_track_ids = set()
promoted_tracks = {} # 记录临时跟踪提升映射
# 处理匹配的目标
for i, j, similarity in matches:
if i < len(all_previous_tracks):
track = all_previous_tracks[i]
track_id = track.track_id
# 检查跟踪是否仍然存在(可能在其他匹配中被删除)
track_exists = (track_id in self.tracks) or (track_id in self.temporary_tracks)
if not track_exists:
continue
# 更新跟踪器状态
if track_id in self.tracks: # 确认跟踪
self.tracks[track_id].update(
current_boxes[j], current_masks[j], current_scores[j],
current_reid_features[j]
)
current_track_ids[j] = track_id
used_track_ids.add(track_id)
print(f"确认目标匹配: TrackID {track_id} -> 检测 {j}, 相似度: {similarity:.3f}, "
f"状态: {self.tracks[track_id].state}, 连续匹配: {self.tracks[track_id].hit_streak}")
elif track_id in self.temporary_tracks: # 临时跟踪
self.temporary_tracks[track_id].update(
current_boxes[j], current_masks[j], current_scores[j],
current_reid_features[j]
)
# 检查是否应该提升为确认跟踪
if self.temporary_tracks[track_id].is_confirmed():
new_track_id = self.promote_temporary_to_confirmed(track_id)
if new_track_id is not None:
current_track_ids[j] = new_track_id
used_track_ids.add(new_track_id)
promoted_tracks[track_id] = new_track_id
else:
current_track_ids[j] = track_id
used_track_ids.add(track_id)
else:
current_track_ids[j] = track_id
used_track_ids.add(track_id)
# 使用安全的访问方式
if track_id in self.temporary_tracks:
track_info = self.temporary_tracks[track_id]
print(f"临时目标匹配: TempTrackID {track_id} -> 检测 {j}, 相似度: {similarity:.3f}, "
f"状态: {track_info.state}, 连续匹配: {track_info.hit_streak}")
elif track_id in promoted_tracks:
new_track_id = promoted_tracks[track_id]
if new_track_id in self.tracks:
track_info = self.tracks[new_track_id]
print(f"临时目标提升: TempTrackID {track_id} -> TrackID {new_track_id}, 状态: {track_info.state}")
# 处理未匹配的目标(新目标)- 创建临时跟踪
for j in range(len(current_masks)):
if current_track_ids[j] == -1:
temp_track_id = self.next_temp_id
self.next_temp_id += 1
current_track_ids[j] = temp_track_id
self.temporary_tracks[temp_track_id] = Track(
temp_track_id, current_boxes[j], current_masks[j],
current_scores[j], current_reid_features[j], is_temporary=True
)
print(f"新临时目标: TempTrackID {temp_track_id}, 状态: {self.temporary_tracks[temp_track_id].state}")
# 标记未匹配的跟踪为丢失(使用安全的访问方式)
tracks_to_mark_missed = []
for track_id, track in list(self.tracks.items()):
if track_id not in used_track_ids:
tracks_to_mark_missed.append((track_id, track, 'confirmed'))
for track_id, track in list(self.temporary_tracks.items()):
if track_id not in used_track_ids and track_id not in promoted_tracks:
tracks_to_mark_missed.append((track_id, track, 'temporary'))
for track_id, track, track_type in tracks_to_mark_missed:
track.mark_missed()
if track_type == 'confirmed':
print(f"确认目标丢失: TrackID {track_id}, 连续丢失: {track.miss_count}, 状态: {track.state}")
else:
print(f"临时目标丢失: TempTrackID {track_id}, 连续丢失: {track.miss_count}, 状态: {track.state}")
# 清理丢失太久的跟踪
self._cleanup_lost_tracks()
# 更新前一帧信息
self.previous_image = current_image
self.previous_keypoints = current_keypoints
self.previous_descriptors = current_descriptors
return current_track_ids
def _cleanup_lost_tracks(self):
"""清理丢失的跟踪"""
# 清理确认跟踪
tracks_to_remove = []
for track_id, track in self.tracks.items():
if track.should_remove():
tracks_to_remove.append(track_id)
for track_id in tracks_to_remove:
if track_id in self.tracks:
del self.tracks[track_id]
print(f"移除确认跟踪: TrackID {track_id}")
# 清理临时跟踪
temp_tracks_to_remove = []
for track_id, track in self.temporary_tracks.items():
if track.should_remove():
temp_tracks_to_remove.append(track_id)
for track_id in temp_tracks_to_remove:
if track_id in self.temporary_tracks:
del self.temporary_tracks[track_id]
print(f"移除临时跟踪: TempTrackID {track_id}")
def load_moad(mode_path="sam3.pt"):
"""加载模型"""
model_load_start_time = time.time()
model = build_sam3_image_model(
checkpoint_path=mode_path
)
processor = Sam3Processor(model, confidence_threshold=0.3)
model_load_end_time = time.time()
model_load_time = model_load_end_time - model_load_start_time
print(f"模型加载时间: {model_load_time:.3f} 秒")
return processor
def Get_image_mask(processor, image_path):
"""获取图像分割结果"""
detection_start_time = time.time()
image = Image.open(image_path)
inference_state = processor.set_image(image)
output = processor.set_text_prompt(state=inference_state, prompt="building")
masks, boxes, scores = output["masks"], output["boxes"], output["scores"]
detection_end_time = time.time()
detection_time = detection_end_time - detection_start_time
print(f"检测单张时间: {detection_time:.3f} 秒")
print(f"原始检测到 {len(masks)} 个分割结果")
print(f"掩码形状: {masks.shape}")
return masks, boxes, scores
def Ronghe_calculate_iou(box1, box2):
"""计算两个边界框的IoU"""
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
if union_area == 0:
return 0.0
iou_2 = inter_area / box2_area
iou_1 = inter_area / box1_area
iou = max(iou_2, iou_1)
return iou
def calculate_mask_overlap(mask1, mask2):
"""计算两个掩码的重叠比例"""
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
intersection = np.logical_and(mask1_np, mask2_np)
mask1_area = np.sum(mask1_np)
if mask1_area == 0:
return 0.0
overlap_ratio = np.sum(intersection) / mask1_area
return overlap_ratio
def fuse_overlapping_masks(masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6):
"""融合重叠的掩码和边界框"""
if len(masks) == 0:
return masks, boxes, scores
boxes_np = boxes.cpu().numpy().copy()
scores_np = scores.cpu().numpy().copy()
areas = []
for box in boxes_np:
x1, y1, x2, y2 = box
width = x2 - x1
height = y2 - y1
area = width * height
areas.append(area)
areas_np = np.array(areas)
sorted_indices = np.argsort(areas_np)[::-1]
boxes_sorted = boxes_np[sorted_indices]
scores_sorted = scores_np[sorted_indices]
areas_sorted = areas_np[sorted_indices]
masks_list = [masks[i] for i in range(len(masks))]
masks_sorted = [masks_list[i] for i in sorted_indices]
keep_indices = []
suppressed = set()
fused_masks = masks_sorted.copy()
for i in range(len(boxes_sorted)):
if i in suppressed:
continue
keep_indices.append(i)
current_mask = fused_masks[i]
for j in range(i + 1, len(boxes_sorted)):
if j in suppressed:
continue
iou = Ronghe_calculate_iou(boxes_sorted[i], boxes_sorted[j])
if iou > iou_threshold:
mask_overlap = calculate_mask_overlap(current_mask, masks_sorted[j])
suppressed.add(j)
fused_mask = fuse_two_masks(current_mask, masks_sorted[j])
fused_masks[i] = fused_mask
current_mask = fused_mask
print(f"融合检测结果: 索引 {sorted_indices[i]} (面积: {areas_sorted[i]:.1f}) 融合索引 {sorted_indices[j]} (面积: {areas_sorted[j]:.1f})",
" iou:", iou, " mask重叠:", mask_overlap)
else:
pass
final_indices = [sorted_indices[i] for i in keep_indices]
final_masks_list = [fused_masks[i] for i in keep_indices]
final_masks = torch.stack(final_masks_list)
final_boxes = boxes[final_indices]
final_scores = scores[final_indices]
print(f"融合后剩余 {len(final_masks)} 个分割结果 (减少了 {len(masks) - len(final_masks)} 个)")
return final_masks, final_boxes, final_scores
def fuse_two_masks(mask1, mask2):
"""将两个mask融合"""
fused_mask = torch.logical_or(mask1, mask2).float()
return fused_mask
def overlay_masks_with_tracking(image, masks, boxes, scores, track_ids, tracker, fusion_mode=False):
"""在图像上叠加掩码,并显示跟踪ID和状态"""
image = image.convert("RGB")
draw = ImageDraw.Draw(image)
try:
font = ImageFont.truetype("SimHei.ttf", 40)
except:
try:
font = ImageFont.truetype("Arial.ttf", 40)
except:
font = ImageFont.load_default()
masks_np = masks.cpu().numpy().astype(np.uint8)
masks_np = masks_np.squeeze(1)
boxes_np = boxes.cpu().numpy()
scores_np = scores.cpu().numpy()
for i, (mask, box, score, track_id) in enumerate(zip(masks_np, boxes_np, scores_np, track_ids)):
# 获取跟踪状态和是否为临时跟踪
status = tracker.get_track_status(track_id)
is_temporary = tracker.is_temporary_track(track_id)
# 获取跟踪的详细信息
track_info = None
if track_id in tracker.tracks:
track_info = tracker.tracks[track_id]
elif track_id in tracker.temporary_tracks:
track_info = tracker.temporary_tracks[track_id]
if track_info:
hit_streak = track_info.hit_streak
miss_count = track_info.miss_count
age = track_info.age
else:
hit_streak = 0
miss_count = 0
age = 1
# 根据跟踪状态决定颜色和透明度
if status == TrackState.CONFIRMED:
# 已确认目标(连续跟踪5帧以上):使用彩色显示
color = tracker.get_track_color(track_id)
mask_alpha = 128 # 正常透明度
outline_width = 3
else:
# 临时目标:使用灰色50%透明度
color = (128, 128, 128) # 灰色
mask_alpha = 64 # 50%透明度
outline_width = 2
if mask.ndim == 3:
mask = mask.squeeze(0)
alpha_mask = (mask * mask_alpha).astype(np.uint8)
overlay = Image.new("RGBA", image.size, color + (mask_alpha,))
alpha = Image.fromarray(alpha_mask, mode='L')
overlay.putalpha(alpha)
image = Image.alpha_composite(image.convert("RGBA"), overlay).convert("RGB")
draw = ImageDraw.Draw(image)
x1, y1, x2, y2 = box
x1 = max(0, min(x1, image.width))
y1 = max(0, min(y1, image.height))
x2 = max(0, min(x2, image.width))
y2 = max(0, min(y2, image.height))
# 根据状态选择边框样式
if status == TrackState.CONFIRMED:
# 已确认目标:实线边框
draw.rectangle([x1, y1, x2, y2], outline=color, width=outline_width)
else:
# 临时目标:虚线边框
draw.rectangle([x1, y1, x2, y2], outline=color, width=outline_width)
# 绘制虚线效果
dash_length = 5
for x in range(int(x1), int(x2), dash_length*2):
draw.line([x, y1, x+dash_length, y1], fill=color, width=2)
draw.line([x, y2, x+dash_length, y2], fill=color, width=2)
for y in range(int(y1), int(y2), dash_length*2):
draw.line([x1, y, x1, y+dash_length], fill=color, width=2)
draw.line([x2, y, x2, y+dash_length], fill=color, width=2)
# 构建显示文本
track_prefix = "Temp" if is_temporary else "Track"
if fusion_mode:
base_text = f"{track_prefix}:{track_id}({status}) F-ID:{i} S:{score:.2f}"
else:
base_text = f"{track_prefix}:{track_id}({status}) ID:{i} S:{score:.2f}"
# 添加跟踪统计信息
stat_text = f"H:{hit_streak} M:{miss_count} A:{age}"
full_text = f"{base_text}\n{stat_text}"
try:
# 计算文本尺寸
lines = full_text.split('\n')
text_bbox = [draw.textbbox((0, 0), line, font=font) for line in lines]
text_width = max(bbox[2] - bbox[0] for bbox in text_bbox)
text_height = sum(bbox[3] - bbox[1] for bbox in text_bbox) + 5 * (len(lines) - 1)
except:
text_width, text_height = 200, 40
text_x = x1
text_y = max(0, y1 - text_height - 5)
# 绘制文本背景(使用与目标相同的颜色)
draw.rectangle([text_x, text_y, text_x + text_width + 10, text_y + text_height + 5],
fill=color)
# 绘制文本(黑色文字在浅色背景上更清晰)
text_color = "black" if status == TrackState.CONFIRMED else "white"
y_offset = text_y + 2
for line in lines:
draw.text((text_x + 5, y_offset), line, fill=text_color, font=font)
y_offset += font.size + 2
return image
def extract_number_from_filename(filename):
"""从DJI_XXXX.JPG格式的文件名中提取数字"""
try:
if filename.startswith('DJI_') and filename.endswith(('.JPG', '.jpg', '.JPEG', '.jpeg')):
number_part = filename[4:].split('.')[0]
return int(number_part)
except (ValueError, IndexError):
pass
return float('inf')
def process_image_folder(processor, folder_path, output_dir="output"):
"""处理文件夹中的所有图像(使用增强的特征点跟踪器)"""
os.makedirs(output_dir, exist_ok=True)
image_extensions = ['*.jpg', '*.jpeg', '*.png', '*.bmp', '*.tiff', '*.tif', '*.JPG', '*.JPEG', '*.PNG']
image_files = []
for ext in image_extensions:
image_files.extend(glob.glob(os.path.join(folder_path, ext)))
image_files.sort(key=lambda x: extract_number_from_filename(os.path.basename(x)))
print(f"找到 {len(image_files)} 张图像")
# 使用增强的特征点跟踪器
tracker = FeatureBasedTracker(iou_threshold=0.3, min_matches=10, reid_threshold=0.7)
results = []
for i, image_path in enumerate(image_files):
print(f"\n{'='*50}")
print(f"处理第 {i+1}/{len(image_files)} 张图像: {os.path.basename(image_path)}")
try:
# 检测图像
masks, boxes, scores = Get_image_mask(processor, image_path)
if len(masks) == 0:
print("未检测到目标,跳过此图像")
# 更新跟踪器(标记丢失)
current_image = Image.open(image_path)
tracker.update(current_image, [], [], [])
del masks, boxes, scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 融合重叠的mask
fused_masks, fused_boxes, fused_scores = fuse_overlapping_masks(
masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6
)
if len(fused_boxes) == 0:
print("融合后无目标,跳过此图像")
current_image = Image.open(image_path)
tracker.update(current_image, [], [], [])
del masks, boxes, scores, fused_masks, fused_boxes, fused_scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 加载当前图像用于特征点跟踪
current_image = Image.open(image_path)
# 使用增强的特征点跟踪器进行目标跟踪
track_ids = tracker.update(current_image, fused_masks, fused_boxes.cpu().numpy(),
fused_scores.cpu().numpy())
# 打印跟踪统计信息
confirmed_count = sum(1 for tid in track_ids if tracker.get_track_status(tid) == TrackState.CONFIRMED)
temporary_count = sum(1 for tid in track_ids if tracker.get_track_status(tid) == TrackState.TEMPORARY)
print(f"跟踪统计: 总目标 {len(track_ids)}, 已确认 {confirmed_count}, 临时 {temporary_count}")
# 保存结果
image_name = os.path.splitext(os.path.basename(image_path))[0]
save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, i, tracker)
results.append({
'image_path': image_path,
'image_name': image_name,
'track_ids': track_ids,
'confirmed_count': confirmed_count,
'temporary_count': temporary_count
})
except Exception as e:
print(f"处理图像 {image_path} 时出错: {e}")
import traceback
traceback.print_exc()
finally:
variables_to_delete = ['masks', 'boxes', 'scores', 'fused_masks', 'fused_boxes',
'fused_scores', 'current_image']
for var_name in variables_to_delete:
if var_name in locals():
del locals()[var_name]
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
print(f"内存清理完成,准备处理下一张图像")
return results
def save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, image_index, tracker):
"""保存单张图像的结果"""
original_image = Image.open(image_path)
# 应用跟踪结果显示(传入tracker参数)
result_image_original = overlay_masks_with_tracking(
original_image, masks, boxes, scores,
list(range(len(masks))), tracker, fusion_mode=False
)
result_image_fused = overlay_masks_with_tracking(
original_image, fused_masks, fused_boxes, fused_scores,
track_ids, tracker, fusion_mode=True
)
# 创建并保存对比图像
create_comparison_image(
result_image_original, result_image_fused,
len(masks), len(fused_masks), output_dir, image_name, image_index, tracker
)
del original_image, result_image_original, result_image_fused
gc.collect()
def create_comparison_image(original_img, fused_img, n_original, n_fused, output_dir, image_name, image_index, tracker):
"""创建、保存并显示对比图像"""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
ax1.imshow(original_img)
ax1.set_title(f"Original Result - {image_name}: {n_original} segments", fontsize=14)
ax1.axis('off')
ax2.imshow(fused_img)
ax2.set_title(f"Fused with Tracking - {image_name}: {n_fused} segments", fontsize=14)
ax2.axis('off')
plt.tight_layout()
comparison_path = os.path.join(output_dir, f"segmentation_comparison_{image_name}.png")
plt.savefig(comparison_path, dpi=300, bbox_inches='tight', facecolor='white')
print(f"对比图像已保存: {comparison_path}")
if image_index < 3:
plt.show()
else:
plt.close(fig)
plt.close('all')
def main():
"""主函数"""
# 清空GPU缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.synchronize()
processor = load_moad("sam3.pt")
# 设置模型为评估模式并移到GPU
processor.model.eval()
folder_path = "/home/r9000k/v0_data/rtk/300_location_1130_15pm/images"
output_dir = "output"
try:
results = process_image_folder(processor, folder_path, output_dir)
# 打印最终统计信息
total_confirmed = sum(r['confirmed_count'] for r in results if 'confirmed_count' in r)
total_temporary = sum(r['temporary_count'] for r in results if 'temporary_count' in r)
print(f"\n处理完成!共处理 {len(results)} 张图像")
print(f"跟踪统计: 总确认目标 {total_confirmed}, 总临时目标 {total_temporary}")
print(f"结果保存在 {output_dir} 目录中")
except Exception as e:
print(f"处理过程中出错: {e}")
import traceback
traceback.print_exc()
finally:
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
if __name__ == "__main__":
main()
样例5 -*
有问题 待定
优化:
1对于房子静止目标 ,没必要 所有边界框提取ReID特征和历史匹配,加快速度。
目前这个代码是有的
2连续3帧跟踪成功的目标在分配ID 否则别进来干扰
3 完全丢失以后,重新出现的匹配
1检测画框,并且合并框,并且合并mask
2按照框大小,然后融合重叠的框
3 匈牙利匹配跟踪
4 从文件夹读取照片
5保存结果
6 内存管理
7 跟踪效果
计算H 变换 然后将当前帧变换到上一帧去
IOU匹配目标框和mask,
然后匈牙利匹配。
for j, (curr_mask, curr_box, curr_reid) in enumerate(
zip(current_masks, current_boxes, current_reid_features)):
# 计算mask相似度
mask_similarity = self.calculate_mask_similarity(transformed_mask, curr_mask)
# 计算变换后框的IoU
iou = self.calculate_iou(transformed_box, curr_box)
# 计算ReID特征相似度
reid_similarity = track.get_similarity(curr_reid) if curr_reid is not None else 0.0
# 综合相似度(ReID权重较高)
total_similarity = (0.4 * mask_similarity + 0.2 * iou + 0.4 * reid_similarity)
cost_matrix[i, j] = 1 - total_similarity
# 匈牙利算法匹配
row_ind, col_ind = linear_sum_assignment(cost_matrix)
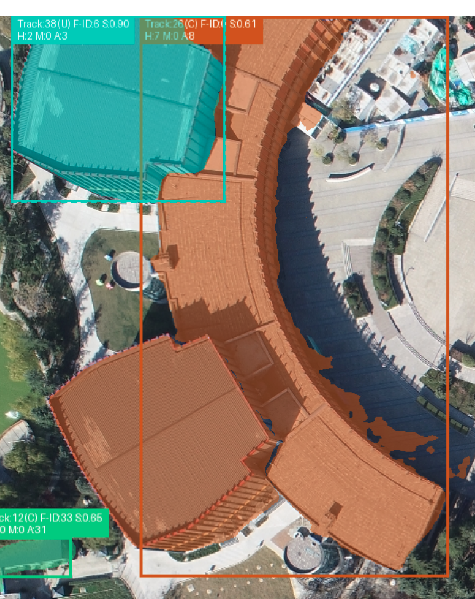
8 5次跟踪成功才分配ID,否则不分配。 5次以内用白色框显示,跟踪成功后采用颜色显示


1. ReID网络 (ReIDNetwork类)
- 使用预训练的ResNet50作为骨干网络
- 提取512维的外观特征向量
- 支持从图像裁剪中提取目标特征
- 特征进行L2归一化便于相似度计算
2. 跟踪状态管理 (Track类和 TrackState)
- U (Unconfirmed): 新目标,匹配次数少于3次
- C (Confirmed): 已确认目标,连续匹配3次以上
- 每个目标维护特征历史、匹配统计等信息
3. 增强的跟踪器 (FeatureBasedTracker)
- 3次匹配确认机制: 目标需要连续匹配3次才会从U状态转为C状态
- ReID特征匹配: 即使目标完全丢失,也能通过外观特征重新识别
- 综合相似度计算: 结合mask相似度、IoU和ReID特征相似度
- 目标生命周期管理: 自动清理丢失太久的目标
4. 可视化增强
- 状态显示: 在每个目标旁显示跟踪状态 (C/U)
- 统计信息: 显示连续匹配次数、丢失次数、跟踪年龄
- 视觉区分: 已确认目标用实线框,未确认目标用虚线框
5. 优势特点
- 鲁棒性: 即使目标完全丢失多帧,仍能通过ReID特征重新识别
- 准确性: 5次匹配确认机制减少误跟踪
- 可解释性: 清晰的状态显示和统计信息
- 灵活性: 可调整ReID阈值和确认次数参数

import torch
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib.patches as patches
import time
import os
import glob
from scipy.optimize import linear_sum_assignment # 匈牙利匹配算法
import colorsys
import gc
import matplotlib
matplotlib.use('TkAgg')
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="tkinter")
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore")
# 新增导入
import cv2
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
#################################### For Image ####################################
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
class ReIDNetwork(nn.Module):
"""ReID网络用于提取目标外观特征"""
def __init__(self, feature_dim=512):
super(ReIDNetwork, self).__init__()
# 使用预训练的ResNet作为骨干网络
self.backbone = models.resnet50(pretrained=True)
# 移除分类层
self.backbone = nn.Sequential(*list(self.backbone.children())[:-2])
# 全局平均池化
self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
# 特征降维
self.feature_reduction = nn.Sequential(
nn.Linear(2048, feature_dim),
nn.BatchNorm1d(feature_dim),
nn.ReLU(inplace=True),
nn.Linear(feature_dim, feature_dim // 2),
nn.BatchNorm1d(feature_dim // 2),
nn.ReLU(inplace=True),
)
self.feature_dim = feature_dim // 2
# 图像预处理
self.transform = transforms.Compose([
transforms.Resize((256, 128)), # ReID标准尺寸
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def forward(self, x):
"""前向传播"""
features = self.backbone(x)
features = self.global_avg_pool(features)
features = features.view(features.size(0), -1)
features = self.feature_reduction(features)
# L2归一化
features = nn.functional.normalize(features, p=2, dim=1)
return features
def extract_features_from_crop(self, image, box):
"""从图像裁剪中提取特征"""
try:
# 裁剪目标区域
x1, y1, x2, y2 = map(int, box)
x1 = max(0, x1)
y1 = max(0, y1)
x2 = min(image.width, x2)
y2 = min(image.height, y2)
if x2 <= x1 or y2 <= y1:
return None
crop = image.crop((x1, y1, x2, y2))
# 转换为RGB(处理可能的RGBA图像)
if crop.mode != 'RGB':
crop = crop.convert('RGB')
# 预处理
crop_tensor = self.transform(crop).unsqueeze(0)
# 提取特征
with torch.no_grad():
features = self.forward(crop_tensor)
return features.squeeze(0).cpu().numpy()
except Exception as e:
print(f"ReID特征提取错误: {e}")
return None
class TrackState:
"""跟踪状态枚举"""
TEMPORARY = "T" # 临时跟踪(跟踪时间少于5帧)
CONFIRMED = "C" # 已确认(连续跟踪5帧以上)
class Track:
"""单个目标的跟踪信息"""
def __init__(self, track_id, box, mask, score, reid_features=None, is_temporary=True):
self.track_id = track_id
self.box = box
self.mask = mask
self.score = score
self.reid_features = reid_features if reid_features is not None else []
# 跟踪状态:临时跟踪或已确认
self.state = TrackState.TEMPORARY if is_temporary else TrackState.CONFIRMED
self.hit_streak = 1 # 连续匹配次数
self.miss_count = 0 # 连续丢失次数
self.age = 1 # 跟踪年龄(帧数)
self.is_temporary = is_temporary # 是否为临时跟踪
# 历史记录
self.feature_history = []
self.box_history = [box.copy()]
if reid_features is not None:
self.feature_history.append(reid_features)
def update(self, box, mask, score, reid_features=None):
"""更新跟踪状态"""
self.box = box
self.mask = mask
self.score = score
self.age += 1
self.hit_streak += 1
self.miss_count = 0
# 检查是否应该确认跟踪(连续跟踪5帧以上)
if self.is_temporary and self.hit_streak >= 2:
self.state = TrackState.CONFIRMED
self.is_temporary = False
print(f"目标确认: TrackID {self.track_id} 已从临时转为确认状态")
# 更新特征历史
if reid_features is not None:
self.reid_features = reid_features
self.feature_history.append(reid_features)
# 保持最近的特征
if len(self.feature_history) > 10:
self.feature_history.pop(0)
# 更新框历史
self.box_history.append(box.copy())
if len(self.box_history) > 20:
self.box_history.pop(0)
def mark_missed(self):
"""标记目标丢失"""
self.miss_count += 1
self.hit_streak = 0
def is_confirmed(self):
"""返回是否已确认(连续跟踪5帧以上)"""
return self.state == TrackState.CONFIRMED
def is_temporary_track(self):
"""返回是否为临时跟踪"""
return self.is_temporary
def should_remove(self, max_miss_count=30):
"""判断是否应该移除跟踪(丢失太久)"""
# 临时跟踪丢失更快被移除
if self.is_temporary:
return self.miss_count > 1 # 临时跟踪丢失5帧就移除
else:
return self.miss_count > max_miss_count # 确认跟踪可以丢失更久
def get_similarity(self, other_features, method='cosine'):
"""计算与另一个特征的相似度"""
if not self.feature_history or other_features is None:
return 0.0
# 使用历史特征计算最大相似度
similarities = []
for hist_feat in self.feature_history:
if method == 'cosine':
sim = np.dot(hist_feat, other_features) / (
np.linalg.norm(hist_feat) * np.linalg.norm(other_features) + 1e-8)
similarities.append(sim)
return max(similarities) if similarities else 0.0
class FeatureBasedTracker:
"""基于特征点的目标跟踪器,适用于无人机俯视图像"""
def __init__(self, iou_threshold=0.3, min_matches=10, ransac_thresh=5.0,
reid_threshold=0.7, confirm_threshold=5):
self.iou_threshold = iou_threshold
self.min_matches = min_matches
self.ransac_thresh = ransac_thresh
self.reid_threshold = reid_threshold
self.confirm_threshold = confirm_threshold
self.next_id = 0
self.next_temp_id = 0 # 临时ID计数器
self.tracks = {} # {track_id: Track object}
self.temporary_tracks = {} # 临时跟踪字典
self.previous_image = None
self.previous_keypoints = None
self.previous_descriptors = None
self.track_colors = {}
# 特征检测器
self.sift = cv2.SIFT_create()
self.orb = cv2.ORB_create(1000)
# 初始化ReID网络
self.reid_net = ReIDNetwork()
self.reid_net.eval()
def extract_reid_features(self, image, boxes):
"""为所有边界框提取ReID特征"""
features = []
for box in boxes:
feature = self.reid_net.extract_features_from_crop(image, box)
features.append(feature)
return features
def extract_features(self, image):
"""提取图像特征点"""
gray = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2GRAY)
# 尝试SIFT,如果失败则使用ORB
try:
keypoints, descriptors = self.sift.detectAndCompute(gray, None)
if descriptors is not None and len(descriptors) > 10:
return keypoints, descriptors
except:
pass
# 使用ORB作为备用
keypoints, descriptors = self.orb.detectAndCompute(gray, None)
return keypoints, descriptors
def calculate_homography(self, kp1, desc1, kp2, desc2):
"""计算两帧之间的单应性矩阵"""
if desc1 is None or desc2 is None or len(desc1) < 4 or len(desc2) < 4:
return None
# 根据描述符类型选择匹配方法
if desc1.dtype == np.float32: # SIFT描述符
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(desc1, desc2, k=2)
good_matches = []
for match_pair in matches:
if len(match_pair) == 2:
m, n = match_pair
if m.distance < 0.7 * n.distance:
good_matches.append(m)
else: # ORB描述符
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(desc1, desc2)
matches = sorted(matches, key=lambda x: x.distance)
good_matches = matches[:min(50, len(matches))]
if len(good_matches) < self.min_matches:
return None
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
try:
H, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, self.ransac_thresh)
return H
except:
return None
def transform_mask(self, mask, H, target_shape):
"""使用单应性矩阵变换mask"""
try:
mask_np = mask.cpu().numpy().squeeze().astype(np.uint8)
transformed_mask = cv2.warpPerspective(mask_np, H, (target_shape[1], target_shape[0]))
transformed_mask = (transformed_mask > 0.5).astype(np.float32)
return torch.from_numpy(transformed_mask).unsqueeze(0)
except:
return mask
def transform_box(self, box, H):
"""使用单应性矩阵变换边界框"""
try:
x1, y1, x2, y2 = box
corners = np.array([[[x1, y1]], [[x2, y1]], [[x2, y2]], [[x1, y2]]], dtype=np.float32)
transformed_corners = cv2.perspectiveTransform(corners, H)
tx1 = transformed_corners[:, :, 0].min()
ty1 = transformed_corners[:, :, 1].min()
tx2 = transformed_corners[:, :, 0].max()
ty2 = transformed_corners[:, :, 1].max()
return [max(0, tx1), max(0, ty1), max(0, tx2), max(0, ty2)]
except:
return box
def calculate_mask_similarity(self, mask1, mask2):
"""计算两个mask的相似度"""
try:
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
intersection = np.logical_and(mask1_np, mask2_np)
union = np.logical_or(mask1_np, mask2_np)
if np.sum(union) == 0:
return 0.0
iou = np.sum(intersection) / np.sum(union)
mask1_area = np.sum(mask1_np)
mask2_area = np.sum(mask2_np)
if max(mask1_area, mask2_area) == 0:
area_similarity = 0.0
else:
area_similarity = 1 - abs(mask1_area - mask2_area) / max(mask1_area, mask2_area)
similarity = 0.7 * iou + 0.3 * area_similarity
return similarity
except:
return 0.0
def hungarian_matching_with_similarity(self, previous_tracks, current_masks, current_boxes,
current_reid_features, H, image_shape):
"""使用匈牙利算法进行基于相似度的匹配"""
if len(previous_tracks) == 0 or len(current_masks) == 0:
return []
cost_matrix = np.ones((len(previous_tracks), len(current_masks)))
for i, track in enumerate(previous_tracks):
prev_mask = track.mask
prev_box = track.box
# 变换前一帧的mask到当前帧坐标系
if H is not None:
try:
transformed_mask = self.transform_mask(prev_mask, H, image_shape)
transformed_box = self.transform_box(prev_box, H)
except:
transformed_mask = prev_mask
transformed_box = prev_box
else:
transformed_mask = prev_mask
transformed_box = prev_box
for j, (curr_mask, curr_box, curr_reid) in enumerate(
zip(current_masks, current_boxes, current_reid_features)):
# 计算mask相似度
mask_similarity = self.calculate_mask_similarity(transformed_mask, curr_mask)
# 计算变换后框的IoU
iou = self.calculate_iou(transformed_box, curr_box)
# 计算ReID特征相似度
reid_similarity = track.get_similarity(curr_reid) if curr_reid is not None else 0.0
# 综合相似度(ReID权重较高)
total_similarity = (0.4 * mask_similarity + 0.2 * iou + 0.4 * reid_similarity)
cost_matrix[i, j] = 1 - total_similarity
# 匈牙利算法匹配
row_ind, col_ind = linear_sum_assignment(cost_matrix)
matches = []
for i, j in zip(row_ind, col_ind):
if cost_matrix[i, j] <= (1 - self.iou_threshold):
matches.append((i, j, 1 - cost_matrix[i, j]))
return matches
def calculate_iou(self, box1, box2):
"""计算两个边界框的IoU"""
try:
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
return inter_area / union_area if union_area > 0 else 0.0
except:
return 0.0
def get_track_color(self, track_id):
"""为track_id获取或生成颜色"""
if track_id not in self.track_colors:
hue = (track_id * 0.618033988749895) % 1.0
saturation = 0.8 + (track_id % 3) * 0.1
value = 0.8 + (track_id % 2) * 0.2
r, g, b = colorsys.hsv_to_rgb(hue, saturation, value)
self.track_colors[track_id] = (int(r * 255), int(g * 255), int(b * 255))
return self.track_colors[track_id]
def get_track_status(self, track_id):
"""获取跟踪状态"""
if track_id in self.tracks:
return self.tracks[track_id].state
elif track_id in self.temporary_tracks:
return self.temporary_tracks[track_id].state
return TrackState.TEMPORARY
def is_temporary_track(self, track_id):
"""判断是否为临时跟踪"""
if track_id in self.temporary_tracks:
return True
elif track_id in self.tracks:
return False
return True # 默认返回True,避免错误
def promote_temporary_to_confirmed(self, temp_track_id):
"""将临时跟踪提升为确认跟踪"""
if temp_track_id not in self.temporary_tracks:
return None
temp_track = self.temporary_tracks[temp_track_id]
# 分配新的永久ID
new_track_id = self.next_id
self.next_id += 1
# 创建确认跟踪
confirmed_track = Track(
new_track_id, temp_track.box, temp_track.mask, temp_track.score,
temp_track.reid_features, is_temporary=False
)
# 复制历史状态
confirmed_track.hit_streak = temp_track.hit_streak
confirmed_track.miss_count = temp_track.miss_count
confirmed_track.age = temp_track.age
confirmed_track.feature_history = temp_track.feature_history.copy()
confirmed_track.box_history = temp_track.box_history.copy()
# 添加到确认跟踪字典
self.tracks[new_track_id] = confirmed_track
# 移除临时跟踪
del self.temporary_tracks[temp_track_id]
print(f"临时跟踪 {temp_track_id} 已提升为确认跟踪 {new_track_id}")
return new_track_id
def update(self, current_image, current_masks, current_boxes, current_scores):
"""更新跟踪器状态"""
current_track_ids = []
if len(current_masks) == 0:
print("警告:当前帧没有检测到目标")
# 标记所有跟踪为丢失
for track in list(self.tracks.values()) + list(self.temporary_tracks.values()):
track.mark_missed()
self.previous_image = current_image
self.previous_keypoints, self.previous_descriptors = self.extract_features(current_image)
return current_track_ids
# 提取ReID特征
current_reid_features = self.extract_reid_features(current_image, current_boxes)
current_keypoints, current_descriptors = self.extract_features(current_image)
# 计算单应性矩阵
H = None
if self.previous_image is not None and current_keypoints is not None and self.previous_keypoints is not None:
H = self.calculate_homography(self.previous_keypoints, self.previous_descriptors,
current_keypoints, current_descriptors)
image_shape = current_masks[0].shape[-2:] if len(current_masks) > 0 else (current_image.height, current_image.width)
# 合并所有跟踪(确认+临时)
all_previous_tracks = list(self.tracks.values()) + list(self.temporary_tracks.values())
if len(all_previous_tracks) == 0:
# 第一帧初始化:所有新目标都作为临时跟踪
for i, (mask, box, score, reid_feat) in enumerate(
zip(current_masks, current_boxes, current_scores, current_reid_features)):
temp_track_id = self.next_temp_id
self.next_temp_id += 1
self.temporary_tracks[temp_track_id] = Track(
temp_track_id, box, mask, score, reid_feat, is_temporary=True
)
current_track_ids.append(temp_track_id)
print(f"新临时目标: TempTrackID {temp_track_id}, 状态: {self.temporary_tracks[temp_track_id].state}")
else:
# 使用匈牙利算法匹配
matches = self.hungarian_matching_with_similarity(
all_previous_tracks, current_masks, current_boxes, current_reid_features,
H, image_shape
)
# 分配跟踪ID
current_track_ids = [-1] * len(current_masks)
used_track_ids = set()
promoted_tracks = {} # 记录临时跟踪提升映射
# 处理匹配的目标
for i, j, similarity in matches:
if i < len(all_previous_tracks):
track = all_previous_tracks[i]
track_id = track.track_id
# 检查跟踪是否仍然存在(可能在其他匹配中被删除)
track_exists = (track_id in self.tracks) or (track_id in self.temporary_tracks)
if not track_exists:
continue
# 更新跟踪器状态
if track_id in self.tracks: # 确认跟踪
self.tracks[track_id].update(
current_boxes[j], current_masks[j], current_scores[j],
current_reid_features[j]
)
current_track_ids[j] = track_id
used_track_ids.add(track_id)
print(f"确认目标匹配: TrackID {track_id} -> 检测 {j}, 相似度: {similarity:.3f}, "
f"状态: {self.tracks[track_id].state}, 连续匹配: {self.tracks[track_id].hit_streak}")
elif track_id in self.temporary_tracks: # 临时跟踪
self.temporary_tracks[track_id].update(
current_boxes[j], current_masks[j], current_scores[j],
current_reid_features[j]
)
# 检查是否应该提升为确认跟踪
if self.temporary_tracks[track_id].is_confirmed():
new_track_id = self.promote_temporary_to_confirmed(track_id)
if new_track_id is not None:
current_track_ids[j] = new_track_id
used_track_ids.add(new_track_id)
promoted_tracks[track_id] = new_track_id
else:
current_track_ids[j] = track_id
used_track_ids.add(track_id)
else:
current_track_ids[j] = track_id
used_track_ids.add(track_id)
# 使用安全的访问方式
if track_id in self.temporary_tracks:
track_info = self.temporary_tracks[track_id]
print(f"临时目标匹配: TempTrackID {track_id} -> 检测 {j}, 相似度: {similarity:.3f}, "
f"状态: {track_info.state}, 连续匹配: {track_info.hit_streak}")
elif track_id in promoted_tracks:
new_track_id = promoted_tracks[track_id]
if new_track_id in self.tracks:
track_info = self.tracks[new_track_id]
print(f"临时目标提升: TempTrackID {track_id} -> TrackID {new_track_id}, 状态: {track_info.state}")
# 处理未匹配的目标(新目标)- 创建临时跟踪
for j in range(len(current_masks)):
if current_track_ids[j] == -1:
temp_track_id = self.next_temp_id
self.next_temp_id += 1
current_track_ids[j] = temp_track_id
self.temporary_tracks[temp_track_id] = Track(
temp_track_id, current_boxes[j], current_masks[j],
current_scores[j], current_reid_features[j], is_temporary=True
)
print(f"新临时目标: TempTrackID {temp_track_id}, 状态: {self.temporary_tracks[temp_track_id].state}")
# 标记未匹配的跟踪为丢失(使用安全的访问方式)
tracks_to_mark_missed = []
for track_id, track in list(self.tracks.items()):
if track_id not in used_track_ids:
tracks_to_mark_missed.append((track_id, track, 'confirmed'))
for track_id, track in list(self.temporary_tracks.items()):
if track_id not in used_track_ids and track_id not in promoted_tracks:
tracks_to_mark_missed.append((track_id, track, 'temporary'))
for track_id, track, track_type in tracks_to_mark_missed:
track.mark_missed()
if track_type == 'confirmed':
print(f"确认目标丢失: TrackID {track_id}, 连续丢失: {track.miss_count}, 状态: {track.state}")
else:
print(f"临时目标丢失: TempTrackID {track_id}, 连续丢失: {track.miss_count}, 状态: {track.state}")
# 清理丢失太久的跟踪
self._cleanup_lost_tracks()
# 更新前一帧信息
self.previous_image = current_image
self.previous_keypoints = current_keypoints
self.previous_descriptors = current_descriptors
return current_track_ids
def _cleanup_lost_tracks(self):
"""清理丢失的跟踪"""
# 清理确认跟踪
tracks_to_remove = []
for track_id, track in self.tracks.items():
if track.should_remove():
tracks_to_remove.append(track_id)
for track_id in tracks_to_remove:
if track_id in self.tracks:
del self.tracks[track_id]
print(f"移除确认跟踪: TrackID {track_id}")
# 清理临时跟踪
temp_tracks_to_remove = []
for track_id, track in self.temporary_tracks.items():
if track.should_remove():
temp_tracks_to_remove.append(track_id)
for track_id in temp_tracks_to_remove:
if track_id in self.temporary_tracks:
del self.temporary_tracks[track_id]
print(f"移除临时跟踪: TempTrackID {track_id}")
def load_moad(mode_path="sam3.pt"):
"""加载模型"""
model_load_start_time = time.time()
model = build_sam3_image_model(
checkpoint_path=mode_path
)
processor = Sam3Processor(model, confidence_threshold=0.5)
model_load_end_time = time.time()
model_load_time = model_load_end_time - model_load_start_time
print(f"模型加载时间: {model_load_time:.3f} 秒")
return processor
def Get_image_mask(processor, image_path):
"""获取图像分割结果"""
detection_start_time = time.time()
image = Image.open(image_path)
inference_state = processor.set_image(image)
output = processor.set_text_prompt(state=inference_state, prompt="building")
masks, boxes, scores = output["masks"], output["boxes"], output["scores"]
detection_end_time = time.time()
detection_time = detection_end_time - detection_start_time
print(f"检测单张时间: {detection_time:.3f} 秒")
print(f"原始检测到 {len(masks)} 个分割结果")
print(f"掩码形状: {masks.shape}")
return masks, boxes, scores
def Ronghe_calculate_iou(box1, box2):
"""计算两个边界框的IoU"""
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
if union_area == 0:
return 0.0
iou_2 = inter_area / box2_area
iou_1 = inter_area / box1_area
iou = max(iou_2, iou_1)
return iou
def calculate_mask_overlap(mask1, mask2):
"""计算两个掩码的重叠比例"""
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
intersection = np.logical_and(mask1_np, mask2_np)
mask1_area = np.sum(mask1_np)
if mask1_area == 0:
return 0.0
overlap_ratio = np.sum(intersection) / mask1_area
return overlap_ratio
def fuse_overlapping_masks(masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6):
"""融合重叠的掩码和边界框"""
if len(masks) == 0:
return masks, boxes, scores
boxes_np = boxes.cpu().numpy().copy()
scores_np = scores.cpu().numpy().copy()
areas = []
for box in boxes_np:
x1, y1, x2, y2 = box
width = x2 - x1
height = y2 - y1
area = width * height
areas.append(area)
areas_np = np.array(areas)
sorted_indices = np.argsort(areas_np)[::-1]
boxes_sorted = boxes_np[sorted_indices]
scores_sorted = scores_np[sorted_indices]
areas_sorted = areas_np[sorted_indices]
masks_list = [masks[i] for i in range(len(masks))]
masks_sorted = [masks_list[i] for i in sorted_indices]
keep_indices = []
suppressed = set()
fused_masks = masks_sorted.copy()
for i in range(len(boxes_sorted)):
if i in suppressed:
continue
keep_indices.append(i)
current_mask = fused_masks[i]
for j in range(i + 1, len(boxes_sorted)):
if j in suppressed:
continue
iou = Ronghe_calculate_iou(boxes_sorted[i], boxes_sorted[j])
if iou > iou_threshold:
mask_overlap = calculate_mask_overlap(current_mask, masks_sorted[j])
suppressed.add(j)
fused_mask = fuse_two_masks(current_mask, masks_sorted[j])
fused_masks[i] = fused_mask
current_mask = fused_mask
print(f"融合检测结果: 索引 {sorted_indices[i]} (面积: {areas_sorted[i]:.1f}) 融合索引 {sorted_indices[j]} (面积: {areas_sorted[j]:.1f})",
" iou:", iou, " mask重叠:", mask_overlap)
else:
pass
final_indices = [sorted_indices[i] for i in keep_indices]
final_masks_list = [fused_masks[i] for i in keep_indices]
final_masks = torch.stack(final_masks_list)
final_boxes = boxes[final_indices]
final_scores = scores[final_indices]
print(f"融合后剩余 {len(final_masks)} 个分割结果 (减少了 {len(masks) - len(final_masks)} 个)")
return final_masks, final_boxes, final_scores
def fuse_two_masks(mask1, mask2):
"""将两个mask融合"""
fused_mask = torch.logical_or(mask1, mask2).float()
return fused_mask
def overlay_masks_with_tracking(image, masks, boxes, scores, track_ids, tracker, fusion_mode=False):
"""在图像上叠加掩码,并显示跟踪ID和状态"""
image = image.convert("RGB")
draw = ImageDraw.Draw(image)
try:
font = ImageFont.truetype("SimHei.ttf", 40)
except:
try:
font = ImageFont.truetype("Arial.ttf", 40)
except:
font = ImageFont.load_default()
masks_np = masks.cpu().numpy().astype(np.uint8)
masks_np = masks_np.squeeze(1)
boxes_np = boxes.cpu().numpy()
scores_np = scores.cpu().numpy()
for i, (mask, box, score, track_id) in enumerate(zip(masks_np, boxes_np, scores_np, track_ids)):
# 获取跟踪状态和是否为临时跟踪
status = tracker.get_track_status(track_id)
is_temporary = tracker.is_temporary_track(track_id)
# 获取跟踪的详细信息
track_info = None
if track_id in tracker.tracks:
track_info = tracker.tracks[track_id]
elif track_id in tracker.temporary_tracks:
track_info = tracker.temporary_tracks[track_id]
if track_info:
hit_streak = track_info.hit_streak
miss_count = track_info.miss_count
age = track_info.age
else:
hit_streak = 0
miss_count = 0
age = 1
# 根据跟踪状态决定颜色和透明度
if status == TrackState.CONFIRMED:
# 已确认目标(连续跟踪5帧以上):使用彩色显示
color = tracker.get_track_color(track_id)
mask_alpha = 128 # 正常透明度
outline_width = 3
else:
# 临时目标:使用灰色50%透明度
color = (128, 128, 128) # 灰色
mask_alpha = 64 # 50%透明度
outline_width = 2
if mask.ndim == 3:
mask = mask.squeeze(0)
alpha_mask = (mask * mask_alpha).astype(np.uint8)
overlay = Image.new("RGBA", image.size, color + (mask_alpha,))
alpha = Image.fromarray(alpha_mask, mode='L')
overlay.putalpha(alpha)
image = Image.alpha_composite(image.convert("RGBA"), overlay).convert("RGB")
draw = ImageDraw.Draw(image)
x1, y1, x2, y2 = box
x1 = max(0, min(x1, image.width))
y1 = max(0, min(y1, image.height))
x2 = max(0, min(x2, image.width))
y2 = max(0, min(y2, image.height))
# 根据状态选择边框样式
if status == TrackState.CONFIRMED:
# 已确认目标:实线边框
draw.rectangle([x1, y1, x2, y2], outline=color, width=outline_width)
else:
# 临时目标:虚线边框
draw.rectangle([x1, y1, x2, y2], outline=color, width=outline_width)
# 绘制虚线效果
dash_length = 5
for x in range(int(x1), int(x2), dash_length*2):
draw.line([x, y1, x+dash_length, y1], fill=color, width=2)
draw.line([x, y2, x+dash_length, y2], fill=color, width=2)
for y in range(int(y1), int(y2), dash_length*2):
draw.line([x1, y, x1, y+dash_length], fill=color, width=2)
draw.line([x2, y, x2, y+dash_length], fill=color, width=2)
# 构建显示文本
track_prefix = "Temp" if is_temporary else "Track"
if fusion_mode:
base_text = f"{track_prefix}:{track_id}({status}) F-ID:{i} S:{score:.2f}"
else:
base_text = f"{track_prefix}:{track_id}({status}) ID:{i} S:{score:.2f}"
# 添加跟踪统计信息
stat_text = f"H:{hit_streak} M:{miss_count} A:{age}"
full_text = f"{base_text}\n{stat_text}"
try:
# 计算文本尺寸
lines = full_text.split('\n')
text_bbox = [draw.textbbox((0, 0), line, font=font) for line in lines]
text_width = max(bbox[2] - bbox[0] for bbox in text_bbox)
text_height = sum(bbox[3] - bbox[1] for bbox in text_bbox) + 5 * (len(lines) - 1)
except:
text_width, text_height = 200, 40
text_x = x1
text_y = max(0, y1 - text_height - 5)
# 绘制文本背景(使用与目标相同的颜色)
draw.rectangle([text_x, text_y, text_x + text_width + 10, text_y + text_height + 5],
fill=color)
# 绘制文本(黑色文字在浅色背景上更清晰)
text_color = "black" if status == TrackState.CONFIRMED else "white"
y_offset = text_y + 2
for line in lines:
draw.text((text_x + 5, y_offset), line, fill=text_color, font=font)
y_offset += font.size + 2
return image
def extract_number_from_filename(filename):
"""从DJI_XXXX.JPG格式的文件名中提取数字"""
try:
if filename.startswith('DJI_') and filename.endswith(('.JPG', '.jpg', '.JPEG', '.jpeg')):
number_part = filename[4:].split('.')[0]
return int(number_part)
except (ValueError, IndexError):
pass
return float('inf')
def process_image_folder(processor, folder_path, output_dir="output"):
"""处理文件夹中的所有图像(使用增强的特征点跟踪器)"""
os.makedirs(output_dir, exist_ok=True)
image_extensions = ['*.jpg', '*.jpeg', '*.png', '*.bmp', '*.tiff', '*.tif', '*.JPG', '*.JPEG', '*.PNG']
image_files = []
for ext in image_extensions:
image_files.extend(glob.glob(os.path.join(folder_path, ext)))
image_files.sort(key=lambda x: extract_number_from_filename(os.path.basename(x)))
print(f"找到 {len(image_files)} 张图像")
# 使用增强的特征点跟踪器
tracker = FeatureBasedTracker(iou_threshold=0.3, min_matches=10, reid_threshold=0.7)
results = []
for i, image_path in enumerate(image_files):
print(f"\n{'='*50}")
print(f"处理第 {i+1}/{len(image_files)} 张图像: {os.path.basename(image_path)}")
try:
# 检测图像
masks, boxes, scores = Get_image_mask(processor, image_path)
if len(masks) == 0:
print("未检测到目标,跳过此图像")
# 更新跟踪器(标记丢失)
current_image = Image.open(image_path)
tracker.update(current_image, [], [], [])
del masks, boxes, scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 融合重叠的mask
fused_masks, fused_boxes, fused_scores = fuse_overlapping_masks(
masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6
)
if len(fused_boxes) == 0:
print("融合后无目标,跳过此图像")
current_image = Image.open(image_path)
tracker.update(current_image, [], [], [])
del masks, boxes, scores, fused_masks, fused_boxes, fused_scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 加载当前图像用于特征点跟踪
current_image = Image.open(image_path)
# 使用增强的特征点跟踪器进行目标跟踪
track_ids = tracker.update(current_image, fused_masks, fused_boxes.cpu().numpy(),
fused_scores.cpu().numpy())
# 打印跟踪统计信息
confirmed_count = sum(1 for tid in track_ids if tracker.get_track_status(tid) == TrackState.CONFIRMED)
temporary_count = sum(1 for tid in track_ids if tracker.get_track_status(tid) == TrackState.TEMPORARY)
print(f"跟踪统计: 总目标 {len(track_ids)}, 已确认 {confirmed_count}, 临时 {temporary_count}")
# 保存结果
image_name = os.path.splitext(os.path.basename(image_path))[0]
save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, i, tracker)
results.append({
'image_path': image_path,
'image_name': image_name,
'track_ids': track_ids,
'confirmed_count': confirmed_count,
'temporary_count': temporary_count
})
except Exception as e:
print(f"处理图像 {image_path} 时出错: {e}")
import traceback
traceback.print_exc()
finally:
variables_to_delete = ['masks', 'boxes', 'scores', 'fused_masks', 'fused_boxes',
'fused_scores', 'current_image']
for var_name in variables_to_delete:
if var_name in locals():
del locals()[var_name]
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
print(f"内存清理完成,准备处理下一张图像")
return results
def save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, image_index, tracker):
"""保存单张图像的结果"""
original_image = Image.open(image_path)
# 应用跟踪结果显示(传入tracker参数)
result_image_original = overlay_masks_with_tracking(
original_image, masks, boxes, scores,
list(range(len(masks))), tracker, fusion_mode=False
)
result_image_fused = overlay_masks_with_tracking(
original_image, fused_masks, fused_boxes, fused_scores,
track_ids, tracker, fusion_mode=True
)
# 创建并保存对比图像
create_comparison_image(
result_image_original, result_image_fused,
len(masks), len(fused_masks), output_dir, image_name, image_index, tracker
)
del original_image, result_image_original, result_image_fused
gc.collect()
def create_comparison_image(original_img, fused_img, n_original, n_fused, output_dir, image_name, image_index, tracker):
"""创建、保存并显示对比图像"""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
ax1.imshow(original_img)
ax1.set_title(f"Original Result - {image_name}: {n_original} segments", fontsize=14)
ax1.axis('off')
ax2.imshow(fused_img)
ax2.set_title(f"Fused with Tracking - {image_name}: {n_fused} segments", fontsize=14)
ax2.axis('off')
plt.tight_layout()
comparison_path = os.path.join(output_dir, f"segmentation_comparison_{image_name}.png")
plt.savefig(comparison_path, dpi=300, bbox_inches='tight', facecolor='white')
print(f"对比图像已保存: {comparison_path}")
if image_index < 3:
plt.show()
else:
plt.close(fig)
plt.close('all')
def main():
"""主函数"""
processor = load_moad("sam3.pt")
folder_path = "/home/dongdong/2project/0data/RTK/data_4_city/300_map_2pm/images/"
output_dir = "output"
try:
results = process_image_folder(processor, folder_path, output_dir)
# 打印最终统计信息
total_confirmed = sum(r['confirmed_count'] for r in results if 'confirmed_count' in r)
total_temporary = sum(r['temporary_count'] for r in results if 'temporary_count' in r)
print(f"\n处理完成!共处理 {len(results)} 张图像")
print(f"跟踪统计: 总确认目标 {total_confirmed}, 总临时目标 {total_temporary}")
print(f"结果保存在 {output_dir} 目录中")
except Exception as e:
print(f"处理过程中出错: {e}")
import traceback
traceback.print_exc()
finally:
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
if __name__ == "__main__":
main()
历史34 稳定版本
没有多帧判断和临时移除策略
import torch
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib.patches as patches
import time
import os
import glob
from scipy.optimize import linear_sum_assignment # 匈牙利匹配算法
import colorsys
import gc
import matplotlib
matplotlib.use('TkAgg')
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="tkinter")
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore")
# 新增导入
import cv2
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
#################################### For Image ####################################
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
class ReIDNetwork(nn.Module):
"""ReID网络用于提取目标外观特征"""
def __init__(self, feature_dim=512):
super(ReIDNetwork, self).__init__()
# 使用预训练的ResNet作为骨干网络
self.backbone = models.resnet50(pretrained=True)
# 移除分类层
self.backbone = nn.Sequential(*list(self.backbone.children())[:-2])
# 全局平均池化
self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
# 特征降维
self.feature_reduction = nn.Sequential(
nn.Linear(2048, feature_dim),
nn.BatchNorm1d(feature_dim),
nn.ReLU(inplace=True),
nn.Linear(feature_dim, feature_dim // 2),
nn.BatchNorm1d(feature_dim // 2),
nn.ReLU(inplace=True),
)
self.feature_dim = feature_dim // 2
# 图像预处理
self.transform = transforms.Compose([
transforms.Resize((256, 128)), # ReID标准尺寸
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def forward(self, x):
"""前向传播"""
features = self.backbone(x)
features = self.global_avg_pool(features)
features = features.view(features.size(0), -1)
features = self.feature_reduction(features)
# L2归一化
features = nn.functional.normalize(features, p=2, dim=1)
return features
def extract_features_from_crop(self, image, box):
"""从图像裁剪中提取特征"""
try:
# 裁剪目标区域
x1, y1, x2, y2 = map(int, box)
x1 = max(0, x1)
y1 = max(0, y1)
x2 = min(image.width, x2)
y2 = min(image.height, y2)
if x2 <= x1 or y2 <= y1:
return None
crop = image.crop((x1, y1, x2, y2))
# 转换为RGB(处理可能的RGBA图像)
if crop.mode != 'RGB':
crop = crop.convert('RGB')
# 预处理
crop_tensor = self.transform(crop).unsqueeze(0)
# 提取特征
with torch.no_grad():
features = self.forward(crop_tensor)
return features.squeeze(0).cpu().numpy()
except Exception as e:
print(f"ReID特征提取错误: {e}")
return None
class TrackState:
"""跟踪状态枚举"""
UNCONFIRMED = "U" # 未确认
CONFIRMED = "C" # 已确认
class Track:
"""单个目标的跟踪信息"""
def __init__(self, track_id, box, mask, score, reid_features=None):
self.track_id = track_id
self.box = box
self.mask = mask
self.score = score
self.reid_features = reid_features if reid_features is not None else []
self.state = TrackState.UNCONFIRMED
self.hit_streak = 1 # 连续匹配次数
self.miss_count = 0 # 连续丢失次数
self.age = 1 # 跟踪年龄(帧数)
# 历史记录
self.feature_history = []
self.box_history = [box.copy()]
if reid_features is not None:
self.feature_history.append(reid_features)
def update(self, box, mask, score, reid_features=None):
"""更新跟踪状态"""
self.box = box
self.mask = mask
self.score = score
self.age += 1
self.hit_streak += 1
self.miss_count = 0
# 更新特征历史
if reid_features is not None:
self.reid_features = reid_features
self.feature_history.append(reid_features)
# 保持最近的特征
if len(self.feature_history) > 10:
self.feature_history.pop(0)
# 更新框历史
self.box_history.append(box.copy())
if len(self.box_history) > 20:
self.box_history.pop(0)
# 检查是否应该确认跟踪
if self.state == TrackState.UNCONFIRMED and self.hit_streak >= 3:
self.state = TrackState.CONFIRMED
def mark_missed(self):
"""标记目标丢失"""
self.miss_count += 1
self.hit_streak = 0
def is_confirmed(self):
"""返回是否已确认"""
return self.state == TrackState.CONFIRMED
def should_remove(self, max_miss_count=30):
"""判断是否应该移除跟踪(丢失太久)"""
return self.miss_count > max_miss_count
def get_similarity(self, other_features, method='cosine'):
"""计算与另一个特征的相似度"""
if not self.feature_history or other_features is None:
return 0.0
# 使用历史特征计算最大相似度
similarities = []
for hist_feat in self.feature_history:
if method == 'cosine':
sim = np.dot(hist_feat, other_features) / (
np.linalg.norm(hist_feat) * np.linalg.norm(other_features) + 1e-8)
similarities.append(sim)
return max(similarities) if similarities else 0.0
class FeatureBasedTracker:
"""基于特征点的目标跟踪器,适用于无人机俯视图像"""
def __init__(self, iou_threshold=0.3, min_matches=10, ransac_thresh=5.0,
reid_threshold=0.7, confirm_threshold=3):
self.iou_threshold = iou_threshold
self.min_matches = min_matches
self.ransac_thresh = ransac_thresh
self.reid_threshold = reid_threshold
self.confirm_threshold = confirm_threshold
self.next_id = 0
self.tracks = {} # {track_id: Track object}
self.previous_image = None
self.previous_keypoints = None
self.previous_descriptors = None
self.track_colors = {}
# 特征检测器
self.sift = cv2.SIFT_create()
self.orb = cv2.ORB_create(1000)
# 初始化ReID网络
self.reid_net = ReIDNetwork()
self.reid_net.eval()
def extract_reid_features(self, image, boxes):
"""为所有边界框提取ReID特征"""
features = []
for box in boxes:
feature = self.reid_net.extract_features_from_crop(image, box)
features.append(feature)
return features
def extract_features(self, image):
"""提取图像特征点"""
gray = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2GRAY)
# 尝试SIFT,如果失败则使用ORB
try:
keypoints, descriptors = self.sift.detectAndCompute(gray, None)
if descriptors is not None and len(descriptors) > 10:
return keypoints, descriptors
except:
pass
# 使用ORB作为备用
keypoints, descriptors = self.orb.detectAndCompute(gray, None)
return keypoints, descriptors
def calculate_homography(self, kp1, desc1, kp2, desc2):
"""计算两帧之间的单应性矩阵"""
if desc1 is None or desc2 is None or len(desc1) < 4 or len(desc2) < 4:
return None
# 根据描述符类型选择匹配方法
if desc1.dtype == np.float32: # SIFT描述符
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(desc1, desc2, k=2)
good_matches = []
for match_pair in matches:
if len(match_pair) == 2:
m, n = match_pair
if m.distance < 0.7 * n.distance:
good_matches.append(m)
else: # ORB描述符
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(desc1, desc2)
matches = sorted(matches, key=lambda x: x.distance)
good_matches = matches[:min(50, len(matches))]
if len(good_matches) < self.min_matches:
return None
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
try:
H, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, self.ransac_thresh)
return H
except:
return None
def transform_mask(self, mask, H, target_shape):
"""使用单应性矩阵变换mask"""
try:
mask_np = mask.cpu().numpy().squeeze().astype(np.uint8)
transformed_mask = cv2.warpPerspective(mask_np, H, (target_shape[1], target_shape[0]))
transformed_mask = (transformed_mask > 0.5).astype(np.float32)
return torch.from_numpy(transformed_mask).unsqueeze(0)
except:
return mask
def transform_box(self, box, H):
"""使用单应性矩阵变换边界框"""
try:
x1, y1, x2, y2 = box
corners = np.array([[[x1, y1]], [[x2, y1]], [[x2, y2]], [[x1, y2]]], dtype=np.float32)
transformed_corners = cv2.perspectiveTransform(corners, H)
tx1 = transformed_corners[:, :, 0].min()
ty1 = transformed_corners[:, :, 1].min()
tx2 = transformed_corners[:, :, 0].max()
ty2 = transformed_corners[:, :, 1].max()
return [max(0, tx1), max(0, ty1), max(0, tx2), max(0, ty2)]
except:
return box
def calculate_mask_similarity(self, mask1, mask2):
"""计算两个mask的相似度"""
try:
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
intersection = np.logical_and(mask1_np, mask2_np)
union = np.logical_or(mask1_np, mask2_np)
if np.sum(union) == 0:
return 0.0
iou = np.sum(intersection) / np.sum(union)
mask1_area = np.sum(mask1_np)
mask2_area = np.sum(mask2_np)
if max(mask1_area, mask2_area) == 0:
area_similarity = 0.0
else:
area_similarity = 1 - abs(mask1_area - mask2_area) / max(mask1_area, mask2_area)
similarity = 0.7 * iou + 0.3 * area_similarity
return similarity
except:
return 0.0
def hungarian_matching_with_similarity(self, previous_tracks, current_masks, current_boxes,
current_reid_features, H, image_shape):
"""使用匈牙利算法进行基于相似度的匹配"""
if len(previous_tracks) == 0 or len(current_masks) == 0:
return []
cost_matrix = np.ones((len(previous_tracks), len(current_masks)))
for i, track in enumerate(previous_tracks):
prev_mask = track.mask
prev_box = track.box
# 变换前一帧的mask到当前帧坐标系
if H is not None:
try:
transformed_mask = self.transform_mask(prev_mask, H, image_shape)
transformed_box = self.transform_box(prev_box, H)
except:
transformed_mask = prev_mask
transformed_box = prev_box
else:
transformed_mask = prev_mask
transformed_box = prev_box
for j, (curr_mask, curr_box, curr_reid) in enumerate(
zip(current_masks, current_boxes, current_reid_features)):
# 计算mask相似度
mask_similarity = self.calculate_mask_similarity(transformed_mask, curr_mask)
# 计算变换后框的IoU
iou = self.calculate_iou(transformed_box, curr_box)
# 计算ReID特征相似度
reid_similarity = track.get_similarity(curr_reid) if curr_reid is not None else 0.0
# 综合相似度(ReID权重较高)
total_similarity = (0.4 * mask_similarity + 0.2 * iou + 0.4 * reid_similarity)
cost_matrix[i, j] = 1 - total_similarity
# 匈牙利算法匹配
row_ind, col_ind = linear_sum_assignment(cost_matrix)
matches = []
for i, j in zip(row_ind, col_ind):
if cost_matrix[i, j] <= (1 - self.iou_threshold):
matches.append((i, j, 1 - cost_matrix[i, j]))
return matches
def calculate_iou(self, box1, box2):
"""计算两个边界框的IoU"""
try:
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
return inter_area / union_area if union_area > 0 else 0.0
except:
return 0.0
def get_track_color(self, track_id):
"""为track_id获取或生成颜色"""
if track_id not in self.track_colors:
hue = (track_id * 0.618033988749895) % 1.0
saturation = 0.8 + (track_id % 3) * 0.1
value = 0.8 + (track_id % 2) * 0.2
r, g, b = colorsys.hsv_to_rgb(hue, saturation, value)
self.track_colors[track_id] = (int(r * 255), int(g * 255), int(b * 255))
return self.track_colors[track_id]
def get_track_status(self, track_id):
"""获取跟踪状态"""
if track_id in self.tracks:
return self.tracks[track_id].state
return TrackState.UNCONFIRMED
def update(self, current_image, current_masks, current_boxes, current_scores):
"""更新跟踪器状态"""
current_track_ids = []
if len(current_masks) == 0:
print("警告:当前帧没有检测到目标")
# 标记所有跟踪为丢失
for track in self.tracks.values():
track.mark_missed()
self.previous_image = current_image
self.previous_keypoints, self.previous_descriptors = self.extract_features(current_image)
return current_track_ids
# 提取ReID特征
current_reid_features = self.extract_reid_features(current_image, current_boxes)
current_keypoints, current_descriptors = self.extract_features(current_image)
# 计算单应性矩阵
H = None
if self.previous_image is not None and current_keypoints is not None and self.previous_keypoints is not None:
H = self.calculate_homography(self.previous_keypoints, self.previous_descriptors,
current_keypoints, current_descriptors)
image_shape = current_masks[0].shape[-2:] if len(current_masks) > 0 else (current_image.height, current_image.width)
if len(self.tracks) == 0:
# 第一帧初始化
for i, (mask, box, score, reid_feat) in enumerate(
zip(current_masks, current_boxes, current_scores, current_reid_features)):
track_id = self.next_id
self.next_id += 1
self.tracks[track_id] = Track(track_id, box, mask, score, reid_feat)
current_track_ids.append(track_id)
print(f"新目标: TrackID {track_id}, 状态: {self.tracks[track_id].state}")
else:
# 使用匈牙利算法匹配
previous_tracks = list(self.tracks.values())
matches = self.hungarian_matching_with_similarity(
previous_tracks, current_masks, current_boxes, current_reid_features,
H, image_shape
)
# 分配跟踪ID
current_track_ids = [-1] * len(current_masks)
used_track_ids = set()
# 处理匹配的目标
for i, j, similarity in matches:
if i < len(previous_tracks):
track_id = previous_tracks[i].track_id
current_track_ids[j] = track_id
used_track_ids.add(track_id)
# 更新跟踪器状态
self.tracks[track_id].update(
current_boxes[j], current_masks[j], current_scores[j],
current_reid_features[j]
)
print(f"目标匹配: TrackID {track_id} -> 检测 {j}, 相似度: {similarity:.3f}, "
f"状态: {self.tracks[track_id].state}, 连续匹配: {self.tracks[track_id].hit_streak}")
# 处理未匹配的目标(新目标)
for j in range(len(current_masks)):
if current_track_ids[j] == -1:
new_id = self.next_id
self.next_id += 1
current_track_ids[j] = new_id
self.tracks[new_id] = Track(
new_id, current_boxes[j], current_masks[j],
current_scores[j], current_reid_features[j]
)
print(f"新目标: TrackID {new_id}, 状态: {self.tracks[new_id].state}")
# 标记未匹配的跟踪为丢失
for track_id, track in list(self.tracks.items()):
if track_id not in used_track_ids:
track.mark_missed()
print(f"目标丢失: TrackID {track_id}, 连续丢失: {track.miss_count}, 状态: {track.state}")
# 清理丢失太久的跟踪
tracks_to_remove = []
for track_id, track in self.tracks.items():
if track.should_remove():
tracks_to_remove.append(track_id)
for track_id in tracks_to_remove:
if track_id in self.tracks:
del self.tracks[track_id]
print(f"移除跟踪: TrackID {track_id}")
# 更新前一帧信息
self.previous_image = current_image
self.previous_keypoints = current_keypoints
self.previous_descriptors = current_descriptors
return current_track_ids
def load_moad(mode_path="sam3.pt"):
"""加载模型"""
model_load_start_time = time.time()
model = build_sam3_image_model(
checkpoint_path=mode_path
)
processor = Sam3Processor(model, confidence_threshold=0.5)
model_load_end_time = time.time()
model_load_time = model_load_end_time - model_load_start_time
print(f"模型加载时间: {model_load_time:.3f} 秒")
return processor
def Get_image_mask(processor, image_path):
"""获取图像分割结果"""
detection_start_time = time.time()
image = Image.open(image_path)
inference_state = processor.set_image(image)
output = processor.set_text_prompt(state=inference_state, prompt="building")
masks, boxes, scores = output["masks"], output["boxes"], output["scores"]
detection_end_time = time.time()
detection_time = detection_end_time - detection_start_time
print(f"检测单张时间: {detection_time:.3f} 秒")
print(f"原始检测到 {len(masks)} 个分割结果")
print(f"掩码形状: {masks.shape}")
return masks, boxes, scores
def Ronghe_calculate_iou(box1, box2):
"""计算两个边界框的IoU"""
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
if union_area == 0:
return 0.0
iou_2 = inter_area / box2_area
iou_1 = inter_area / box1_area
iou = max(iou_2, iou_1)
return iou
def calculate_mask_overlap(mask1, mask2):
"""计算两个掩码的重叠比例"""
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
intersection = np.logical_and(mask1_np, mask2_np)
mask1_area = np.sum(mask1_np)
if mask1_area == 0:
return 0.0
overlap_ratio = np.sum(intersection) / mask1_area
return overlap_ratio
def fuse_overlapping_masks(masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6):
"""融合重叠的掩码和边界框"""
if len(masks) == 0:
return masks, boxes, scores
boxes_np = boxes.cpu().numpy().copy()
scores_np = scores.cpu().numpy().copy()
areas = []
for box in boxes_np:
x1, y1, x2, y2 = box
width = x2 - x1
height = y2 - y1
area = width * height
areas.append(area)
areas_np = np.array(areas)
sorted_indices = np.argsort(areas_np)[::-1]
boxes_sorted = boxes_np[sorted_indices]
scores_sorted = scores_np[sorted_indices]
areas_sorted = areas_np[sorted_indices]
masks_list = [masks[i] for i in range(len(masks))]
masks_sorted = [masks_list[i] for i in sorted_indices]
keep_indices = []
suppressed = set()
fused_masks = masks_sorted.copy()
for i in range(len(boxes_sorted)):
if i in suppressed:
continue
keep_indices.append(i)
current_mask = fused_masks[i]
for j in range(i + 1, len(boxes_sorted)):
if j in suppressed:
continue
iou = Ronghe_calculate_iou(boxes_sorted[i], boxes_sorted[j])
if iou > iou_threshold:
mask_overlap = calculate_mask_overlap(current_mask, masks_sorted[j])
suppressed.add(j)
fused_mask = fuse_two_masks(current_mask, masks_sorted[j])
fused_masks[i] = fused_mask
current_mask = fused_mask
print(f"融合检测结果: 索引 {sorted_indices[i]} (面积: {areas_sorted[i]:.1f}) 融合索引 {sorted_indices[j]} (面积: {areas_sorted[j]:.1f})",
" iou:", iou, " mask重叠:", mask_overlap)
else:
pass
final_indices = [sorted_indices[i] for i in keep_indices]
final_masks_list = [fused_masks[i] for i in keep_indices]
final_masks = torch.stack(final_masks_list)
final_boxes = boxes[final_indices]
final_scores = scores[final_indices]
print(f"融合后剩余 {len(final_masks)} 个分割结果 (减少了 {len(masks) - len(final_masks)} 个)")
return final_masks, final_boxes, final_scores
def fuse_two_masks(mask1, mask2):
"""将两个mask融合"""
fused_mask = torch.logical_or(mask1, mask2).float()
return fused_mask
def overlay_masks_with_tracking(image, masks, boxes, scores, track_ids, tracker, fusion_mode=False):
"""在图像上叠加掩码,并显示跟踪ID和状态"""
image = image.convert("RGB")
draw = ImageDraw.Draw(image)
try:
font = ImageFont.truetype("SimHei.ttf", 40) # 减小字体大小以显示更多信息
except:
try:
font = ImageFont.truetype("Arial.ttf", 40)
except:
font = ImageFont.load_default()
masks_np = masks.cpu().numpy().astype(np.uint8)
masks_np = masks_np.squeeze(1)
boxes_np = boxes.cpu().numpy()
scores_np = scores.cpu().numpy()
for i, (mask, box, score, track_id) in enumerate(zip(masks_np, boxes_np, scores_np, track_ids)):
# 从tracker获取该track_id对应的颜色和状态
color = tracker.get_track_color(track_id)
status = tracker.get_track_status(track_id)
# 获取跟踪的详细信息
track_info = tracker.tracks.get(track_id, None)
if track_info:
hit_streak = track_info.hit_streak
miss_count = track_info.miss_count
age = track_info.age
else:
hit_streak = 0
miss_count = 0
age = 1
if mask.ndim == 3:
mask = mask.squeeze(0)
alpha_mask = (mask * 128).astype(np.uint8)
overlay = Image.new("RGBA", image.size, color + (128,))
alpha = Image.fromarray(alpha_mask, mode='L')
overlay.putalpha(alpha)
image = Image.alpha_composite(image.convert("RGBA"), overlay).convert("RGB")
draw = ImageDraw.Draw(image)
x1, y1, x2, y2 = box
x1 = max(0, min(x1, image.width))
y1 = max(0, min(y1, image.height))
x2 = max(0, min(x2, image.width))
y2 = max(0, min(y2, image.height))
# 根据状态选择边框颜色和样式
if status == TrackState.CONFIRMED:
# 已确认目标:实线边框
draw.rectangle([x1, y1, x2, y2], outline=color, width=3)
else:
# 未确认目标:虚线边框
draw.rectangle([x1, y1, x2, y2], outline=color, width=2)
# 绘制虚线效果
dash_length = 5
for x in range(int(x1), int(x2), dash_length*2):
draw.line([x, y1, x+dash_length, y1], fill=color, width=2)
draw.line([x, y2, x+dash_length, y2], fill=color, width=2)
for y in range(int(y1), int(y2), dash_length*2):
draw.line([x1, y, x1, y+dash_length], fill=color, width=2)
draw.line([x2, y, x2, y+dash_length], fill=color, width=2)
# 构建显示文本
if fusion_mode:
base_text = f"Track:{track_id}({status}) F-ID:{i} S:{score:.2f}"
else:
base_text = f"Track:{track_id}({status}) ID:{i} S:{score:.2f}"
# 添加跟踪统计信息
stat_text = f"H:{hit_streak} M:{miss_count} A:{age}"
full_text = f"{base_text}\n{stat_text}"
try:
# 计算文本尺寸
lines = full_text.split('\n')
text_bbox = [draw.textbbox((0, 0), line, font=font) for line in lines]
text_width = max(bbox[2] - bbox[0] for bbox in text_bbox)
text_height = sum(bbox[3] - bbox[1] for bbox in text_bbox) + 5 * (len(lines) - 1)
except:
text_width, text_height = 200, 40
text_x = x1
text_y = max(0, y1 - text_height - 5)
# 绘制文本背景
draw.rectangle([text_x, text_y, text_x + text_width + 10, text_y + text_height + 5],
fill=color)
# 绘制文本
y_offset = text_y + 2
for line in lines:
draw.text((text_x + 5, y_offset), line, fill="white", font=font)
y_offset += font.size + 2
return image
def extract_number_from_filename(filename):
"""从DJI_XXXX.JPG格式的文件名中提取数字"""
try:
if filename.startswith('DJI_') and filename.endswith(('.JPG', '.jpg', '.JPEG', '.jpeg')):
number_part = filename[4:].split('.')[0]
return int(number_part)
except (ValueError, IndexError):
pass
return float('inf')
def process_image_folder(processor, folder_path, output_dir="output"):
"""处理文件夹中的所有图像(使用增强的特征点跟踪器)"""
os.makedirs(output_dir, exist_ok=True)
image_extensions = ['*.jpg', '*.jpeg', '*.png', '*.bmp', '*.tiff', '*.tif', '*.JPG', '*.JPEG', '*.PNG']
image_files = []
for ext in image_extensions:
image_files.extend(glob.glob(os.path.join(folder_path, ext)))
image_files.sort(key=lambda x: extract_number_from_filename(os.path.basename(x)))
print(f"找到 {len(image_files)} 张图像")
# 使用增强的特征点跟踪器
tracker = FeatureBasedTracker(iou_threshold=0.3, min_matches=10, reid_threshold=0.7)
results = []
for i, image_path in enumerate(image_files):
print(f"\n{'='*50}")
print(f"处理第 {i+1}/{len(image_files)} 张图像: {os.path.basename(image_path)}")
try:
# 检测图像
masks, boxes, scores = Get_image_mask(processor, image_path)
if len(masks) == 0:
print("未检测到目标,跳过此图像")
# 更新跟踪器(标记丢失)
current_image = Image.open(image_path)
tracker.update(current_image, [], [], [])
del masks, boxes, scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 融合重叠的mask
fused_masks, fused_boxes, fused_scores = fuse_overlapping_masks(
masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6
)
if len(fused_boxes) == 0:
print("融合后无目标,跳过此图像")
current_image = Image.open(image_path)
tracker.update(current_image, [], [], [])
del masks, boxes, scores, fused_masks, fused_boxes, fused_scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 加载当前图像用于特征点跟踪
current_image = Image.open(image_path)
# 使用增强的特征点跟踪器进行目标跟踪
track_ids = tracker.update(current_image, fused_masks, fused_boxes.cpu().numpy(),
fused_scores.cpu().numpy())
# 打印跟踪统计信息
confirmed_count = sum(1 for tid in track_ids if tracker.get_track_status(tid) == TrackState.CONFIRMED)
unconfirmed_count = len(track_ids) - confirmed_count
print(f"跟踪统计: 总目标 {len(track_ids)}, 已确认 {confirmed_count}, 未确认 {unconfirmed_count}")
# 保存结果
image_name = os.path.splitext(os.path.basename(image_path))[0]
save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, i, tracker)
results.append({
'image_path': image_path,
'image_name': image_name,
'track_ids': track_ids,
'confirmed_count': confirmed_count,
'unconfirmed_count': unconfirmed_count
})
except Exception as e:
print(f"处理图像 {image_path} 时出错: {e}")
import traceback
traceback.print_exc()
finally:
variables_to_delete = ['masks', 'boxes', 'scores', 'fused_masks', 'fused_boxes',
'fused_scores', 'current_image']
for var_name in variables_to_delete:
if var_name in locals():
del locals()[var_name]
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
print(f"内存清理完成,准备处理下一张图像")
return results
def save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, image_index, tracker):
"""保存单张图像的结果"""
original_image = Image.open(image_path)
# 应用跟踪结果显示(传入tracker参数)
result_image_original = overlay_masks_with_tracking(
original_image, masks, boxes, scores,
list(range(len(masks))), tracker, fusion_mode=False
)
result_image_fused = overlay_masks_with_tracking(
original_image, fused_masks, fused_boxes, fused_scores,
track_ids, tracker, fusion_mode=True
)
# 创建并保存对比图像
create_comparison_image(
result_image_original, result_image_fused,
len(masks), len(fused_masks), output_dir, image_name, image_index, tracker
)
del original_image, result_image_original, result_image_fused
gc.collect()
def create_comparison_image(original_img, fused_img, n_original, n_fused, output_dir, image_name, image_index, tracker):
"""创建、保存并显示对比图像"""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
ax1.imshow(original_img)
ax1.set_title(f"Original Result - {image_name}: {n_original} segments", fontsize=14)
ax1.axis('off')
ax2.imshow(fused_img)
ax2.set_title(f"Fused with Tracking - {image_name}: {n_fused} segments", fontsize=14)
ax2.axis('off')
plt.tight_layout()
comparison_path = os.path.join(output_dir, f"segmentation_comparison_{image_name}.png")
plt.savefig(comparison_path, dpi=300, bbox_inches='tight', facecolor='white')
print(f"对比图像已保存: {comparison_path}")
if image_index < 3:
plt.show()
else:
plt.close(fig)
plt.close('all')
def main():
"""主函数"""
processor = load_moad("sam3.pt")
folder_path = "/home/dongdong/2project/0data/RTK/data_4_city/300_map_2pm/images/"
output_dir = "output"
try:
results = process_image_folder(processor, folder_path, output_dir)
# 打印最终统计信息
total_confirmed = sum(r['confirmed_count'] for r in results if 'confirmed_count' in r)
total_unconfirmed = sum(r['unconfirmed_count'] for r in results if 'unconfirmed_count' in r)
print(f"\n处理完成!共处理 {len(results)} 张图像")
print(f"跟踪统计: 总确认目标 {total_confirmed}, 总未确认目标 {total_unconfirmed}")
print(f"结果保存在 {output_dir} 目录中")
except Exception as e:
print(f"处理过程中出错: {e}")
import traceback
traceback.print_exc()
finally:
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
if __name__ == "__main__":
main()
样例4
1检测画框,并且合并框,并且合并mask
2按照框大小,然后融合重叠的框
3 匈牙利匹配跟踪
4 从文件夹读取照片
5保存结果
6 内存管理
7 跟踪效果
计算H 变换 然后将当前帧变换到上一帧去匹配mask,
for j, (curr_mask, curr_box) in enumerate(zip(current_masks, current_boxes)):
# 计算mask相似度
mask_similarity = self.calculate_mask_similarity(transformed_mask, curr_mask)
# 计算变换后框的IoU
iou = self.calculate_iou(transformed_box, curr_box)
# 综合相似度
total_similarity = 0.6 * mask_similarity + 0.4 * iou
cost_matrix[i, j] = 1 - total_similarity
然后匈牙利匹配。
等待增夹稳定的跟踪
import torch
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib.patches as patches
import time
import os
import glob
from scipy.optimize import linear_sum_assignment # 匈牙利匹配算法
import colorsys
import gc
import matplotlib
matplotlib.use('TkAgg')
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="tkinter")
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore")
# 新增导入
import cv2
#################################### For Image ####################################
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
class FeatureBasedTracker:
"""基于特征点的目标跟踪器,适用于无人机俯视图像"""
def __init__(self, iou_threshold=0.3, min_matches=10, ransac_thresh=5.0):
self.iou_threshold = iou_threshold
self.min_matches = min_matches
self.ransac_thresh = ransac_thresh
self.next_id = 0
self.tracks = {} # {track_id: {'box': box, 'mask': mask, 'features': features}}
self.previous_image = None
self.previous_keypoints = None
self.previous_descriptors = None
self.track_colors = {}
# 特征检测器
self.sift = cv2.SIFT_create()
# 备用ORB检测器
self.orb = cv2.ORB_create(1000)
def extract_features(self, image):
"""提取图像特征点"""
gray = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2GRAY)
# 尝试SIFT,如果失败则使用ORB
try:
keypoints, descriptors = self.sift.detectAndCompute(gray, None)
if descriptors is not None and len(descriptors) > 10:
return keypoints, descriptors
except:
pass
# 使用ORB作为备用
keypoints, descriptors = self.orb.detectAndCompute(gray, None)
return keypoints, descriptors
def calculate_homography(self, kp1, desc1, kp2, desc2):
"""计算两帧之间的单应性矩阵"""
if desc1 is None or desc2 is None or len(desc1) < 4 or len(desc2) < 4:
return None
# 根据描述符类型选择匹配方法
if desc1.dtype == np.float32: # SIFT描述符
# 使用FLANN匹配器
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(desc1, desc2, k=2)
# Lowe's ratio test
good_matches = []
for match_pair in matches:
if len(match_pair) == 2:
m, n = match_pair
if m.distance < 0.7 * n.distance:
good_matches.append(m)
else: # ORB描述符
# 使用BFMatcher
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(desc1, desc2)
matches = sorted(matches, key=lambda x: x.distance)
good_matches = matches[:min(50, len(matches))]
if len(good_matches) < self.min_matches:
return None
# 提取匹配点坐标
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
# 计算单应性矩阵
try:
H, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, self.ransac_thresh)
return H
except:
return None
def transform_mask(self, mask, H, target_shape):
"""使用单应性矩阵变换mask"""
try:
mask_np = mask.cpu().numpy().squeeze().astype(np.uint8)
# 应用透视变换
transformed_mask = cv2.warpPerspective(mask_np, H, (target_shape[1], target_shape[0]))
transformed_mask = (transformed_mask > 0.5).astype(np.float32)
return torch.from_numpy(transformed_mask).unsqueeze(0)
except:
return mask
def transform_box(self, box, H):
"""使用单应性矩阵变换边界框"""
try:
x1, y1, x2, y2 = box
corners = np.array([[[x1, y1]], [[x2, y1]], [[x2, y2]], [[x1, y2]]], dtype=np.float32)
transformed_corners = cv2.perspectiveTransform(corners, H)
tx1 = transformed_corners[:, :, 0].min()
ty1 = transformed_corners[:, :, 1].min()
tx2 = transformed_corners[:, :, 0].max()
ty2 = transformed_corners[:, :, 1].max()
return [max(0, tx1), max(0, ty1), max(0, tx2), max(0, ty2)]
except:
return box
def calculate_mask_similarity(self, mask1, mask2):
"""计算两个mask的相似度(考虑重叠和形状)"""
try:
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
intersection = np.logical_and(mask1_np, mask2_np)
union = np.logical_or(mask1_np, mask2_np)
if np.sum(union) == 0:
return 0.0
iou = np.sum(intersection) / np.sum(union)
# 添加形状相似性度量
mask1_area = np.sum(mask1_np)
mask2_area = np.sum(mask2_np)
if max(mask1_area, mask2_area) == 0:
area_similarity = 0.0
else:
area_similarity = 1 - abs(mask1_area - mask2_area) / max(mask1_area, mask2_area)
# 综合相似度
similarity = 0.7 * iou + 0.3 * area_similarity
return similarity
except:
return 0.0
def hungarian_matching_with_similarity(self, previous_data, current_masks, current_boxes, H, image_shape):
"""使用匈牙利算法进行基于相似度的匹配"""
if len(previous_data) == 0 or len(current_masks) == 0:
return []
# 构建成本矩阵(1 - 相似度)
cost_matrix = np.ones((len(previous_data), len(current_masks)))
for i, prev_data in enumerate(previous_data):
prev_mask = prev_data['mask']
prev_box = prev_data['box']
# 变换前一帧的mask到当前帧坐标系
if H is not None:
try:
transformed_mask = self.transform_mask(prev_mask, H, image_shape)
transformed_box = self.transform_box(prev_box, H)
except:
transformed_mask = prev_mask
transformed_box = prev_box
else:
transformed_mask = prev_mask
transformed_box = prev_box
for j, (curr_mask, curr_box) in enumerate(zip(current_masks, current_boxes)):
# 计算mask相似度
mask_similarity = self.calculate_mask_similarity(transformed_mask, curr_mask)
# 计算变换后框的IoU
iou = self.calculate_iou(transformed_box, curr_box)
# 综合相似度
total_similarity = 0.6 * mask_similarity + 0.4 * iou
cost_matrix[i, j] = 1 - total_similarity
# 匈牙利算法匹配
row_ind, col_ind = linear_sum_assignment(cost_matrix)
matches = []
for i, j in zip(row_ind, col_ind):
if cost_matrix[i, j] <= (1 - self.iou_threshold):
matches.append((i, j, 1 - cost_matrix[i, j]))
return matches
def calculate_iou(self, box1, box2):
"""计算两个边界框的IoU"""
try:
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
return inter_area / union_area if union_area > 0 else 0.0
except:
return 0.0
def get_track_color(self, track_id):
"""为track_id获取或生成颜色"""
if track_id not in self.track_colors:
hue = (track_id * 0.618033988749895) % 1.0
saturation = 0.8 + (track_id % 3) * 0.1
value = 0.8 + (track_id % 2) * 0.2
r, g, b = colorsys.hsv_to_rgb(hue, saturation, value)
self.track_colors[track_id] = (int(r * 255), int(g * 255), int(b * 255))
return self.track_colors[track_id]
def update(self, current_image, current_masks, current_boxes, current_scores):
"""更新跟踪器状态"""
# 初始化current_track_ids,确保在所有分支都有返回值
current_track_ids = []
# 检查是否有检测结果
if len(current_masks) == 0:
print("警告:当前帧没有检测到目标")
# 更新前一帧信息(即使没有目标也要更新)
self.previous_image = current_image
self.previous_keypoints, self.previous_descriptors = self.extract_features(current_image)
return current_track_ids # 返回空列表
current_keypoints, current_descriptors = self.extract_features(current_image)
# 计算单应性矩阵
H = None
if self.previous_image is not None and current_keypoints is not None and self.previous_keypoints is not None:
H = self.calculate_homography(self.previous_keypoints, self.previous_descriptors,
current_keypoints, current_descriptors)
# 获取图像形状用于mask变换
image_shape = current_masks[0].shape[-2:] if len(current_masks) > 0 else (current_image.height, current_image.width)
if self.previous_image is None:
# 第一帧初始化
track_ids = list(range(self.next_id, self.next_id + len(current_masks)))
self.next_id += len(current_masks)
self.tracks = {}
for track_id, (mask, box, score) in zip(track_ids, zip(current_masks, current_boxes, current_scores)):
self.tracks[track_id] = {
'mask': mask, 'box': box, 'score': score
}
self.get_track_color(track_id)
current_track_ids = track_ids
else:
# 使用匈牙利算法匹配
previous_data = [{'mask': data['mask'], 'box': data['box']}
for data in self.tracks.values()]
matches = self.hungarian_matching_with_similarity(
previous_data, current_masks, current_boxes, H, image_shape
)
# 分配跟踪ID
current_track_ids = [-1] * len(current_masks)
used_track_ids = set()
# 处理匹配的目标
track_id_list = list(self.tracks.keys())
for i, j, similarity in matches:
if i < len(track_id_list):
track_id = track_id_list[i]
current_track_ids[j] = track_id
used_track_ids.add(track_id)
# 更新跟踪器状态
self.tracks[track_id] = {
'mask': current_masks[j],
'box': current_boxes[j],
'score': current_scores[j]
}
# 处理未匹配的目标(新目标)
for j in range(len(current_masks)):
if current_track_ids[j] == -1:
new_id = self.next_id
self.next_id += 1
current_track_ids[j] = new_id
self.tracks[new_id] = {
'mask': current_masks[j],
'box': current_boxes[j],
'score': current_scores[j]
}
self.get_track_color(new_id)
# 清理丢失的跟踪
current_track_set = set(current_track_ids)
lost_tracks = [tid for tid in self.tracks.keys() if tid not in current_track_set]
for track_id in lost_tracks:
if track_id in self.tracks:
del self.tracks[track_id]
# 更新前一帧信息
self.previous_image = current_image
self.previous_keypoints = current_keypoints
self.previous_descriptors = current_descriptors
return current_track_ids
def load_moad(mode_path="sam3.pt"):
"""加载模型"""
model_load_start_time = time.time()
model = build_sam3_image_model(
checkpoint_path=mode_path
)
processor = Sam3Processor(model, confidence_threshold=0.5)
model_load_end_time = time.time()
model_load_time = model_load_end_time - model_load_start_time
print(f"模型加载时间: {model_load_time:.3f} 秒")
return processor
def Get_image_mask(processor, image_path):
"""获取图像分割结果"""
detection_start_time = time.time()
image = Image.open(image_path)
inference_state = processor.set_image(image)
output = processor.set_text_prompt(state=inference_state, prompt="building")
masks, boxes, scores = output["masks"], output["boxes"], output["scores"]
detection_end_time = time.time()
detection_time = detection_end_time - detection_start_time
print(f"检测单张时间: {detection_time:.3f} 秒")
print(f"原始检测到 {len(masks)} 个分割结果")
print(f"掩码形状: {masks.shape}")
return masks, boxes, scores
def Ronghe_calculate_iou(box1, box2):
"""计算两个边界框的IoU"""
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
if union_area == 0:
return 0.0
# 这里的iou是用来合并mask的,不许修改计算方式,这个不同于iou重叠度的计算。
iou_2 = inter_area / box2_area
iou_1 = inter_area / box1_area
iou = max(iou_2, iou_1)
# iou = inter_area/union_area
return iou
def calculate_mask_overlap(mask1, mask2):
"""计算两个掩码的重叠比例"""
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
intersection = np.logical_and(mask1_np, mask2_np)
mask1_area = np.sum(mask1_np)
if mask1_area == 0:
return 0.0
overlap_ratio = np.sum(intersection) / mask1_area
return overlap_ratio
def fuse_overlapping_masks(masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6):
"""融合重叠的掩码和边界框"""
if len(masks) == 0:
return masks, boxes, scores
boxes_np = boxes.cpu().numpy().copy()
scores_np = scores.cpu().numpy().copy()
areas = []
for box in boxes_np:
x1, y1, x2, y2 = box
width = x2 - x1
height = y2 - y1
area = width * height
areas.append(area)
areas_np = np.array(areas)
sorted_indices = np.argsort(areas_np)[::-1]
boxes_sorted = boxes_np[sorted_indices]
scores_sorted = scores_np[sorted_indices]
areas_sorted = areas_np[sorted_indices]
masks_list = [masks[i] for i in range(len(masks))]
masks_sorted = [masks_list[i] for i in sorted_indices]
keep_indices = []
suppressed = set()
fused_masks = masks_sorted.copy()
for i in range(len(boxes_sorted)):
if i in suppressed:
continue
keep_indices.append(i)
current_mask = fused_masks[i]
for j in range(i + 1, len(boxes_sorted)):
if j in suppressed:
continue
iou = Ronghe_calculate_iou(boxes_sorted[i], boxes_sorted[j])
if iou > iou_threshold:
mask_overlap = calculate_mask_overlap(current_mask, masks_sorted[j])
suppressed.add(j)
fused_mask = fuse_two_masks(current_mask, masks_sorted[j])
fused_masks[i] = fused_mask
current_mask = fused_mask
print(f"融合检测结果: 索引 {sorted_indices[i]} (面积: {areas_sorted[i]:.1f}) 融合索引 {sorted_indices[j]} (面积: {areas_sorted[j]:.1f})",
" iou:", iou, " mask重叠:", mask_overlap)
else:
#print(f"IoU不足: 索引 {sorted_indices[i]} 和索引 {sorted_indices[j]}", " iou:", iou)
pass
final_indices = [sorted_indices[i] for i in keep_indices]
final_masks_list = [fused_masks[i] for i in keep_indices]
final_masks = torch.stack(final_masks_list)
final_boxes = boxes[final_indices]
final_scores = scores[final_indices]
print(f"融合后剩余 {len(final_masks)} 个分割结果 (减少了 {len(masks) - len(final_masks)} 个)")
return final_masks, final_boxes, final_scores
def fuse_two_masks(mask1, mask2):
"""将两个mask融合"""
fused_mask = torch.logical_or(mask1, mask2).float()
return fused_mask
def overlay_masks_with_tracking(image, masks, boxes, scores, track_ids, tracker, fusion_mode=False):
"""在图像上叠加掩码,并显示跟踪ID(使用tracker中的颜色)"""
image = image.convert("RGB")
draw = ImageDraw.Draw(image)
try:
font = ImageFont.truetype("SimHei.ttf", 60)
except:
try:
font = ImageFont.truetype("Arial.ttf", 60)
except:
font = ImageFont.load_default()
masks_np = masks.cpu().numpy().astype(np.uint8)
masks_np = masks_np.squeeze(1)
boxes_np = boxes.cpu().numpy()
scores_np = scores.cpu().numpy()
for i, (mask, box, score, track_id) in enumerate(zip(masks_np, boxes_np, scores_np, track_ids)):
# 从tracker获取该track_id对应的颜色
color = tracker.get_track_color(track_id)
if mask.ndim == 3:
mask = mask.squeeze(0)
alpha_mask = (mask * 128).astype(np.uint8)
overlay = Image.new("RGBA", image.size, color + (128,))
alpha = Image.fromarray(alpha_mask, mode='L')
overlay.putalpha(alpha)
image = Image.alpha_composite(image.convert("RGBA"), overlay).convert("RGB")
draw = ImageDraw.Draw(image)
x1, y1, x2, y2 = box
x1 = max(0, min(x1, image.width))
y1 = max(0, min(y1, image.height))
x2 = max(0, min(x2, image.width))
y2 = max(0, min(y2, image.height))
draw.rectangle([x1, y1, x2, y2], outline=color, width=3)
if fusion_mode:
text = f"Track:{track_id} Fused-ID:{i} Score:{score:.3f}"
else:
text = f"Track:{track_id} ID:{i} Score:{score:.3f}"
try:
left, top, right, bottom = draw.textbbox((0, 0), text, font=font)
text_width = right - left
text_height = bottom - top
except:
text_width, text_height = draw.textsize(text, font=font)
text_x = x1
text_y = max(0, y1 - text_height - 5)
draw.rectangle([text_x, text_y, text_x + text_width + 10, text_y + text_height + 5],
fill=color)
draw.text((text_x + 5, text_y + 2), text, fill="white", font=font)
return image
def extract_number_from_filename(filename):
"""从DJI_XXXX.JPG格式的文件名中提取数字"""
try:
# 匹配DJI_XXXX.JPG格式
if filename.startswith('DJI_') and filename.endswith(('.JPG', '.jpg', '.JPEG', '.jpeg')):
# 提取DJI_和扩展名之间的数字部分
number_part = filename[4:].split('.')[0]
return int(number_part)
except (ValueError, IndexError):
pass
return float('inf') # 如果不是DJI格式,返回无穷大,使其排在后面
def process_image_folder(processor, folder_path, output_dir="output"):
"""处理文件夹中的所有图像(使用新的特征点跟踪器)"""
os.makedirs(output_dir, exist_ok=True)
# 获取图像文件
image_extensions = ['*.jpg', '*.jpeg', '*.png', '*.bmp', '*.tiff', '*.tif', '*.JPG', '*.JPEG', '*.PNG']
image_files = []
for ext in image_extensions:
image_files.extend(glob.glob(os.path.join(folder_path, ext)))
image_files.sort(key=lambda x: extract_number_from_filename(os.path.basename(x)))
print(f"找到 {len(image_files)} 张图像")
# 使用新的特征点跟踪器
tracker = FeatureBasedTracker(iou_threshold=0.3, min_matches=10)
results = []
for i, image_path in enumerate(image_files):
print(f"\n{'='*50}")
print(f"处理第 {i+1}/{len(image_files)} 张图像: {os.path.basename(image_path)}")
try:
# 检测图像
masks, boxes, scores = Get_image_mask(processor, image_path)
if len(masks) == 0:
print("未检测到目标,跳过此图像")
del masks, boxes, scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 融合重叠的mask
fused_masks, fused_boxes, fused_scores = fuse_overlapping_masks(
masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6
)
if len(fused_boxes) == 0:
print("融合后无目标,跳过此图像")
del masks, boxes, scores, fused_masks, fused_boxes, fused_scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 加载当前图像用于特征点跟踪
current_image = Image.open(image_path)
# 使用特征点跟踪器进行目标跟踪
track_ids = tracker.update(current_image, fused_masks, fused_boxes.cpu().numpy(),
fused_scores.cpu().numpy())
# 保存结果
image_name = os.path.splitext(os.path.basename(image_path))[0]
save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, i, tracker)
results.append({
'image_path': image_path,
'image_name': image_name,
'track_ids': track_ids
})
except Exception as e:
print(f"处理图像 {image_path} 时出错: {e}")
import traceback
traceback.print_exc()
finally:
variables_to_delete = ['masks', 'boxes', 'scores', 'fused_masks', 'fused_boxes',
'fused_scores', 'current_image']
for var_name in variables_to_delete:
if var_name in locals():
del locals()[var_name]
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
print(f"内存清理完成,准备处理下一张图像")
return results
def save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, image_index, tracker):
"""保存单张图像的结果"""
original_image = Image.open(image_path)
# 应用跟踪结果显示(传入tracker参数)
result_image_original = overlay_masks_with_tracking(
original_image, masks, boxes, scores,
list(range(len(masks))), tracker, fusion_mode=False
)
result_image_fused = overlay_masks_with_tracking(
original_image, fused_masks, fused_boxes, fused_scores,
track_ids, tracker, fusion_mode=True
)
# 创建并保存对比图像,并显示每一张
create_comparison_image(
result_image_original, result_image_fused,
len(masks), len(fused_masks), output_dir, image_name, image_index, tracker
)
# 及时释放图像变量
del original_image, result_image_original, result_image_fused
gc.collect()
def create_comparison_image(original_img, fused_img, n_original, n_fused, output_dir, image_name, image_index, tracker):
"""创建、保存并显示对比图像"""
# 创建图形
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
# 显示原始结果
ax1.imshow(original_img)
ax1.set_title(f"Original Result - {image_name}: {n_original} segments", fontsize=14)
ax1.axis('off')
# 显示融合后结果
ax2.imshow(fused_img)
ax2.set_title(f"Fused with Tracking - {image_name}: {n_fused} segments", fontsize=14)
ax2.axis('off')
plt.tight_layout()
# 保存对比图像
comparison_path = os.path.join(output_dir, f"segmentation_comparison_{image_name}.png")
plt.savefig(comparison_path, dpi=300, bbox_inches='tight', facecolor='white')
print(f"对比图像已保存: {comparison_path}")
# 显示图像(每张都显示,但限制数量避免卡顿)
if image_index < 3: # 只显示前3张
plt.show()
else:
plt.close(fig) # 关闭图形以释放内存
plt.close('all') # 关闭所有图形
def main():
"""主函数"""
# 1. 加载模型
processor = load_moad("sam3.pt")
# 2. 处理文件夹中的图像
folder_path = "/home/dongdong/2project/0data/RTK/data_4_city/300_map_2pm/images/"
output_dir = "output"
try:
results = process_image_folder(processor, folder_path, output_dir)
print(f"\n处理完成!共处理 {len(results)} 张图像")
print(f"结果保存在 {output_dir} 目录中")
except Exception as e:
print(f"处理过程中出错: {e}")
import traceback
traceback.print_exc()
finally:
# 最终清理
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
if __name__ == "__main__":
main()
样例3
1检测画框,并且合并框,并且合并mask
2按照框大小,然后融合重叠的框
3 匈牙利匹配跟踪
4 从文件夹读取照片
5保存结果
6 内存管理
7 跟踪效果不好,容易丢失切换。



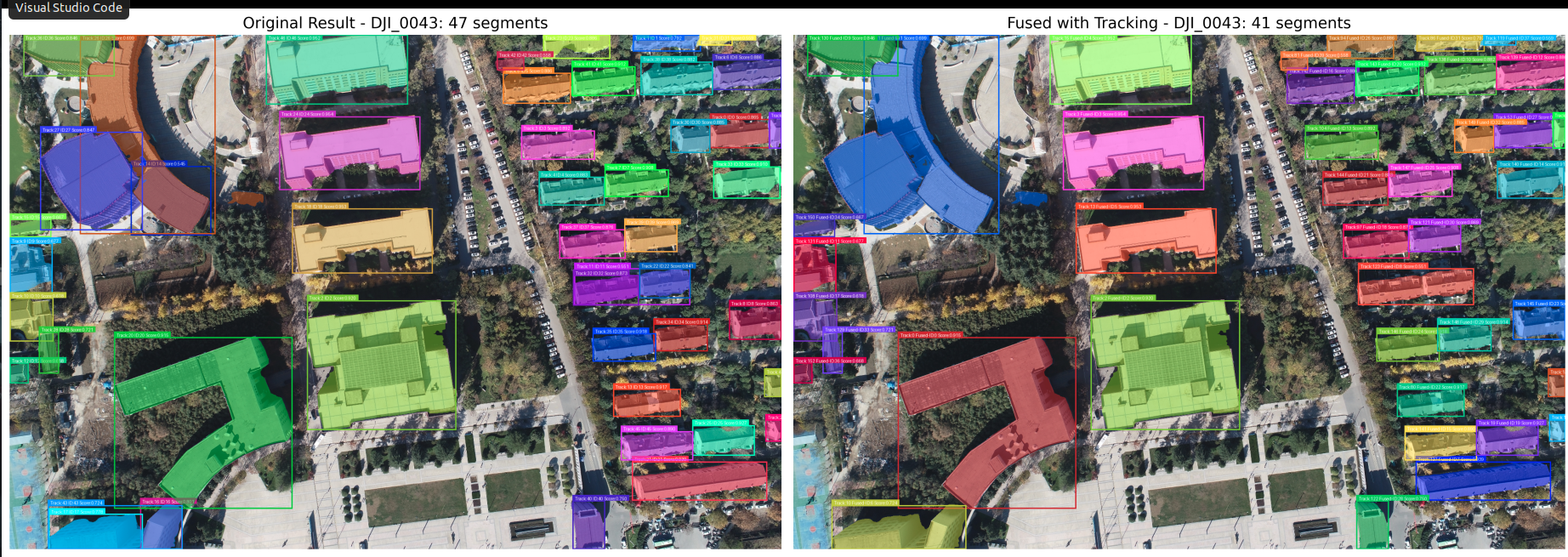


import torch
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib.patches as patches
import time
import os
import glob
from scipy.optimize import linear_sum_assignment # 匈牙利匹配算法
import colorsys
import gc
import matplotlib
matplotlib.use('TkAgg')
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="tkinter")
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore")
#################################### For Image ####################################
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
class ObjectTracker:
"""目标跟踪器,使用匈牙利算法进行ID匹配"""
def __init__(self, iou_threshold=0.3):
self.iou_threshold = iou_threshold
self.next_id = 0
self.tracks = {} # {track_id: last_box}
self.previous_boxes = None
self.track_colors = {} # 存储每个track_id对应的颜色
def hungarian_matching(self, boxes1, boxes2):
"""使用匈牙利算法进行框匹配"""
if len(boxes1) == 0 or len(boxes2) == 0:
return []
# 计算成本矩阵(使用1-IoU作为成本)
cost_matrix = np.zeros((len(boxes1), len(boxes2)))
for i, box1 in enumerate(boxes1):
for j, box2 in enumerate(boxes2):
iou = self.calculate_iou(box1, box2)
cost_matrix[i, j] = 1 - iou # 成本 = 1 - IoU
# 匈牙利算法求解
row_ind, col_ind = linear_sum_assignment(cost_matrix)
matches = []
for i, j in zip(row_ind, col_ind):
if cost_matrix[i, j] <= (1 - self.iou_threshold): # IoU >= threshold
matches.append((i, j, 1 - cost_matrix[i, j])) # (index1, index2, iou)
return matches
def calculate_iou(self, box1, box2):
"""计算两个边界框的IoU"""
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
if union_area == 0:
return 0.0
# iou_2 = inter_area / box2_area
# iou_1 = inter_area / box1_area
# iou = max(iou_2, iou_1)
iou = inter_area/union_area
return iou
return iou
def get_track_color(self, track_id):
"""为track_id获取或生成颜色"""
if track_id not in self.track_colors:
# 生成新的颜色(使用HSV色彩空间确保颜色差异明显)
hue = (track_id * 0.618033988749895) % 1.0 # 黄金比例分割
saturation = 0.8 + (track_id % 3) * 0.1 # 0.8-1.0之间的饱和度
value = 0.8 + (track_id % 2) * 0.2 # 0.8-1.0之间的亮度
# 转换为RGB
r, g, b = colorsys.hsv_to_rgb(hue, saturation, value)
self.track_colors[track_id] = (int(r * 255), int(g * 255), int(b * 255))
return self.track_colors[track_id]
def update(self, current_boxes, current_scores):
"""更新跟踪器状态"""
if self.previous_boxes is None or len(self.previous_boxes) == 0:
# 第一帧,初始化所有跟踪
track_ids = list(range(self.next_id, self.next_id + len(current_boxes)))
self.next_id += len(current_boxes)
self.tracks = {track_id: box for track_id, box in zip(track_ids, current_boxes)}
self.previous_boxes = current_boxes.copy()
# 为新track_id生成颜色
for track_id in track_ids:
self.get_track_color(track_id)
return track_ids
# 使用匈牙利算法匹配
matches = self.hungarian_matching(self.previous_boxes, current_boxes)
# 分配跟踪ID
current_track_ids = [-1] * len(current_boxes) # 初始化为-1
# 处理匹配的目标
used_track_ids = set()
for i, j, iou in matches:
# 获取对应的track_id
track_id_list = list(self.tracks.keys())
if i < len(track_id_list):
track_id = track_id_list[i]
current_track_ids[j] = track_id
used_track_ids.add(track_id)
# 更新跟踪器状态
self.tracks[track_id] = current_boxes[j]
# 处理未匹配的目标(新目标)
for j in range(len(current_boxes)):
if current_track_ids[j] == -1: # 新目标
new_id = self.next_id
self.next_id += 1
current_track_ids[j] = new_id
self.tracks[new_id] = current_boxes[j]
# 为新track_id生成颜色
self.get_track_color(new_id)
# 清理丢失的跟踪(只保留当前帧中存在的跟踪)
current_track_set = set(current_track_ids)
lost_tracks = [tid for tid in self.tracks.keys() if tid not in current_track_set]
for track_id in lost_tracks:
if track_id in self.tracks:
del self.tracks[track_id]
# 注意:不删除颜色,以便如果目标重新出现时使用相同颜色
self.previous_boxes = current_boxes.copy()
return current_track_ids
def load_moad(mode_path="sam3.pt"):
"""加载模型"""
model_load_start_time = time.time()
model = build_sam3_image_model(
checkpoint_path=mode_path
)
processor = Sam3Processor(model, confidence_threshold=0.5)
model_load_end_time = time.time()
model_load_time = model_load_end_time - model_load_start_time
print(f"模型加载时间: {model_load_time:.3f} 秒")
return processor
def Get_image_mask(processor, image_path):
"""获取图像分割结果"""
detection_start_time = time.time()
image = Image.open(image_path)
inference_state = processor.set_image(image)
output = processor.set_text_prompt(state=inference_state, prompt="building")
masks, boxes, scores = output["masks"], output["boxes"], output["scores"]
detection_end_time = time.time()
detection_time = detection_end_time - detection_start_time
print(f"检测单张时间: {detection_time:.3f} 秒")
print(f"原始检测到 {len(masks)} 个分割结果")
print(f"掩码形状: {masks.shape}")
return masks, boxes, scores
def Ronghe_calculate_iou(box1, box2):
"""计算两个边界框的IoU"""
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
if union_area == 0:
return 0.0
# 这里的iou是用来合并mask的,不许修改计算方式,这个不同于iou重叠度的计算。
iou_2 = inter_area / box2_area
iou_1 = inter_area / box1_area
iou = max(iou_2, iou_1)
# iou = inter_area/union_area
return iou
def calculate_mask_overlap(mask1, mask2):
"""计算两个掩码的重叠比例"""
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
intersection = np.logical_and(mask1_np, mask2_np)
mask1_area = np.sum(mask1_np)
if mask1_area == 0:
return 0.0
overlap_ratio = np.sum(intersection) / mask1_area
return overlap_ratio
def fuse_overlapping_masks(masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6):
"""融合重叠的掩码和边界框"""
if len(masks) == 0:
return masks, boxes, scores
boxes_np = boxes.cpu().numpy().copy()
scores_np = scores.cpu().numpy().copy()
areas = []
for box in boxes_np:
x1, y1, x2, y2 = box
width = x2 - x1
height = y2 - y1
area = width * height
areas.append(area)
areas_np = np.array(areas)
sorted_indices = np.argsort(areas_np)[::-1]
boxes_sorted = boxes_np[sorted_indices]
scores_sorted = scores_np[sorted_indices]
areas_sorted = areas_np[sorted_indices]
masks_list = [masks[i] for i in range(len(masks))]
masks_sorted = [masks_list[i] for i in sorted_indices]
keep_indices = []
suppressed = set()
fused_masks = masks_sorted.copy()
for i in range(len(boxes_sorted)):
if i in suppressed:
continue
keep_indices.append(i)
current_mask = fused_masks[i]
for j in range(i + 1, len(boxes_sorted)):
if j in suppressed:
continue
iou = Ronghe_calculate_iou(boxes_sorted[i], boxes_sorted[j])
if iou > iou_threshold:
mask_overlap = calculate_mask_overlap(current_mask, masks_sorted[j])
suppressed.add(j)
fused_mask = fuse_two_masks(current_mask, masks_sorted[j])
fused_masks[i] = fused_mask
current_mask = fused_mask
print(f"融合检测结果: 索引 {sorted_indices[i]} (面积: {areas_sorted[i]:.1f}) 融合索引 {sorted_indices[j]} (面积: {areas_sorted[j]:.1f})",
" iou:", iou, " mask重叠:", mask_overlap)
else:
#print(f"IoU不足: 索引 {sorted_indices[i]} 和索引 {sorted_indices[j]}", " iou:", iou)
pass
final_indices = [sorted_indices[i] for i in keep_indices]
final_masks_list = [fused_masks[i] for i in keep_indices]
final_masks = torch.stack(final_masks_list)
final_boxes = boxes[final_indices]
final_scores = scores[final_indices]
print(f"融合后剩余 {len(final_masks)} 个分割结果 (减少了 {len(masks) - len(final_masks)} 个)")
return final_masks, final_boxes, final_scores
def fuse_two_masks(mask1, mask2):
"""将两个mask融合"""
fused_mask = torch.logical_or(mask1, mask2).float()
return fused_mask
def overlay_masks_with_tracking(image, masks, boxes, scores, track_ids, tracker, fusion_mode=False):
"""在图像上叠加掩码,并显示跟踪ID(使用tracker中的颜色)"""
image = image.convert("RGB")
draw = ImageDraw.Draw(image)
try:
font = ImageFont.truetype("SimHei.ttf", 60)
except:
try:
font = ImageFont.truetype("Arial.ttf", 60)
except:
font = ImageFont.load_default()
masks_np = masks.cpu().numpy().astype(np.uint8)
masks_np = masks_np.squeeze(1)
boxes_np = boxes.cpu().numpy()
scores_np = scores.cpu().numpy()
for i, (mask, box, score, track_id) in enumerate(zip(masks_np, boxes_np, scores_np, track_ids)):
# 从tracker获取该track_id对应的颜色
color = tracker.get_track_color(track_id)
if mask.ndim == 3:
mask = mask.squeeze(0)
alpha_mask = (mask * 128).astype(np.uint8)
overlay = Image.new("RGBA", image.size, color + (128,))
alpha = Image.fromarray(alpha_mask, mode='L')
overlay.putalpha(alpha)
image = Image.alpha_composite(image.convert("RGBA"), overlay).convert("RGB")
draw = ImageDraw.Draw(image)
x1, y1, x2, y2 = box
x1 = max(0, min(x1, image.width))
y1 = max(0, min(y1, image.height))
x2 = max(0, min(x2, image.width))
y2 = max(0, min(y2, image.height))
draw.rectangle([x1, y1, x2, y2], outline=color, width=3)
if fusion_mode:
text = f"Track:{track_id} Fused-ID:{i} Score:{score:.3f}"
else:
text = f"Track:{track_id} ID:{i} Score:{score:.3f}"
try:
left, top, right, bottom = draw.textbbox((0, 0), text, font=font)
text_width = right - left
text_height = bottom - top
except:
text_width, text_height = draw.textsize(text, font=font)
text_x = x1
text_y = max(0, y1 - text_height - 5)
draw.rectangle([text_x, text_y, text_x + text_width + 10, text_y + text_height + 5],
fill=color)
draw.text((text_x + 5, text_y + 2), text, fill="white", font=font)
return image
def extract_number_from_filename(filename):
"""从DJI_XXXX.JPG格式的文件名中提取数字"""
try:
# 匹配DJI_XXXX.JPG格式
if filename.startswith('DJI_') and filename.endswith(('.JPG', '.jpg', '.JPEG', '.jpeg')):
# 提取DJI_和扩展名之间的数字部分
number_part = filename[4:].split('.')[0]
return int(number_part)
except (ValueError, IndexError):
pass
return float('inf') # 如果不是DJI格式,返回无穷大,使其排在后面
def process_image_folder(processor, folder_path, output_dir="output"):
"""处理文件夹中的所有图像"""
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 获取图像文件
image_extensions = ['*.jpg', '*.jpeg', '*.png', '*.bmp', '*.tiff', '*.tif', '*.JPG', '*.JPEG', '*.PNG']
image_files = []
for ext in image_extensions:
image_files.extend(glob.glob(os.path.join(folder_path, ext)))
# 按照DJI_XXXX数字排序
image_files.sort(key=lambda x: extract_number_from_filename(os.path.basename(x)))
print(f"找到 {len(image_files)} 张图像")
# 初始化跟踪器
tracker = ObjectTracker(iou_threshold=0.3)
results = []
for i, image_path in enumerate(image_files):
print(f"\n{'='*50}")
print(f"处理第 {i+1}/{len(image_files)} 张图像: {os.path.basename(image_path)}")
try:
# 检测图像
masks, boxes, scores = Get_image_mask(processor, image_path)
if len(masks) == 0:
print("未检测到目标,跳过此图像")
# 及时释放变量
del masks, boxes, scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 融合重叠的mask
fused_masks, fused_boxes, fused_scores = fuse_overlapping_masks(
masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6
)
if len(fused_boxes) == 0:
print("融合后无目标,跳过此图像")
# 及时释放变量
del masks, boxes, scores, fused_masks, fused_boxes, fused_scores
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
continue
# 目标跟踪
fused_boxes_np = fused_boxes.cpu().numpy()
track_ids = tracker.update(fused_boxes_np, fused_scores.cpu().numpy())
# 保存结果
image_name = os.path.splitext(os.path.basename(image_path))[0]
save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, i, tracker)
results.append({
'image_path': image_path,
'image_name': image_name,
'track_ids': track_ids
})
except Exception as e:
print(f"处理图像 {image_path} 时出错: {e}")
finally:
# 强制清空变量并回收内存
variables_to_delete = ['masks', 'boxes', 'scores', 'fused_masks', 'fused_boxes', 'fused_scores', 'fused_boxes_np']
for var_name in variables_to_delete:
if var_name in locals():
del locals()[var_name]
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
print(f"内存清理完成,准备处理下一张图像")
return results
def save_results(image_path, masks, boxes, scores, fused_masks, fused_boxes,
fused_scores, track_ids, output_dir, image_name, image_index, tracker):
"""保存单张图像的结果"""
original_image = Image.open(image_path)
# 应用跟踪结果显示(传入tracker参数)
result_image_original = overlay_masks_with_tracking(
original_image, masks, boxes, scores,
list(range(len(masks))), tracker, fusion_mode=False
)
result_image_fused = overlay_masks_with_tracking(
original_image, fused_masks, fused_boxes, fused_scores,
track_ids, tracker, fusion_mode=True
)
# 创建并保存对比图像,并显示每一张
create_comparison_image(
result_image_original, result_image_fused,
len(masks), len(fused_masks), output_dir, image_name, image_index, tracker
)
# 及时释放图像变量
del original_image, result_image_original, result_image_fused
gc.collect()
def create_comparison_image(original_img, fused_img, n_original, n_fused, output_dir, image_name, image_index, tracker):
"""创建、保存并显示对比图像"""
# 创建图形
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
# 显示原始结果
ax1.imshow(original_img)
ax1.set_title(f"Original Result - {image_name}: {n_original} segments", fontsize=14)
ax1.axis('off')
# 显示融合后结果
ax2.imshow(fused_img)
ax2.set_title(f"Fused with Tracking - {image_name}: {n_fused} segments", fontsize=14)
ax2.axis('off')
plt.tight_layout()
# 保存对比图像
comparison_path = os.path.join(output_dir, f"segmentation_comparison_{image_name}.png")
plt.savefig(comparison_path, dpi=300, bbox_inches='tight', facecolor='white')
print(f"对比图像已保存: {comparison_path}")
# 显示图像(每张都显示,但限制数量避免卡顿)
if image_index < 3: # 只显示前3张
plt.show()
else:
plt.close(fig) # 关闭图形以释放内存
plt.close('all') # 关闭所有图形
def main():
"""主函数"""
# 1. 加载模型
processor = load_moad("sam3.pt")
# 2. 处理文件夹中的图像
folder_path = "/home/dongdong/2project/0data/RTK/data_4_city/300_map_2pm/images/"
output_dir = "output"
try:
results = process_image_folder(processor, folder_path, output_dir)
print(f"\n处理完成!共处理 {len(results)} 张图像")
print(f"结果保存在 {output_dir} 目录中")
finally:
# 最终清理
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
if __name__ == "__main__":
main()
例子2
检测画框,并且合并框,并且合并mask
按照框大小,然后融合重叠的框
没有合并mask前

合并后

没有合并mask前

合并后
没有合并mask前

合并后

import torch
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib.patches as patches
import time # 添加时间模块
import matplotlib
matplotlib.use('TkAgg') # Tkinter后端
import warnings
# 抑制所有相关的警告
warnings.filterwarnings("ignore", category=UserWarning, module="tkinter")
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore") # 抑制所有警告
#################################### For Image ####################################
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
'''
输入
1 模型地址
输出
1 识别器
'''
def load_moad(mode_path="sam3.pt"):
# 记录模型加载开始时间
model_load_start_time = time.time()
# Load the model
model = build_sam3_image_model(
checkpoint_path=mode_path
)
processor = Sam3Processor(model, confidence_threshold=0.5)
# 记录模型加载结束时间
model_load_end_time = time.time()
model_load_time = model_load_end_time - model_load_start_time
print(f"模型加载时间: {model_load_time:.3f} 秒")
return processor
'''
输入
1 模型识别器sam
2 照片名字
3 图像resize尺寸,默认原尺寸
输出
1 out 包含 mask box
'''
def Get_image_mask(processor,image_path):
# 记录单张检测开始时间
detection_start_time = time.time()
# Load an image
image = Image.open(image_path)
inference_state = processor.set_image(image)
# Prompt the model with text
output = processor.set_text_prompt(state=inference_state, prompt="building") #building,road and playground building car、people、bicycle
# Get the masks, bounding boxes, and scores
masks, boxes, scores = output["masks"], output["boxes"], output["scores"]
# 记录单张检测结束时间
detection_end_time = time.time()
detection_time = detection_end_time - detection_start_time
print(f"检测单张时间: {detection_time:.3f} 秒")
print(f"原始检测到 {len(masks)} 个分割结果")
print(f"掩码形状: {masks.shape}")
return masks, boxes, scores
'''
计算IOU重叠度
'''
def Api_calculate_iou(box1, box2):
"""计算两个边界框的IoU(交并比)"""
# 解包坐标
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
# 计算交集区域
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
# 计算交集面积
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
# 计算并集面积
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
# 避免除以零
if union_area == 0:
return 0.0
#iou_= inter_area / union_area
iou_2= inter_area / box2_area
iou_1= inter_area / box1_area
iou_=max(iou_2,iou_1)# 避免完全保卫战好不到的情况
return iou_
def calculate_mask_overlap(mask1, mask2):
"""计算两个掩码的重叠比例(基于mask1)"""
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
# 计算交集和mask1的面积
intersection = np.logical_and(mask1_np, mask2_np)
mask1_area = np.sum(mask1_np)
if mask1_area == 0:
return 0.0
overlap_ratio = np.sum(intersection) / mask1_area
return overlap_ratio
# 没用到 优先用IOU大的去融合小的
def fuse_overlapping_masks_use_scores(masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6):
"""
融合重叠的掩码和边界框
参数:
masks: 形状为 [N, 1, H, W] 的掩码张量
boxes: 形状为 [N, 4] 的边界框张量
scores: 形状为 [N] 的得分张量
iou_threshold: IoU阈值,用于判定边界框是否重叠
overlap_threshold: 掩码重叠阈值,用于判定是否融合
"""
# 应用融合函数
print("\n开始融合重叠的检测结果...")
fusion_start_time = time.time()
if len(masks) == 0:
return masks, boxes, scores
# 转换为numpy数组进行处理(使用copy()避免负步长问题)
boxes_np = boxes.cpu().numpy().copy()
scores_np = scores.cpu().numpy().copy()
# 按得分降序排序
# 降序索引
sorted_indices = np.argsort(scores_np)[::-1]
# 根据索引重新调整顺序
boxes_sorted = boxes_np[sorted_indices]
scores_sorted = scores_np[sorted_indices]
# 处理masks:先转换为列表,然后按排序索引重新组织
masks_list = [masks[i] for i in range(len(masks))]
# 根据索引重新调整顺序
masks_sorted = [masks_list[i] for i in sorted_indices]
# 初始化保留索引
keep_indices = []
suppressed = set()
for i in range(len(boxes_sorted)):
print('=====================',i)
if i in suppressed:
print('1 跳过',i)
continue
keep_indices.append(i)
for j in range(i + 1, len(boxes_sorted)):
if j in suppressed:
print('2 跳过',i)
continue
# 计算IoU
iou = Api_calculate_iou(boxes_sorted[i], boxes_sorted[j])
if iou > iou_threshold:
# 计算掩码重叠比例
#overlap_ratio = calculate_mask_overlap(masks_sorted[i], masks_sorted[j])
#if overlap_ratio > overlap_threshold:
suppressed.add(j)
print(f"融合检测结果: 索引 {sorted_indices[i]} (得分: {scores_sorted[i]:.3f}) 覆盖索引 {sorted_indices[j]} (得分: {scores_sorted[j]:.3f})"," iou:",iou)
#print(f" - IoU: {iou:.3f}, 掩码重叠比例: {overlap_ratio:.3f}")
else:
#keep_indices.append(i)
print(f"xxxxxx融合检测结果: 索引 {sorted_indices[i]} (得分: {scores_sorted[i]:.3f}) 覆盖索引 {sorted_indices[j]} (得分: {scores_sorted[j]:.3f})"," iou:",iou)
# 获取保留的检测结果
final_indices = [sorted_indices[i] for i in keep_indices]
# 使用PyTorch的索引操作来获取最终结果
final_masks = torch.stack([masks_list[i] for i in final_indices])
final_boxes = boxes[final_indices]
final_scores = scores[final_indices]
print(f"融合后剩余 {len(final_masks)} 个分割结果 (减少了 {len(masks) - len(final_masks)} 个)")
fusion_time = time.time() - fusion_start_time
print(f"融合完成时间: {fusion_time:.3f} 秒")
return final_masks, final_boxes, final_scores
def fuse_overlapping_masks_justIou(masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6):
"""
融合重叠的掩码和边界框
参数:
masks: 形状为 [N, 1, H, W] 的掩码张量
boxes: 形状为 [N, 4] 的边界框张量
scores: 形状为 [N] 的得分张量
iou_threshold: IoU阈值,用于判定边界框是否重叠
overlap_threshold: 掩码重叠阈值,用于判定是否融合
"""
if len(masks) == 0:
return masks, boxes, scores
# 转换为numpy数组进行处理(使用copy()避免负步长问题)
boxes_np = boxes.cpu().numpy().copy()
scores_np = scores.cpu().numpy().copy()
# 计算每个边界框的面积 (w * h)
areas = []
for box in boxes_np:
x1, y1, x2, y2 = box
width = x2 - x1
height = y2 - y1
area = width * height
areas.append(area)
areas_np = np.array(areas)
# 按面积降序排序(面积大的优先)
sorted_indices = np.argsort(areas_np)[::-1]
# 根据索引重新调整顺序
boxes_sorted = boxes_np[sorted_indices]
scores_sorted = scores_np[sorted_indices]
areas_sorted = areas_np[sorted_indices]
# 处理masks:先转换为列表,然后按排序索引重新组织
masks_list = [masks[i] for i in range(len(masks))]
# 根据索引重新调整顺序
masks_sorted = [masks_list[i] for i in sorted_indices]
# 初始化保留索引
keep_indices = []
suppressed = set()
for i in range(len(boxes_sorted)):
print('=====================', i)
if i in suppressed:
print('1 跳过', i)
continue
keep_indices.append(i)
for j in range(i + 1, len(boxes_sorted)):
if j in suppressed:
print('2 跳过', j)
continue
# 计算IoU
iou = Api_calculate_iou(boxes_sorted[i], boxes_sorted[j])
if iou > iou_threshold:
# 计算掩码重叠比例
# overlap_ratio = calculate_mask_overlap(masks_sorted[i], masks_sorted[j])
# if overlap_ratio > overlap_threshold:
suppressed.add(j)
print(f"融合检测结果: 索引 {sorted_indices[i]} (面积: {areas_sorted[i]:.1f}) 覆盖索引 {sorted_indices[j]} (面积: {areas_sorted[j]:.1f})", " iou:", iou)
# print(f" - IoU: {iou:.3f}, 掩码重叠比例: {overlap_ratio:.3f}")
else:
print(f"xxxxxx未融合: 索引 {sorted_indices[i]} (面积: {areas_sorted[i]:.1f}) 和索引 {sorted_indices[j]} (面积: {areas_sorted[j]:.1f})", " iou:", iou)
# 获取保留的检测结果
final_indices = [sorted_indices[i] for i in keep_indices]
# 使用PyTorch的索引操作来获取最终结果
final_masks = torch.stack([masks_list[i] for i in final_indices])
final_boxes = boxes[final_indices]
final_scores = scores[final_indices]
print(f"融合后剩余 {len(final_masks)} 个分割结果 (减少了 {len(masks) - len(final_masks)} 个)")
return final_masks, final_boxes, final_scores
def fuse_overlapping_masks(masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6):
"""
融合重叠的掩码和边界框
参数:
masks: 形状为 [N, 1, H, W] 的掩码张量
boxes: 形状为 [N, 4] 的边界框张量
scores: 形状为 [N] 的得分张量
iou_threshold: IoU阈值,用于判定边界框是否重叠
overlap_threshold: 掩码重叠阈值,用于判定是否融合
"""
if len(masks) == 0:
return masks, boxes, scores
# 转换为numpy数组进行处理(使用copy()避免负步长问题)
boxes_np = boxes.cpu().numpy().copy()
scores_np = scores.cpu().numpy().copy()
# 计算每个边界框的面积 (w * h)
areas = []
for box in boxes_np:
x1, y1, x2, y2 = box
width = x2 - x1
height = y2 - y1
area = width * height
areas.append(area)
areas_np = np.array(areas)
# 按面积降序排序(面积大的优先)
sorted_indices = np.argsort(areas_np)[::-1]
# 根据索引重新调整顺序
boxes_sorted = boxes_np[sorted_indices]
scores_sorted = scores_np[sorted_indices]
areas_sorted = areas_np[sorted_indices]
# 处理masks:先转换为列表,然后按排序索引重新组织
masks_list = [masks[i] for i in range(len(masks))]
# 根据索引重新调整顺序
masks_sorted = [masks_list[i] for i in sorted_indices]
# 初始化保留索引和融合后的masks
keep_indices = []
suppressed = set()
fused_masks = masks_sorted.copy() # 用于存储融合后的masks
for i in range(len(boxes_sorted)):
print('=====================', i)
if i in suppressed:
print('1 跳过', i)
continue
keep_indices.append(i)
current_mask = fused_masks[i] # 当前要融合的大mask
for j in range(i + 1, len(boxes_sorted)):
if j in suppressed:
print('2 跳过', j)
continue
# 计算IoU
iou = Api_calculate_iou(boxes_sorted[i], boxes_sorted[j])
if iou > iou_threshold:
# 计算掩码重叠比例
mask_overlap = calculate_mask_overlap(current_mask, masks_sorted[j])
suppressed.add(j)
# 将小mask合并到大mask上
fused_mask = fuse_two_masks(current_mask, masks_sorted[j])
fused_masks[i] = fused_mask
current_mask = fused_mask # 更新当前mask
print(f"融合检测结果: 索引 {sorted_indices[i]} (面积: {areas_sorted[i]:.1f}) 融合索引 {sorted_indices[j]} (面积: {areas_sorted[j]:.1f})",
" iou:", iou, " mask重叠:", mask_overlap)
# if mask_overlap > overlap_threshold:
# suppressed.add(j)
# # 将小mask合并到大mask上
# fused_mask = fuse_two_masks(current_mask, masks_sorted[j])
# fused_masks[i] = fused_mask
# current_mask = fused_mask # 更新当前mask
# print(f"融合检测结果: 索引 {sorted_indices[i]} (面积: {areas_sorted[i]:.1f}) 融合索引 {sorted_indices[j]} (面积: {areas_sorted[j]:.1f})",
# " iou:", iou, " mask重叠:", mask_overlap)
# else:
# print(f"mask重叠不足: 索引 {sorted_indices[i]} 和索引 {sorted_indices[j]}",
# " iou:", iou, " mask重叠:", mask_overlap)
else:
print(f"IoU不足: 索引 {sorted_indices[i]} 和索引 {sorted_indices[j]}",
" iou:", iou)
# 获取保留的检测结果(使用融合后的masks)
final_indices = [sorted_indices[i] for i in keep_indices]
final_masks_list = [fused_masks[i] for i in keep_indices]
# 使用PyTorch的索引操作来获取最终结果
final_masks = torch.stack(final_masks_list)
final_boxes = boxes[final_indices]
final_scores = scores[final_indices]
print(f"融合后剩余 {len(final_masks)} 个分割结果 (减少了 {len(masks) - len(final_masks)} 个)")
return final_masks, final_boxes, final_scores
def fuse_two_masks(mask1, mask2):
"""
将两个mask融合(取并集)
参数:
mask1: 第一个mask张量 [1, H, W]
mask2: 第二个mask张量 [1, H, W]
返回:
融合后的mask张量 [1, H, W]
"""
# 使用逻辑或操作合并两个mask
fused_mask = torch.logical_or(mask1, mask2).float()
return fused_mask
def overlay_masks_with_info(image, masks, boxes, scores, fusion_mode=False):
"""
在图像上叠加掩码,并添加ID、得分和矩形框
masks: 形状为 [N, 1, H, W] 的四维张量
boxes: 形状为 [N, 4] 的边界框张量 [x1, y1, x2, y2]
scores: 形状为 [N] 的得分张量
fusion_mode: 是否为融合后的模式(使用不同颜色)
"""
# 转换为RGB模式以便绘制
image = image.convert("RGB")
draw = ImageDraw.Draw(image)
# 尝试加载字体,如果失败则使用默认字体
try:
# 尝试使用系统中文字体
font = ImageFont.truetype("SimHei.ttf", 20)
except:
try:
font = ImageFont.truetype("Arial.ttf", 20)
except:
font = ImageFont.load_default()
# 将掩码转换为numpy数组并去除通道维度
masks_np = masks.cpu().numpy().astype(np.uint8) # 形状: [N, 1, H, W]
masks_np = masks_np.squeeze(1) # 移除通道维度,形状: [N, H, W]
boxes_np = boxes.cpu().numpy() # 形状: [N, 4]
scores_np = scores.cpu().numpy() # 形状: [N]
n_masks = masks_np.shape[0]
# 根据是否为融合模式选择不同的颜色映射
if fusion_mode:
cmap = plt.cm.get_cmap("viridis", n_masks) # 融合模式使用viridis配色
else:
cmap = plt.cm.get_cmap("rainbow", n_masks) # 原始模式使用rainbow配色
for i, (mask, box, score) in enumerate(zip(masks_np, boxes_np, scores_np)):
# 获取颜色
color = tuple(int(c * 255) for c in cmap(i)[:3])
# 确保掩码是二维的
if mask.ndim == 3:
mask = mask.squeeze(0)
# 创建透明度掩码
alpha_mask = (mask * 128).astype(np.uint8) # 0.5透明度
# 创建彩色覆盖层
overlay = Image.new("RGBA", image.size, color + (128,))
# 应用alpha通道
alpha = Image.fromarray(alpha_mask, mode='L')
overlay.putalpha(alpha)
# 叠加到图像上
image = Image.alpha_composite(image.convert("RGBA"), overlay).convert("RGB")
draw = ImageDraw.Draw(image)
# 绘制边界框
x1, y1, x2, y2 = box
# 确保坐标在图像范围内
x1 = max(0, min(x1, image.width))
y1 = max(0, min(y1, image.height))
x2 = max(0, min(x2, image.width))
y2 = max(0, min(y2, image.height))
# 绘制矩形框
draw.rectangle([x1, y1, x2, y2], outline=color, width=3)
# 准备文本信息
if fusion_mode:
text = f"Fused-ID:{i} Score:{score:.3f}"
else:
text = f"ID:{i} Score:{score:.3f}"
# 计算文本位置(在框的上方)
try:
# 新版本的PIL
left, top, right, bottom = draw.textbbox((0, 0), text, font=font)
text_width = right - left
text_height = bottom - top
except:
# 旧版本的PIL
text_width, text_height = draw.textsize(text, font=font)
text_x = x1
text_y = max(0, y1 - text_height - 5)
# 绘制文本背景
draw.rectangle([text_x, text_y, text_x + text_width + 10, text_y + text_height + 5],
fill=color)
# 绘制文本
draw.text((text_x + 5, text_y + 2), text, fill="white", font=font)
return image
def save_mask(masks_to_save, boxes_to_save, scores_to_save, prefix="mask"):
"""保存单个掩码的通用函数"""
print(f"\n保存{prefix}的单个掩码...")
for i, (mask, box, score) in enumerate(zip(masks_to_save, boxes_to_save, scores_to_save)):
# 创建单个掩码的可视化
base_image = Image.open(image_path).convert("RGB")
single_draw = ImageDraw.Draw(base_image)
# 尝试加载字体
try:
single_font = ImageFont.truetype("SimHei.ttf", 24)
except:
try:
single_font = ImageFont.truetype("Arial.ttf", 24)
except:
single_font = ImageFont.load_default()
# 处理掩码
mask_np = mask.cpu().numpy().squeeze().astype(np.uint8)
color = tuple(int(c * 255) for c in plt.cm.get_cmap("viridis", len(masks_to_save))(i)[:3])
# 创建透明度掩码
alpha_mask = (mask_np * 128).astype(np.uint8)
overlay = Image.new("RGBA", base_image.size, color + (128,))
alpha = Image.fromarray(alpha_mask, mode='L')
overlay.putalpha(alpha)
base_image = Image.alpha_composite(base_image.convert("RGBA"), overlay).convert("RGB")
single_draw = ImageDraw.Draw(base_image)
# 绘制边界框和文本
x1, y1, x2, y2 = box.cpu().numpy()
single_draw.rectangle([x1, y1, x2, y2], outline=color, width=3)
text = f"ID:{i} Score:{score:.3f}"
try:
# 新版本的PIL
left, top, right, bottom = single_draw.textbbox((0, 0), text, font=single_font)
text_width = right - left
text_height = bottom - top
except:
# 旧版本的PIL
text_width, text_height = single_draw.textsize(text, font=single_font)
text_x = x1
text_y = max(0, y1 - text_height - 5)
single_draw.rectangle([text_x, text_y, text_x + text_width + 10, text_y + text_height + 5],
fill=color)
single_draw.text((text_x + 5, text_y + 2), text, fill="white", font=single_font)
base_image.save(f"{prefix}_with_info_{i:02d}.png")
print(f"保存{prefix} {i:02d}.png (得分: {score:.3f})")
# # 保存原始和融合后的单个掩码
# save_mask(masks, boxes, scores, "original_mask")
# save_mask(fused_masks, fused_boxes, fused_scores, "fused_mask")
# 4 可视化
def Show_result(show_flag,save_flag):
if show_flag:
# 应用掩码叠加(原始结果)
original_image = Image.open(image_path)
result_image_original = overlay_masks_with_info(original_image, masks, boxes, scores, fusion_mode=False)
# 应用掩码叠加(融合后结果)
result_image_fused = overlay_masks_with_info(original_image, fused_masks, fused_boxes, fused_scores, fusion_mode=True)
# 设置中文字体或使用英文避免警告
try:
# 尝试设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
except:
pass
# 显示对比图像
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
# 原始结果
ax1.imshow(result_image_original)
ax1.set_title(f"原始结果: 检测到 {len(masks)} 个分割结果", fontsize=14)
ax1.axis('off')
# 融合后结果
ax2.imshow(result_image_fused)
ax2.set_title(f"融合后结果: 剩余 {len(fused_masks)} 个分割结果", fontsize=14)
ax2.axis('off')
plt.tight_layout()
plt.savefig("segmentation_comparison.png", bbox_inches='tight', dpi=300, facecolor='white')
plt.show()
if save_flag:
# 保存结果图像
output_path_original = "segmentation_result_original.png"
output_path_fused = "segmentation_result_fused.png"
result_image_original.save(output_path_original)
result_image_fused.save(output_path_fused)
print(f"原始分割结果已保存到: {output_path_original}")
print(f"融合后分割结果已保存到: {output_path_fused}")
# 1 加载模型
processor=load_moad("sam3.pt")
# 2 输入图像 检测mask
path_="/home/dongdong/2project/0data/RTK/data_4_city/300_map_2pm/images/"
image_path = path_+"DJI_0060.JPG"
masks, boxes, scores = Get_image_mask(processor,image_path)
# 3 应用融合函数 融合mask
fused_masks, fused_boxes, fused_scores = fuse_overlapping_masks(
masks, boxes, scores,
iou_threshold=0.5, # 可以调整这个阈值
overlap_threshold=0.6 # 可以调整这个阈值
)
# 可视化和保存结果
Show_result(1,1)
print("所有处理完成!")
例子1
检测画框,并且合并
按照分数排序,然后融合重叠的框
缺点 丢失框



import torch
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib.patches as patches
import time # 添加时间模块
#################################### For Image ####################################
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
# 记录总开始时间
total_start_time = time.time()
# 记录模型加载开始时间
model_load_start_time = time.time()
# Load the model
model = build_sam3_image_model(
checkpoint_path="/home/r9000k/v2_project/sam/sam3/assets/model/sam3.pt"
)
processor = Sam3Processor(model, confidence_threshold=0.5)
# 记录模型加载结束时间
model_load_end_time = time.time()
model_load_time = model_load_end_time - model_load_start_time
print(f"模型加载时间: {model_load_time:.3f} 秒")
# 记录单张检测开始时间
detection_start_time = time.time()
image_path = "testimage/微信图片_20251120225838_38.jpg"
image_path = "3.jpg"
# Load an image
image = Image.open(image_path)
inference_state = processor.set_image(image)
# Prompt the model with text
output = processor.set_text_prompt(state=inference_state, prompt="building") #building,road and playground building car、people、bicycle
# Get the masks, bounding boxes, and scores
masks, boxes, scores = output["masks"], output["boxes"], output["scores"]
# 记录单张检测结束时间
detection_end_time = time.time()
detection_time = detection_end_time - detection_start_time
print(f"检测单张时间: {detection_time:.3f} 秒")
print(f"原始检测到 {len(masks)} 个分割结果")
print(f"掩码形状: {masks.shape}")
def calculate_iou(box1, box2):
"""计算两个边界框的IoU(交并比)"""
# 解包坐标
x1_1, y1_1, x1_2, y1_2 = box1
x2_1, y2_1, x2_2, y2_2 = box2
# 计算交集区域
xi1 = max(x1_1, x2_1)
yi1 = max(y1_1, y2_1)
xi2 = min(x1_2, x2_2)
yi2 = min(y1_2, y2_2)
# 计算交集面积
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
# 计算并集面积
box1_area = (x1_2 - x1_1) * (y1_2 - y1_1)
box2_area = (x2_2 - x2_1) * (y2_2 - y2_1)
union_area = box1_area + box2_area - inter_area
# 避免除以零
if union_area == 0:
return 0.0
#iou_= inter_area / union_area
iou_2= inter_area / box2_area
iou_1= inter_area / box1_area
iou_=max(iou_2,iou_1)
return iou_
def calculate_mask_overlap(mask1, mask2):
"""计算两个掩码的重叠比例(基于mask1)"""
mask1_np = mask1.cpu().numpy().squeeze().astype(bool)
mask2_np = mask2.cpu().numpy().squeeze().astype(bool)
# 计算交集和mask1的面积
intersection = np.logical_and(mask1_np, mask2_np)
mask1_area = np.sum(mask1_np)
if mask1_area == 0:
return 0.0
overlap_ratio = np.sum(intersection) / mask1_area
return overlap_ratio
def fuse_overlapping_masks(masks, boxes, scores, iou_threshold=0.5, overlap_threshold=0.6):
"""
融合重叠的掩码和边界框
参数:
masks: 形状为 [N, 1, H, W] 的掩码张量
boxes: 形状为 [N, 4] 的边界框张量
scores: 形状为 [N] 的得分张量
iou_threshold: IoU阈值,用于判定边界框是否重叠
overlap_threshold: 掩码重叠阈值,用于判定是否融合
"""
if len(masks) == 0:
return masks, boxes, scores
# 转换为numpy数组进行处理(使用copy()避免负步长问题)
boxes_np = boxes.cpu().numpy().copy()
scores_np = scores.cpu().numpy().copy()
# 按得分降序排序
# 降序索引
sorted_indices = np.argsort(scores_np)[::-1]
# 根据索引重新调整顺序
boxes_sorted = boxes_np[sorted_indices]
scores_sorted = scores_np[sorted_indices]
# 处理masks:先转换为列表,然后按排序索引重新组织
masks_list = [masks[i] for i in range(len(masks))]
# 根据索引重新调整顺序
masks_sorted = [masks_list[i] for i in sorted_indices]
# 初始化保留索引
keep_indices = []
suppressed = set()
for i in range(len(boxes_sorted)):
print('=====================',i)
if i in suppressed:
print('1 跳过',i)
continue
keep_indices.append(i)
for j in range(i + 1, len(boxes_sorted)):
if j in suppressed:
print('2 跳过',i)
continue
# 计算IoU
iou = calculate_iou(boxes_sorted[i], boxes_sorted[j])
if iou > iou_threshold:
# 计算掩码重叠比例
#overlap_ratio = calculate_mask_overlap(masks_sorted[i], masks_sorted[j])
#if overlap_ratio > overlap_threshold:
suppressed.add(j)
print(f"融合检测结果: 索引 {sorted_indices[i]} (得分: {scores_sorted[i]:.3f}) 覆盖索引 {sorted_indices[j]} (得分: {scores_sorted[j]:.3f})"," iou:",iou)
#print(f" - IoU: {iou:.3f}, 掩码重叠比例: {overlap_ratio:.3f}")
else:
#keep_indices.append(i)
print(f"xxxxxx融合检测结果: 索引 {sorted_indices[i]} (得分: {scores_sorted[i]:.3f}) 覆盖索引 {sorted_indices[j]} (得分: {scores_sorted[j]:.3f})"," iou:",iou)
# 获取保留的检测结果
final_indices = [sorted_indices[i] for i in keep_indices]
# 使用PyTorch的索引操作来获取最终结果
final_masks = torch.stack([masks_list[i] for i in final_indices])
final_boxes = boxes[final_indices]
final_scores = scores[final_indices]
print(f"融合后剩余 {len(final_masks)} 个分割结果 (减少了 {len(masks) - len(final_masks)} 个)")
return final_masks, final_boxes, final_scores
# 应用融合函数
print("\n开始融合重叠的检测结果...")
fusion_start_time = time.time()
# 调用融合函数
fused_masks, fused_boxes, fused_scores = fuse_overlapping_masks(
masks, boxes, scores,
iou_threshold=0.5, # 可以调整这个阈值
overlap_threshold=0.6 # 可以调整这个阈值
)
fusion_time = time.time() - fusion_start_time
print(f"融合完成时间: {fusion_time:.3f} 秒")
def overlay_masks_with_info(image, masks, boxes, scores, fusion_mode=False):
"""
在图像上叠加掩码,并添加ID、得分和矩形框
masks: 形状为 [N, 1, H, W] 的四维张量
boxes: 形状为 [N, 4] 的边界框张量 [x1, y1, x2, y2]
scores: 形状为 [N] 的得分张量
fusion_mode: 是否为融合后的模式(使用不同颜色)
"""
# 转换为RGB模式以便绘制
image = image.convert("RGB")
draw = ImageDraw.Draw(image)
# 尝试加载字体,如果失败则使用默认字体
try:
# 尝试使用系统中文字体
font = ImageFont.truetype("SimHei.ttf", 20)
except:
try:
font = ImageFont.truetype("Arial.ttf", 20)
except:
font = ImageFont.load_default()
# 将掩码转换为numpy数组并去除通道维度
masks_np = masks.cpu().numpy().astype(np.uint8) # 形状: [N, 1, H, W]
masks_np = masks_np.squeeze(1) # 移除通道维度,形状: [N, H, W]
boxes_np = boxes.cpu().numpy() # 形状: [N, 4]
scores_np = scores.cpu().numpy() # 形状: [N]
n_masks = masks_np.shape[0]
# 根据是否为融合模式选择不同的颜色映射
if fusion_mode:
cmap = plt.cm.get_cmap("viridis", n_masks) # 融合模式使用viridis配色
else:
cmap = plt.cm.get_cmap("rainbow", n_masks) # 原始模式使用rainbow配色
for i, (mask, box, score) in enumerate(zip(masks_np, boxes_np, scores_np)):
# 获取颜色
color = tuple(int(c * 255) for c in cmap(i)[:3])
# 确保掩码是二维的
if mask.ndim == 3:
mask = mask.squeeze(0)
# 创建透明度掩码
alpha_mask = (mask * 128).astype(np.uint8) # 0.5透明度
# 创建彩色覆盖层
overlay = Image.new("RGBA", image.size, color + (128,))
# 应用alpha通道
alpha = Image.fromarray(alpha_mask, mode='L')
overlay.putalpha(alpha)
# 叠加到图像上
image = Image.alpha_composite(image.convert("RGBA"), overlay).convert("RGB")
draw = ImageDraw.Draw(image)
# 绘制边界框
x1, y1, x2, y2 = box
# 确保坐标在图像范围内
x1 = max(0, min(x1, image.width))
y1 = max(0, min(y1, image.height))
x2 = max(0, min(x2, image.width))
y2 = max(0, min(y2, image.height))
# 绘制矩形框
draw.rectangle([x1, y1, x2, y2], outline=color, width=3)
# 准备文本信息
if fusion_mode:
text = f"Fused-ID:{i} Score:{score:.3f}"
else:
text = f"ID:{i} Score:{score:.3f}"
# 计算文本位置(在框的上方)
try:
# 新版本的PIL
left, top, right, bottom = draw.textbbox((0, 0), text, font=font)
text_width = right - left
text_height = bottom - top
except:
# 旧版本的PIL
text_width, text_height = draw.textsize(text, font=font)
text_x = x1
text_y = max(0, y1 - text_height - 5)
# 绘制文本背景
draw.rectangle([text_x, text_y, text_x + text_width + 10, text_y + text_height + 5],
fill=color)
# 绘制文本
draw.text((text_x + 5, text_y + 2), text, fill="white", font=font)
return image
# 记录可视化开始时间
visualization_start_time = time.time()
# 应用掩码叠加(原始结果)
original_image = Image.open(image_path)
result_image_original = overlay_masks_with_info(original_image, masks, boxes, scores, fusion_mode=False)
# 应用掩码叠加(融合后结果)
result_image_fused = overlay_masks_with_info(original_image, fused_masks, fused_boxes, fused_scores, fusion_mode=True)
# 保存结果图像
output_path_original = "segmentation_result_original.png"
output_path_fused = "segmentation_result_fused.png"
result_image_original.save(output_path_original)
result_image_fused.save(output_path_fused)
# 记录可视化结束时间
visualization_end_time = time.time()
visualization_time = visualization_end_time - visualization_start_time
print(f"可视化时间: {visualization_time:.3f} 秒")
print(f"原始分割结果已保存到: {output_path_original}")
print(f"融合后分割结果已保存到: {output_path_fused}")
# 设置中文字体或使用英文避免警告
try:
# 尝试设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
except:
pass
# 显示对比图像
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
# 原始结果
ax1.imshow(result_image_original)
ax1.set_title(f"原始结果: 检测到 {len(masks)} 个分割结果", fontsize=14)
ax1.axis('off')
# 融合后结果
ax2.imshow(result_image_fused)
ax2.set_title(f"融合后结果: 剩余 {len(fused_masks)} 个分割结果", fontsize=14)
ax2.axis('off')
plt.tight_layout()
plt.savefig("segmentation_comparison.png", bbox_inches='tight', dpi=300, facecolor='white')
plt.show()
# 记录总结束时间
total_end_time = time.time()
total_time = total_end_time - total_start_time
# 打印详细的时间统计
print("\n" + "="*50)
print("运行时间统计:")
print("="*50)
print(f"模型加载时间: {model_load_time:.3f} 秒")
print(f"检测单张时间: {detection_time:.3f} 秒")
print(f"融合处理时间: {fusion_time:.3f} 秒")
print(f"可视化时间: {visualization_time:.3f} 秒")
print("-"*50)
print(f"总运行时间: {total_time:.3f} 秒")
print("="*50)
def save_mask(masks_to_save, boxes_to_save, scores_to_save, prefix="mask"):
"""保存单个掩码的通用函数"""
print(f"\n保存{prefix}的单个掩码...")
for i, (mask, box, score) in enumerate(zip(masks_to_save, boxes_to_save, scores_to_save)):
# 创建单个掩码的可视化
base_image = Image.open(image_path).convert("RGB")
single_draw = ImageDraw.Draw(base_image)
# 尝试加载字体
try:
single_font = ImageFont.truetype("SimHei.ttf", 24)
except:
try:
single_font = ImageFont.truetype("Arial.ttf", 24)
except:
single_font = ImageFont.load_default()
# 处理掩码
mask_np = mask.cpu().numpy().squeeze().astype(np.uint8)
color = tuple(int(c * 255) for c in plt.cm.get_cmap("viridis", len(masks_to_save))(i)[:3])
# 创建透明度掩码
alpha_mask = (mask_np * 128).astype(np.uint8)
overlay = Image.new("RGBA", base_image.size, color + (128,))
alpha = Image.fromarray(alpha_mask, mode='L')
overlay.putalpha(alpha)
base_image = Image.alpha_composite(base_image.convert("RGBA"), overlay).convert("RGB")
single_draw = ImageDraw.Draw(base_image)
# 绘制边界框和文本
x1, y1, x2, y2 = box.cpu().numpy()
single_draw.rectangle([x1, y1, x2, y2], outline=color, width=3)
text = f"ID:{i} Score:{score:.3f}"
try:
# 新版本的PIL
left, top, right, bottom = single_draw.textbbox((0, 0), text, font=single_font)
text_width = right - left
text_height = bottom - top
except:
# 旧版本的PIL
text_width, text_height = single_draw.textsize(text, font=single_font)
text_x = x1
text_y = max(0, y1 - text_height - 5)
single_draw.rectangle([text_x, text_y, text_x + text_width + 10, text_y + text_height + 5],
fill=color)
single_draw.text((text_x + 5, text_y + 2), text, fill="white", font=single_font)
base_image.save(f"{prefix}_with_info_{i:02d}.png")
print(f"保存{prefix} {i:02d}.png (得分: {score:.3f})")
# # 保存原始和融合后的单个掩码
# save_mask(masks, boxes, scores, "original_mask")
# save_mask(fused_masks, fused_boxes, fused_scores, "fused_mask")
print("所有处理完成!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号