浅析自定义/review命令与Cursor内置Agent Review代码审核功能效果对比与工作区别
之前我有整理一个自定义的代码审核命令,然后 Cursor 也有内置 Agent Review 功能,最近在使用的时候发现:我自定义命令基本可以把问题检查出来,且会给修改建议,及优先修复建议(基本给的都挺准的),但是同样的情况使用内置 Agent Review 功能却审查不出问题来。
比如有个需求我使用 Agent Review 功能进行代码审核,它没检查出当前我这个需求代码变更的有什么问题,反而给的是2个之前有变更的文件(非本次改动的)
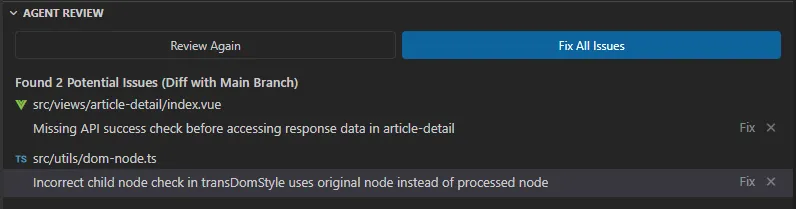
而我使用我自定义的代码审核命令 /review 基本审核出了问题,且给修改建议,及优先修复建议(因为有些是 AI 给的建议,并非问题)
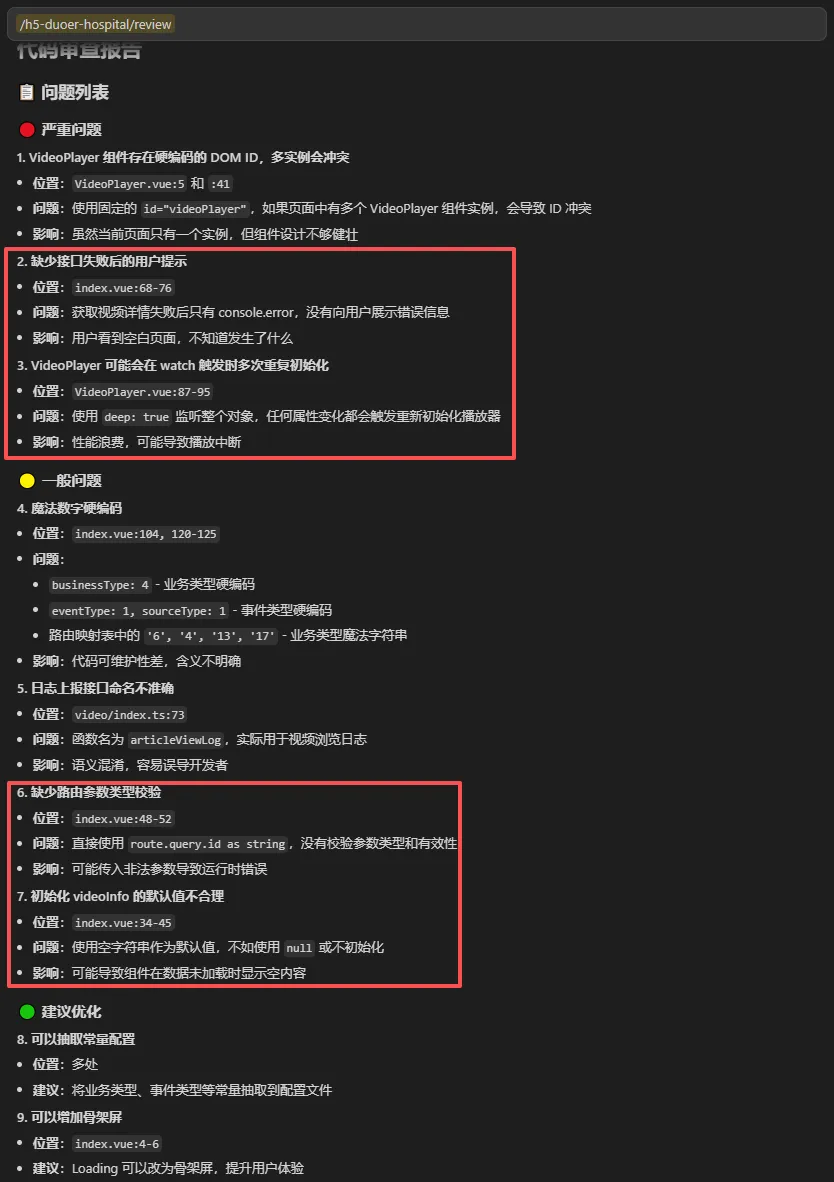
给的优先修复建议也很准确(高优先级的确实是需要优化的,中低的,基本就是可改可不改的)

效果区别如此之大,所以我想了解一下我自定义代码审核命令与 Cursor 内置 Agent Review 功能的区别。
一、工作方式对比
1、自定义 /review 命令(在对话中) - 工作方式:
你的对话 → AI 看到本次需求的所有代码 → 按 review.md 审查 → 输出报告
特点:
- ✅ 有会话记忆:AI 知道你刚才做了什么需求、改了哪些代码
- ✅ 范围精确:只审查本次对话中产生/修改的代码
- ✅ 严格遵循规则:完全按照你的 review.md 清单执行
- ✅ 上下文完整:理解需求背景,能发现"逻辑不符合需求"的问题
比喻:就像一个全程旁观的同事,看着你写完代码,知道你要做什么,然后拿着清单仔细检查
2、Cursor 内置 Agent Review - 工作方式:
点击 Review 按钮 → Agent 扫描工作区/Git diff → 用内置逻辑分析 → 输出报告
特点:
- ❌ 没有会话记忆:不知道你的需求背景,只看到代码变更
- ❌ 范围不精确:可能审查了 Git diff 中的所有文件(包括无关改动)
- ⚠️ 规则不完全遵循:可能参考你的 review.md,但也混合了内置规则
- ❌ 缺少需求上下文:只能发现"代码本身的问题",无法判断"是否符合需求"
比喻:就像一个新来的审查员,没看到你开发过程,只拿到最终的代码 diff,用通用标准检查
3、了解了两者的工作方式,所以可以知道为什么会出现我遇到的情况?
(1)问题 1:Agent Review 没发现自定义命令发现问题
可能原因:
- 缺少需求上下文:用 /review 时,AI 知道需求是什么,能发现"逻辑不符合需求"的问题
- 审查深度不同:Agent Review 可能只做表面检查(语法、格式),而 /review 会深入分析业务逻辑
(2)问题 2:Agent Review 审查了不相关的文件
可能原因:
- 基于 Git diff:Agent Review 看到了工作区的所有未提交改动,或者最近的改动(那2个文件确实是最近改动的)
- 范围失控:可能之前改过那 2 个文件但没提交,Agent Review 把它们也纳入了审查范围
4、本质总结
| 对比维度 | /review 命令 | Agent Review |
|---|---|---|
| 知道需求吗? | ✅ 知道(会话上下文) | ❌ 不知道 |
| 审查范围 | 本次需求代码 | Git diff 或全项目 |
| 规则执行 | 严格按 review.md | 内置规则为主 |
| 适用场景 | 需求验收审查 | 代码健康扫描 |
简单说:自定义 /review 是有针对性的专项审查,而 Agent Review 是普适性的扫描工具。前者更精准,后者更广泛。
二、Cursor 内置 Agent Review 的工作原理
1、工作步骤
(1)第一步 - 收集"案卷材料":Agent Review 启动时会自动收集这些信息
输入材料:
├─ Git 变更(git diff):最近提交/未提交的代码改动
├─ 当前打开的文件:你正在编辑的文件
├─ 最近修改的文件:最近几分钟/几小时改过的文件
└─ 项目配置:eslint、prettier、tsconfig 等规则
关键点: 它不知道你的需求背景、会话历史、为什么要这样改!
(2)第二步 - AI "阅读"代码:AI 会像阅读理解考试一样分析代码
分析维度:
├─ 语法层面:有没有明显的语法错误、类型错误
├─ 代码风格:变量命名、缩进、是否符合项目规范
├─ 常见问题:
│ ├─ 未使用的变量/导入
│ ├─ 潜在的空指针异常
│ ├─ 异步代码的错误处理
│ └─ 性能问题(如循环中的重复计算)
└─ 最佳实践:React/Vue 官方推荐的写法
(3)第三步 - 对照"检查清单":有一套内置的通用审查清单(如下简化版)
| 检查项 | 具体内容 | 例子 |
|---|---|---|
| 类型安全 | TypeScript 类型是否完整 | any 类型是否过多 |
| 错误处理 | try-catch、?.、?? 等 | API 调用是否有错误处理 |
| 性能隐患 | 不必要的重渲染、内存泄漏 | useEffect 缺少清理函数 |
| 代码复杂度 | 函数是否过长、嵌套是否过深 | 超过 50 行的函数 |
| 安全问题 | XSS、注入攻击风险 | 直接使用 dangerouslySetInnerHTML |
| 可维护性 | 命名是否清晰、注释是否必要 | 变量名叫 data1, temp |
(4)第四步-生成报告:AI 按严重程度分类问题
(5)第五步-呈现给你:生成自然语言的审查报告,包括:问题位置(文件名 + 行号)、问题描述等
2、Agent Review 的 AI 模型在做什么?
# 伪代码示例
def agent_review(files):
# 1. 静态分析
ast_tree = parse_code(files) # 解析成抽象语法树
# 2. 模式匹配
issues = []
for node in ast_tree:
if matches_pattern(node, KNOWN_PROBLEMS):
issues.append(node)
# 3. AI 推理
context = build_context(files, project_config)
ai_suggestions = llm.analyze(
code=files,
context=context,
rules=BUILT_IN_RULES # 内置规则库
)
# 4. 生成报告
return format_report(issues + ai_suggestions)
关键: 它使用的是预训练的通用知识 + 内置规则库,而不是你的会话历史!
三、核心区别
1、审查范围不同
(1)自定义 /review 命令 = "剧组导演审查"
- 只审查"这场戏"相关的内容(本次会话中的代码变更)
- 了解完整剧情(需求背景、历史问题、修复过程)
- 针对性强:知道你要拍什么、为什么这样拍
(2)Cursor Agent Review = "质检部抽查"
- 可能审查打开的文件、最近修改的文件,或 git 变更
- 不清楚"这场戏"的背景,只看代码本身
- 通用性强:按标准流程检查代码质量
2、上下文理解不同
(1)/review 命令:
- 知道你在修复视频播放器
- 重点审查 VideoPlayer.vue、index.vue 等变更文件
- 结合需求检查:watch 逻辑是否正确、nextTick 用法、条件渲染等
(2)Agent Review:
- ❌ 不知道这次会话做了什么
- ❓ 可能看到你打开了 vant-override.scss(最近查看的文件)
- 🔍 按通用标准检查:发现样式代码有小问题就报告了
3、审查维度不同
(1)/review 命令有定制化的审查清单
✓ 功能正确性(符合需求、边界处理)
✓ 代码质量(命名、职责单一、重复代码)
✓ Vue 规范(组件拆分、props、响应式)
✓ 性能考量(重复渲染、竞态条件、内存泄漏)← 重点!
✓ 安全检查
(2)Cursor Agent Review 使用内置的通用标准,可能更关注:代码风格一致性、潜在的 bug 模式、类型安全,但不一定针对"本次需求"
4、实际场景对比
假设我这次改动了 3 个文件:
| 工具 | 看到的内容 | 审查重点 |
|---|---|---|
| /review |
✅ 本次会话变更的 3 个文件 ✅ 需求背景:修复黑屏 ✅ 问题历史:DOM 未就绪 |
🔍 watch + nextTick 是否正确 🔍 v-if 条件是否合理 🔍 是否还有其他潜在的时序问题 |
| Agent Review |
❓ 可能包含打开的其他文件 ❌ 不知道需求背景 ❌ 不知道之前有黑屏问题 |
🔍 代码格式是否规范 🔍 有没有明显的语法问题 🔍 类型定义是否完整 |
四、通俗比喻:快递分拣机 vs 人工质检
1、Agent Review = 自动分拣机
输入:一堆包裹(代码文件)
处理:
1. 扫描条形码(代码语法)
2. 测量重量尺寸(代码复杂度)
3. 检测违禁品(明显错误)
4. 按规则分类(严重/一般/建议)
输出:问题清单
特点:
✅ 速度快(几秒钟)
✅ 标准化(按固定规则)
❌ 不懂背景(不知道为什么寄、要送给谁)
❌ 只能发现"表面问题"
2、自定义 /review 命令 = 人工质检员
输入:一堆包裹 + 订单详情(需求背景)
处理:
1. 看订单:客户要寄什么、为什么寄
2. 检查内容:是否符合客户需求
3. 检查包装:是否安全、是否易碎
4. 结合经验:这类包裹常见问题
输出:定制化报告
特点:
✅ 针对性强(结合需求)
✅ 深度分析(理解上下文)
❌ 速度慢(需要读完整个会话)
✅ 能发现"深层问题"
五、最佳实践
1、案例 2:最近需求碰到一个。Agent Review 检测出 3 个问题(2个是不相关的文件,1个是当前修改的文件且确实有问题)

讲的是有个 loading 状态在 catch 里没有重置。但是自定义命令代码审核没有发现这个问题,所以问了下原因

因此我优化下自定义命令,加上 2 个维度和细节
### 1. 功能正确性
- [ ] 代码逻辑是否符合需求描述
- [ ] 边界情况是否已处理
- [ ] 错误处理是否完善
- [ ] catch 块是否有状态恢复(特别是 loading/disabled 状态)
- [ ] 是否有降级方案(避免空白/卡死)
- [ ] UI 状态管理是否健壮
- [ ] Loading/Disabled 状态在所有路径(成功/失败/异常)下都能正确恢复
- [ ] 是否存在"卡死"风险
2、因此最佳实践是:两者结合使用,互相查漏补缺,持续迭代完善自定义的代码审核命令。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号