

scrapy框架爬取17173游戏
1.任务:
scrapy框架爬取17173游戏排行榜,内容包括游戏名称、票数,并保存
2.爬虫代码 -- a17173.py
1 import scrapy 2 import json 3 4 class A17173Spider(scrapy.Spider): 5 name = '17173' 6 allowed_domains = ['17173.com'] 7 start_urls = ['http://top.17173.com/default-index.html?oper_status=1&game_frame=0&game_type=0&game_theme=0&game_feature=0&page={}'.format(num) for num in range(1,6)] 8 def parse(self, response): 9 newgame_ranks = response.xpath('//div[@class="main-c1"]//div[@class="c1"]/em/text()').extract() 10 newgame_names = response.xpath('//div[@class="main-c1"]//div[@class="con"]/a/text()').extract() 11 newgame_votess = [x.strip() for x in response.xpath('//div[@class="main-c1"]//div[@class="item-in"]/div[@class="c3"]/text()').extract()] 12 hotgame_ranks = response.xpath('//div[@class="main-c2"]//div[@class="c1"]/em/text()').extract() 13 hotgame_names = response.xpath('//div[@class="main-c2"]//div[@class="con"]/a/text()').extract() 14 hotgame_votess = [x.strip() for x in response.xpath('//div[@class="main-c2"]//div[@class="item-in"]/div[@class="c3"]/text()').extract()] 15 16 for newgame_rank, newgame_name, newgame_votes, hotgame_rank, hotgame_name, hotgame_votes in zip(newgame_ranks, newgame_names, newgame_votess, hotgame_ranks, hotgame_names, hotgame_votess): 17 yield { 18 'newgame_rank' : newgame_rank, 19 'newgame_name': newgame_name, 20 'newgame_votes': newgame_votes, 21 'hotgame_rank': hotgame_rank, 22 'hotgame_name': hotgame_name, 23 'hotgame_votes': hotgame_votes 24 } 25 print(type(hotgame_votess))
3.pipelines.py
1 # Define your item pipelines here 2 # 3 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 4 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 5 6 7 # useful for handling different item types with a single interface 8 from itemadapter import ItemAdapter 9 10 11 class GamePipeline: 12 def open_spider(self,spider): 13 self.filename1 = open('新游期待榜.txt','w',encoding='utf-8') 14 self.filename2 = open('热门游戏榜.txt','w',encoding='utf-8') 15 16 17 def process_item(self, item, spider): 18 info1 = item['newgame_rank'] + '\t' + item['newgame_name'] + '\t' + item['newgame_votes'] + '\n' 19 self.filename1.write(info1) 20 self.filename1.flush() 21 22 info2 = item['hotgame_rank'] + '\t' + item['hotgame_name'] + '\t' + item['hotgame_votes'] + '\n' 23 self.filename2.write(info2) 24 self.filename2.flush() 25 26 return item 27 28 29 def close_spider(self,spider): 30 self.filename1.close() 31 self.filename2.close()
4.结果
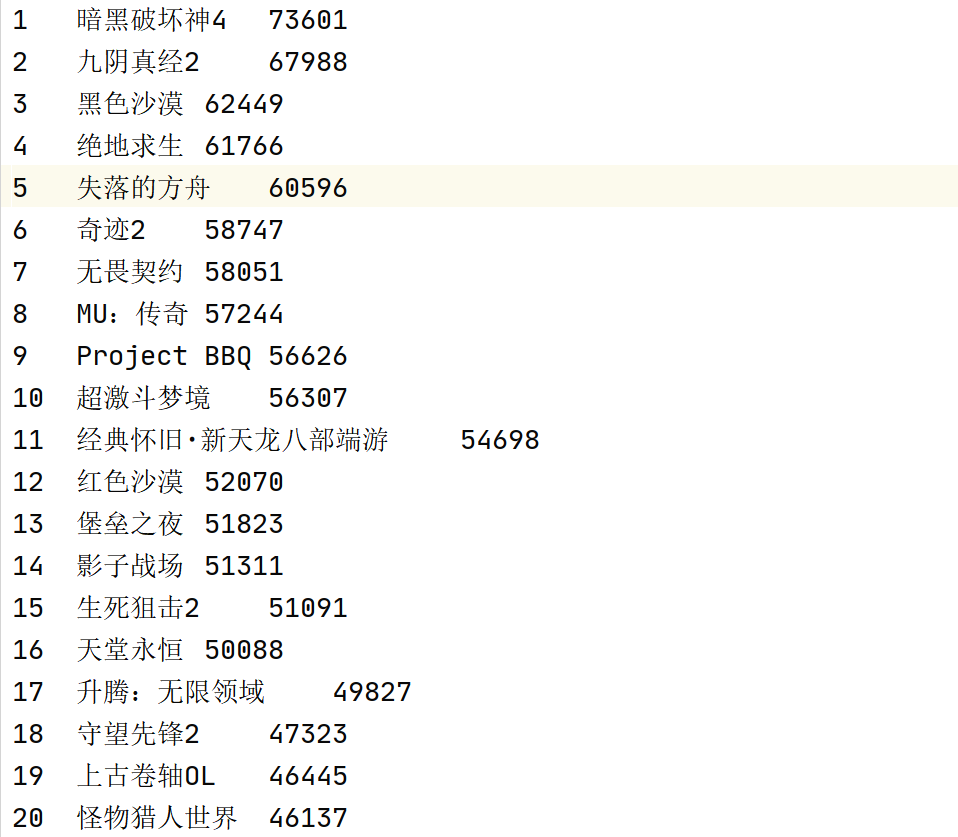
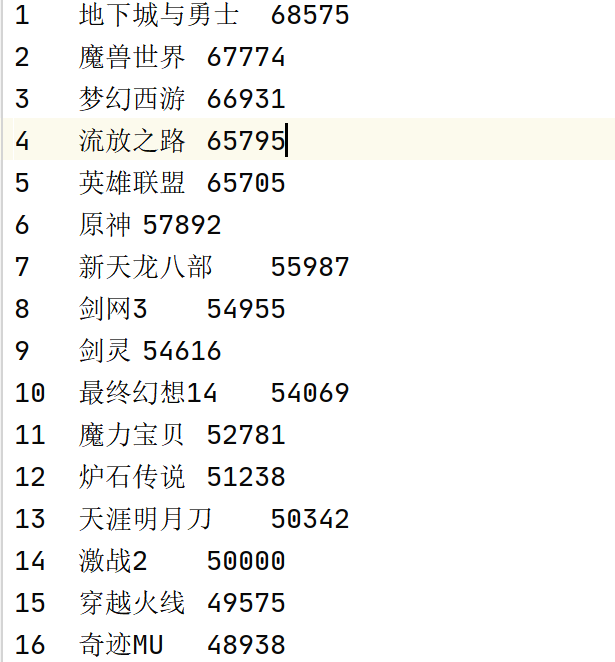

 浙公网安备 33010602011771号
浙公网安备 33010602011771号