第一次个人编程作业
一、github地址
二、题目及需求
题目:论文查重
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
说实话看到这个题目之后整个人都是懵的,发现自己连题目都有点看不懂。到处都是知识的盲区.jpg 于是熟练的打开的百度(bushi 输入查重算法,出来的几乎都是python和java写的 被迫开始了从零开始的学Pyhton之路
三、算法实现
看了好多篇博客 最后选择余弦相似度算法计算文本相似度 因为只能看懂这个
余弦相似度算法: 一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。 (不禁要感叹,数学真的是一门神奇的学科,文本相似度都能抽象成数学里的模型
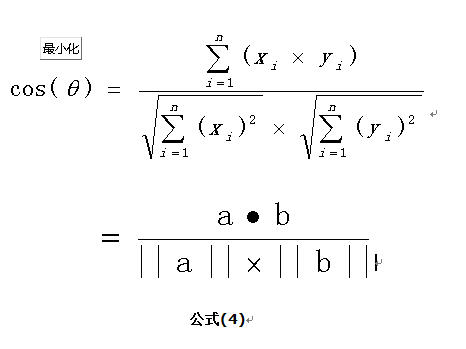
比如:余弦相似度量:计算个体间的相似度。
相似度越小,距离越大。相似度越大,距离越小。
假设有3个物品,item1,item2和item3,用向量表示分别为:
item1[1,1,0,0,1],
item2[0,0,1,2,1],
item3[0,0,1,2,0],
即五维空间中的3个点。用欧式距离公式计算item1、itme2之间的距离,以及item2和item3之间的距离,分别是:
item1-item2=
item2-item3=
用余弦函数计算item1和item2夹角间的余弦值为:
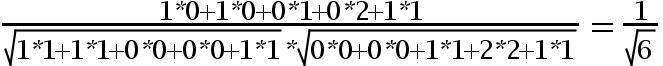
用余弦函数计算item2和item3夹角间的余弦值为:
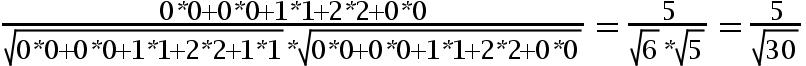
由此可得出item1和item2相似度小,两个之间的距离大(距离为7),item2和itme3相似度大,两者之间的距离小(距离为1)。
余弦相似度算法的大致流程图:
部分实现代码如下:
#定义一个类
class getText():
def __init__(txts,f11,f22,K=1000):
txts.f1 = f11
txts.f2 = f22
#构造词和权重的关系
def vector(txts):
cut1 = jieba.analyse.extract_tags(txts.f1,topK = txts.topK, withWeight = True)
cut2 = jieba.analyse.extract_tags(txts.f2,topK = txts.topK, withWeight = True)
#构建向量
for key,value in cut1:
txts.vector1[key] = value
for key,value in cut2:
txts.vector2[key] = value
#利用余弦相似的公式计算相似度
def similar(txts):
txts.vector()
txts.delsim()
sum = 0
for key in txts.vector1:
sum += txts.vector1[key]*txts.vector2[key]
a = sqrt(reduce(lambda x,y: x+y, map(lambda x: x*x, txts.vector1.values())))
b = sqrt(reduce(lambda x,y: x+y, map(lambda x: x*x, txts.vector2.values())))
sum = sum/(a*b)
return sum
计算模块接口部分的性能改进
用函数跑了一下
E:\Python-3.8\python.exe E:/python_pycharm/venv/test/project.py
Running time: 2.5078000000178235 Seconds
不是专业版的pycharm卑微
至于如何改进,那就是我的知识盲区了
计算模块部分单元测试展示
E:\Python-3.8\python.exe E:/python_pycharm/venv/test/test.py
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 1.809 seconds.
Prefix dict has been built successfully.
orig_0.8_add.txt 相似度
0.83
orig_0.8_del.txt 相似度
0.86
orig_0.8_dis_1.txt 相似度
0.97
orig_0.8_dis_10.txt 相似度
0.89
orig_0.8_dis_15.txt 相似度
0.64
orig_0.8_dis_3.txt 相似度
0.94
orig_0.8_dis_7.txt 相似度
0.92
orig_0.8_mix.txt 相似度
0.9
orig_0.8_rep.txt 相似度
0.75
----------------------------------------------------------------------
Ran 9 tests in 5.483s
OK
进程已结束,退出代码0
测试单元代码
import unittest
import project
class MyTest(unittest.TestCase):
def test_add(txts):
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_add.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.getText(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print("orig_0.8_add.txt 相似度")
print(similarity)
def test_del(txts):
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_del.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.getText(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print("orig_0.8_del.txt 相似度")
print(similarity)
def test_dis_1(txts):
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_1.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.getText(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print("orig_0.8_dis_1.txt 相似度")
print(similarity)
def test_dis_3(txts):
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_3.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.getText(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print("orig_0.8_dis_3.txt 相似度")
print(similarity)
def test_dis_7(txts):
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_7.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.getText(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print("orig_0.8_dis_7.txt 相似度")
print(similarity)
def test_dis_10(txts):
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_10.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.getText(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print("orig_0.8_dis_10.txt 相似度")
print(similarity)
def test_dis_15(txts):
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_15.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.getText(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print("orig_0.8_dis_15.txt 相似度")
print(similarity)
def test_mix(txts):
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_mix.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.getText(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print("orig_0.8_mix.txt 相似度")
print(similarity)
def test_rep(txts):
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_rep.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.getText(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print("orig_0.8_rep.txt 相似度")
print(similarity)
if __name__ == '__main__':
unittest.main()
异常处理
- 空文本的情况
try:
# 求解
except Exception as e:
print(e) # 异常类型
return 0.0 # 对于零向量 余弦值为0
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 200 | 230 |
| · Analysis | · 需求分析 (包括学习新技术) | 800 | 1400 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 40 |
| · Design | · 具体设计 | 40 | 60 |
| · Coding | · 具体编码 | 50 | 70 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 20 | 30 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 40 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 50 |
| · 合计 | 1400 | 2200 |
总结
1、这大概是我大学以来遇到最大的坎吧(望天 它不是难 它是那种、那种无从下手的感觉 同时也让自己意识到了计算机水太深自己需要走的路还很长很长从艰难的学python到艰难的用python 真的觉得自己应该早点趁课余时间多学点东西 就不会这么无措了
2、这次作业让我收获很多 算是第一次意识到“项目”到底是个怎样的东西,而不是一直停留在打代码的阶段 让我对于计算机这个领域有了新认识
3、从一开始的特别丧一直抱怨到慢慢摸出了个雏形 我觉得这是一次自我的突破 让我觉得原来我也是可以的虽然花了大佬的好几倍精力和时间 死了一堆脑细胞但最终还是做到了 不容易害
4、害也不知道说啥 就下次继续努力吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号