

https://github.com/IDEA-Research/Grounded-SAM-2?tab=readme-ov-file

# # 创建名为 sam2 的 Python 3.10 环境
# conda create -n sam2 python=3.10 -y
# # Linux/Mac
# conda activate sam2
# win10
# activate sam2
# 安装 PyTorch (CUDA 11.8 版本)
# conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=11.8 -c pytorch -c nvidia -y
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu118
1 正常安装sam2
2 安装目标检测grounding_dino
cd grounding_dino

# 先安装依赖
pip install -r requirements.txt
# 然后尝试非 editable 安装
pip install .
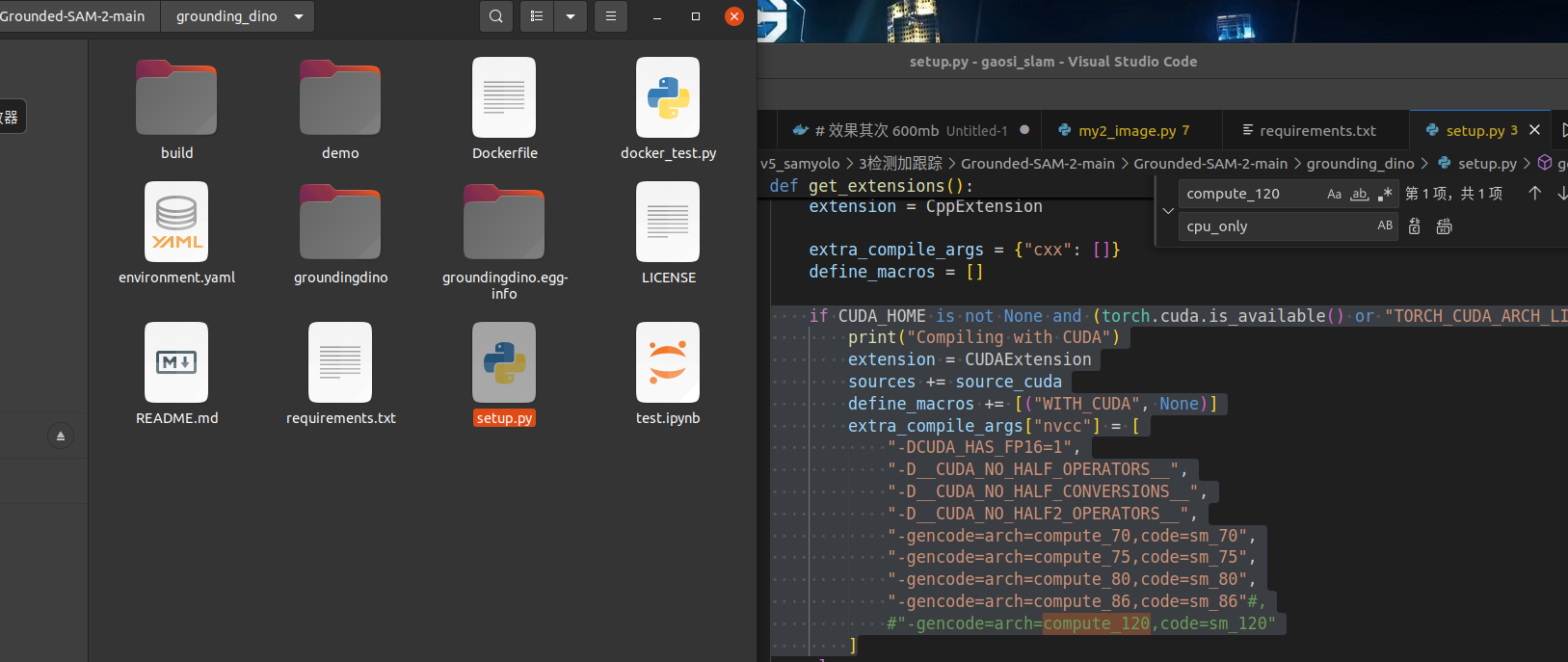
注销cuda不合适的版本 rtx3070 最高86 注销120
if CUDA_HOME is not None and (torch.cuda.is_available() or "TORCH_CUDA_ARCH_LIST" in os.environ):
print("Compiling with CUDA")
extension = CUDAExtension
sources += source_cuda
define_macros += [("WITH_CUDA", None)]
extra_compile_args["nvcc"] = [
"-DCUDA_HAS_FP16=1",
"-D__CUDA_NO_HALF_OPERATORS__",
"-D__CUDA_NO_HALF_CONVERSIONS__",
"-D__CUDA_NO_HALF2_OPERATORS__",
"-gencode=arch=compute_70,code=sm_70",
"-gencode=arch=compute_75,code=sm_75",
"-gencode=arch=compute_80,code=sm_80",
"-gencode=arch=compute_86,code=sm_86"#,
#"-gencode=arch=compute_120,code=sm_120"
]
测试1
https://github.com/IDEA-Research/Grounded-SAM-2?tab=readme-ov-file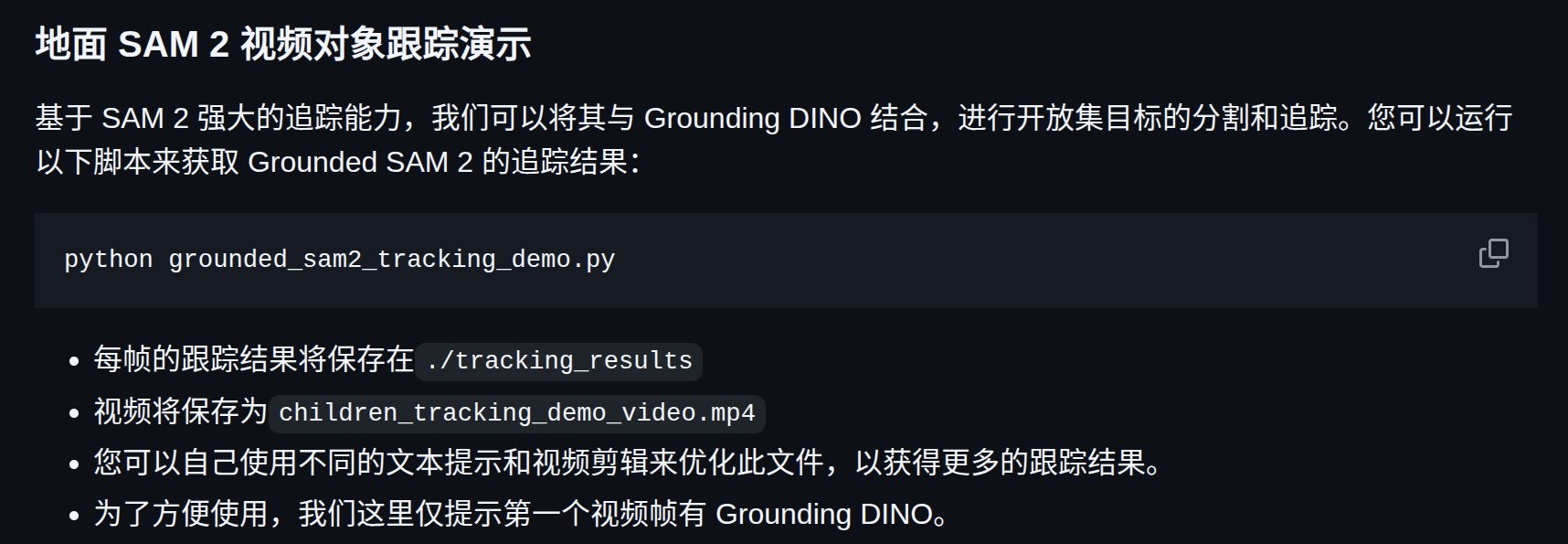
加载图片生成视频
python grounded_sam2_tracking_demo.py
速度超级快就合成完毕 why?
import os
import cv2
import torch
import numpy as np
import supervision as sv
from PIL import Image
from sam2.build_sam import build_sam2_video_predictor, build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
from utils.track_utils import sample_points_from_masks
from utils.video_utils import create_video_from_images
#nvidia-smi -l 2
"""
Step 1: Environment settings and model initialization
"""
# use bfloat16 for the entire notebook
torch.autocast(device_type="cuda", dtype=torch.bfloat16).__enter__()
if torch.cuda.get_device_properties(0).major >= 8:
# turn on tfloat32 for Ampere GPUs (https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
# init sam image predictor and video predictor model
# sam2_checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
# model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
# 注意 1_hiera_b 原始是 1_hiera_b+
# sam2_checkpoint = "./checkpoints/sam2.1_hiera_base_plus.pt"
# model_cfg = "configs/sam2.1/sam2.1_hiera_b.yaml"
sam2_checkpoint = "./checkpoints/sam2.1_hiera_small.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_s.yaml"
video_predictor = build_sam2_video_predictor(model_cfg, sam2_checkpoint)
sam2_image_model = build_sam2(model_cfg, sam2_checkpoint)
image_predictor = SAM2ImagePredictor(sam2_image_model)
# init grounding dino model from huggingface
model_id = "IDEA-Research/grounding-dino-tiny"
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = AutoProcessor.from_pretrained(model_id)
grounding_model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
# setup the input image and text prompt for SAM 2 and Grounding DINO
# VERY important: text queries need to be lowercased + end with a dot
text = "car."
# `video_dir` a directory of JPEG frames with filenames like `<frame_index>.jpg`
video_dir = "notebooks/videos/car"
# scan all the JPEG frame names in this directory
frame_names = [
p for p in os.listdir(video_dir)
if os.path.splitext(p)[-1] in [".jpg", ".jpeg", ".JPG", ".JPEG"]
]
frame_names.sort(key=lambda p: int(os.path.splitext(p)[0]))
# init video predictor state
inference_state = video_predictor.init_state(video_path=video_dir)
ann_frame_idx = 0 # the frame index we interact with
ann_obj_id = 1 # give a unique id to each object we interact with (it can be any integers)
print('图像加载完毕')
"""
Step 2: Prompt Grounding DINO and SAM image predictor to get the box and mask for specific frame
"""
# prompt grounding dino to get the box coordinates on specific frame
img_path = os.path.join(video_dir, frame_names[ann_frame_idx])
image = Image.open(img_path)
# run Grounding DINO on the image
inputs = processor(images=image, text=text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = grounding_model(**inputs)
results = processor.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
#box_threshold=0.25,
text_threshold=0.3,
target_sizes=[image.size[::-1]]
)
# prompt SAM image predictor to get the mask for the object
image_predictor.set_image(np.array(image.convert("RGB")))
# process the detection results
input_boxes = results[0]["boxes"].cpu().numpy()
OBJECTS = results[0]["labels"]
# prompt SAM 2 image predictor to get the mask for the object
masks, scores, logits = image_predictor.predict(
point_coords=None,
point_labels=None,
box=input_boxes,
multimask_output=False,
)
# convert the mask shape to (n, H, W)
if masks.ndim == 3:
masks = masks[None]
scores = scores[None]
logits = logits[None]
elif masks.ndim == 4:
masks = masks.squeeze(1)
"""
Step 3: Register each object's positive points to video predictor with seperate add_new_points call
"""
PROMPT_TYPE_FOR_VIDEO = "box" # or "point"
assert PROMPT_TYPE_FOR_VIDEO in ["point", "box", "mask"], "SAM 2 video predictor only support point/box/mask prompt"
# If you are using point prompts, we uniformly sample positive points based on the mask
if PROMPT_TYPE_FOR_VIDEO == "point":
# sample the positive points from mask for each objects
all_sample_points = sample_points_from_masks(masks=masks, num_points=10)
for object_id, (label, points) in enumerate(zip(OBJECTS, all_sample_points), start=1):
labels = np.ones((points.shape[0]), dtype=np.int32)
_, out_obj_ids, out_mask_logits = video_predictor.add_new_points_or_box(
inference_state=inference_state,
frame_idx=ann_frame_idx,
obj_id=object_id,
points=points,
labels=labels,
)
# Using box prompt
elif PROMPT_TYPE_FOR_VIDEO == "box":
for object_id, (label, box) in enumerate(zip(OBJECTS, input_boxes), start=1):
_, out_obj_ids, out_mask_logits = video_predictor.add_new_points_or_box(
inference_state=inference_state,
frame_idx=ann_frame_idx,
obj_id=object_id,
box=box,
)
# Using mask prompt is a more straightforward way
elif PROMPT_TYPE_FOR_VIDEO == "mask":
for object_id, (label, mask) in enumerate(zip(OBJECTS, masks), start=1):
labels = np.ones((1), dtype=np.int32)
_, out_obj_ids, out_mask_logits = video_predictor.add_new_mask(
inference_state=inference_state,
frame_idx=ann_frame_idx,
obj_id=object_id,
mask=mask
)
else:
raise NotImplementedError("SAM 2 video predictor only support point/box/mask prompts")
"""
Step 4: Propagate the video predictor to get the segmentation results for each frame
"""
video_segments = {} # video_segments contains the per-frame segmentation results
for out_frame_idx, out_obj_ids, out_mask_logits in video_predictor.propagate_in_video(inference_state):
video_segments[out_frame_idx] = {
out_obj_id: (out_mask_logits[i] > 0.0).cpu().numpy()
for i, out_obj_id in enumerate(out_obj_ids)
}
"""
Step 5: Visualize the segment results across the video and save them
"""
save_dir = "./tracking_results"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
ID_TO_OBJECTS = {i: obj for i, obj in enumerate(OBJECTS, start=1)}
for frame_idx, segments in video_segments.items():
img = cv2.imread(os.path.join(video_dir, frame_names[frame_idx]))
object_ids = list(segments.keys())
masks = list(segments.values())
masks = np.concatenate(masks, axis=0)
detections = sv.Detections(
xyxy=sv.mask_to_xyxy(masks), # (n, 4)
mask=masks, # (n, h, w)
class_id=np.array(object_ids, dtype=np.int32),
)
box_annotator = sv.BoxAnnotator()
annotated_frame = box_annotator.annotate(scene=img.copy(), detections=detections)
label_annotator = sv.LabelAnnotator()
annotated_frame = label_annotator.annotate(annotated_frame, detections=detections, labels=[ID_TO_OBJECTS[i] for i in object_ids])
mask_annotator = sv.MaskAnnotator()
annotated_frame = mask_annotator.annotate(scene=annotated_frame, detections=detections)
cv2.imwrite(os.path.join(save_dir, f"annotated_frame_{frame_idx:05d}.jpg"), annotated_frame)
"""
Step 6: Convert the annotated frames to video
"""
output_video_path = "./children_tracking_demo_video.mp4"
create_video_from_images(save_dir, output_video_path)

python grounded_sam2_tracking_demo_with_continuous_id.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号