

ConceptGraphs: Open-vocabulary 3D scene graphs for perception and planning,
好的,ConceptGraphs 这篇论文与之前讨论的 HOV-SG 思想一脉相承,但它在具体实现方法和侧重点上有所不同,可以看作是在同一前沿方向上的一种具体、可扩展的实现方案。其核心思想是:一种无需对象检测模型训练、无需文本标注、完全基于开放词汇模型(如 CLIP)的“自下而上”的方法,来构建开放词汇的3D场景图,并直接用于机器人感知与规划。
一、核心思想:一种“自下而上”的开放词汇建图方法
与一些需要预训练物体检测器或大量人工标注的方法不同,ConceptGraphs 的核心创新在于其极其简单和通用的构建流程。它的目标不是识别出“椅子”、“桌子”这类预定义的物体,而是让3D地图中的任何一点都能用任意语言概念(开放词汇)来查询。
关键区别:对象识别 vs. 概念查询
- 传统对象识别方法:“这是一个椅子吗?”(需要预先知道“椅子”这个类别并训练过)。
- ConceptGraphs 的方法:“地图中哪个区域最符合‘我用来放杯子的东西’这个描述?”(无需预训练,直接使用语言模型的理解能力)。
二、工作流程:如何构建ConceptGraph?
其流程非常清晰,分为三个核心步骤,下图展示了从原始数据到可用于规划的概念图的完整过程:
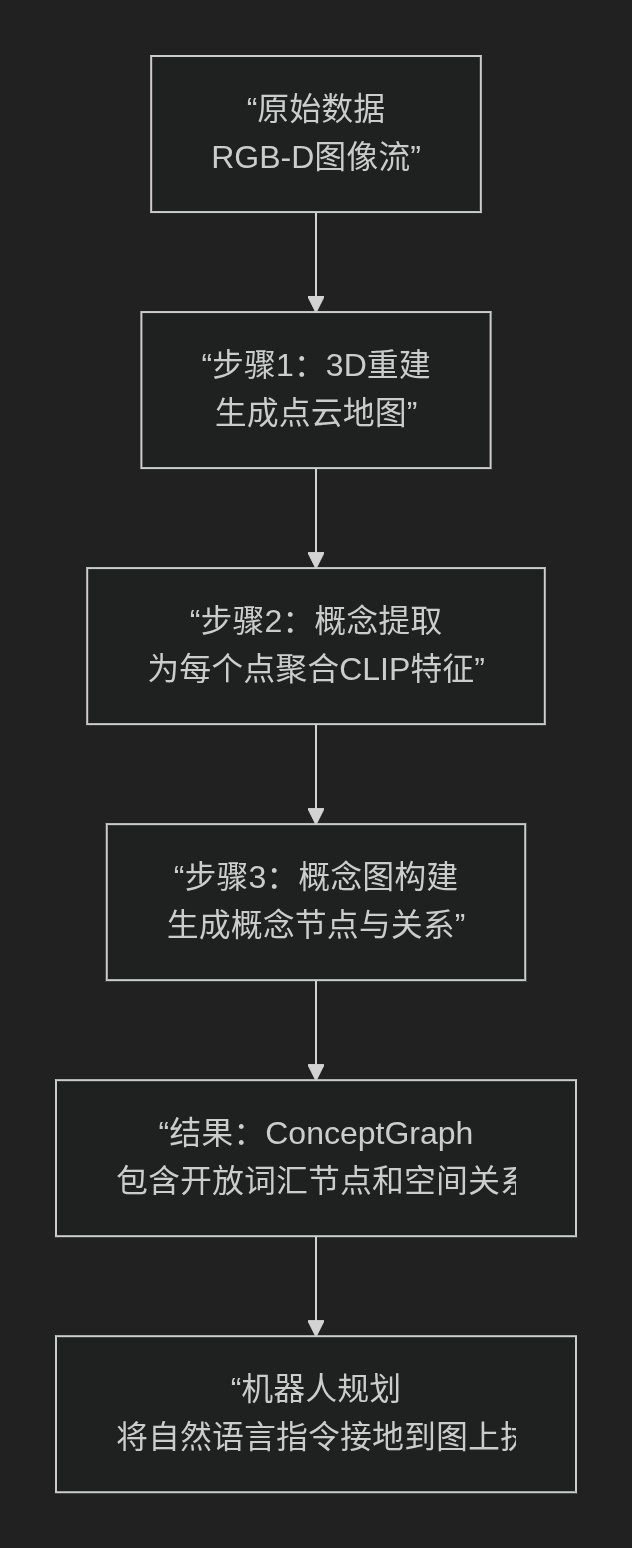
步骤一:3D重建
- 使用现成的SLAM系统(如VDB-Fusion)处理RGB-D图像流,生成一个稠密3D点云地图。每个点不仅有3D坐标和颜色,还有一个关键属性:它出现在哪些原始图像帧中。
步骤二:概念提取——核心创新
这是最关键的一步,实现了“开放词汇”能力。
- 点与图像的关联:对于点云中的每一个3D点,系统可以找到所有观察到它的2D图像区域(patches)。
- CLIP特征聚合:将这些2D图像区域输入到预训练的CLIP模型的图像编码器中,为每个图像区域提取一个高维特征向量。
- 然后,将所有与此3D点关联的图像区域特征进行聚合(例如,取平均),得到一个单一的、强大的CLIP特征向量,并赋予这个3D点。
- 结果:至此,地图中的每一个3D点都携带了一个语义嵌入向量。这个向量位于CLIP模型创造的语义空间中,与文本嵌入向量可以直接比较。
步骤三:概念图构建
- 节点生成:使用几何分割算法(如欧几里得聚类)将点云分组为不同的物体实例。每个实例(即一组点)的CLIP特征是其所有点特征的聚合。这样,每个实例成为一个概念节点,拥有几何属性和语义特征。
- 关系生成:计算节点之间的空间关系(如“在上面”、“在旁边”、“包含”),形成图的边。
- 最终产出:一个开放词汇的3D场景图。图中的每个节点都可以用任意语言概念通过计算相似度来查询。
三、在机器人感知与规划中的应用
当机器人收到自然语言指令后,它利用ConceptGraph进行推理和规划的过程可以清晰地表示为以下流程:

好的,ConceptGraphs 这篇论文与之前讨论的 HOV-SG 思想一脉相承,但它在具体实现方法和侧重点上有所不同,可以看作是在同一前沿方向上的一种具体、可扩展的实现方案。其核心思想是:一种无需对象检测模型训练、无需文本标注、完全基于开放词汇模型(如 CLIP)的“自下而上”的方法,来构建开放词汇的3D场景图,并直接用于机器人感知与规划。
一、核心思想:一种“自下而上”的开放词汇建图方法
与一些需要预训练物体检测器或大量人工标注的方法不同,ConceptGraphs 的核心创新在于其极其简单和通用的构建流程。它的目标不是识别出“椅子”、“桌子”这类预定义的物体,而是让3D地图中的任何一点都能用任意语言概念(开放词汇)来查询。
关键区别:对象识别 vs. 概念查询
- 传统对象识别方法:“这是一个椅子吗?”(需要预先知道“椅子”这个类别并训练过)。
- ConceptGraphs 的方法:“地图中哪个区域最符合‘我用来放杯子的东西’这个描述?”(无需预训练,直接使用语言模型的理解能力)。
二、工作流程:如何构建ConceptGraph?
其流程非常清晰,分为三个核心步骤,下图展示了从原始数据到可用于规划的概念图的完整过程:
步骤一:3D重建
- 使用现成的SLAM系统(如VDB-Fusion)处理RGB-D图像流,生成一个稠密3D点云地图。每个点不仅有3D坐标和颜色,还有一个关键属性:它出现在哪些原始图像帧中。
步骤二:概念提取——核心创新
这是最关键的一步,实现了“开放词汇”能力。
- 点与图像的关联:对于点云中的每一个3D点,系统可以找到所有观察到它的2D图像区域(patches)。
- CLIP特征聚合:将这些2D图像区域输入到预训练的CLIP模型的图像编码器中,为每个图像区域提取一个高维特征向量。然后,将所有与此3D点关联的图像区域特征进行聚合(例如,取平均),得到一个单一的、强大的CLIP特征向量,并赋予这个3D点。
- 结果:至此,地图中的每一个3D点都携带了一个语义嵌入向量。这个向量位于CLIP模型创造的语义空间中,与文本嵌入向量可以直接比较。
步骤三:概念图构建
- 节点生成:使用几何分割算法(如欧几里得聚类)将点云分组为不同的物体实例。每个实例(即一组点)的CLIP特征是其所有点特征的聚合。这样,每个实例成为一个概念节点,拥有几何属性和语义特征。
- 关系生成:计算节点之间的空间关系(如“在上面”、“在旁边”、“包含”),形成图的边。
- 最终产出:一个开放词汇的3D场景图。图中的每个节点都可以用任意语言概念通过计算相似度来查询。
三、在机器人感知与规划中的应用
当机器人收到自然语言指令后,它利用ConceptGraph进行推理和规划的过程可以清晰地表示为以下流程:
- 语言接地:将指令中的关键词(“桌子”、“马克杯”)通过CLIP的文本编码器转换为文本特征向量。
- 图数据库查询:在ConceptGraph中,将文本特征向量与所有节点的CLIP特征向量进行相似度计算(如余弦相似度)。
- 目标节点定位:找到与“桌子”和“马克杯”最相似的节点。由于图包含空间关系,机器人可以推理出“马克杯”节点在“桌子”节点之上。
- 规划与执行:机器人可规划一条路径,先导航到桌子附近,然后操作机械臂拿取桌上的目标马克杯。
四、核心思想总结与价值
ConceptGraphs 的核心思想是:摒弃“先识别物体,再构建地图”的传统思路,转而采用一种“先为地图注入通用语义,再按需查询概念”的自下而上、数据驱动的方法。
其主要优势在于:
- 真正的开放词汇:不依赖任何预定义的封闭类别列表,可以理解训练数据中未曾出现过的概念,泛化能力极强。
- 实现简单:无需训练复杂的3D物体检测模型,构建流程主要依赖于现成的SLAM和预训练的CLIP模型,非常简洁。
- 概念稠密:每个点都带有语义信息,使得查询不再局限于物体级别,可以指向物体的部件或特定区域。
- 直接支持规划:生成的图结构自然地结合了几何、语义和关系信息,为符号推理和运动规划提供了理想的接口。
简而言之,ConceptGraphs 提供了一种务实而强大的路径,将大规模视觉-语言模型的知识“蒸馏”到机器人的空间记忆中,创造出一个机器人和人类都能用自然语言理解和操作的地图。 它和之前讨论的HOV-SG共同代表了当前将具身AI与3D空间理解相结合的最前沿探索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号