

https://github.com/IDEA-Research/GroundingDINO



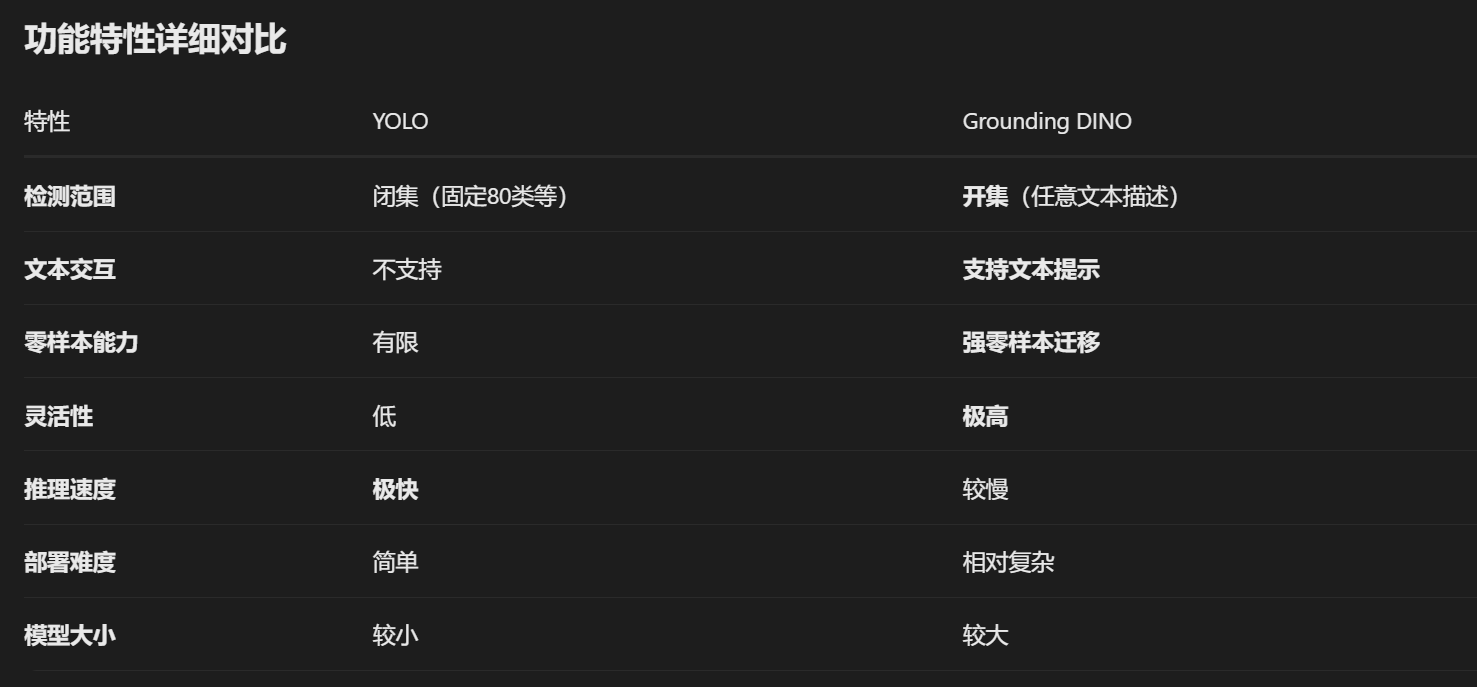
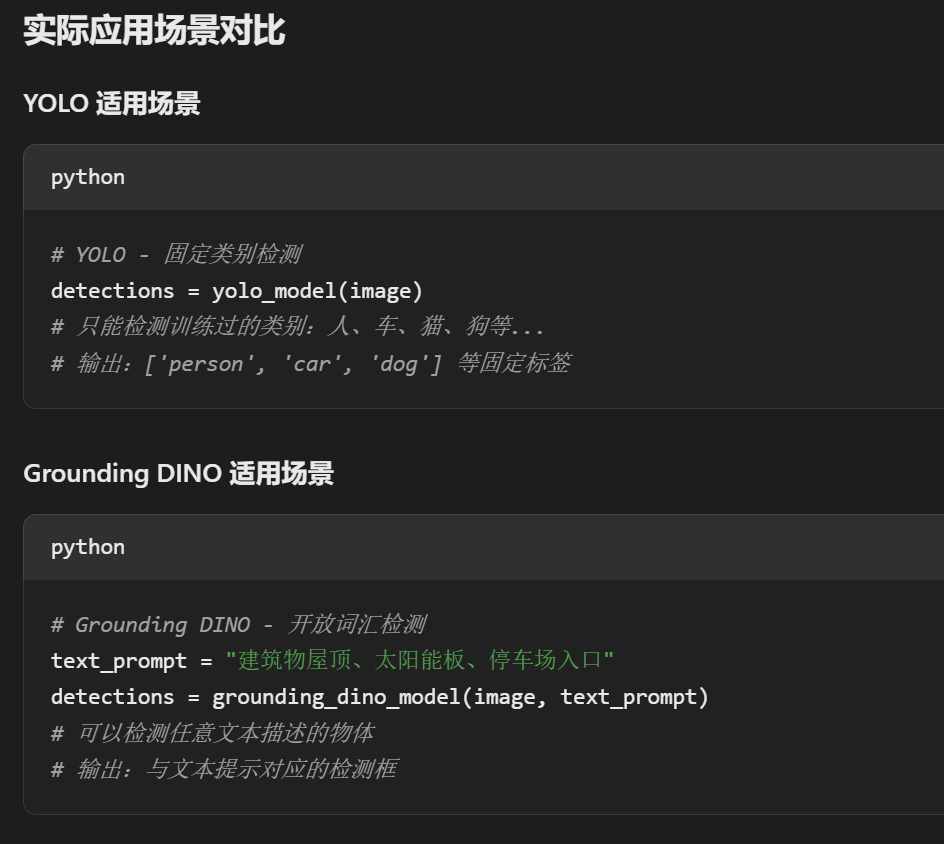
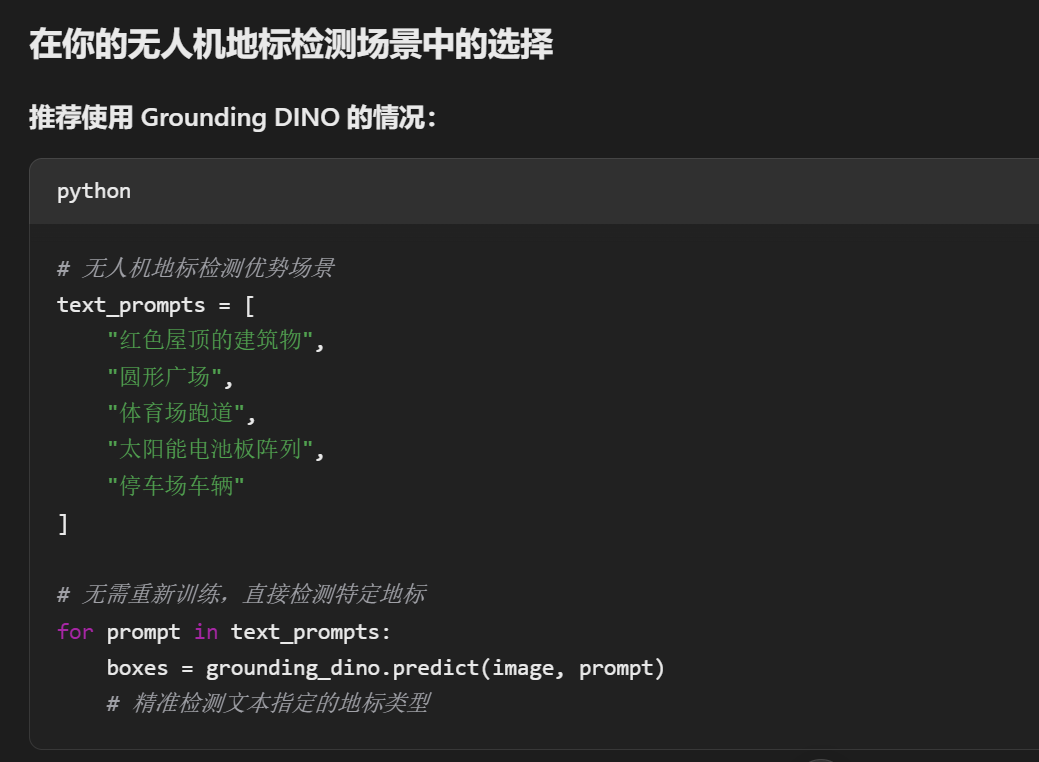
级联方案(推荐)
def optimized_drone_pipeline(image):
# 第一段:YOLO快速初筛
fast_detections = yolo_model(image)
# 第二段:对感兴趣区域用Grounding DINO精细识别
for roi in fast_detections:
if is_potential_landmark(roi):
specific_prompt = get_landmark_prompt(roi)
detailed_detection = grounding_dino(roi, specific_prompt)
return combined_results




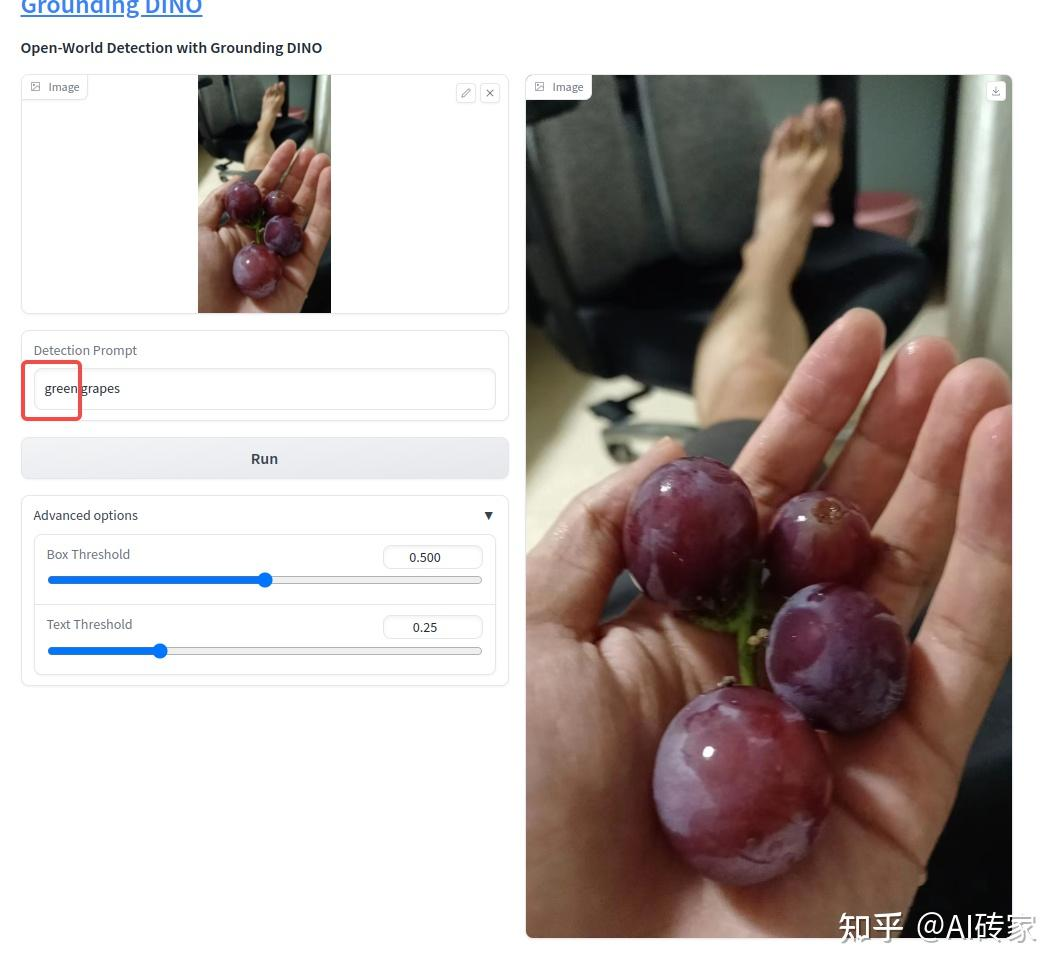
https://github.com/loki-keroro/SAMbase_segmentation
基于SAM-DINO-CLIP组合模型实现全景图场景下的地物分类和实例分割

模型会根据不同的提示文本,生成不同的掩码,可修改main.py中的category_cfg变量,自定义提示文本。
- landcover_prompts为地物分类的提示,在全景图场景下一般用于分割区域连续或较大的类别
- cityobject_prompts为实例分割的提示,在全景图场景下一般用于图像内区域不连续的对象类别
- landcover_prompts_cn和cityobject_prompts_cn为每个类别的中文含义
category_cfg = {
"landcover_prompts": ['building', 'low vegetation', 'tree', 'river', 'shed', 'road', 'lake', 'bare soil'],
"landcover_prompts_cn": ['建筑', '低矮植被', '树木', '河流', '棚屋', '道路', '湖泊', '裸土'],
"cityobject_prompts": ['car', 'truck', 'bus', 'train', 'ship', 'boat'],
"cityobject_prompts_cn": ['轿车', '卡车', '巴士', '列车', '船(舰)', '船(舶)']
}
安装
git clone https://github.com/IDEA-Research/GroundingDINO.git
cd GroundingDINO/
pip install -e .如果报错
# # 创建名为 sam2 的 Python 3.10 环境
# conda create -n sam2 python=3.10 -y
# # Linux/Mac
# conda activate sam2
# win10
# activate sam2
# 安装 PyTorch (CUDA 11.8 版本)
# conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=11.8 -c pytorch -c nvidia -y
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu118
# 先安装依赖
pip install -r requirements.txt
# 然后尝试非 editable 安装
pip install .
下载权重
mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth cd ..


# 效果其次 600mb PYTHONWARNINGS="ignore" python demo/inference_on_a_image.py \ -c groundingdino/config/GroundingDINO_SwinT_OGC.py \ -p weights/groundingdino_swint_ogc.pth \ -i demo/npu2pm.JPG \ -o "demo/" \ -t "house" # 效果更好 900mb PYTHONWARNINGS="ignore" python demo/inference_on_a_image.py \ -c groundingdino/config/GroundingDINO_SwinB_cfg.py \ -p weights/groundingdino_swinb_cogcoor.pth \ -i demo/npu2pm.JPG \ -o "demo/" \ -t "house"



测试代码1 usb相机 opencv 读取和可视化
import argparse
import os
import sys
import time
import warnings
import numpy as np
import torch
import cv2
from PIL import Image, ImageDraw, ImageFont
import groundingdino.datasets.transforms as T
from groundingdino.models import build_model
from groundingdino.util.slconfig import SLConfig
from groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
from groundingdino.util.vl_utils import create_positive_map_from_span
from groundingdino.util.inference import load_model, load_image, predict, annotate
import cv2
# 配置警告过滤器
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
def parse_args():
parser = argparse.ArgumentParser(description="GroundingDINO 实时目标检测")
parser.add_argument("--model_type", type=str, default="SwinB", choices=["SwinB", "SwinT"],
help="模型类型: SwinB(大模型)或SwinT(小模型)")
parser.add_argument("--text_prompt", type=str, default="building, person, door, cap",
help="检测文本提示,多个目标用逗号分隔")
parser.add_argument("--box_threshold", type=float, default=0.25,
help="框检测阈值")
parser.add_argument("--text_threshold", type=float, default=0.25,
help="文本检测阈值")
parser.add_argument("--cpu_only", action="store_true",
help="仅使用CPU运行")
parser.add_argument("--camera_id", type=int, default=0,
help="摄像头ID")
parser.add_argument("--output_dir", type=str, default="outputs",
help="输出目录")
return parser.parse_args()
def plot_boxes_to_image_cv2(image_cv2, boxes, labels):
"""
在OpenCV图像上绘制检测框和标签
"""
H, W = image_cv2.shape[:2]
for box, label in zip(boxes, labels):
# 从0..1转换到0..W, 0..H
box = box * torch.Tensor([W, H, W, H])
# 从xywh转换到xyxy
box[:2] -= box[2:] / 2
box[2:] += box[:2]
# 坐标转换
x0, y0, x1, y1 = map(int, box.tolist())
# 随机颜色
color = tuple(map(int, np.random.randint(0, 255, size=3)))
# 绘制矩形框
cv2.rectangle(image_cv2, (x0, y0), (x1, y1), color, 2)
# 绘制标签背景和文字
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.5
thickness = 1
# 获取文本大小
(text_width, text_height), _ = cv2.getTextSize(label, font, font_scale, thickness)
# 绘制文本背景
cv2.rectangle(image_cv2, (x0, y0 - text_height - 5),
(x0 + text_width, y0), color, -1)
# 绘制文本
cv2.putText(image_cv2, label, (x0, y0 - 5), font,
font_scale, (255, 255, 255), thickness, cv2.LINE_AA)
return image_cv2
def load_model(model_config_path, model_checkpoint_path, cpu_only=False):
"""
加载模型
"""
try:
args = SLConfig.fromfile(model_config_path)
args.device = "cuda" if not cpu_only and torch.cuda.is_available() else "cpu"
model = build_model(args)
checkpoint = torch.load(model_checkpoint_path, map_location="cpu")
load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
print("模型加载结果:", load_res)
model.eval()
return model
except Exception as e:
raise RuntimeError(f"加载模型失败: {str(e)}")
def get_grounding_output(model, image, caption, box_threshold, text_threshold=None,
with_logits=True, cpu_only=False):
"""
获取模型的检测输出
"""
if text_threshold is None:
raise ValueError("text_threshold不能为None")
caption = caption.lower().strip()
if not caption.endswith("."):
caption += "."
device = "cuda" if not cpu_only and torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
model = model.to(device)
image = image.to(device)
with torch.no_grad():
outputs = model(image[None], captions=[caption])
logits = outputs["pred_logits"].sigmoid()[0] # (nq, 256)
boxes = outputs["pred_boxes"][0] # (nq, 4)
# 过滤输出
logits_filt = logits.cpu().clone()
boxes_filt = boxes.cpu().clone()
filt_mask = logits_filt.max(dim=1)[0] > box_threshold
logits_filt = logits_filt[filt_mask]
boxes_filt = boxes_filt[filt_mask]
# 获取短语
tokenizer = model.tokenizer
tokenized = tokenizer(caption)
pred_phrases = []
for logit, box in zip(logits_filt, boxes_filt):
pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenizer)
if with_logits:
pred_phrases.append(pred_phrase + f"({logit.max().item():.2f})")
else:
pred_phrases.append(pred_phrase)
return boxes_filt, pred_phrases
def preprocess_cv2_image(image_cv2):
"""
将OpenCV图像转换为模型输入格式
"""
# 转换颜色空间 BGR -> RGB
image_pil = Image.fromarray(cv2.cvtColor(image_cv2, cv2.COLOR_BGR2RGB))
transform = T.Compose([
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
image, _ = transform(image_pil, None)
return image_pil, image
def main():
args = parse_args()
# 创建输出目录
os.makedirs(args.output_dir, exist_ok=True)
# 根据模型类型选择配置
if args.model_type == "SwinB":
config_file = "../groundingdino/config/GroundingDINO_SwinB_cfg.py"
checkpoint_path = "../weights/groundingdino_swinb_cogcoor.pth"
else:
config_file = "../groundingdino/config/GroundingDINO_SwinT_OGC.py"
checkpoint_path = "../weights/groundingdino_swint_ogc.pth"
try:
# 加载模型
print(f"正在加载 {args.model_type} 模型...")
model = load_model(config_file, checkpoint_path, args.cpu_only)
print("模型加载完成")
# 打开摄像头
cap = cv2.VideoCapture(args.camera_id)
if not cap.isOpened():
raise RuntimeError("无法打开摄像头")
print("开始实时检测,按ESC键退出...")
# image_path='npu2pm.JPG'
# frame, image_tensor = preprocess_cv2_image(image_path)
while True:
# #读取摄像头画面
ret, frame = cap.read()
if not ret:
print("无法获取摄像头画面")
break
_, image_tensor = preprocess_cv2_image(frame)
# 运行模型
start_time = time.time()
boxes_filt, pred_phrases = get_grounding_output(
model, image_tensor, args.text_prompt,
args.box_threshold, args.text_threshold,
cpu_only=args.cpu_only
)
elapsed_time = time.time() - start_time
# 在图像上绘制检测结果
if len(boxes_filt) > 0:
frame = plot_boxes_to_image_cv2(frame, boxes_filt, pred_phrases)
# 显示FPS
fps = 1 / elapsed_time if elapsed_time > 0 else 0
cv2.putText(frame, f"FPS: {fps:.1f}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
# 显示结果
cv2.imshow("Real-time Detection", frame)
# 按ESC键退出
if cv2.waitKey(1) == 27:
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
except Exception as e:
print(f"发生错误: {str(e)}")
sys.exit(1)
if __name__ == "__main__":
main()
代码2 从uSB相机或者文件夹读取图像 识别保存
import os
import sys
import time
import warnings
import numpy as np
import torch
import cv2
from PIL import Image, ImageDraw, ImageFont
import groundingdino.datasets.transforms as T
from groundingdino.models import build_model
from groundingdino.util.slconfig import SLConfig
from groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
from groundingdino.util.vl_utils import create_positive_map_from_span
from groundingdino.util.inference import load_model, load_image, predict, annotate
# 配置警告过滤器
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
# 无人机对地检测目标列表(排除树木和人)
DRONE_TARGETS = [
# 车辆类
"vehicle", "car", "truck", "bus", "van", "SUV", "motorcycle", "bicycle",
"construction vehicle", "excavator", "bulldozer", "crane", "forklift",
"tractor", "trailer", "ambulance", "fire truck", "police car",
# 建筑物和结构
"building", "house", "apartment", "commercial building", "factory",
"warehouse", "shed", "garage", "roof", "chimney",
"bridge", "overpass", "tunnel", "dam", "power plant",
# 道路和交通设施
"road", "highway", "street", "pavement", "crosswalk", "roundabout",
"traffic light", "street light", "road sign", "billboard",
"parking lot", "gas station", "bus stop",
# 水域相关
"river", "lake", "pond", "reservoir", "swimming pool", "fountain",
"boat", "ship", "yacht", "speedboat", "dock", "pier", "harbor",
# 农业相关
"farmland", "crop field", "greenhouse", "barn", "silo", "windmill",
"irrigation system", "livestock pen",
# 能源设施
"solar panel", "wind turbine", "power line", "transformer",
"oil rig", "oil tank", "gas pipeline",
# 运动场地
"soccer field", "basketball court", "tennis court", "baseball field",
"swimming pool", "stadium", "running track",
# 基础设施
"airport", "runway", "hangar", "airplane", "helicopter",
"railway", "train", "railroad track", "train station",
"cell tower", "communication tower", "satellite dish",
# 军事和安全设施(可选)
"military vehicle", "barracks", "checkpoint", "fence", "gate",
# 其他重要目标
"container", "shipping container", "cargo", "construction material",
"playground equipment", "park bench", "statue", "monument"
]
DRONE_TARGETS_min = [
# 建筑物和结构
"building", "house", "apartment", "commercial building", "factory",
"warehouse", "shed", "garage", "roof", "chimney",
"bridge", "overpass", "tunnel", "dam", "power plant",
# 道路和交通设施
"road", "highway", "street", "pavement", "crosswalk", "roundabout",
"traffic light", "street light", "road sign", "billboard",
"parking lot", "gas station", "bus stop",
# 运动场地
"soccer field", "basketball court", "tennis court", "baseball field",
"swimming pool", "stadium", "running track",
]
class Config:
def __init__(self):
# 模型配置
self.model_type = "SwinB" # "SwinB" 938mb 或 "SwinT" 600mb
#self.text_prompt = "building, person, door, cap" # 检测文本提示
self.text_prompt = ", ".join(DRONE_TARGETS_min)
'''
官方
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
'''
self.box_threshold = 0.2 # 提高框阈值,减少误检
self.text_threshold = 0.18 # 降低文本阈值,提高小目标召回
self.cpu_only = False # 仅使用CPU运行
# 输入源配置
self.input_type = "folder" # "video"或"folder"
self.video_path = 0 # 视频路径或摄像头ID
self.folder_path = "/home/r9000k/v0_data/rtk/nwpu_1130_12pm" # 图像文件夹路径
# 输出配置
self.output_dir = "outputs" # 输出目录
self.save_results = True # 是否保存结果
self.show_results = True # 是否显示结果
# 其他配置
# 后处理配置
self.min_target_area = 0 # 最小目标面积(像素),过滤过小目标
self.sort_by_timestamp = True # 是否按时间戳排序图像
def plot_boxes_to_image_cv2(image_cv2, boxes, labels):
"""
在OpenCV图像上绘制检测框和标签
"""
H, W = image_cv2.shape[:2]
for box, label in zip(boxes, labels):
# 从0..1转换到0..W, 0..H
box = box * torch.Tensor([W, H, W, H])
# 从xywh转换到xyxy
box[:2] -= box[2:] / 2
box[2:] += box[:2]
# 坐标转换
x0, y0, x1, y1 = map(int, box.tolist())
# 随机颜色
color = tuple(map(int, np.random.randint(0, 255, size=3)))
# 绘制矩形框
cv2.rectangle(image_cv2, (x0, y0), (x1, y1), color, 2)
# 绘制标签背景和文字
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.5
thickness = 1
# 获取文本大小
(text_width, text_height), _ = cv2.getTextSize(label, font, font_scale, thickness)
# 绘制文本背景
cv2.rectangle(image_cv2, (x0, y0 - text_height - 5),
(x0 + text_width, y0), color, -1)
# 绘制文本
cv2.putText(image_cv2, label, (x0, y0 - 5), font,
font_scale, (255, 255, 255), thickness, cv2.LINE_AA)
return image_cv2
def load_model(model_config_path, model_checkpoint_path, cpu_only=False):
"""
加载模型
"""
try:
args = SLConfig.fromfile(model_config_path)
args.device = "cuda" if not cpu_only and torch.cuda.is_available() else "cpu"
model = build_model(args)
checkpoint = torch.load(model_checkpoint_path, map_location="cpu")
load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
print("模型加载结果:", load_res)
model.eval()
return model
except Exception as e:
raise RuntimeError(f"加载模型失败: {str(e)}")
# def get_grounding_output(model, image, caption, box_threshold, text_threshold=None,
# with_logits=True, cpu_only=False):
# """
# 获取模型的检测输出
# """
# if text_threshold is None:
# raise ValueError("text_threshold不能为None")
# caption = caption.lower().strip()
# if not caption.endswith("."):
# caption += "."
# device = "cuda" if not cpu_only and torch.cuda.is_available() else "cpu"
# print(f"使用设备: {device}")
# model = model.to(device)
# image = image.to(device)
# with torch.no_grad():
# outputs = model(image[None], captions=[caption])
# logits = outputs["pred_logits"].sigmoid()[0] # (nq, 256)
# boxes = outputs["pred_boxes"][0] # (nq, 4)
# # 过滤输出
# logits_filt = logits.cpu().clone()
# boxes_filt = boxes.cpu().clone()
# filt_mask = logits_filt.max(dim=1)[0] > box_threshold
# logits_filt = logits_filt[filt_mask]
# boxes_filt = boxes_filt[filt_mask]
# # 获取短语
# tokenizer = model.tokenizer
# tokenized = tokenizer(caption)
# pred_phrases = []
# for logit, box in zip(logits_filt, boxes_filt):
# pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenizer)
# if with_logits:
# pred_phrases.append(pred_phrase + f"({logit.max().item():.2f})")
# else:
# pred_phrases.append(pred_phrase)
# return boxes_filt, pred_phrases
def get_grounding_output(model, image, caption, box_threshold, text_threshold=None,
with_logits=True, cpu_only=False, min_area=0):
"""
获取模型的检测输出,添加面积过滤
"""
if text_threshold is None:
raise ValueError("text_threshold不能为None")
caption = caption.lower().strip()
if not caption.endswith("."):
caption += "."
device = "cuda" if not cpu_only and torch.cuda.is_available() else "cpu"
model = model.to(device)
image = image.to(device)
with torch.no_grad():
outputs = model(image[None], captions=[caption])
logits = outputs["pred_logits"].sigmoid()[0] # (nq, 256)
boxes = outputs["pred_boxes"][0] # (nq, 4)
# 过滤输出
logits_filt = logits.cpu().clone()
boxes_filt = boxes.cpu().clone()
filt_mask = logits_filt.max(dim=1)[0] > box_threshold
logits_filt = logits_filt[filt_mask]
boxes_filt = boxes_filt[filt_mask]
# 获取短语
tokenizer = model.tokenizer
tokenized = tokenizer(caption)
pred_phrases = []
valid_boxes = []
for logit, box in zip(logits_filt, boxes_filt):
# 计算目标面积(归一化坐标)
area = (box[2] * box[3]) * (image.shape[2] * image.shape[1]) # 转为像素面积
if area < min_area:
continue
pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenizer)
if with_logits:
pred_phrases.append(pred_phrase + f"({logit.max().item():.2f})")
else:
pred_phrases.append(pred_phrase)
valid_boxes.append(box)
return torch.stack(valid_boxes) if valid_boxes else torch.empty(0), pred_phrases
def preprocess_cv2_image(image_cv2):
"""
将OpenCV图像转换为模型输入格式
"""
# 转换颜色空间 BGR -> RGB
image_pil = Image.fromarray(cv2.cvtColor(image_cv2, cv2.COLOR_BGR2RGB))
transform = T.Compose([
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
image, _ = transform(image_pil, None)
return image_pil, image
def get_image_files_from_folder(folder_path, sort_by_number=True):
"""
从文件夹获取所有图像文件,可选按时间戳排序
"""
supported_formats = ('.jpg', '.jpeg', '.png', '.bmp', '.tiff', '.gif')
image_files = []
for root, _, files in os.walk(folder_path):
for file in files:
if file.lower().endswith(supported_formats):
image_files.append(os.path.join(root, file))
if sort_by_number:
# 提取文件名中的数字部分进行排序
def extract_number(filename):
# 从文件名中提取数字部分,例如DJI_0004.JPG -> 4
base = os.path.basename(filename)
# 去除扩展名
name_without_ext = os.path.splitext(base)[0]
# 提取数字部分
numbers = ''.join(filter(str.isdigit, name_without_ext))
return int(numbers) if numbers else 0
image_files.sort(key=extract_number)
return image_files
def process_video(model, config):
"""
处理视频或摄像头输入
"""
cap = cv2.VideoCapture(config.video_path)
if not cap.isOpened():
raise RuntimeError(f"无法打开视频源: {config.video_path}")
print("开始实时检测,按ESC键退出...")
cv2.namedWindow('Video_Detection', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Video_Detection', 640, 480)
while True:
ret, frame = cap.read()
if not ret:
print("无法获取视频帧")
break
_, image_tensor = preprocess_cv2_image(frame)
# 运行模型
start_time = time.time()
boxes_filt, pred_phrases = get_grounding_output(
model, image_tensor, config.text_prompt,
config.box_threshold, config.text_threshold,
cpu_only=config.cpu_only,
min_area=config.min_target_area
)
elapsed_time = time.time() - start_time
# 在图像上绘制检测结果
if len(boxes_filt) > 0:
frame = plot_boxes_to_image_cv2(frame, boxes_filt, pred_phrases)
# 显示FPS
fps = 1 / elapsed_time if elapsed_time > 0 else 0
cv2.putText(frame, f"FPS: {fps:.1f}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
if config.show_results:
cv2.imshow("Video_Detection", frame)
if config.save_results:
output_path = os.path.join(config.output_dir, f"frame_{int(time.time())}.jpg")
cv2.imwrite(output_path, frame)
# 按ESC键退出
if cv2.waitKey(1) == 27:
break
cap.release()
if config.show_results:
cv2.destroyAllWindows()
def process_folder(model, config):
"""
处理文件夹中的图像
"""
image_files = get_image_files_from_folder(config.folder_path, config.sort_by_timestamp)
if not image_files:
print(f"在文件夹 {config.folder_path} 中未找到图像文件")
return
print(f"找到 {len(image_files)} 张图像,开始处理...")
cv2.namedWindow('Image_Detection', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Image_Detection', 640, 480)
for i, image_path in enumerate(image_files):
print(f"处理图像 {i+1}/{len(image_files)}: {image_path}")
try:
frame = cv2.imread(image_path)
if frame is None:
print(f"无法读取图像: {image_path}")
continue
_, image_tensor = preprocess_cv2_image(frame)
# 运行模型
start_time = time.time()
boxes_filt, pred_phrases = get_grounding_output(
model, image_tensor, config.text_prompt,
config.box_threshold, config.text_threshold,
cpu_only=config.cpu_only,
min_area=config.min_target_area
)
elapsed_time = time.time() - start_time
# 在图像上绘制检测结果
if len(boxes_filt) > 0:
frame = plot_boxes_to_image_cv2(frame, boxes_filt, pred_phrases)
# 显示处理信息
fps = 1 / elapsed_time if elapsed_time > 0 else 0
info_text = f"Image {i+1}/{len(image_files)} - FPS: {fps:.1f}"
cv2.putText(frame, info_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
if config.show_results:
cv2.imshow("Image_Detection", frame)
if cv2.waitKey(0) == 27:
break
if config.save_results:
output_filename = os.path.basename(image_path)
output_path = os.path.join(config.output_dir, output_filename)
cv2.imwrite(output_path, frame)
print(f"结果已保存到: {output_path}")
except Exception as e:
print(f"处理图像 {image_path} 时出错: {str(e)}")
if config.show_results:
cv2.destroyAllWindows()
def main():
config = Config()
# 创建输出目录
os.makedirs(config.output_dir, exist_ok=True)
# 根据模型类型选择配置
if config.model_type == "SwinB":
config_file = "../groundingdino/config/GroundingDINO_SwinB_cfg.py"
checkpoint_path = "../weights/groundingdino_swinb_cogcoor.pth"
else:
config_file = "../groundingdino/config/GroundingDINO_SwinT_OGC.py"
checkpoint_path = "../weights/groundingdino_swint_ogc.pth"
try:
# 加载模型
print(f"正在加载 {config.model_type} 模型...")
model = load_model(config_file, checkpoint_path, config.cpu_only)
print("模型加载完成")
# 根据输入类型选择处理方式
if config.input_type == "video":
process_video(model, config)
elif config.input_type == "folder":
process_folder(model, config)
else:
raise ValueError(f"不支持的输入类型: {config.input_type}")
except Exception as e:
print(f"发生错误: {str(e)}")
sys.exit(1)
if __name__ == "__main__":
main()
代码
代码2
import warnings
warnings.filterwarnings("ignore") # 忽略所有警告
# 或针对特定警告:
warnings.filterwarnings("ignore", category=FutureWarning) # 仅忽略 FutureWarning
warnings.filterwarnings("ignore", category=UserWarning) # 仅忽略 UserWarning
from groundingdino.util.inference import load_model, load_image, predict, annotate
import cv2
config_path="../groundingdino/config/GroundingDINO_SwinT_OGC.py"
weights_path="../weights/groundingdino_swint_ogc.pth"
'''
以下是"房子"的英文近义词,按语义分类:
🏠 Direct Synonyms
House - 最常用
Building - 建筑物(更广义)
Home - 带有情感色彩的家
Residence - 正式用语,住所
Dwelling - 居住场所
🏡 Specific Types of Houses
Villa - 别墅
Apartment - 公寓
Cottage - 小屋,村舍
Bungalow - 平房
Mansion - 豪宅
Duplex - 双拼别墅
Townhouse - 联排别墅
🏘️ Architectural Terms
Structure - 结构物
Edifice - 大型建筑(正式)
Construction - 建筑物
Property - 房产
📝 Literary/Formal Terms
Abode - 住所(文学性)
Habitation - 居住地
Domicile - 法定住所
Residency - 居所
# "building road vehicle park residential commercial industrial"
'''
model = load_model(config_path, weights_path)
IMAGE_PATH = "npu2pm.JPG"
TEXT_PROMPT = "building house structure construction"
BOX_TRESHOLD = 0.3 #0.35
TEXT_TRESHOLD = 0.3 # 0.25
Save_path=TEXT_PROMPT+IMAGE_PATH
image_source, image = load_image(IMAGE_PATH)
boxes, logits, phrases = predict(
model=model,
image=image,
caption=TEXT_PROMPT,
box_threshold=BOX_TRESHOLD,
text_threshold=TEXT_TRESHOLD
)
annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
cv2.imwrite(Save_path, annotated_frame)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号