
LLM大语言模型到底能做啥?
一、前言
有很多人会很困惑,LLM大语言模型到底能做啥?除了聊天以外,还能给我们带来什么价值?
首先要回答这个问题,我们先要了解transform能做啥?
二、Transformer模型
2.1 起源与发展
2017 年 Google 在《Attention Is All You Need》中提出了 Transformer 结构用于序列标注,在翻译任务上超过了之前最优秀的循环神经网络模型;与此同时,Fast AI 在《Universal Language Model Fine-tuning for Text Classification》中提出了一种名为 ULMFiT 的迁移学习方法,将在大规模数据上预训练好的 LSTM 模型迁移用于文本分类,只用很少的标注数据就达到了最佳性能。
这些具有开创性的工作促成了两个著名 Transformer 模型的出现:
- GPT (the Generative Pretrained Transformer);
- BERT (Bidirectional Encoder Representations from Transformers)。
通过将 Transformer 结构与无监督学习相结合,我们不再需要对每一个任务都从头开始训练模型,并且几乎在所有 NLP 任务上都远远超过先前的最强基准。
GPT 和 BERT 被提出之后,NLP 领域出现了越来越多基于 Transformer 结构的模型,其中比较有名有:

虽然新的 Transformer 模型层出不穷,它们采用不同的预训练目标在不同的数据集上进行训练,但是依然可以按模型结构将它们大致分为三类:
- 纯 Encoder 模型(例如 BERT),又称自编码 (auto-encoding) Transformer 模型;
- 纯 Decoder 模型(例如 GPT),又称自回归 (auto-regressive) Transformer 模型;
- Encoder-Decoder 模型(例如 BART、T5),又称 Seq2Seq (sequence-to-sequence) Transformer 模型。
Transformer 模型本质上都是预训练语言模型,大都采用自监督学习 (Self-supervised learning) 的方式在大量生语料上进行训练,也就是说,训练这些 Transformer 模型完全不需要人工标注数据。
2.2 Transformer 的结构
标准的 Transformer 模型主要由两个模块构成:
- Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征);
- Decoder(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。

这两个模块可以根据任务的需求而单独使用:
- 纯 Encoder 模型:适用于只需要理解输入语义的任务,例如句子分类、命名实体识别;
- 纯 Decoder 模型:适用于生成式任务,例如文本生成;
- Encoder-Decoder 模型或 Seq2Seq 模型:适用于需要基于输入的生成式任务,例如翻译、摘要。
原始的 Transformer 模型结构如下图所示,Encoder 在左,Decoder 在右:

2.3 Transformer 家族
虽然新的 Transformer 模型层出不穷,但是它们依然可以被归纳到以下三种结构中:
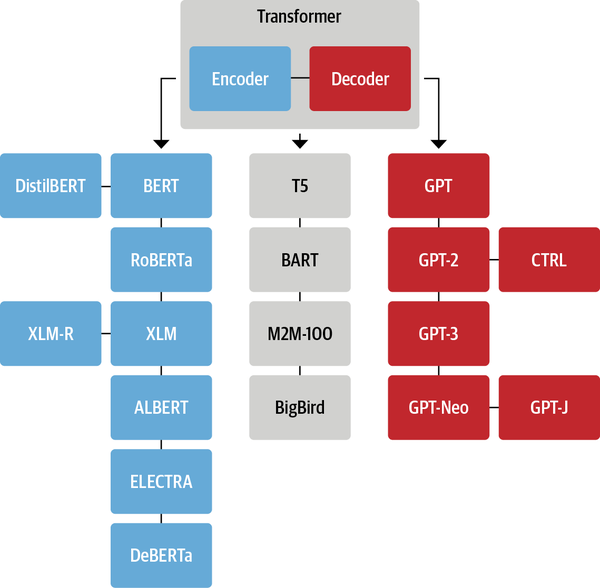
2.4 Transformers 库
Transformers 库将目前的 NLP 任务归纳为几下几类:
- 文本分类:例如情感分析、句子对关系判断等;
- 对文本中的词语进行分类:例如词性标注 (POS)、命名实体识别 (NER) 等;
- 文本生成:例如填充预设的模板 (prompt)、预测文本中被遮掩掉 (masked) 的词语;
- 从文本中抽取答案:例如根据给定的问题从一段文本中抽取出对应的答案;
- 根据输入文本生成新的句子:例如文本翻译、自动摘要等。
Transformers 库最基础的对象就是 pipeline() 函数,它封装了预训练模型和对应的前处理和后处理环节。我们只需输入文本,就能得到预期的答案。目前常用的 pipelines 有:
feature-extraction(获得文本的向量化表示)fill-mask(填充被遮盖的词、片段)ner(命名实体识别)question-answering(自动问答)sentiment-analysis(情感分析)summarization(自动摘要)text-generation(文本生成)translation(机器翻译)zero-shot-classification(零训练样本分类)
三、语音模型
3.1 语音转文本(Speech2Text)
Speech2Text 模型由 Changhan Wang、Yun Tang、Xutai Ma、Anne Wu、Dmytro Okhonko、Juan Pino 在 fairseq S2T:使用 fairseq 进行快速语音到文本建模 中提出。它是一个基于 Transformer 的 seq2seq(编码器-解码器)模型,专为端到端自动语音识别(ASR)和语音翻译(ST)设计。它使用一个卷积下采样器,将语音输入的长度减少 3/4,然后将其送入编码器。该模型通过标准自回归交叉熵损失进行训练,并自回归地生成文本/翻译。
四、视频处理
4.1 什么是视频处理?
在计算机视觉(CV)和人工智能(AI)的研究领域,视频处理涉及自动分析视频数据,以理解和解释时间与空间特征。视频数据是随时间变化的图像序列,其中的信息在空间和时间上都已数字化。这使我们能够对视频中每一帧的内容进行详细的分析和操作。
得益于深度学习(DL)和人工智能的飞速发展,视频处理在当今技术驱动的世界中变得越来越重要。传统上,深度学习研究主要集中在图像、语音和文本上,但视频数据由于其庞大的规模和复杂性,为研究提供了独特而宝贵的机会。YouTube等平台上每天上传数百万视频,使得视频数据成为一个丰富的资源,推动了人工智能研究并促成了突破性的应用。
4.2 视频处理的应用
-
监控系统: 视频处理在公共安全、犯罪预防和交通监控中扮演着关键角色。它能够自动检测可疑活动,帮助识别个人,并提高监控系统的效率。
-
自动驾驶: 在自动驾驶领域,视频处理对于导航、障碍物检测和决策过程至关重要。它使自动驾驶汽车能够理解周围环境,识别路标,并对不断变化的环境做出反应,从而确保安全高效的运输。
-
医疗保健: 视频处理在医疗保健领域具有重要应用,包括医学诊断、手术和患者监测。它有助于分析医学图像,在外科手术过程中提供实时反馈,并持续监测患者以检测任何异常或紧急情况。
4.3 视频处理中的挑战
-
计算需求: 实时视频分析需要大量的处理能力,这在开发和部署高效视频处理系统时构成了重大挑战。高性能计算资源对于满足这些需求至关重要。
-
存储要求: 高分辨率视频会产生大量数据,导致存储挑战。高效的数据压缩和管理技术对于处理海量视频数据是必需的。
-
隐私和伦理问题: 视频处理,尤其是在监控和医疗保健领域,涉及处理敏感信息。确保隐私和解决与视频数据滥用相关的伦理问题是必须仔细管理的CROCIAL考虑因素。
4.4 视频处理任务
视频处理是人工智能和计算机视觉中一个动态且至关重要的领域,它提供了众多应用并带来了独特的挑战。随着深度学习的进步和视频数据可用性的增加,其在现代技术中的重要性持续增长。在接下来的部分中,我们将更深入地探讨深度学习在视频处理中的应用。你将探索最先进的模型,包括3D CNNs和Transformer。
此外,我们将涵盖各种任务,如对象跟踪、动作识别、视频稳定、字幕生成、摘要和背景减除。这些主题将使你全面了解深度学习模型如何应用于不同的视频处理挑战和应用程序。
4.5 视频 Vision Transformer (ViViT)
摘自论文的摘要如下
我们提出了纯 Transformer 视频分类模型,借鉴了此类模型在图像分类中的最新成功经验。我们的模型从输入视频中提取时空标记,然后通过一系列 Transformer 层进行编码。为了处理视频中遇到的长序列标记,我们提出了几种高效的模型变体,它们分解了输入的空间和时间维度。尽管基于 Transformer 的模型只有在可用大量训练数据集时才有效,但我们展示了如何在训练过程中有效正则化模型并利用预训练图像模型,从而能够在相对较小的数据集上进行训练。我们进行了彻底的消融研究,并在 Kinetics 400 和 600、Epic Kitchens、Something-Something v2 和 Moments in Time 等多个视频分类基准测试中取得了最先进的结果,超越了基于深度 3D 卷积网络的现有方法。为了促进进一步研究,我们在 https://github.com/google-research/scenic 发布了代码。
五、LLM大语言模型的短板
5.1 大语言模型
除了优化模型结构,研究者发现扩大模型规模也可以提高性能。在保持模型结构以及预训练任务基本不变的情况下,仅仅通过扩大模型规模就可以显著增强模型能力,尤其当规模达到一定程度时,模型甚至展现出了能够解决未见过复杂问题的涌现(Emergent Abilities)能力。例如 175B 规模的 GPT-3 模型只需要在输入中给出几个示例,就能通过上下文学习(In-context Learning)完成各种小样本(Few-Shot)任务,而这是 1.5B 规模的 GPT-2 模型无法做到的。
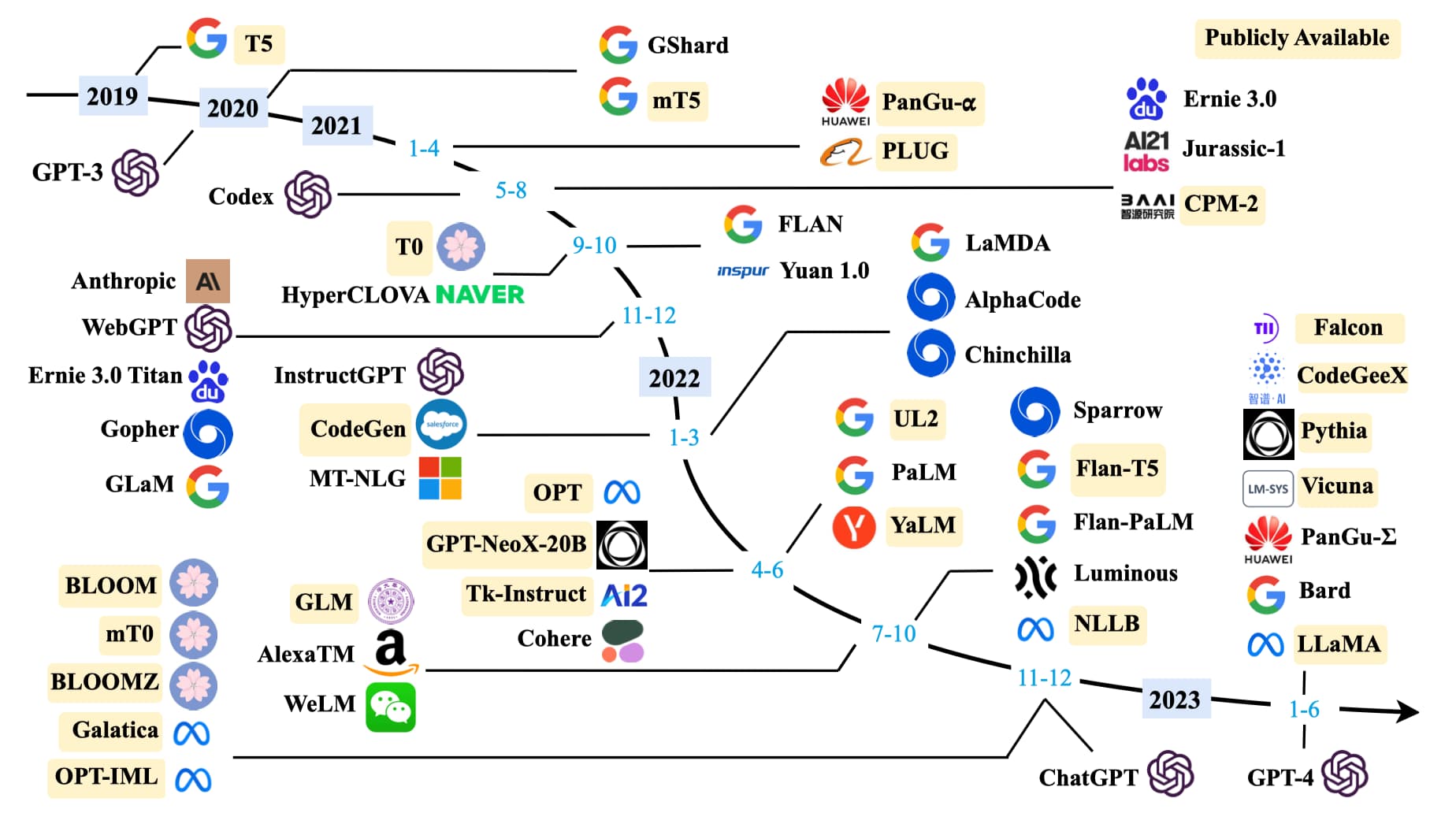
在规模扩展定律(Scaling Laws)被证明对语言模型有效之后,研究者基于 Transformer 结构不断加深模型深度,构建出了许多大语言模型,如图所示。
一个标志性的事件是 2022 年 11 月 30 日 OpenAI 公司发布了面向普通消费者的 ChatGPT 模型(Chat Generative Pre-trained Transformer),它能够记住先前的聊天内容真正像人类一样交流,甚至能撰写诗歌、论文、文案、代码等。发布后,ChatGPT 模型引起了巨大轰动,上线短短 5 天注册用户数就超过 100 万。2023 年一月末,ChatGPT 活跃用户数量已经突破 1 亿,成为史上增长最快的消费者应用。
5.2 为什么视频模型没有相同的效果
语音与文字都属于自然语言的的范畴,都符合统计学原理,并遵循一定的概率分布。通过学习这个概率分布,计算机就算没有理解文字或音频的含义,但是还是可以精确的预测下一个词是什么。
但是视频的处理要比语音和文字复杂的多,虽然深度学习可以精确的标记出画面的哪些区域是花,草,树木,行人,道路等等,但是它因为不了解物理世界的运行逻辑,无法真正理解画面的含义,所以AI生成的视频会有众多的瑕疵,比如:手臂会穿越身体;人会漂浮在草丛中等等。
世界本身是不可预测的,模型却试图填补每一块缺失的信息。
5.3 世界模型
强化学习之父Richard Sutton老爷子加入了Yann LeCun行列,认为当前的LLM路线行不通,不可能通向AGI
图灵奖获得者Richard Sutton,强化学习之父最新采访,认为当前热门的大语言模型是一条死胡同。他的核心观点是,LLMs 的架构从根本上缺乏从实际互动(on-the-job)中持续学习的能力。无论我们如何扩大其规模,它们本质上仍然是在模仿人类数据,而不是通过与世界直接互动来理解世界并实现目标
Sutton 预言,未来将出现一种新的 AI 架构,它能够像人类和所有动物一样,在与环境的持续互动中实时学习,无需经历独立的“训练阶段”。这种基于经验的、持续学习的新范式,一旦实现,将使我们当前依赖大规模静态数据集训练 LLMs 的方法变得过时,权力向更高级智能形式的转移是必然趋势。
世界模型与传统AI范式(如监督学习、强化学习)的根本区别在于其从被动响应到主动预测的转变。传统的监督学习模型,其核心任务是学习一个从输入到输出的映射函数,例如图像分类或语音识别。这些模型在处理一个输入时,并不会考虑这个输入在时间序列上的前后关系,也不会预测未来的状态。它们只是根据训练数据中学到的模式,对当前的输入做出一个判断。而世界模型则不同,它关注的是时间序列上的动态变化,致力于理解“世界为什么会这样变化”。
六、AI Agent
6.1 人类与AI协同的三种模式
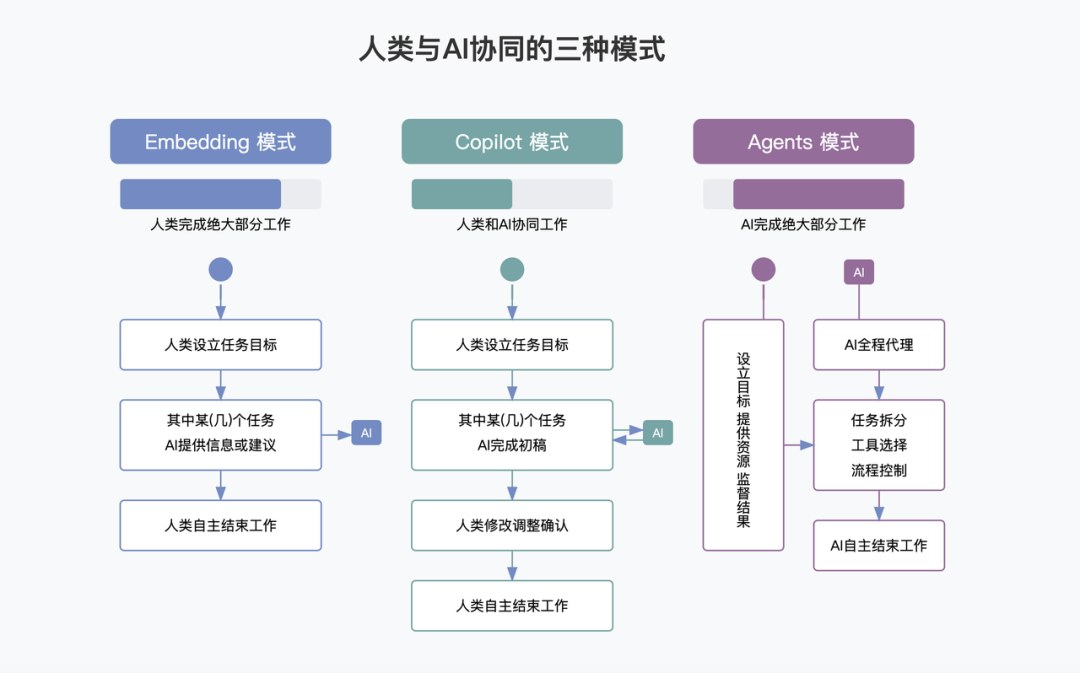
6.2 MCP协议
MCP 可以看作是 AI 应用程序的 "USB-C端口"。就像 USB-C 为连接设备与各种外设提供了标准化方式,MCP为 AI 模型连接不同数据源和工具提供了标准化方法。
通俗来讲,MCP让AI不再局限于“聊天“,而是长出“手”和“脚”,真正具备动手查询,汇报,执行等能力。彻底改变人与软件的交互方式,不用学习应用软件的复杂操作,一个简单的指令,就可以让计算机完成指定的工作。

六、总结
经过上述知识,我们可以了解到LLM大语言模型在以下方面可以达到甚至超越人类:
1.自然语言处理:大模型在文本分类,词性标注,命名实体识别,文本生成,抽取答案,文本翻译、自动摘要等文本(或语音)处理或文本(或语音)生成任务具有卓越表现(例如:聊天,数学,代码,文档分析,风险评估,报告生成等等)
2.机器视觉:如物体识别,对象跟踪、动作识别、图像分析,视频稳定、字幕生成、摘要和背景减除等视频(或图片)处理有超越人类的表现,但是在视频生成有明显的瑕疵。
3.软件交互:使用自然语言去操作软件,无需复杂操作。
随笔
有些人会觉得llm大模型只会“聊天”,感觉很鸡肋。其实人类通过自己的视觉,触觉,嗅觉,味觉,听觉去了解这个世界,用语言去描述它,并用文字的形式记录下来。自然语言(文字和语音)包含着人类对这个世界的理解,并且自然语言符合统计学的规律,很适合大模型的学习和模拟。
世界具有不可预测性,但是抽象出来的的文字,是可以被预测的。
人类与计算机的交互方式,从一开始的二进制机器码,汇编语言,C/C++, JAVA, Python,再到自然语言。(操作语言越来越简单,学习成本也会越来越低)
llm大模型出现是革命性质的,它改变了人和计算机的交互方式,降低了计算机的使用门槛。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号