
图解KV Cache
LLM中下一个token预测
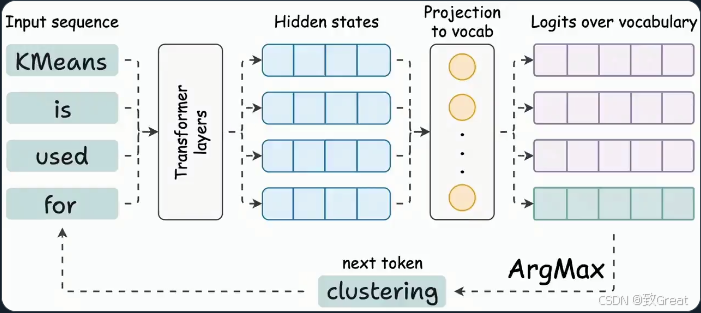
Transformer 生成隐藏状态
- Transformer 为所有 token 生成隐藏状态。
- 隐藏状态被投射到词汇空间。
- 最后一个 token 的 logits 用于生成下一个 token。
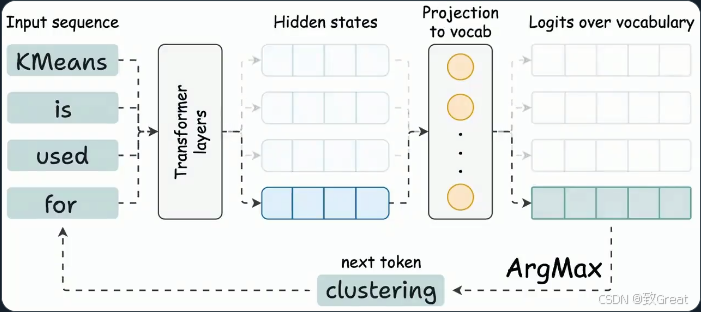
生成新 token 的输出
- 要生成新 token,我们只需要最新 token 的隐藏状态。
- 其他隐藏状态不需要重新计算。
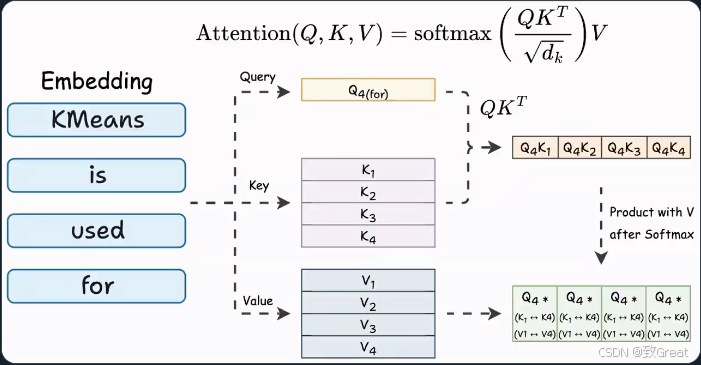
注意力机制中的计算
在注意力阶段(Softmax计算):
- Query-Key-Value的最后一列计算涉及:
- 最后一个查询向量。
- 所有Key向量。
此外:
- 最终注意力结果的最后一行涉及:
- 最后一个Query向量。
- 所有Key和Value向量。
我们可以发现
要生成新 token,网络中的每个注意操作只需要:
- 最后一个Token的Query向量。
- 所有Key和Value向量。
KV 缓存的核心思想
当我们生成新 token 时:
- 用于所有先前 token 的 KV 向量不会改变。
- 因此,我们只需要为前一步生成的 token 生成一个 KV 向量。
- 其余的 KV 向量可以从缓存中检索,节省计算和时间。
这称为 KV 缓存!
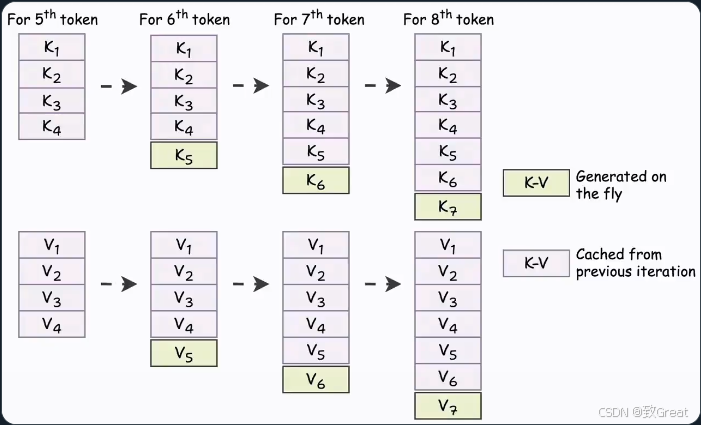
具体工作流程如下:
- 为前一步生成的标记生成 QKV 向量。
- 从缓存中获取所有其他 KV 向量。
- 计算注意力。
尽管 KV 缓存加速了推理,但它也占用了大量内存。例如:
- Llama3-70B 参数下:
- 总层数 = 80
- 隐藏大小 = 8k
- 最大输出大小 = 4k
- 每个Token在 KV 缓存中占用约 2.5 MB。
- 4k 个Token将占用 10.5 GB。
简单来说,用了KV Cache可以支持更多用户,提高效率 →但是同时也会占用更多内存,以空间换时间。
整体动态图如下:

代码实现
class CachedSelfAttention(nn.Module): def __init__(self, embed_dim, num_heads): super().__init__() self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = embed_dim // num_heads # 定义投影矩阵 self.q_proj = nn.Linear(embed_dim, embed_dim) self.k_proj = nn.Linear(embed_dim, embed_dim) self.v_proj = nn.Linear(embed_dim, embed_dim) self.out_proj = nn.Linear(embed_dim, embed_dim) # 初始化缓存 self.cache_k = None self.cache_v = None def forward(self, x, use_cache=False): batch_size, seq_len, embed_dim = x.shape # 计算Q、K、V q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) # 如果使用缓存且缓存存在,则拼接历史KV if use_cache and self.cache_k is not None: k = torch.cat([self.cache_k, k], dim=-2) v = torch.cat([self.cache_v, v], dim=-2) # 如果使用缓存,更新缓存 if use_cache: self.cache_k = k self.cache_v = v # 计算注意力分数(注意这里的k是包含历史缓存的) attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5) attn_probs = F.softmax(attn_scores, dim=-1) # 应用注意力权重 output = attn_probs @ v output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim) return self.out_proj(output) def reset_cache(self): """重置缓存,用于新序列的生成""" self.cache_k = None self.cache_v = None
总结
在Transformer架构中,KV Cache是一种关键的性能优化机制。它通过缓存已计算的Key和Value矩阵,避免在自回归生成过程中重复计算,从而显著提升推理效率。这种机制类似于人类思维中的短期记忆系统,使模型能够高效地利用历史信息。
KV Cache 作为 Transformer 架构中的关键性能优化机制,通过巧妙的缓存设计显著提升了模型的推理效率。其工作原理主要体现在三个核心维度:
- 首先,在计算效率方面,KV Cache通过缓存已处理token的Key和Value表示,有效消除了重复计算的开销。这种机制使得模型在自回归生成过程中能够实现2-3倍的速度提升,显著降低了计算资源的浪费,为大规模应用部署提供了可能。
- 其次,在上下文处理能力上,KV Cache通过维持完整的长序列表示,确保了模型对上下文的准确理解。这种机制增强了注意力机制的效果,使模型能够精确检索历史信息,从而保证了长文本生成时的语义连贯性和质量稳定性。
- 最后,在动态特性方面,KV Cache展现出优秀的自适应能力。系统能够根据输入序列的长度动态调整缓存大小,灵活应对不同场景的需求,尤其适合实时交互式对话等动态应用场景。
KV 缓存是加速 LLM 推理的关键技术之一。通过减少重复计算,它显著提升了生成速度,但也带来了内存占用的挑战。理解其工作原理有助于更好地优化和部署大语言模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号