
redis入门
概述
redis是什么
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI
redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
免费和开源! 当下最热门的NoSQL技术!也被称为结构化数据库
Redis能干什么
-
内存存储 持久化。内存是断电即失的,所以持久化很重要(rdb aof)
-
效率高 可以用于高速缓存
-
发布订阅系统
-
地图信息分析
-
计数器 计时器(浏览量)
-
......
特性
-
多样的数据类型
-
持久化
-
集群
-
事务
-
......
学习中需要用到的东西
-
公众号 狂神说
-
官网
-
中文网
-
github
-
windows版本在Github下载,不推荐。
Redis推荐在Linux服务器上搭建
Linux安装
下载软件包
https://download.redis.io/releases/redis-5.0.14.tar.gz
在ec2上使用curl命令下载
curl -o redis-5.0.14.tar.gz https://download.redis.io/releases/redis-5.0.14.tar.gz
解压安装包
[root@ip-172-31-89-155 opt]# cd /software/
[root@ip-172-31-89-155 software]# ls
redis-5.0.14.tar.gz
[root@ip-172-31-89-155 software]# tar -zxvf redis-5.0.14.tar.gz -C /opt/
[root@ip-172-31-89-155 software]# cd /opt
[root@ip-172-31-89-155 opt]# ls
redis-5.0.14
[root@ip-172-31-89-155 opt]# cd /
[root@ip-172-31-89-155 /]# ln -s /opt/redis-5.0.14/ redis
[root@ip-172-31-89-155 /]# ls -l redis
lrwxrwxrwx. 1 root root 18 Oct 27 06:57 redis -> /opt/redis-5.0.14/
安装redis
#yum install gcc-c++ make
#gcc -v 检查版本
#make
[root@ip-172-31-89-155 redis]# make
cd src && make all
make[1]: Entering directory '/opt/redis-5.0.14/src'
CC Makefile.dep
Hint: It's a good idea to run 'make test' ;)
make[1]: Leaving directory '/opt/redis-5.0.14/src'
[root@ip-172-31-89-155 redis]# make install
cd src && make install
make[1]: Entering directory '/opt/redis-5.0.14/src'
Hint: It's a good idea to run 'make test' ;)
INSTALL install
INSTALL install
INSTALL install
INSTALL install
INSTALL install
make[1]: Leaving directory '/opt/redis-5.0.14/src'
[root@ip-172-31-89-155 redis]#
redis默认的安装目录/usr/local/bin
[root@ip-172-31-89-155 bin]# pwd
/usr/local/bin
[root@ip-172-31-89-155 bin]# ls
redis-benchmark redis-check-rdb redis-sentinel
redis-check-aof redis-cli redis-server
拷贝redis配置文件
[root@ip-172-31-89-155 bin]# mkdir /redis_config
[root@ip-172-31-89-155 bin]# cp /opt/redis-5.0.14/redis.conf /redis_config/
[root@ip-172-31-89-155 bin]# cd /redis_config/
[root@ip-172-31-89-155 redis_config]# ls
redis.conf
启动redis
修改redis.conf
daemonize no --> yes 后台运行
启动redis
cd /usr/local/bin
通过指定的配置文件启动
# ./redis-server /redis_config/redis.conf
15247:C 27 Oct 2022 07:22:15.575 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
15247:C 27 Oct 2022 07:22:15.575 # Redis version=5.0.14, bits=64, commit=00000000, modified=0, pid=15247, just started
15247:C 27 Oct 2022 07:22:15.575 # Configuration loaded
连接测试
连接redis server
# ./redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set name goldtree
OK
127.0.0.1:6379> get name
"goldtree"
127.0.0.1:6379>
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379>
redis连接成功
查看redis进程
# ps -ef|grep redis
root 15248 1 0 07:22 ? 00:00:03 ./redis-server 127.0.0.1:6379
root 15260 1434 0 07:25 pts/0 00:00:00 ./redis-cli -p 6379
root 15450 15428 0 08:10 pts/1 00:00:00 grep --color=auto redis
关闭redis服务
# ./redis-cli -p 6379
127.0.0.1:6379> shutdown
not connected>
# ps -ef|grep redis
root 15260 1434 0 07:25 pts/0 00:00:00 ./redis-cli -p 6379
root 15469 15428 0 08:13 pts/1 00:00:00 grep --color=auto redis
redis-benchmark性能测试
redis-benchmark是一个压力测试工具
官方自带的性能测试工具
redis-benchmark命令参数
Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests>] [-k <boolean>]
-h <hostname> Server hostname (default 127.0.0.1)
-p <port> Server port (default 6379)
-s <socket> Server socket (overrides host and port)
-a <password> Password for Redis Auth
-c <clients> Number of parallel connections (default 50)
-n <requests> Total number of requests (default 100000)
-d <size> Data size of SET/GET value in bytes (default 3)
--dbnum <db> SELECT the specified db number (default 0)
-k <boolean> 1=keep alive 0=reconnect (default 1)
-r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD
Using this option the benchmark will expand the string __rand_int__
inside an argument with a 12 digits number in the specified range
from 0 to keyspacelen-1. The substitution changes every time a command
is executed. Default tests use this to hit random keys in the
specified range.
-P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline).
-e If server replies with errors, show them on stdout.
(no more than 1 error per second is displayed)
-q Quiet. Just show query/sec values
--csv Output in CSV format
-l Loop. Run the tests forever
-t <tests> Only run the comma separated list of tests. The test
names are the same as the ones produced as output.
-I Idle mode. Just open N idle connections and wait.
Examples:
Run the benchmark with the default configuration against 127.0.0.1:6379:
$ redis-benchmark
Use 20 parallel clients, for a total of 100k requests, against 192.168.1.1:
$ redis-benchmark -h 192.168.1.1 -p 6379 -n 100000 -c 20
Fill 127.0.0.1:6379 with about 1 million keys only using the SET test:
$ redis-benchmark -t set -n 1000000 -r 100000000
Benchmark 127.0.0.1:6379 for a few commands producing CSV output:
$ redis-benchmark -t ping,set,get -n 100000 --csv
Benchmark a specific command line:
$ redis-benchmark -r 10000 -n 10000 eval 'return redis.call("ping")' 0
Fill a list with 10000 random elements:
$ redis-benchmark -r 10000 -n 10000 lpush mylist __rand_int__
On user specified command lines __rand_int__ is replaced with a random integer
with a range of values selected by the -r option.
基础知识
redis默认有16个数据库
在redis.conf中
默认使用第0个数据库
可以使用select进行数据库切换
切换到3号数据库
[root@ip-172-31-89-155 bin]# ./redis-cli -p 6379
127.0.0.1:6379> select 3 #切换到3号数据库
OK
127.0.0.1:6379[3]>
127.0.0.1:6379[3]> dbsize #查看DB大小
(integer) 0
127.0.0.1:6379[3]>
127.0.0.1:6379[3]> set name pangjuzi
OK
127.0.0.1:6379[3]> get name
"pangjuzi"
127.0.0.1:6379[3]> dbsize
(integer) 1
127.0.0.1:6379[3]> select 7 #切换到7号数据库
OK
127.0.0.1:6379[7]> dbsize #查看数据库大小
(integer) 0
127.0.0.1:6379[7]>
查看数据库中所有的key
127.0.0.1:6379[3]> keys * #查看所有的key
1) "name"
2) "age"
清空DB有两种方式
#清空当前DB
127.0.0.1:6379[3]> flushdb
OK
#清空所有DB
127.0.0.1:6379[3]> flushall
OK
redis是单线程的
redis是很快的,官方表示,redis是基于内存操作的,CPU不是redis性能瓶颈,redis的瓶颈是机器的内存和网络带宽,因此使用单线程实现。
redis是C语言写的,官方提供的数据为100000+的QPS,完全不比memcache差!
redis为什么单线程还这么快?
-
误区1 :高性能的服务器一定是多线程的
-
误区2 :多线程(CPU上下文会切换)一定比单线程效率高
CPU的速度 > 内存 > 硬盘速度
核心:redis是将所有的数据全部放在内存中的,所以说使用单线程去操作就是效率最高的,多线程的CPU上下问会切换,消耗时间。对于内存系统来说,如果没有上下文切换效率就是最高的!多次读写都是在一个CPU上的,在内存情况下,这个就是最佳的方案!
redis五大数据类型
官方文档
Redis is an open source (BSD licensed), in-memory data structure store used as a database, cache, message broker, and streaming engine. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
全文翻译
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库 、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
redis-key
############################################################
127.0.0.1:6379> flushall #清空数据库
OK
127.0.0.1:6379> keys * #查看所有的key
(empty list or set)
127.0.0.1:6379> set name goldtree
OK
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> set age 1
OK
127.0.0.1:6379> keys *
1) "name"
2) "age"
127.0.0.1:6379>
############################################################
127.0.0.1:6379> EXISTS name #key name是否存在
(integer) 1
127.0.0.1:6379> EXISTS gender
(integer) 0
############################################################
127.0.0.1:6379> move name 1 #把key name 移动到1号数据库
(integer) 1
127.0.0.1:6379> keys *
1) "age"
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> keys *
1) "name"
############################################################
127.0.0.1:6379[1]> set name pangjuzi
OK
127.0.0.1:6379[1]> keys *
1) "name"
127.0.0.1:6379[1]> get name
"pangjuzi"
127.0.0.1:6379[1]> expire name 10 #给name设置10秒过期时间
(integer) 1
127.0.0.1:6379[1]> ttl name #查看剩余过期时间
(integer) 6
127.0.0.1:6379[1]> ttl name
(integer) 2
127.0.0.1:6379[1]> ttl name
(integer) -2
127.0.0.1:6379[1]> get name
(nil)
############################################################
127.0.0.1:6379> keys *
1) "name"
2) "age"
127.0.0.1:6379> type name #查看key的数据类型
string
127.0.0.1:6379> type age
string
String(字符串)
127.0.0.1:6379> set key1 v1
OK
127.0.0.1:6379> get key1
"v1"
127.0.0.1:6379> keys *
1) "key1"
127.0.0.1:6379> exists key1
(integer) 1
127.0.0.1:6379>
127.0.0.1:6379> append key1 "hello" #在key1键中追加hello
(integer) 7
127.0.0.1:6379> get key1
"v1hello"
127.0.0.1:6379> strlen key1 #获取key1中值的长度
(integer) 7
127.0.0.1:6379> append key1 ",goldtree"
(integer) 16
127.0.0.1:6379> get key1
"v1hello,goldtree"
127.0.0.1:6379> strlen key1
(integer) 16
127.0.0.1:6379> append name goldtree #若key不存在,就相当于set name goldtree
(integer) 8
127.0.0.1:6379> keys *
1) "key1"
2) "name"
#################################################################
127.0.0.1:6379> set views 0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views #原子操作加1
(integer) 1
127.0.0.1:6379> incr views
(integer) 2
127.0.0.1:6379> get views
"2"
127.0.0.1:6379> decr views #整数原子减1
(integer) 1
127.0.0.1:6379> decr views
(integer) 0
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> decr views
(integer) -1
127.0.0.1:6379> get views
"-1"
127.0.0.1:6379> incrby views 10 #以步长为10自增长
(integer) 9
127.0.0.1:6379> incrby views 10
(integer) 19
127.0.0.1:6379> get views
"19"
127.0.0.1:6379> decrby views 5 #以步长为5自减少
(integer) 14
127.0.0.1:6379> get views
"14"
######################################################################
#字符串范围 range
127.0.0.1:6379> set key1 hello,goldtree
OK
127.0.0.1:6379> get key1
"hello,goldtree"
127.0.0.1:6379> GETRANGE key1 0 4 #获取前5个字符 [0,4]
"hello"
127.0.0.1:6379> GETRANGE key1 0 -1 #获取所有字符串
"hello,goldtree"
#替换
127.0.0.1:6379> set key2 abcdefg
OK
127.0.0.1:6379> get key2
"abcdefg"
127.0.0.1:6379> SETRANGE key2 1 nn #替换指定位置开始的字符串
(integer) 7
127.0.0.1:6379> get key2
"anndefg"
#################################################################
# setex 设置key对应字符串value,并且设置key在给定的seconds时间之后超时过期。
# setnx key不存在就是设置value,key存在就什么都不做(分布式锁中常用)
127.0.0.1:6379> SETEX key3 60 dajiahao
OK
127.0.0.1:6379> ttl key3
(integer) 56
127.0.0.1:6379> ttl key3
(integer) 53
127.0.0.1:6379> keys *
1) "key3"
2) "key2"
3) "key1"
127.0.0.1:6379> ttl key3
(integer) -2
127.0.0.1:6379> keys *
1) "key2"
2) "key1"
127.0.0.1:6379> keys *
1) "key2"
2) "key1"
127.0.0.1:6379> get key2
"anndefg"
127.0.0.1:6379> SETNX key2 aaaaa
(integer) 0
127.0.0.1:6379> get key2
"anndefg"
127.0.0.1:6379> SETNX key3 aaaaa
(integer) 1
127.0.0.1:6379> get key3
"aaaaa"
####################################################################
#mset
对应给定的keys到他们相应的values上。MSET会用新的value替换已经存在的value,就像普通的SET命令一样
127.0.0.1:6379> MSET key1 hello key2 world
OK
127.0.0.1:6379> get key1
"hello"
127.0.0.1:6379> get key2
"world"
#msetnx
对应给定的keys到他们相应的values上。只要有一个key已经存在,MSETNX一个操作都不会执行
127.0.0.1:6379> MSETNX key1 hello key2 therer
(integer) 1
127.0.0.1:6379> MSETNX key2 there key3 world
(integer) 0
127.0.0.1:6379> MGET key1 key2 key3
1) "hello"
2) "therer"
3) (nil)
#mget 返回所有指定的key的value。对于每个不对应string或者不存在的key,都返回特殊值nil
#对象
127.0.0.1:6379> set user:1 {name:goldtree,age:3} #设置一个user:1对象 值为json字符串
#这里的key是一个巧妙的设计 user:{id}:{filed},如此设计在redis中是完全OK的
127.0.0.1:6379> mset user:1:name goldtree user:1:age 2
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "goldtree"
2) "2"
##########################################################################
#getset 自动将key对应到value并且返回原来key对应的value
127.0.0.1:6379> INCR mycounter
(integer) 1
127.0.0.1:6379> GETSET mycounter 0
"1"
127.0.0.1:6379> get mycounter
"0"
String类型的使用场景:value除了是字符串还可以是数字
-
计数器
-
统计多单位的数量
-
粉丝数
-
对象缓存存储
List
基本数据类型,列表
在redis里面,redis可以把list玩成堆栈,队列,阻塞队列
在列表中插入数据
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> LPUSH list one #从左边在list中放入one,向列表头部添加值
(integer) 1
127.0.0.1:6379> LPUSH list two
(integer) 2
127.0.0.1:6379> LPUSH list three
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1 #读取list中的值
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> keys *
1) "list"
127.0.0.1:6379> RPUSH list four #从右边在list中放入four,向列表尾部添加值
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "one"
4) "four"
移除列表中的数据
#LPOP 移除并且返回 key 对应的 list 的第一个元素
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "one"
4) "four"
127.0.0.1:6379> LPOP list
"three"
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "one"
3) "four"
#RPOP 移除并返回存于 key 的 list 的最后一个元素
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "one"
3) "four"
127.0.0.1:6379> RPOP list
"four"
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "one"
通过index获得值
127.0.0.1:6379> LPUSH list one two three four five
(integer) 5
127.0.0.1:6379> LRANGE list 0 -1
1) "five"
2) "four"
3) "three"
4) "two"
5) "one"
127.0.0.1:6379> LINDEX list 3
"two"
获得list得长度
127.0.0.1:6379> LRANGE list 0 -1
1) "five"
2) "four"
3) "three"
4) "two"
5) "one"
127.0.0.1:6379> LLEN list
(integer) 5
移除list中的值
# LREM key count value
# count > 0: 从头往尾移除值为 value 的元素。
# count < 0: 从尾往头移除值为 value 的元素。
# count = 0: 移除所有值为 value 的元素。
127.0.0.1:6379> Lpush list one one two two one one two two
(integer) 8
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "two"
3) "one"
4) "one"
5) "two"
6) "two"
7) "one"
8) "one"
127.0.0.1:6379> LREM list 3 one
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "two"
3) "two"
4) "two"
5) "one"
127.0.0.1:6379> LREM list 5 two
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "one"
127.0.0.1:6379> LREM list 5 two
(integer) 0
127.0.0.1:6379> LRANGE list 0 -1
1) "one"
修剪(trim)一个已存在的 list
127.0.0.1:6379> RPUSH list one two three
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1
1) "one"
2) "two"
3) "three"
127.0.0.1:6379> LTRIM list 1 -1
OK
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "three"
RPOPLPUSH
原子性地返回并移除存储在 source 的列表的最后一个元素(列表尾部元素), 并把该元素放入存储在 destination 的列表的第一个元素位置(列表头部)
# RPOPLPUSH source destination
127.0.0.1:6379> RPUSH list one two three
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1
1) "one"
2) "two"
3) "three"
127.0.0.1:6379> RPOPLPUSH list otherlist
"three"
127.0.0.1:6379> LRANGE list 0 -1
1) "one"
2) "two"
127.0.0.1:6379> LRANGE otherlist 0 -1
1) "three"
LPUSHX RPUSHX LSET
#LPUSHX key value
#只有当 key 已经存在并且存着一个 list 的时候,在这个 key 下面的 list 的头部插入 value。 与 LPUSH 相反,当 key 不存在的时候不会进行任何操作
#RPUSHX key value
#将值 value 插入到列表 key 的表尾, 当且仅当 key 存在并且是一个列表。 和 RPUSH 命令相反, 当 key 不存在时,RPUSHX 命令什么也不做
#LSET key index value
#设置 index 位置的list元素的值为 value
127.0.0.1:6379> RPUSH list Hello
(integer) 1
127.0.0.1:6379> RPUSHX list World
(integer) 2
127.0.0.1:6379> LRANGE list 0 -1
1) "Hello"
2) "World"
127.0.0.1:6379> RPUSHX otherlist World
(integer) 0
127.0.0.1:6379> LRANGE otherlist 0 -1
(empty list or set)
127.0.0.1:6379> lset list 0 goldtree
OK
127.0.0.1:6379> LRANGE list 0 -1
1) "goldtree"
2) "World"
127.0.0.1:6379> lset otherlist 0 goldtree
(error) ERR no such key
LINSERT
#LINSERT key BEFORE|AFTER pivot value
#把 value 插入存于 key 的列表中在基准值 pivot 的前面或后面。
#当 key 不存在时,这个list会被看作是空list,任何操作都不会发生。
#当 key 存在,但保存的不是一个list的时候,会返回error
127.0.0.1:6379> RPUSH list Hello World
(integer) 2
127.0.0.1:6379> LRANGE list 0 -1
1) "Hello"
2) "World"
127.0.0.1:6379> LINSERT list before Hello we
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1
1) "we"
2) "Hello"
3) "World"
127.0.0.1:6379> LINSERT list after Hello the
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "we"
2) "Hello"
3) "the"
4) "World"
小结
-
list实际是一个链表,before node after ,left,right都可以插入值
-
如果key不存在,创建新的链表
-
如果key存在,新增内容
-
如果移除了所有值,空链表,也代表不存在
-
在两边插入或者改动值,效率最高。中间元素,相对来说效率会低一点
-
消息队列,lpush rpop
-
栈 lpush lpop
Set (集合)
Set中的值是不能重复的,是无序的
SADD key member [member ...]
#添加一个或多个指定的member元素到集合的 key中.指定的一个或者多个元素member 如果已经在集合key中存在则忽略.如果集合key 不存在,则新建集合key,并添加member元素到集合key中
127.0.0.1:6379> SADD myset "Hello World" #""号被看作一个member
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "Hello World"
127.0.0.1:6379> SADD myset goldtree
(integer) 1
127.0.0.1:6379> SADD myset World
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "Hello World"
2) "World"
3) "goldtree"
127.0.0.1:6379> SADD myset World #已存在的member不会重复添加
(integer) 0
127.0.0.1:6379> SADD myset xiao wan zi
(integer) 3
127.0.0.1:6379> SMEMBERS myset
1) "xiao"
2) "World"
3) "goldtree"
4) "zi"
5) "Hello World"
6) "wan"
SISMEMBER key member
#返回成员 member 是否是存储的集合 key的成员
127.0.0.1:6379> SISMEMBER myset Hello
(integer) 0
127.0.0.1:6379> SISMEMBER myset World
(integer) 1
SCARD key
#返回集合存储的key的基数 (集合元素的数量).
127.0.0.1:6379> SCARD myset
(integer) 6
SREM key member [member ...]
#在key集合中移除指定的元素. 如果指定的元素不是key集合中的元素则忽略 如果key集合不存在则被视为一个空的集合,该命令返回0
127.0.0.1:6379> SADD myset one
(integer) 1
127.0.0.1:6379> SADD myset two
(integer) 1
127.0.0.1:6379> SADD myset three
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "two"
2) "three"
3) "one"
127.0.0.1:6379> SREM myset three
(integer) 1
127.0.0.1:6379> SREM myset four
(integer) 0
127.0.0.1:6379> SMEMBERS myset
1) "two"
2) "one"
SRANDMEMBER key [count]
#仅提供key参数,那么随机返回key集合中的一个元素
#Redis 2.6开始,可以接受 count 参数
#如果count是整数且小于元素的个数,返回含有 count 个不同的元素的数组,如果count是个整数且大于集合中元素的个数时,仅返回整个集合的所有元素
#当count是负数,则会返回一个包含count的绝对值的个数元素的数组,如果count的绝对值大于元素的个数,则返回的结果集里会出现一个元素出现多次的情况
127.0.0.1:6379> SADD myset one two three
(integer) 3
127.0.0.1:6379> SRANDMEMBER myset
"two"
127.0.0.1:6379> SRANDMEMBER myset
"one"
127.0.0.1:6379> SRANDMEMBER myset 2
1) "one"
2) "three"
127.0.0.1:6379> SRANDMEMBER myset 5
1) "two"
2) "one"
3) "three"
127.0.0.1:6379> SRANDMEMBER myset -2
1) "two"
2) "three"
127.0.0.1:6379> SRANDMEMBER myset -5
1) "two"
2) "one"
3) "two"
4) "three"
5) "one"
SPOP key [count]
#从存储在key的集合中移除并返回一个或多个随机元素
127.0.0.1:6379> SADD myset one two three
(integer) 3
127.0.0.1:6379> SMEMBERS myset
1) "two"
2) "three"
3) "one"
127.0.0.1:6379> SPOP myset #随机弹出一个member
"two"
127.0.0.1:6379> SMEMBERS myset
1) "three"
2) "one"
127.0.0.1:6379> SPOP myset -1 #count不能是负数
(error) ERR index out of range
127.0.0.1:6379> SPOP myset 2 #count大于member数量,弹出所有member
1) "one"
2) "three"
127.0.0.1:6379> SMEMBERS myset
(empty list or set)
SMOVE source destination member
#将member从source集合移动到destination集合中
127.0.0.1:6379> SADD myset one two
(integer) 2
127.0.0.1:6379> SADD myotherset three
(integer) 1
127.0.0.1:6379> SMOVE myset myotherset two
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "one"
127.0.0.1:6379> SMEMBERS myotherset
1) "two"
2) "three"
SINTER key [key ...] SINTERSTORE destination key [key ...]
#返回指定所有的集合的成员的交集 共同关注
127.0.0.1:6379> sadd key1 a b c
(integer) 3
127.0.0.1:6379> SADD key2 c d
(integer) 2
127.0.0.1:6379> SADD key3 f g h
(integer) 3
127.0.0.1:6379> SINTER key1 key2 key3
(empty list or set)
127.0.0.1:6379> SINTER key1 key2
1) "c"
SDIFF key [key ...] SDIFFSTORE destination key [key ...]
#返回一个集合与给定集合的差集的元素
127.0.0.1:6379> SDIFF key1 key2
1) "b"
2) "a"
127.0.0.1:6379> SDIFF key2 key1
1) "d"
SUNION key [key ...] SUNIONSTORE destination key [key ...]
#返回给定的多个集合的并集中的所有成员
127.0.0.1:6379> SUNION key1 key2
1) "b"
2) "c"
3) "d"
4) "a"
微博,A用户将所有关注的人放在一个set中,将他的粉丝也放在一个集合中
共同关注 共同爱好 二度好友 推荐好友(六度分割理论)
Hash
Map集合
HSET key field value
#设置 key 指定的哈希集中指定字段的值。
#如果 key 指定的哈希集不存在,会创建一个新的哈希集并与 key 关联。
#如果字段在哈希集中存在,它将被重写
127.0.0.1:6379> HSET myhash field1 "Hello"
(integer) 1
127.0.0.1:6379> HGET myhash field1
"Hello"
HMSET key field value [field value ...]
#设置 key 指定的哈希集中指定字段的值。该命令将重写所有在哈希集中存在的字段。如果 key 指定的哈希集不存在,会创建一个新的哈希集并与 key 关联
127.0.0.1:6379> HMSET myhash field1 Hello field2 World
OK
127.0.0.1:6379> HGET myhash field1
"Hello"
127.0.0.1:6379> HGET myhash field2
"World"
HMGET key field [field ...]
#返回 key 指定的哈希集中指定字段的值
127.0.0.1:6379> HMGET myhash field1 field2 nofield
1) "Hello"
2) "World"
3) (nil)
HGETALL key
#返回 key 指定的哈希集中所有的字段和值
127.0.0.1:6379> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
HDEL key field [field ...]
#从 key 指定的哈希集中移除指定的域
127.0.0.1:6379> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
127.0.0.1:6379> HDEL myhash field1
(integer) 1
127.0.0.1:6379> HGETALL myhash
1) "field2"
2) "World"
HLEN key
#返回 key 指定的哈希集包含的字段的数量
127.0.0.1:6379> HSET myhash field1 Hello
(integer) 1
127.0.0.1:6379> HSET myhash field2 World
(integer) 1
127.0.0.1:6379> HLEN myhash
(integer) 2
HSTRLEN key field
#返回hash指定field的value的字符串长度,如果hash或者field不存在,返回0
127.0.0.1:6379> HSTRLEN myhash field1
(integer) 5
HEXISTS key field
#返回hash里面field是否存在
127.0.0.1:6379> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
127.0.0.1:6379> HEXISTS myhash field1
(integer) 1
127.0.0.1:6379> HEXISTS myhash field10
(integer) 0
HKEYS key 和 HVALS key
#HKEYS key 返回 key 指定的哈希集中所有字段的名字
#HVALS key 返回 key 指定的哈希集中所有字段的值
127.0.0.1:6379> HKEYS myhash
1) "field1"
2) "field2"
127.0.0.1:6379> HVALS myhash
1) "Hello"
2) "World"
HINCRBY key field increment
#增加 key 指定的哈希集中指定字段的数值
#HINCRBY 支持的值的范围限定在 64位 有符号整数
127.0.0.1:6379> HSET myhash field 5
(integer) 1
127.0.0.1:6379> HINCRBY myhash field 1
(integer) 6
127.0.0.1:6379> HGETALL myhash
1) "field"
2) "6"
127.0.0.1:6379> HINCRBY myhash field -1
(integer) 5
127.0.0.1:6379> HGETALL myhash
1) "field"
2) "5"
127.0.0.1:6379> HINCRBY myhash field -10
(integer) -5
127.0.0.1:6379> HGETALL myhash
1) "field"
2) "-5"
HINCRBYFLOAT key field increment
#为指定key的hash的field字段值执行float类型的increment加
127.0.0.1:6379> HSET myhash field 10.50
(integer) 1
127.0.0.1:6379> HINCRBYFLOAT myhash field 0.1
"10.6"
127.0.0.1:6379> HSET myhash field 5.0e3
(integer) 0
127.0.0.1:6379> HGETALL myhash
1) "field"
2) "5.0e3"
127.0.0.1:6379> HINCRBYFLOAT myhash field 2.0e2
"5200"
127.0.0.1:6379> HGETALL myhash
1) "field"
2) "5200"
HSETNX key field value
#只在 key 指定的哈希集中不存在指定的字段时,设置字段的值
127.0.0.1:6379> HSETNX myhash field hello
(integer) 1
127.0.0.1:6379> HSETNX myhash field world
(integer) 0
127.0.0.1:6379> HGET myhash field
"hello"
小结
-
hash存储变更的数据,例如用户信息的保存
sorted set(有序集合)
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
#将所有指定成员添加到键为key有序集合(sorted set)里面
#如果指定添加的成员已经是有序集合里面的成员,则会更新改成员的分数(scrore)并更新到正确的排序位置
XX: 仅仅更新存在的成员,不添加新成员。
NX: 不更新存在的成员。只添加新成员。
CH: 修改返回值为发生变化的成员总数
INCR: 当ZADD指定这个选项时,成员的操作就等同ZINCRBY命令,对成员的分数进行递增操作
127.0.0.1:6379> ZADD myzset 1 one
(integer) 1
127.0.0.1:6379> ZADD myzset 1 uno
(integer) 1
127.0.0.1:6379> ZADD myzset 2 three 3 two
(integer) 2
127.0.0.1:6379> ZRANGE myzset 0 -1
1) "one"
2) "uno"
3) "three"
4) "two"
127.0.0.1:6379> ZRANGE myzset 0 -1 withscores
1) "one"
2) "1"
3) "uno"
4) "1"
5) "three"
6) "2"
7) "two"
8) "3"
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
#返回key的有序集合中的分数在min和max之间的所有元素
#ZRANGEBYSCORE zset (1 5 返回所有符合条件1 < score <= 5的成员
127.0.0.1:6379> ZADD salary 5000 xiaowanzi 3000 mama 250 baba
(integer) 3
127.0.0.1:6379> ZRANGE salary 0 -1
1) "baba"
2) "mama"
3) "xiaowanzi"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf inf
1) "baba"
2) "mama"
3) "xiaowanzi"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf inf withscores
1) "baba"
2) "250"
3) "mama"
4) "3000"
5) "xiaowanzi"
6) "5000"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf 3000 withscores
1) "baba"
2) "250"
3) "mama"
4) "3000"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf (3000 withscores
1) "baba"
2) "250"
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
#ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
127.0.0.1:6379> ZREVRANGEBYSCORE salary +inf -inf
1) "xiaowanzi"
2) "mama"
3) "baba"
127.0.0.1:6379> ZREVRANGEBYSCORE salary +inf -inf withscores
1) "xiaowanzi"
2) "5000"
3) "mama"
4) "3000"
5) "baba"
6) "250"
ZREM key member [member ...]
127.0.0.1:6379> ZREM salary mama
(integer) 1
127.0.0.1:6379> ZREVRANGEBYSCORE salary +inf -inf withscores
1) "xiaowanzi"
2) "5000"
3) "baba"
4) "250"
ZCARD key
#返回key的有序集元素个数
127.0.0.1:6379> ZCARD salary
(integer) 2
ZCOUNT key min max
#返回有序集key中,score值在min和max之间(默认包括score值等于min或max)的成员个数
127.0.0.1:6379> ZRANGE myzset 0 -1
1) "one"
2) "two"
3) "three"
127.0.0.1:6379> ZRANGE myzset -1 0
(empty list or set)
127.0.0.1:6379> ZCOUNT myzset -inf inf
(integer) 3
127.0.0.1:6379> ZCOUNT myzset 1 3
(integer) 3
127.0.0.1:6379> ZCOUNT myzset (1 3
(integer) 2
三种特殊数据类型
geospatial 地理位置
定位 附近的人 打车距离计算
Redis的Geo 在Redis3.2版本推出,可以推算两地之间的距离
可以查询一些测试数据
只有6个命令
GEOADD key longitude latitude member [longitude latitude member ...]
GEODIST key member1 member2 [unit] 返回两个给定位置之间的距离
m 表示单位为米。
km 表示单位为千米。
mi 表示单位为英里。
ft 表示单位为英尺
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] #以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素
GEOPOS key member [member ...] #GEOPOS key member [member ...]
GEOHASH key member [member ...]
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count]
127.0.0.1:6379> GEOADD mygeo 116.405285 39.904989 beijing 121.472644 31.231706 shanghai 113.280637 23.125178 guangzhou 114.085947 22.547 zhenzhen
(integer) 4
127.0.0.1:6379> GEODIST mygeo beijing shanghai km
"1067.5980"
127.0.0.1:6379> GEORADIUS mygeo 120 30 200 km withdist
1) 1) "shanghai"
2) "196.5640"
127.0.0.1:6379> GEORADIUS mygeo 120 30 1500 km withdist
1) 1) "zhenzhen"
2) "1016.9532"
2) 1) "guangzhou"
2) "1015.1519"
3) 1) "shanghai"
2) "196.5640"
4) 1) "beijing"
2) "1149.1099"
127.0.0.1:6379> GEOPOS mygeo beijing
1) 1) "116.40528291463851929"
2) "39.9049884229125027"
127.0.0.1:6379> GEOhash mygeo beijing
1) "wx4g0b7xrt0"
127.0.0.1:6379> GEOhash mygeo beijing shanghai
1) "wx4g0b7xrt0"
2) "wtw3sjt9vg0"
127.0.0.1:6379> GEORADIUSBYMEMBER mygeo shanghai 500 km withdist
1) 1) "shanghai"
2) "0.0000"
127.0.0.1:6379> GEORADIUSBYMEMBER mygeo shanghai 1500 km withdist
1) 1) "zhenzhen"
2) "1211.6366"
2) 1) "guangzhou"
2) "1211.5290"
3) 1) "shanghai"
2) "0.0000"
4) 1) "beijing"
2) "1067.5980"
GEO的底层是zset
127.0.0.1:6379> ZRANGE mygeo 0 -1
1) "zhenzhen"
2) "guangzhou"
3) "shanghai"
4) "beijing"
127.0.0.1:6379> zrem mygeo shanghai
(integer) 1
127.0.0.1:6379> ZRANGE mygeo 0 -1
1) "zhenzhen"
2) "guangzhou"
3) "beijing"
127.0.0.1:6379>
hyperloglog
什么是基数
A {1,3,5,7,8,7}
B {1,3,5,7,8}
基数(不重复的元素)= 5
简介
redis2.8.9版本就更新了Hyperloglog数据结构
Redis Hyperloglgo做基数统计的算法
优点:占用的内存是固定的,2^64不同的元素的技术,只需要12KB内存
网页的UV(一个人访问一个网站多次,但是还算是一个人)
传统的方式,set保存用户的id,然后就可以统计set中的元素的数量。如果保存大量的用户id会消耗大量的存储空间。我们的目的是计数,不是保存用户id。
0.81%的错误率,统计UV任务,可以忽略不计
测试使用
127.0.0.1:6379> PFADD hll a a a b c d e f g g g j k
(integer) 1
127.0.0.1:6379> PFCOUNT hll
(integer) 9
127.0.0.1:6379> PFADD hll2 h w i o du sj ww a
(integer) 1
127.0.0.1:6379> PFCOUNT hll hll2
(integer) 16
127.0.0.1:6379> PFMERGE hll3 hll hll2
OK
127.0.0.1:6379> PFCOUNT hll3
(integer) 16
bitmaps
位存储
统计人数 : 0 0 1 0 0 0 0 1
Bitmaps位图,数据结构。都是操作二进制位来记录,只有0和1两个状态
测试 记录周一到周日的打卡状态
127.0.0.1:6379> SETBIT sign 0 1
(integer) 0
127.0.0.1:6379> SETBIT sign 1 1
(integer) 0
127.0.0.1:6379> SETBIT sign 4 1
(integer) 0
127.0.0.1:6379> SETBIT sign 6 1
(integer) 0
127.0.0.1:6379> GETBIT sign 1
(integer) 1
127.0.0.1:6379> GETBIT sign 2
(integer) 0
127.0.0.1:6379> BITCOUNT sign #统计打卡天数
(integer) 4
Redis的基本事务
Redis事务本质:一组命令的集合!一个事务中的所有命令都会被序列化,在事务执行过程中,会按照顺序执行!
一次性,顺序性,排他性!执行一系列命令
Redis事务没有隔离级别的概念
所有的命令在事务中,并没有直接被执行,只有发起执行命令的时候才会执行
Redis单条命令有原子性,要么同时成功,要么同时失败,原子性!但是Redis事务不保证原子性
Redis的事务:
-
开启事务(MULTI)
-
命令入队()
-
执行事务(EXEC)
正常执行事务
127.0.0.1:6379> MULTI #开启事务
OK
127.0.0.1:6379> set k1 v1 #命令入队
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> get k1
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> EXEC #执行事务
1) OK
2) OK
3) "v1"
4) OK
放弃事务
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> DISCARD #放弃事务
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> get k4
(nil)
编译型异常(代码有问题,命令有错)事务中所有的命令都不会执行
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> getset k3 #命令错误
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> set k5 v5
QUEUED
127.0.0.1:6379> EXEC #所有命令都不会执行
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k1
(nil)
运行时异常(1/0),如果事务队列存在语法性错误,在执行时,正确的命令会被执行。错误命令抛出异常
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> incr k1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> get k3
QUEUED
127.0.0.1:6379> EXEC
1) (error) ERR value is not an integer or out of range
2) OK
3) OK
4) "v3"
监控!Watch
悲观锁
-
很悲观,什么时候都会出问题,无论做什么都会加锁
乐观锁
-
很乐观,认为什么时候都不会出现问题,所以不会上锁。更新数据时判断,在此期间是否有人修改过数据。
-
获取version
-
更新的时候比较version
Redis监视测试
正常执行成功
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money #监视money对象
OK
127.0.0.1:6379> MULTI #事务正常结束,数据期间没有发生变动,这个时候就正常执行成功
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY out 20
QUEUED
127.0.0.1:6379> EXEC
1) (integer) 80
2) (integer) 20
模拟money在事务执行时发生变化
#先在client1
127.0.0.1:6379> WATCH money
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> DECRBY money 10
QUEUED
127.0.0.1:6379> INCRBY out 10
QUEUED
#这时在client2
127.0.0.1:6379> set money 1000
OK
#然后在client1
127.0.0.1:6379> EXEC #由于money发生变动,事务没有执行
(nil)
#使用watch可以当作redis的乐观锁操作!
Jedis
我们要使用java来操作
什么是Jedis 是Redis官方推荐的java连接卡法工具。使用java操作Redis的中间件。如果使用java操作redis,那么要定要对jedis十分的熟悉
intellij idea
介绍
IDEA 全称 IntelliJ IDEA,是
下载
测试
-
创建project 可以创建以空项目
-
创建module
导入jedis包
登录
搜索jedis
下载这个
复制粘贴到module里
导入fastjson
最后结果
<!--导入jedis的包-->
<dependencies>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.3.1</version>
</dependency>
<!--fastjson的包-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.18</version>
</dependency>
</dependencies>
编码测试
-
连接数据库
-
操作命令
-
断开连接
测试代码
package com.goldtree;
import redis.clients.jedis.Jedis;
public class TestPing {
public static void main(String[] args) {
Jedis jedis = new Jedis("44.201.159.141",6379);
System.out.println(jedis.ping());
}
}
测试结果
"C:\Program Files\Java\jdk1.8.0_202\bin\java.exe" "-javaagent:C:\Program
PONG
注意事项
编辑redis.conf
#注释这行
#bind 127.0.0.1
#修改这行
protected-mode yes-->no
常用的API
package com.goldtree;
import redis.clients.jedis.Jedis;
import java.util.Set;
public class TestKey {
public static void main(String[] args) {
Jedis jedis = new Jedis("44.201.159.141",6379);
System.out.println("清空数据: "+jedis.flushDB());
System.out.println("判断username键是否存在: "+jedis.exists("username"));
System.out.println("新增<'username','goldtree'>的键值对: " +jedis.set("username","goldtree"));
System.out.println("新增<'password','12345678'>的键值对: "+jedis.set("password","12345678"));
System.out.print("系统中所有的键如下: ");
Set<String> keys = jedis.keys("*");
System.out.println(keys);
System.out.println("删除键password: "+jedis.del("password"));
System.out.println("判断键password是否存在 " +jedis.exists("password"));
System.out.println("查看键username存储值的类型: "+jedis.type("username"));
System.out.println("随机返回key空间的一个: "+jedis.randomKey());
System.out.println("重命名key:"+jedis.rename("username","name"));
System.out.println("取出改后的name "+jedis.get("name"));
System.out.println("按索引查询: "+jedis.select(0));
System.out.println("删除当前选择数据库中所有的keys: "+jedis.flushDB());
System.out.println("返回当前数据库中key的数目: "+jedis.dbSize());
System.out.println("删除所有数据库的keys: "+jedis.flushAll());
}
}
重温事务
package com.goldtree;
import com.alibaba.fastjson.JSONObject;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class MULTI {
public static void main(String[] args) {
Jedis jedis = new Jedis("54.152.87.57",6300);
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello","world");
jsonObject.put("name","goldtree");
// 开启事务
jedis.flushDB();
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
try {
multi.set("user1", result);
multi.set("user2", result);
int a =1/0; //故意出错,事务失败
multi.exec();
}catch (Exception e){
multi.discard(); //放弃事务
e.printStackTrace();
}finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close(); //关闭连接
}
}
}
Redis 持久化
Redis是内存数据库,如果不能将内存中的数据库状态保存到磁盘,一旦服务器进程退出,服务器中的数据库状态也会小时。所以Redis提供了持久化功能!
RDB(Redis DataBase)
RDB是Redis用来进行持久化的一种方式,是把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写道一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程不进行任何IO操作。这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,RDB方式要比AOF更加高效。RDB的缺点是最后一次持久化后的数据可能丢失。默认是RDB,一般情况不需要修改配置。
RDB保存的文件是dump.rdb
RDB 有两种触发方式,分别是自动触发和手动触发。
默认快照配置
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1
save 300 10
save 60 10000
# By default Redis will stop accepting writes if RDB snapshots are enabled
# (at least one save point) and the latest background save failed.
# This will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# If the background saving process will start working again Redis will
# automatically allow writes again.
#
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
stop-writes-on-bgsave-error yes
# Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes
# The filename where to dump the DB
dbfilename dump.rdb
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir ./
触发机制
-
save的规则满足的情况下,会自动触发rdb规则
-
执行flushall命令,也会产生rdb文件
-
Redis shutdown时,也会产生rdb文件
如何恢复rdb文件
1 只需要将rdb文件放在redis启动目录,redis启动时,会自动检查dump.rdb文件,恢复其中的数据
2 查看需要存放的位置
127.0.0.1:6300> CONFIG GET dir
1) "dir"
2) "/usr/local/bin"
优点:
-
适合大规模的数据恢复!
-
如果数据的完整性要求不高
缺点:
-
需要一定的时间间隔进行操作。如果redis意外宕机了,最后一次修改的数据就没有了
-
fork进程的时候会占用内存空间
AOF(Append Only File)
将所以命令记录下来,类似history,恢复的时候把这个文件全部执行一遍。
以日志的形势记录每个写操作,将Redis执行过的所有指令记录下来。只允许追加文件但不可以改写文件,redis启动时会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据恢复。
AOF默认时关闭的。只需要将appendonly改为yes就可以启动AOF
如果aof文件有错误,redis时启动不了的,需要修复这个文件。
redis提供一个工具redis-check-aof --fix
这个工具会把aof文件中错误删除。会丢数据
优点和缺点
优点
1 每次修改都同步,文件的完整会更好
2 每秒同步一次,可能会丢失一秒的数据
3 从不同步,效率最高。
缺点
1 相对于数据文件来说,aof远远大于RDF,修复的速度比rdb慢
2 aof运行效率比rdb慢
扩展
1 rdb持久化方式能够在指定的时间间隔内对数据进行快照存储
2 aof持久化方式记录每次对服务器写的操作,当服务器重启时候重新执行这些命令来恢复原始数据,aof命令以Redis协议追加保存每次写的操作到文件末尾,redis还能对aof文件进行后台重写,使得aof文件的体积不会过大
3 只做缓存,可以不使用任何持久化
4 同时开启两种持久化方式
-
当redis重启时,会优先载入aof文件恢复原始的数据,因为在通常情况下aof文件保存的数据集要比rdf文件保存的数据完整
-
rdb的数据不实时,同时使用两者时,服务器重启也只会找aof文件,那要不要只使用aof呢?建议不要,因为rdb更适合用于备份数据库(aof在不断变化不好备份),快速重启,而且不会有aof可能潜在的bug。
5 性能建议
-
因为rdb文件只用做后备用途,建议只在slave上持久化rdb文件,而且只要15分钟一次就够了。只保留save 900 1这条规则
-
如果enable aof,好处时在最恶劣情况下也只会丢失不超过2秒的数据,启动脚本较简单只load自己的aof文件就可以了,代价一是带来了持续的IO,二是aof rewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少aof rewrite的频率,aof重写的基础大小默认是64mb,可以设置5GB以上,默认超过原大小100%大小重写也可以改到适当的数值。
-
如果不enable aof,仅靠Master-slave replication实现高可用也可以,能节省一大笔IO,也减少了rewrite带来的系统波动,代价是如果Master-Slave同时宕机,会丢失十几分钟的数据,启动脚本也要比较两个Master/Slave中的RDB文件,载入较新的那个。微博就是这种架构。
Redis发布订阅
Redis发布订阅(pub/sub)是一种消息通信模式,发送者发信息,订阅者接收信息。
Redis客户端可以订阅任意数量的频道。
订阅/发布消息图
第一个:消息发送者,第二个:频道,第三个:消息订阅者
下图展示了频道channel,以及订阅这个频道的三个客户端之间的关系
当有新形象通过PUPBLISH命令发送给频道channel时,这个消息就会被发送给订阅它的三个客户端
命令
这些命令被广泛用于构建即时通讯应用,比如网络聊天室和实时广播等
-
PSUBSCRIBE pattern [pattern ...] 订阅一个或多个给定模式的频道
-
PUBSUB subcommand [argument [argument ...]] 查看订阅与发布系统状态
-
PUBLISH channel message 把信息发送到指定的频道
-
PUNSUBSCRIBE [pattern [pattern ...]] 退订所有给定模式的频道
-
SUBSCRIBE channel [channel ...] 订阅给定的一个或多个频道的信息
-
UNSUBSCRIBE channel [channel ...] 退订给定的频道
测试
#订阅一个叫goldtree的频道
127.0.0.1:6300> SUBSCRIBE goldtree
Reading messages... (press Ctrl-C to quit) #等待读取信息
1) "subscribe"
2) "goldtree"
3) (integer) 1
#再连接一个client,做为发送端发送消息
127.0.0.1:6300> PUBLISH goldtree "hello little one"
(integer) 1
127.0.0.1:6300>
#回到订阅的客户端
127.0.0.1:6300> SUBSCRIBE goldtree
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "goldtree"
3) (integer) 1
1) "message"
2) "goldtree"
3) "hello little one"
使用场景
-
实时信息系统
-
实时聊天
-
订阅关注系统
稍微复杂的场景使用信息中间件MQ
Redis主从复制
1)使用异步复制。 2)一个主服务器可以有多个从服务器。 3)从服务器也可以有自己的从服务器。 4)复制功能不会阻塞主服务器。 5)可以通过复制功能来让主服务器免于执行持久化操作,由从服务器去执行持久化操作即可。
详细介绍
1)Redis 使用异步复制。从 Redis2.8开始,从服务器会以每秒一次的频率向主服务器报告复制流(replication stream)的处理进度。
2)一个主服务器可以有多个从服务器。
3)不仅主服务器可以有从服务器,从服务器也可以有自己的从服务器,多个从服务器之间可以构成一个图状结构。
4)复制功能不会阻塞主服务器:即使有一个或多个从服务器正在进行初次同步, 主服务器也可以继续处理命令请求。
5)复制功能也不会阻塞从服务器:只要在 redis.conf 文件中进行了相应的设置, 即使从服务器正在进行初次同步, 服务器也可以使用旧版本的数据集来处理命令查询。
6)在从服务器删除旧版本数据集并载入新版本数据集的那段时间内,连接请求会被阻塞。
7)还可以配置从服务器,让它在与主服务器之间的连接断开时,向客户端发送一个错误。
8)复制功能可以单纯地用于数据冗余(data redundancy),也可以通过让多个从服务器处理只读命令请求来提升扩展性(scalability): 比如说,繁重的SORT命令可以交给附属节点去运行。
9)可以通过复制功能来让主服务器免于执行持久化操作:只要关闭主服务器的持久化功能,然后由从服务器去执行持久化操作即可。
Redis主从复制
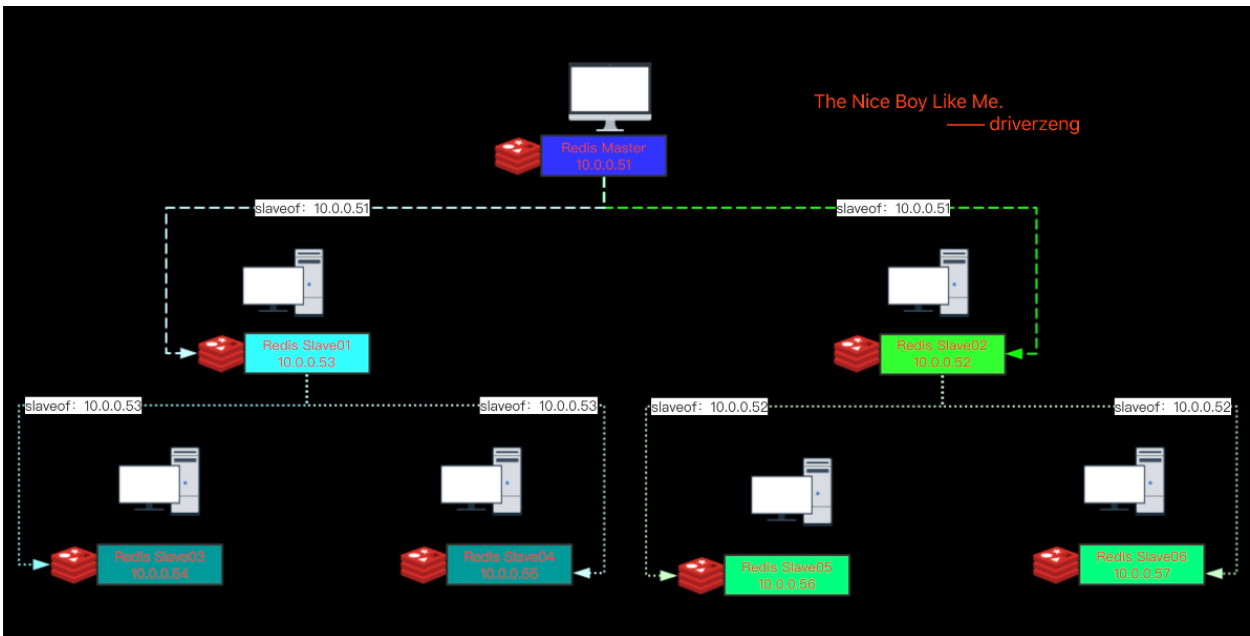
主库关闭持久化的危险性
1.当配置Redis复制功能时,强烈建议打开主服务器的持久化功能。 否则的话,由于延迟等问题,部署的服务应该要避免自动拉起。
2.为了帮助理解主服务器关闭持久化时自动拉起的危险性,参考一下以下会导致主从服务器数据全部丢失的例子:
1)假设节点A为主服务器,并且关闭了持久化。并且节点B和节点C从节点A复制数据
2)节点A崩溃,然后由自动拉起服务重启了节点A. 由于节点A的持久化被关闭了,所以重启之后没有任何数据
3)节点B和节点C将从节点A复制数据,但是A的数据是空的,于是就把自身保存的数据副本删除。
结论:
1)在关闭主服务器上的持久化,并同时开启自动拉起进程的情况下,即便使用Sentinel来实现Redis的高可用性,也是非常危险的。因为主服务器可能拉起得非常快,以至于Sentinel在配置的心跳时间间隔内没有检测到主服务器已被重启,然后还是会执行上面的数据丢失的流程。
2)无论何时,数据安全都是极其重要的,所以应该禁止主服务器关闭持久化的同时自动拉起。
redis主从复制原理
1)从服务器向主服务器发送 SYNC 命令。
2)接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下来执行的所有写命令。
3)当主服务器执行完 BGSAVE 命令时,它会向从服务器发送 RDB 文件,而从服务器则会接收并载入这个文件。
4)主服务器将缓冲区储存的所有写命令发送给从服务器执行。

主从复制的作用包括
-
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
-
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复,实际上是一种服务冗余
-
负载均衡:在主从复制基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务,分担服务器负载;尤其在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量
-
高可用基石:除了上述作用外,主从复制还是哨兵模式和集群能够实现的基础,因此说主从复制是高可用的基础
一般来说,要将Redis运用于工程项目中,只是用一台服务器是万万不能的,原因如下:
-
从结构上说,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求,负载压力大
-
从容量上说,单个Redis服务器内存容量有限,就算一台服务器有256GB,也不能将所有的内存用作Redis存储内存,一般来说,单台redis服务器使用内存不应该超过20GB
-
电商网站上的商品,一般都是一次上传,无数次浏览的。一般一主二从
-
生产环境主从复制必须要使用
测试环境配置
| 节点名 | IP | 角色 |
|---|---|---|
| node1 | 10.0.0.200 | master |
| node2 | 10.0.0.31 | slave |
| node3 | 10.0.0.32 | slave |
只配置从库。不用配置主库!
查看节点复制信息
[root@redhat86m bin]# redis-cli -p 6300
127.0.0.1:6300> info replication
# Replication
role:master #角色
connected_slaves:0 #没有从机
master_replid:d660f33e10d562c72b815c7345552222c64a9512
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
[root@redhat86 ~]# redis-cli -p 6300
127.0.0.1:6300> info replication
# Replication
role:master
connected_slaves:0
master_replid:ac850f048ffd04d3ea7128a12899ea7fc23f87ed
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
[root@redhat86m ~]# redis-cli -p 6300
127.0.0.1:6300> info replication
# Replication
role:master
connected_slaves:0
master_replid:90ac1d51cbcfb9892e116efb04249631b853d280
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
目前三台机器都是master
要配置一主二从的配置
一般只配置从机
#在10.0.0.31执行
127.0.0.1:6300> SLAVEOF 10.0.0.200 6300
OK
#在看一下replication信息
127.0.0.1:6300> info replication
# Replication
role:slave #角色变为了slave
master_host:10.0.0.200 #识别到了master
master_port:6300
master_link_status:up
#在10.0.0.32执行
127.0.0.1:6300> SLAVEOF 10.0.0.200 6300
OK
#在看一下replication信息
127.0.0.1:6300> info replication
# Replication
role:slave #角色变为了slave
master_host:10.0.0.200 #识别到了master
master_port:6300
master_link_status:up
#在master 10.0.0.200执行
127.0.0.1:6300> info replication
# Replication
role:master
connected_slaves:2 #识别到两个从机
slave0:ip=10.0.0.31,port=6300,state=online,offset=168,lag=1
slave1:ip=10.0.0.32,port=6300,state=online,offset=168,lag=1
SLAVEOF 10.0.0.200 6300命令是临时生效,如果要永久生效需要修改配置文件
# replicaof <masterip> <masterport>
replicaof 10.0.0.200 6300
测试1
#主机负责写,从机负责读
#master
127.0.0.1:6300> keys *
(empty list or set)
127.0.0.1:6300> set k1 v1
OK
127.0.0.1:6300> set k2 v2
OK
127.0.0.1:6300>
#slave
127.0.0.1:6300> keys *
1) "k2"
2) "k1"
127.0.0.1:6300> get k1 #可以读取值
"v1"
127.0.0.1:6300> set k3 v3
(error) READONLY You can't write against a read only replica. #不能写
测试2 主机宕机
#master
127.0.0.1:6300> SHUTDOWN
not connected>
#slave 可以读取数据
127.0.0.1:6300> keys *
1) "k2"
2) "k1"
127.0.0.1:6300> get k1
"v1"
#master 好了
[root@redhat79 ~]# !445
redis-server /redis/redis.conf
2887:C 24 Nov 2022 15:42:35.161 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2887:C 24 Nov 2022 15:42:35.162 # Redis version=5.0.14, bits=64, commit=00000000, modified=0, pid=2887, just started
2887:C 24 Nov 2022 15:42:35.162 # Configuration loaded
[root@redhat79 ~]# !446
redis-cli -p 6300
127.0.0.1:6300> ping
PONG
127.0.0.1:6300> keys *
1) "k2"
2) "k1"
127.0.0.1:6300> set k3 v3
OK
127.0.0.1:6300>
#slave
127.0.0.1:6300> get k3 #新设置k3可以查到
"v3"
测试3 从机宕机
#slave
127.0.0.1:6300> SHUTDOWN
not connected>
#master 设置新的值
127.0.0.1:6300> set k4 v4
OK
127.0.0.1:6300> set k5 v5
OK
127.0.0.1:6300> keys *
1) "k4"
2) "k3"
3) "k2"
4) "k5"
5) "k1"
#slave好了 看看能不能看到k4 k5
127.0.0.1:6300> keys *
1) "k2"
2) "k3"
3) "k1"
4) "k5"
5) "k4"
127.0.0.1:6300> get k4
"v4"
注意
如果只是使用命令行配置主从关系,这个时候如果从机重启了,从机会变回master。
复制原理
slave启动成功连接到master后会发送一个sync同步命令
Master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步
全量复制:slave服务在接受到书库文件数据后,将其存盘并加载到内存中
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
但是只要是重新连接master,一次完全同步将被自动执行
要配置主--从--从的配置
#node3配置成node2的从机
#node1
127.0.0.1:6300> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=10.0.0.31,port=6300,state=online,offset=1804,lag=1
#node2
127.0.0.1:6300> info replication
# Replication
role:slave #依旧是从节点 无法写入
master_host:10.0.0.200
master_port:6300
master_link_status:up
master_last_io_seconds_ago:9
master_sync_in_progress:0
slave_repl_offset:1776
slave_priority:100
slave_read_only:1
connected_slaves:1
slave0:ip=10.0.0.32,port=6300,state=online,offset=1776,lag=1
#node3
127.0.0.1:6300> info replication
# Replication
role:slave
master_host:10.0.0.31
master_port:6300
测试
1 主节点还是负责写,从节点负责读
2 主节点宕机 node2能不能当master
#node2能不能当master
127.0.0.1:6300> INFO replication
# Replication
role:slave
master_host:10.0.0.200
master_port:6300
master_link_status:down #node1挂了
#node2
127.0.0.1:6300> SLAVEOF no one #自己当老大
127.0.0.1:6300> INFO replication
# Replication
role:master
connected_slaves:1
slave0:ip=10.0.0.32,port=6300,state=online,offset=2336,lag=0
#node3
127.0.0.1:6300> INFO replication
# Replication
role:slave
master_host:10.0.0.31
master_port:6300
master_link_status:up #此时是up的,如果node2没有执行SLAVEOF no one,这个状态是down的
node1节点回来了也只能重新配置主从关系
哨兵模式
概述
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。着不是一种推荐的方法,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵)架构来解决这个问题。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程。作为进程,他会独立运行,其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。如果故障了根据投票数自动将从库转换为主库
这里的哨兵有两个作用
-
通过发送命令,让Redis服务器返回监控其运行状态。包括主服务器和从服务器。
-
当哨兵检测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控,各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线,当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover故障转移操作.切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。
测试
目前是一主二从
1 配置哨兵配置文件sentinel.conf
[root@redhat86 redis]# vi sentinel.conf
sentinel monitor mymaster 10.0.0.200 6300 2
sentinel monitor mymaster 10.0.0.31 6300 2
sentinel monitor mymaster 10.0.0.32 6300 2
[root@redhat86m redis]# vim sentinel.conf
sentinel monitor mymaster 10.0.0.200 6300 2
sentinel monitor mymaster 10.0.0.31 6300 2
sentinel monitor mymaster 10.0.0.32 6300 2
[root@redhat79 redis]# vim sentinel.conf
sentinel monitor mymaster 10.0.0.200 6300 2
sentinel monitor mymaster 10.0.0.31 6300 2
sentinel monitor mymaster 10.0.0.32 6300 2
2 启动哨兵
#启动redis群集
[root@redhat79 redis]# redis-cli -h 10.0.0.200 -p 6300
10.0.0.200:6300> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=10.0.0.32,port=6300,state=online,offset=140,lag=1
slave1:ip=10.0.0.31,port=6300,state=online,offset=140,lag=1
master_replid:f9c69eb802d121d95234250f51dfabaaf510d93d
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:140
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:140
#启动哨兵
[root@redhat79 redis]# redis-sentinel /redis/sentinel.conf
[root@redhat86 redis]# redis-server /redis/redis.conf
[root@redhat86m redis]# redis-sentinel /redis/sentinel.conf
#10.0.0.200模仿宕机
3 切换
master宕机后,哨兵会在slave中随机挑一个作为master,当原来的master回来了,哨兵把它设置为slave。
优缺点
优点:
1 哨兵集群,基于主从复制模式,所有的主从配置的优点都有
2 主从可以切换,故障可以转移,系统的可用性更好
3 哨兵模式就是主从模式的升级,手动到自动,更加健壮
缺点:
1 Redis不好在线扩容,集群容量一旦达到上线,在线扩容十分麻烦
2 实现哨兵模式的配置其实是很麻烦的,里面有很多选择
Redis缓存穿透和雪崩
Redis缓存使用的时候,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解,如果对数据库的一致性要求很高,那么就不能使用缓存。
另外的一些典型问题就是,缓存穿透,缓存雪崩和缓存击穿。目前,业界也都有比较流行的解决方案!
缓存穿透(查不到)
概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败,当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
解决方案
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,再控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力。
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源
这个方法会存在两个问题:
1 如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
2 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间不一致,这对于需要保持一致性的业务会有影响。
缓存击穿(查太多)
概述
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这个点进行访问,在这个key失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开一个洞。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导致数据库瞬间压力过大。
解决方案
设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点key过期后产生的问题
加互斥锁
分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可,这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
缓存雪崩
概念
缓存雪崩,是指在某一个时间段,缓存集中过期失效。
产生雪崩的原因之一,比如在写文本的时候,马上就要到双十一零点,很快就会来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会到达存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
其中过期,不是非常致命的。比较致命的缓存雪崩是缓存服务器摸个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存。这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务器节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
解决方案
Redis高可用
这个思想的含义是,既然redis有可能挂掉,那我就多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制都数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写数据,其他线程等带。
数据预热
数据预热的含义是,在正式部署之前,先把可能的数据预先访问一编,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问之前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效时间点尽量均匀。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号