

深度学习与人类语言处理-语音识别(part3)
上节回顾深度学习与人类语言处理-语音识别(part2),这节课我们接着看seq2seq模型怎么做语音识别

上节课我们知道LAS做语音识别需要看完一个完整的序列才能输出,把我们希望语音识别模型可以在听到声音的时候就进行输出,一个直观的想法就是用单向的RNN,我们来看看CTC是怎么做的
CTC
根据上面说的,在线语音识别,模型在听到声音的时候就需要输出,我们看下使用RNN的基本架构
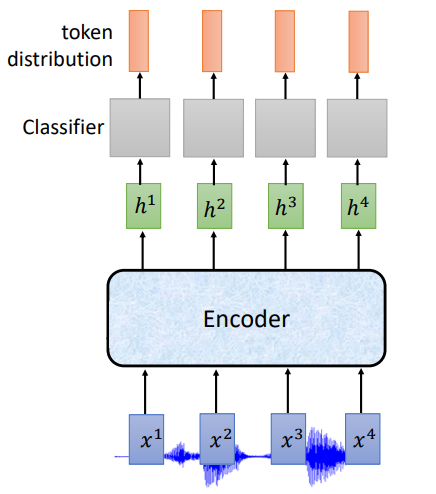
input: 长度为T的声学特征
Encoder:单向RNN
ouput:长度为T的token,每一个输出位置对应词典中每个词的概率
但是对每一个输入的声学特征不总是会有对应的输出token,每一声学特征所包含的信息是非常少的,所以CTC在输出的词汇表中加入了一个标记\(\phi\),表示什么也没有,词典大小变为V+1
ouput:长度为T的token,其中包括 𝜙, 需要合并重复的token,移除𝜙
举例来说:

但是这里我们会发现一个问题,对于一个真实的输出,\(\phi\) 的位置有很多种情况,举个栗子
真实的输入输出:
input:\(x1,x2,x3,x4\) ; ouput: 好棒
可能的输出:
好好棒\(\phi\), \(\phi\)好好棒, 好好棒棒 , 好棒\(\phi\phi\), 好\(\phi\)棒……
所以CTC在训练的时候需要穷举所有可能组合,这个我们后面再讲
CTC work 吗?

从这个结果我们可以看到,CTC的表现很惨,在没有使用其他方法处理的情况下已经坏掉了,比LAS坏了很多,但是在加入语言模型调整后,已经可以work了
issue
那CTC存在什么问题呢?
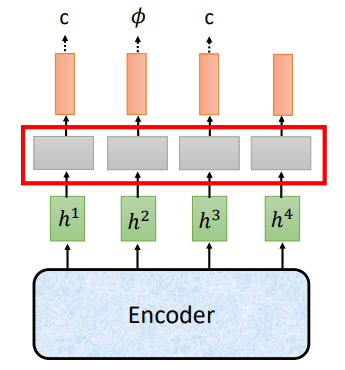
- 每一步的输出是独立的
假设前三个输入都属于“c”的声学特征,但是模型在看到第一个输入就输出了“c“,第二步输出\(\phi\), 第三步又输出了”c",那最终的输出就是“cc”,显然不对啊
RNN Transducer (RNN-T)
在介绍RNN-T之前,我们先看下RNA(Recurrent Neural Aligner),不是核糖核酸啊
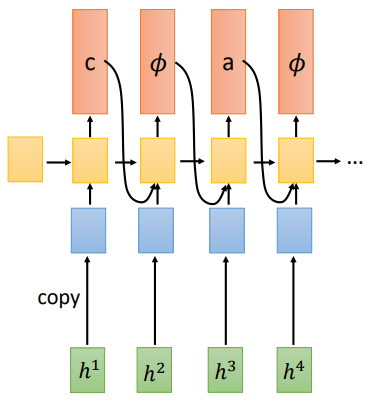
- CTC Decoder(把CTC的softmax看做Decoder)
CTC的每一个输出是相互独立的
- RNA(把softmax换成RNN)
在从上面的图可以看到,RNA就是增加了输出之间的依赖,把CTC的线性分类层换成RNN就可以了
目前为止我们看到的都是吃一个输入,输出一个token,那有没有可能吃一个输入,输出多个token呢?举例来说,输入为“th”,只有一个音,但是需要两个输出。当然也可以把“th”作为一个单独的token加入到词典
RNN-T就是为了解决这个问题

每次看到一个\(h^t\),输出对应的token,直到对应输入被解码完了,就输出一个\(\phi\),告诉模型给我下一个输入,所以一共会有T个\(\phi\) 会被输出
RNN-T和CTC有同样的组合问题:
假设“好棒”有四个声学特征:
𝜙1 好 𝜙2 𝜙3 𝜙4 𝜙5 棒 𝜙6
𝜙1 𝜙2 𝜙3 𝜙4 𝜙5 好 棒 𝜙6
RNN-T同样会在训练时穷举所有的组合
实际上RNN-T训练了一个独立的RNN网络,输出会被接到RNN,\(\phi\)会被忽略
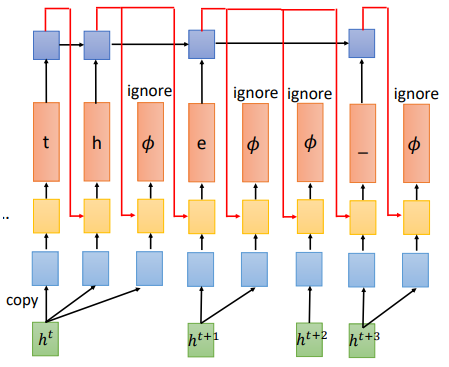
为什么需要额外的RNN呢?
-
这个RNN相当于一个语言模型,只接受token作为输入。所以可以直接先用大量文字训练RNN
-
刚才说到输出中\(\phi\) 的位置有很多种可能,如果RNN把\(\phi\)也作为输入,在对所有组合进行训练是很困难的
Neural Transducer
前面的几个模型每次都是输入一个,Neural Transducer 一次接受窗口范围的输入
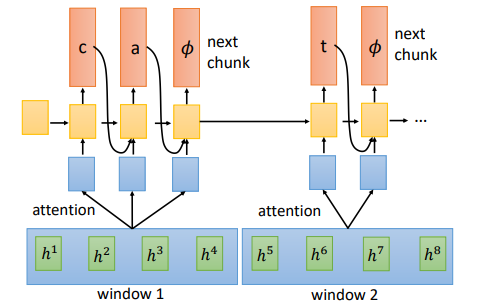
对Encoder的输出,每次取一个窗口作为Decoder的输入,先做一下attention然后开始输出,每次输出\(\phi\) 就会读下一个窗口
那窗口的长度应该设置多长呢?文献中实验了不同的长度
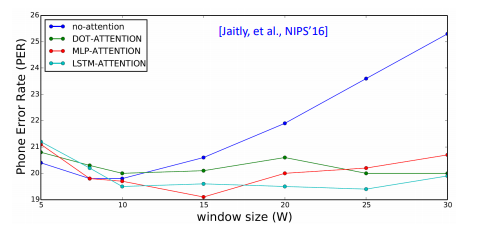
在没有用attention时,长度变长后结果就坏掉了
使用attention后,发现长度变化对结果影响不是很大
MoChA: Monotonic Chunkwise Attention
在Neural Transducer 每次窗口长度是固定的,在MoChA中设计了动态的窗口
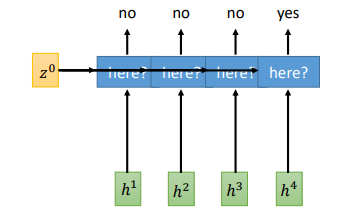
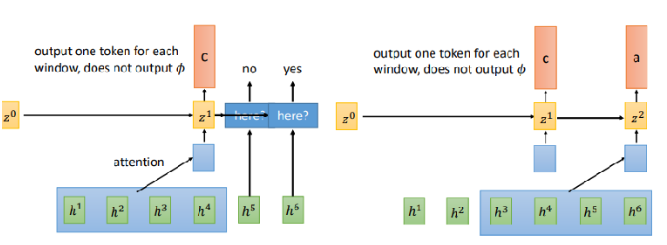
首先使用attention决定窗口应该放在哪里,然后对每一个窗口输出一个token,注意这里不需要\(\phi\) 了,然后移动找下一个窗口
Summary
总结一下语音识别中用到的几个seq2seq模型
- LAS:就是seq2seq
- CTC:decoder 是 linear classifier 的 seq2seq
- RNA:decoder 是 RNN 的seq2seq,输入一个就要输出一个
- RNN-T: decoder 是 RNN ,输入一个就要输出多个的 seq2seq
- Neural Transducer:每次输入 一个 window 的 RNN-T
- MoCha: window 移动伸缩自如的 Neural Transducer
references:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号