
使用deepseek-ocr.rs在Windows本地运行DeepSeek‑OCR/PaddleOCR‑VL/DotsOCR,并启用CUDA与OPENAI HTTP API、在Cherry Studio中调用
前言
本文包含AI生成的代码。
我日常写文档时,经常有OCR书本公式的需求。且由于Deepseek不支持多模态,日常使用也只能将带复杂公式的题目手动进行OCR后再提问。
最开始,我找到了Umi-OCR(https://github.com/hiroi-sora/Umi-OCR)。它可以调用支持公式识别的Pix2Text引擎,提供了方便好用的GUI,并支持二维码生成识别等功能。然而,它的公式识别准确率较低,且这个项目似乎已经不再更新,不支持新的OCR引擎,让我不得不寻找替代。
之前看到有群友推荐PaddleOCR‑VL(https://aistudio.baidu.com/paddleocr),我测试后发现可以完美满足我的要求。这是一个开源OCR模型,且官方网站只要注册账号就有每日3000次的API额度,非常良心。但我发现网页使用时会出现较长的排队,有时候还会无法使用,所以我又开始研究本地部署。
DeepSeek‑OCR的跑分成绩似乎比PaddleOCR‑VL高一些,但我笔记本的显存只有6G,还是不挑战更高规格的模型了。
PaddleOCR‑VL官方仓库(https://huggingface.co/PaddlePaddle/PaddleOCR-VL)提供的部署方法是Docker+Python+Transformers,然而在测试后我发现这玩意对Windows的支持似乎不是很好,且Docker和我的Vmware会打架。
可惜的是,似乎没有什么支持PaddleOCR‑VL的GUI。我尝试了几个WebUI,还是被各种报错劝退了。
最后,我发现了deepseek-ocr.rs(https://github.com/TimmyOVO/deepseek-ocr.rs)这个项目。得益于它更便捷的部署流程,我很快就把它运行了起来。在实现大部分官方功能之外,它额外提供了一个OPENAI API的服务端,这使得我能直接在Cherrystudio中调用它,使用起来非常。
构建带CUDA的deepseek-ocr.rs
deepseek-ocr.rs官方提供的Windows预构建版本并不支持CUDA,需要自行构建。经过测试,在使用CPU运行时,我的首字时间高达134秒,速度5token/秒,完全无法使用。
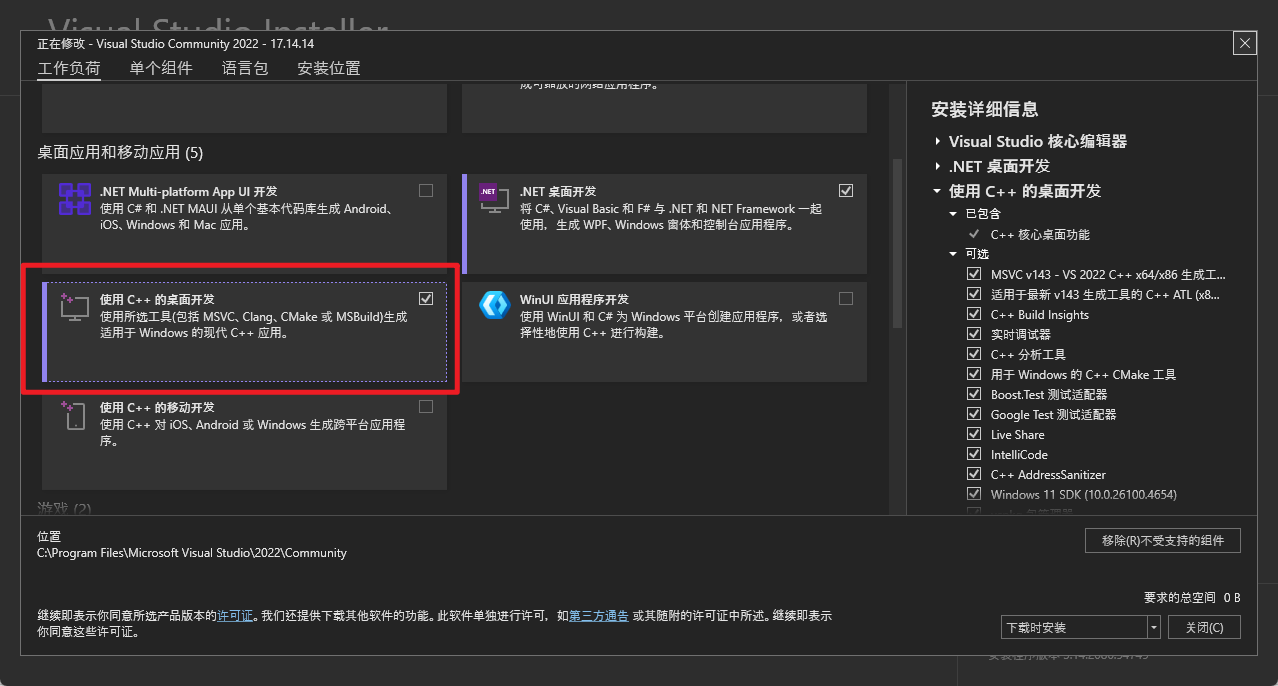
首先,我们需要安装Visual Studio,并选择"使用C++的桌面开发"。这里我使用的是2022版本,选择如下图所示。
安装并配置Git(https://git-scm.com/install/windows)、Rust(https://rust-lang.org/tools/install/)。
安装CUDA,我选择的是12.8(https://developer.nvidia.com/cuda-12-8-1-download-archive?target_os=Windows&target_arch=x86_64)。
打开终端,运行如下指令
git clone https://github.com/TimmyOVO/deepseek-ocr.rs.git
cd deepseek-ocr.rs
cargo fetch
在开始菜单栏搜索“x64 Native Tools Command Prompt for VS 2022”,打开。使用cd命令转到deepseek-ocr.rs文件夹。
cd /D D:\deepseek-ocr.rs
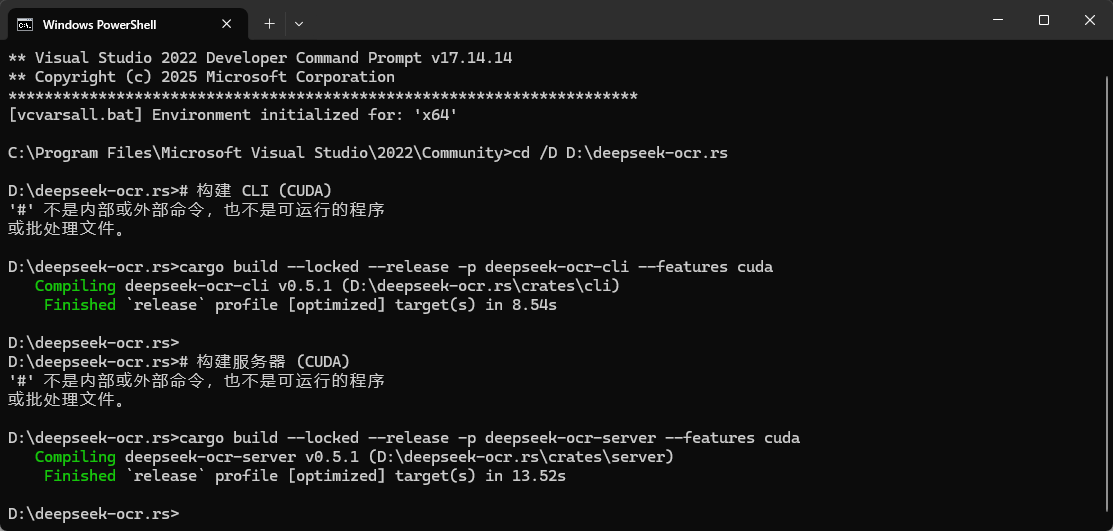
运行如下指令。
# 构建 CLI (CUDA)
cargo build --locked --release -p deepseek-ocr-cli --features cuda
# 构建服务器 (CUDA)
cargo build --locked --release -p deepseek-ocr-server --features cuda
出现下图中提示则为编译成功,大约需要几分钟。这里我编译过了,直接提示完成。
编译后的exe文件在deepseek-ocr.rs\target\release目录。
运行并配置
复制两个exe文件到新的文件夹。打开终端,运行如下命令。
.\deepseek-ocr-server.exe --host 0.0.0.0 --port 8000 --config ".\config.toml"
默认会开始下载Deepseek-OCR,但我们要用的是PaddleOCR‑VL,所以按Ctrl+C终止。
可以看到,目录下生成了一个config.toml,打开它,修改如下行。
[models]
active = "paddleocr-vl"
[inference]
device = "cuda"
max_new_tokens = 1000000
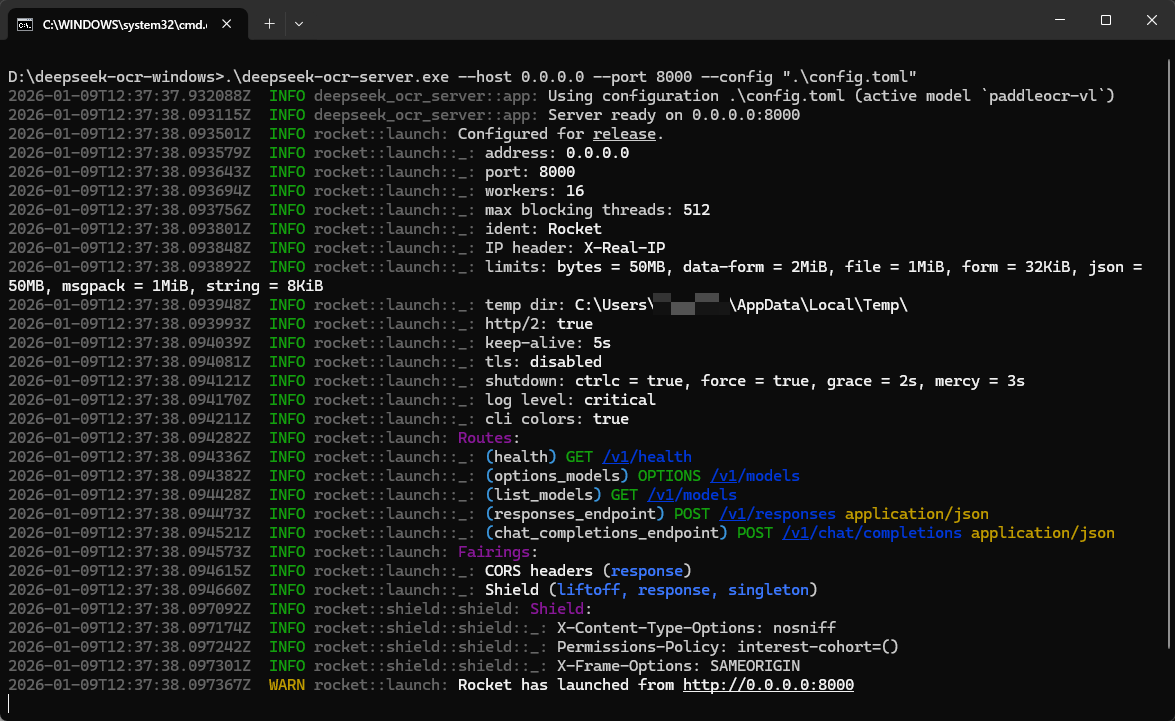
再次运行上面的命令,等待下载模型。最后可以看到成功运行,如下图所示。
配置CherryStudio
打开,点击左下角设置,点击添加。
名字随便取,提供商类型选择OpenAI。
API密钥随便填,API地址填写http://127.0.0.1:8000/v1/。
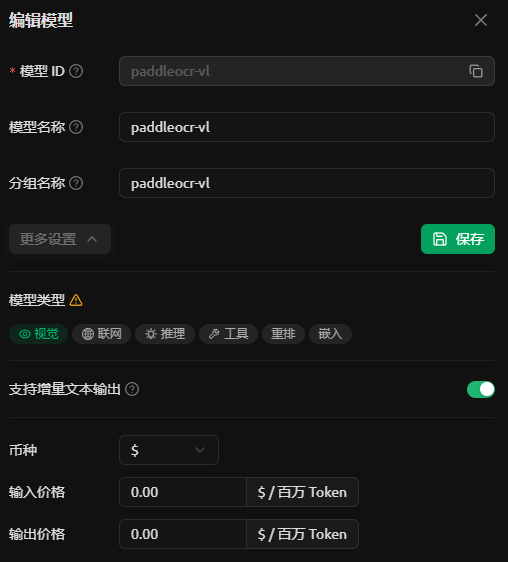
添加模型,命名为paddleocr-vl,点击模型旁边的齿轮,选择“更多设置”,点亮“视觉”。如下图所示。
设置完成如下图所示。
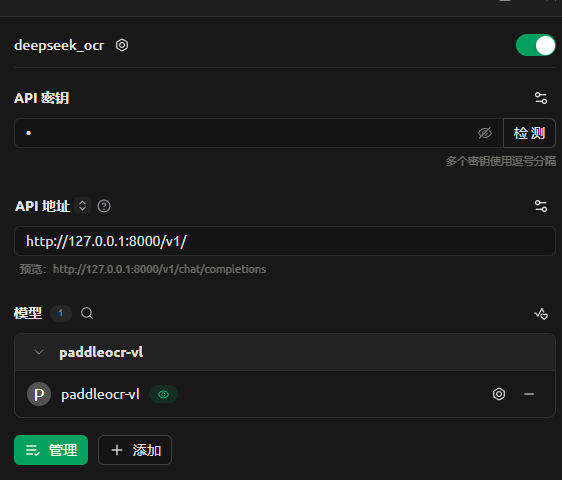
回到“助手”界面,新建一个助手,修改系统提示词为“Convert this receipt to markdown.”,默认模型改为上面设置的模型。
发送图片进行测试,可以看到页面的OCR的结果如下。
| 原图 | 结果 |
|---|---|
 |
 |
结语
所以我为什么不用带多模态的LLM呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号