一文看懂DeepSpeed:用ZeRO训练大模型原理解析及参数含义解释
实际训练中Deepspeed参数配置ZeRO各stage含义是什么,offload以及gradient checkpoint是如何起作用的,本篇基于ZeRO不同stage含义,以及实践时参数含义来阐述Deepspeed原理。
这几天在做大模型的微调,发现几乎所有都用到了deepspeed,这里给大家提供一个ChatGLM2在ptuning模式下的参数配置文件示例:
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \ --train_path data/spo_0.json \ --model_name_or_path ChatGLM2-6B \ --per_device_train_batch_size 1 \ --max_len 1560 \ --max_src_len 1024 \ --learning_rate 1e-4 \ --weight_decay 0.1 \ --num_train_epochs 2 \ --gradient_accumulation_steps 4 \ --warmup_ratio 0.1 \ --mode glm2 \ --train_type ptuning \ --seed 1234 \ --ds_file ds_zero2_no_offload.json \ --gradient_checkpointing \ --show_loss_step 10 \ --pre_seq_len 16 \ --prefix_projection True \ --output_dir ./output-glm2
这个文件中大部分参数都比较熟悉,但是关于ds_zero各stage的的参数配置、offload/upload、gradient checkpoint这一块感觉还不太了解,所以这里解释这三个问题:
1. ZeRO的含义、不同stage的区别以及原理详解
2. offload的参数含义
3. gradient checkpoint含义,以及其是如何起作用的
一、ZeRO原理
1.含义
ZeRO是一种针对大规模分布式深度学习的新型内存优化技术。
在DeepSpeed下,ZeRO训练支持了完整的ZeRO Stages1, 2和3,以及支持将优化器状态、梯度和模型参数从GPU显存下沉到CPU内存或者硬盘上,实现不同程度的显存节省,以便训练更大的模型。
2.不同stage的区别
- Stage 1: 把 优化器状态(optimizer states) 分片到每个数据并行的工作进程(每个GPU)下
- Stage 2: 把优化器状态(optimizer states) + 梯度(gradients)分片到每个数据并行的工作进程(每个GPU)下
- Stage 3: 把优化器状态(optimizer states) + 梯度(gradients) + 模型参数(parameters)分片到每个数据并行的工作进程(每个GPU)下
3. 具体示例
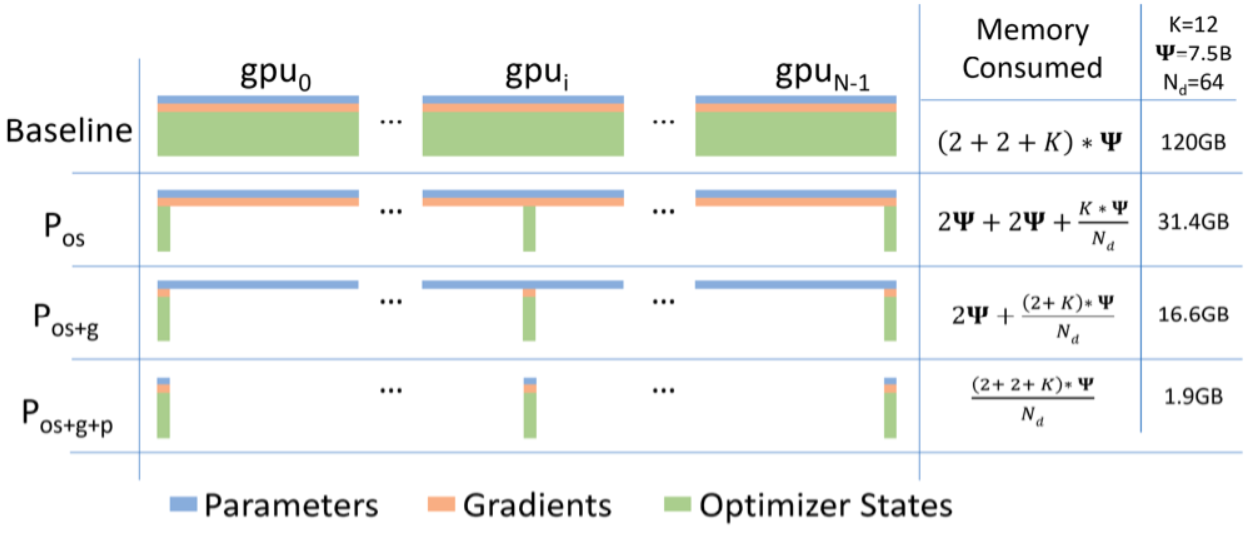
假如GPU卡数为N=64,Ψ是模型参数,假设Ψ=7.5B,假设使用Adam优化器,K是优化器的超参,在64个GPU下K=12,则:
- 如果不用ZeRO,需要占用120GB的显存,A100最大才80GB,塞不下
- 如果用ZeRO Stage1,则占用31.4GB,A100 40GB或者80GB卡都能跑,单机多卡或多机多卡训练的通信量不变
- 如果用ZeRO Stage2,则占用16.6GB,大部分卡都能跑了,比如V100 32GB,3090 24GB,通信量同样不变
- 如果用ZeRO Stage3,则占用1.9GB,啥卡都能跑了,但是通信量会变为1.5倍
备注:
- 优化器状态 一般包含FP32 Gradient、FP32 Variance、FP32 Momentum、FP32 Parameters
- 梯度和模型参数 一般会用FP16就够了,所以占用大头一般是优化器相关的
所以根据实际硬件资源,选择适合Stage策略即可。如果遇到要跑更大的模型,比如想在3090 24GB下跑13B模型,可能Stage3也OOM跑不起来,此时可以开启Optimizer Offload和Param Offload即可跑起来,但相应的性能会受影响。
二、offload的参数含义
offload指将数据、梯度、优化器状态等下沉到CPU内存或硬盘上
三、gradient checkpoint阐释
1. 原理
- 原理:在反向传播时重新计算深度神经网络的中间值(而通常情况是在前向传播时存储的)
- 这个策略是用时间(重新计算这些值两次的时间成本)来换空间(提前存储这些值的内存成本)
2. 理论基础介绍——神经网络是如何使用内存的
神经网络使用的总内存基本上是两个部分的总和,包括静态内存和动态内存:
- 第一部分是模型使用的静态内存。尽管 PyTorch 模型中内置了一些固定开销,但总的来说几乎完全由模型权重决定。而如今,在生产中使用的现代深度学习模型的总参数在100万到10亿之间。作为参考,一个带 16GB GPU 内存的 NVIDIA T4 的实际限制大约在1-1.5亿个参数之间。
- 第二部分是模型的计算图所占用的动态内存。在训练模式下,每次通过神经网络的前向传播都为网络中的每个神经元计算一个激活值,这个值随后被存储在所谓的计算图中。必须为批次中的每个单个训练样本存储一个值,因此数量会迅速的累积起来。总成本取决于模型大小和批处理大小,并设置适用于您的GPU内存的最大批处理大小的限制。一开始存储激活的原因是,在反向传播期间计算梯度时需要用到激活。
3. gradient checkpoint是如何起作用的
- 背景:大型模型在静态和动态方面都很耗资源。首先,它们很难适配 GPU,而且哪怕你把它们放到了设备上,也很难训练,因为批处理大小被迫限制的太小而无法收敛。
- 工作原理:梯度检查点(gradient checkpointing)的工作原理是从计算图中省略一些激活值(由前向传播产生,其中这里的”一些“是指可以只省略模型中的部分激活值,折中时间和空间,即前向传播的时候存一个节点释放一个节点,空的那个等需要用的时候再backword的时候重新计算)。这减少了计算图使用的内存,降低了总体内存压力(并允许在处理过程中使用更大的批次大小)。
- pytorch中对应的函数与实现原理:PyTorch 通过`torch.utils.checkpoint.checkpoint`和`torch.utils.checkpoint.checkpoint_sequential`提供梯度检查点,根据官方文档的 notes,它实现了以下功能,在前向传播时,PyTorch 将保存模型中的每个函数的输入元组。在反向传播过程中,对于每个函数,输入元组和函数的组合以实时的方式重新计算,插入到每个需要它的函数的梯度公式中,然后丢弃(显存中只保存输入数据和函数)。网络计算开销大致相当于每个样本通过模型前向传播开销的两倍。
三、ZeRO工作流程
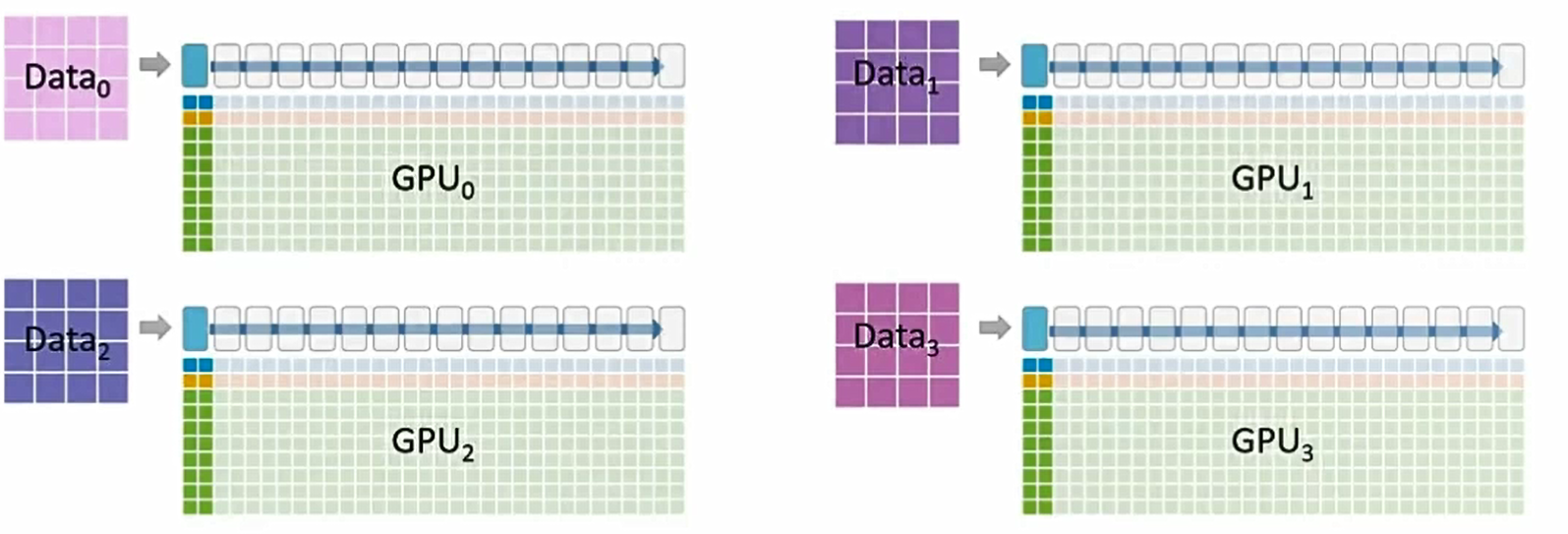
ZeRO 4路数据并行训练
使用:P_os+g+p(优化器状态(optimizer states) +梯度(gradients) +模型参数(parameters))
这是一个16层的transformer模型(类似于Turning NLR或BERT large)

这里有一个很大的训练数据集,我们可以使用4个GPU同时训练。

我们将使用4路数据并行和ZeRO P_os+g+p 内层优化,每一个GPU将优化同一个模型的不同数据

每一个单元 代表相对应的transformer层
代表相对应的transformer层 的GPU内存使用情况
的GPU内存使用情况
这第一行是fp16版本的模型参数
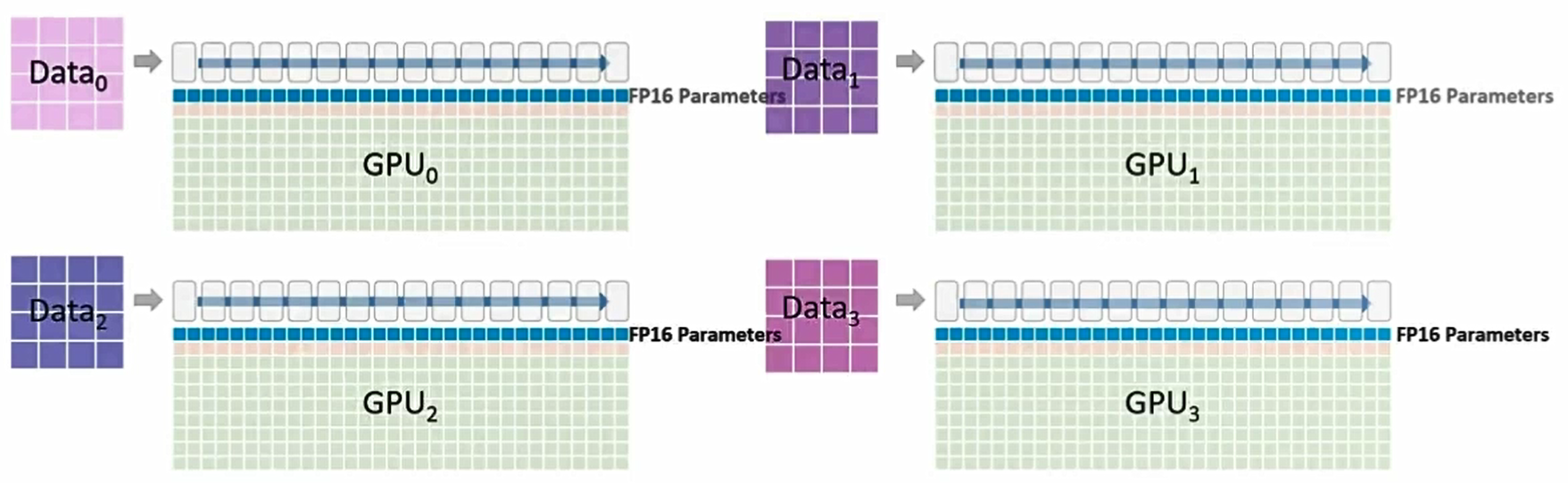
第二行是fp16版本的梯度,它们将被用于反向传播更新权重

最后一大块内存由优化器(Optimizer)占用。该内存块要等到 fp16 梯度计算完成后才会被使用
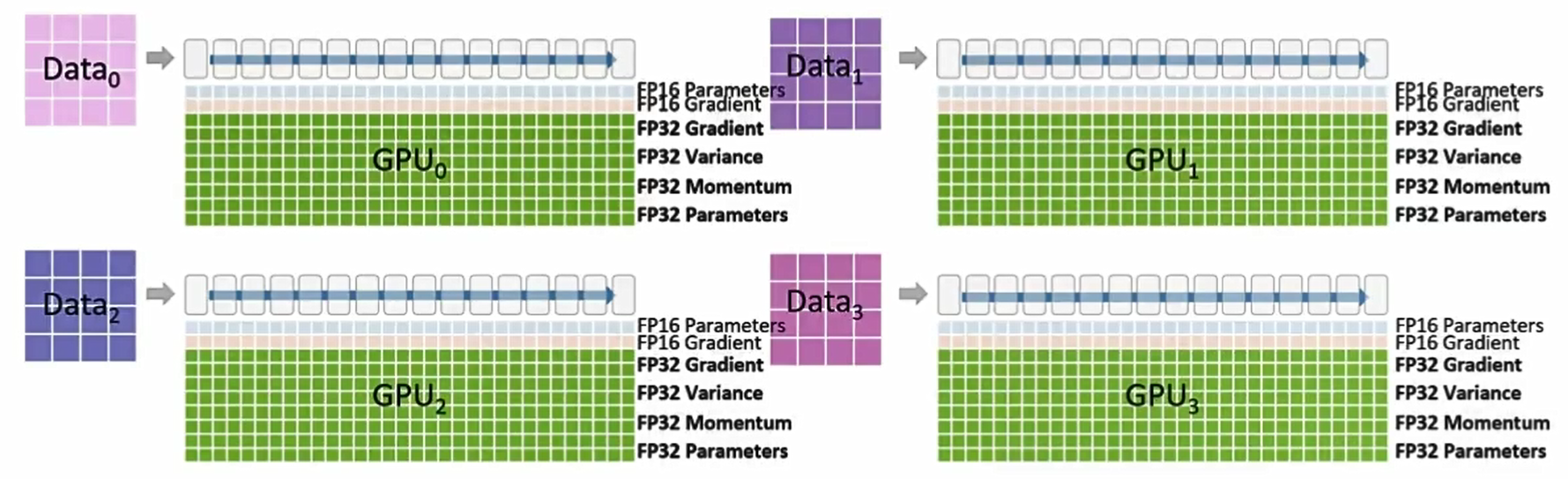
我们还需要一个缓冲区来保存每个 Transformer 层的所有激活。(例如注意力头、MLP 等)
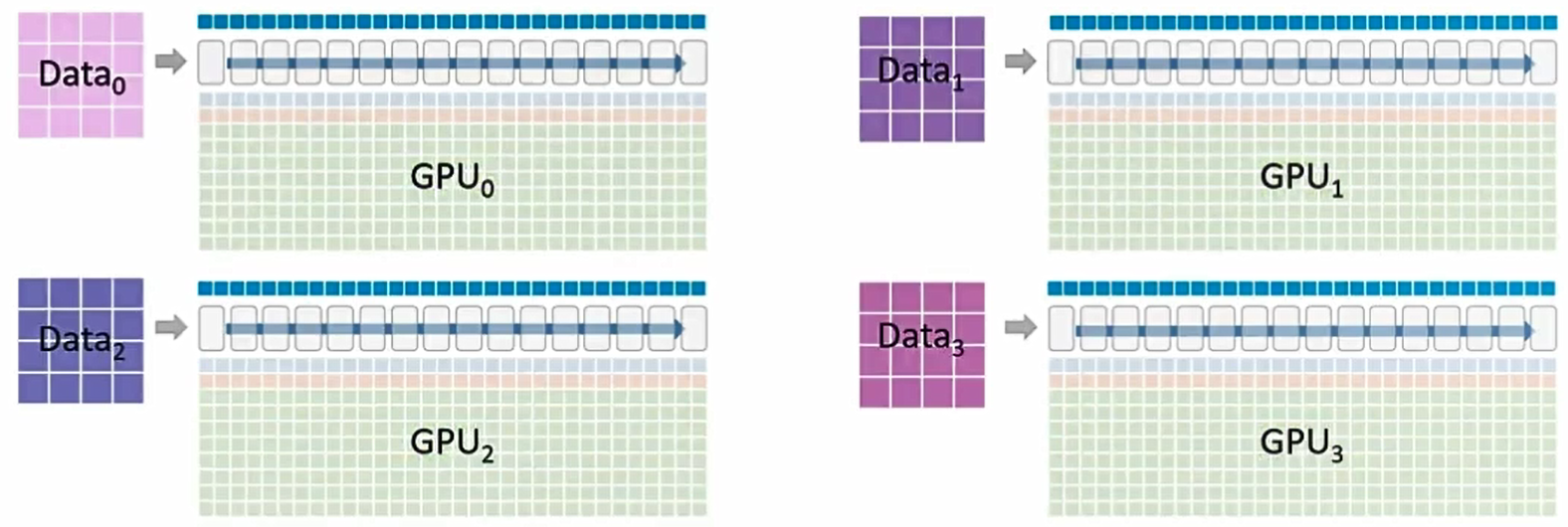
每个 GPU 负责最终模型的一个部分。在4路数据并行的基础上,还使用了 ZeRO P_os+g+p和梯度累积(Gradient accumulation)技术。
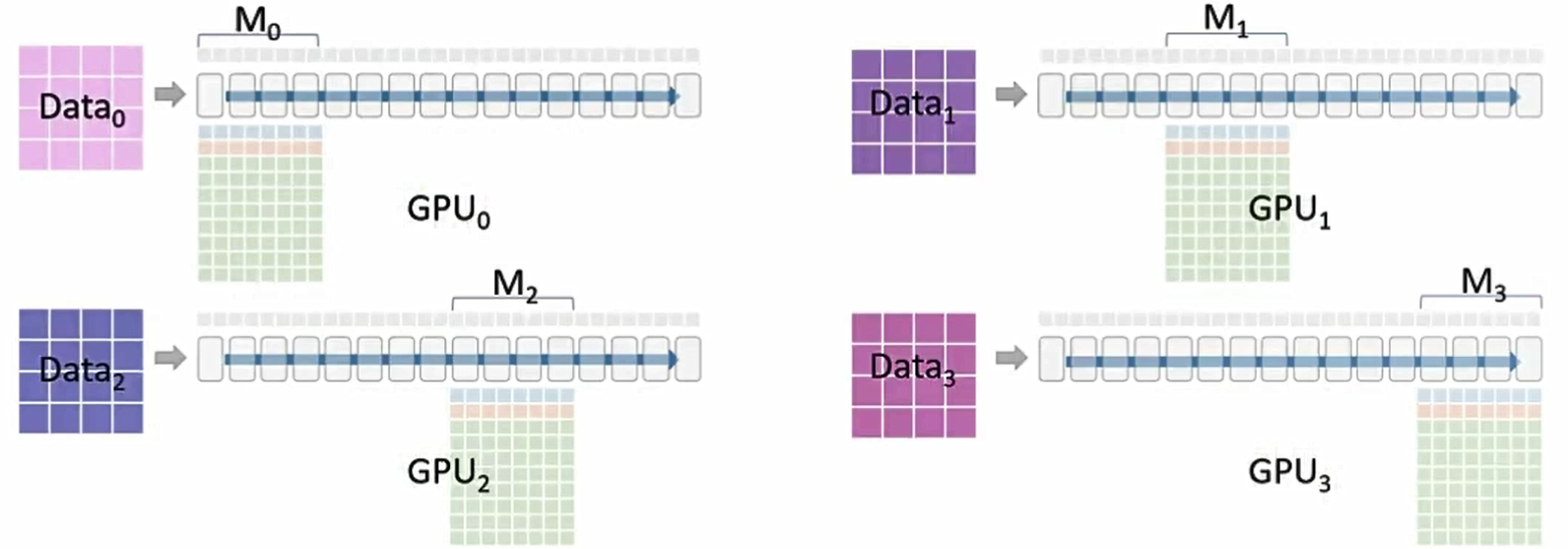
让我们来看一个采用 P_os+g+p(优化器状态 + 梯度 + 参数)的分布式训练周期。
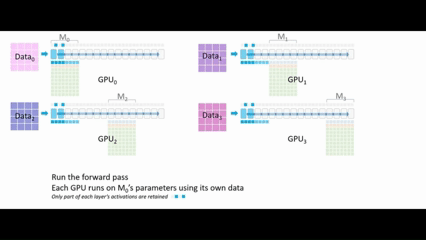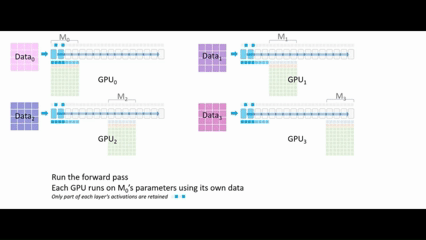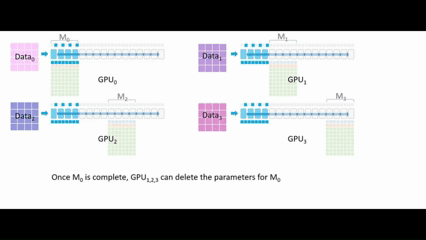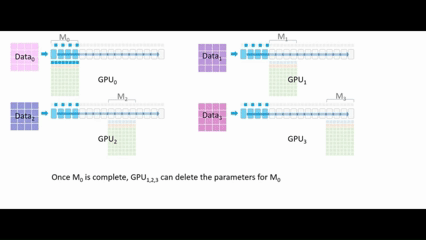
最初只有 GPU₀ 拥有模型 M₀ 的参数,它会将这些参数广播到 GPU₁、GPU₂、GPU₃。所有的GPU都会拥有 M₀ 的参数,GPU₁、GPU₂、GPU₃将这些参数存储在临时缓冲区中。

执行前向传播,每一个GPU使用自己的数据运行M₀ 的参数,每层仅保留部分激活值 ,一旦 M₀的计算完成,GPU₁、GPU₂、GPU₃ 就可以删除M₀的参数。
,一旦 M₀的计算完成,GPU₁、GPU₂、GPU₃ 就可以删除M₀的参数。
GPU₁ 广播 M1的参数。所有配备 M1参数的 GPU 可以继续执行前向传播,一旦所有 GPU 都完成了M1的相关运算,GPU0、GPU2、GPU3 就可以删除 M1的参数。

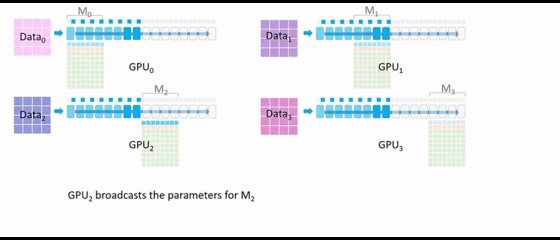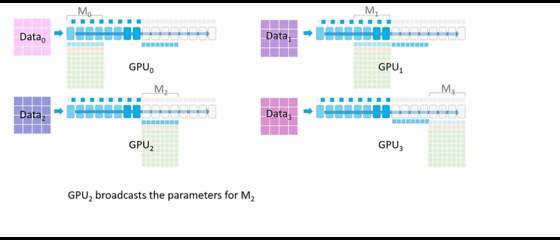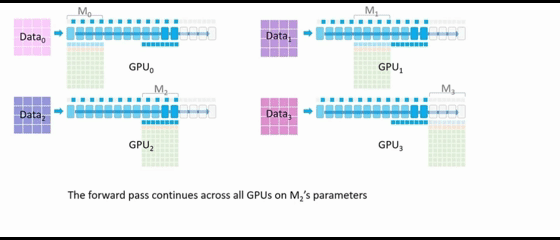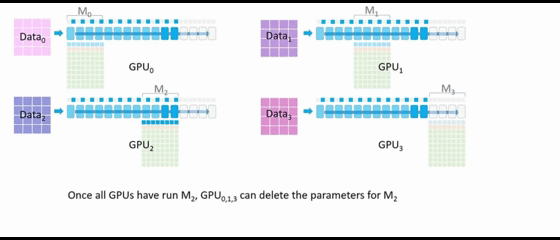
GPU2广播 M2的参数。所有配备 M2参数的 GPU 可以继续执行前向传播,一旦所有 GPU 都完成了M2的相关运算,GPU0、GPU1、GPU3 就可以删除 M2的参数。
GPU3广播 M3的参数,所有配备 M3参数的 GPU 可以继续执行前向传播。前向传播已完成,每个 GPU 会针对其各自的数据集计算损失。

反向传播开始
GPU 0、1、2 会在 Data0、1、2 上保存 M3 梯度的临时缓冲区。
反向传播在 M3 上进行,M3 的激活值从保存的部分激活值中重新计算得到。
GPU0、1、2 将各自的 M3 梯度传递给 GPU3。GPU3 执行梯度累积,并持有针对所有数据的最终 M3 梯度。
GPU0、1、2 删除各自的临时 M3 梯度和参数,所有 M3 的激活值均被删除。

GPU2 将 M2的参数传递给 GPU0、GPU1、GPU3,以便它们能够运行反向传播并计算M2的梯度。
GPU0、GPU1、GPU3 使用临时缓冲区来存储M2的梯度。反向传播在M2上继续进行,M2的激活值从保存的部分激活值中重新计算得出。
GPU0、GPU1、GPU3 将各自的M2梯度传递给 GPU2,GPU2 执行梯度累积并持有针对所有数据的最终M2梯度。
GPU0、GPU1、GPU3 可以删除各自的临时M2梯度和参数,所有M2的激活值也都被删除。


GPU0 将 M0 的参数传递给 GPU1、GPU2、GPU3,以便它们能够运行反向传播并计算 M0 的梯度。
GPU1、GPU2、GPU3 使用临时缓冲区来存储 M0 的梯度。
反向传播在 M0 上继续进行,M0 的激活值从保存的部分激活值中重新计算得出。
GPU1、GPU2、GPU3 将各自的 M0 梯度传递给 GPU0,GPU0 执行梯度累积并持有针对所有数据的最终 M0 梯度。
GPU1、GPU2、GPU3 删除各自的临时 M0 梯度和参数,所有 M0 的激活值也都被删除。

现在每个 GPU 都拥有了各自对应的梯度(从所有数据集累积而来),我们可以据此计算更新后的参数了。
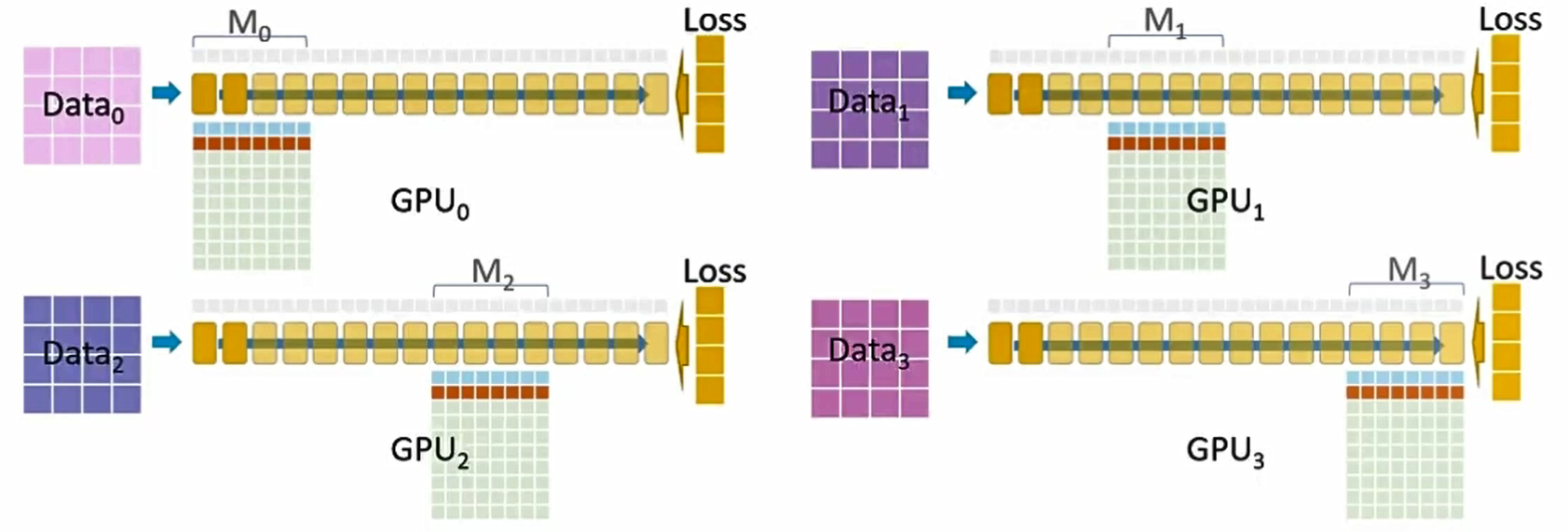
优化步骤在每个 GPU 上并行开始。
优化器生成单精度(fp32)的更新后模型权重,这些权重会被转换为半精度(fp16)。半精度(fp16)权重将作为下一轮迭代的模型参数,训练迭代完成!

参考:https://zhuanlan.zhihu.com/p/674745061

 浙公网安备 33010602011771号
浙公网安备 33010602011771号