Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景
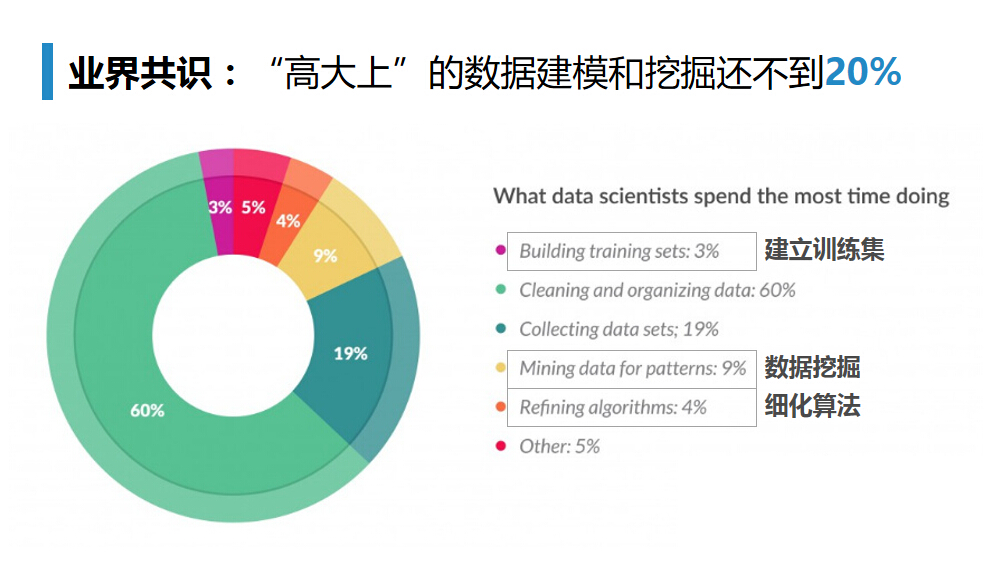
在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作中。
这个项目推出以后受到很大关注,因为开放源码,大家可以在现成源码基础上进一步开发。然而,Python3和Python2是有区别的,《Python即时网络爬虫项目: 内容提取器的定义》 一文的源码无法在Python2.7下使用,本文将发布一个Python2.7的内容提取器。
2. 解决方案
为了解决这个问题,我们把影响通用性和工作效率的提取器隔离出来,描述了如下的数据处理流程图:
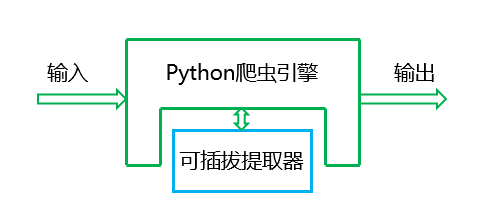
图中“可插拔提取器”必须很强的模块化,那么关键的接口有:
- 标准化的输入:以标准的HTML DOM对象为输入
- 标准化的内容提取:使用标准的xslt模板提取网页内容
- 标准化的输出:以标准的XML格式输出从网页上提取到的内容
- 明确的提取器插拔接口:提取器是一个明确定义的类,通过类方法与爬虫引擎模块交互
3. 提取器代码
可插拔提取器是即时网络爬虫项目的核心组件,定义成一个类: GsExtractor
适用python2.7的源代码文件及其说明文档请从 github 下载
使用模式是这样的:
- 实例化一个GsExtractor对象
- 为这个对象设定xslt提取器,相当于把这个对象配置好(使用三类setXXX()方法)
- 把html dom输入给它,就能获得xml输出(使用extract()方法)
下面是这个GsExtractor类的源代码(适用于Python2.7)

4. 用法示例
下面是一个示例程序,演示怎样使用GsExtractor类提取豆瓣讨论组话题。本示例有如下特征:
- 提取器的内容通过GooSeeker平台上的api获得
- 保存结果文件到当前文件夹
下面是源代码,都可从 github 下载

提取结果如下图所示:

5. 接下来阅读
本文已经说明了提取器的价值和用法,但是没有说怎样生成它,只有快速生成提取器才能达到节省开发者时间的目的,这个问题将在其他文章讲解,请看《1分钟快速生成用于网页内容提取的xslt模板》
6. 集搜客GooSeeker开源代码下载源
1. GooSeeker开源Python网络爬虫GitHub源
7. 文档修改历史
2016-08-05:V1.0,Python2.7下的内容提取器类首次发布


 浙公网安备 33010602011771号
浙公网安备 33010602011771号