对浏览器的工作原理的理解( 以chrome浏览器为例 ) --学习总结
首先,在浏览器中输入网址(服务器地址),浏览器会去下载相对应的静态资源文件,第一个下载的是html文件(一般为index.html),在html文件中遇到类似的link标以及script标签的时候,会去下载相对应的css文件和javaScrpt文件。
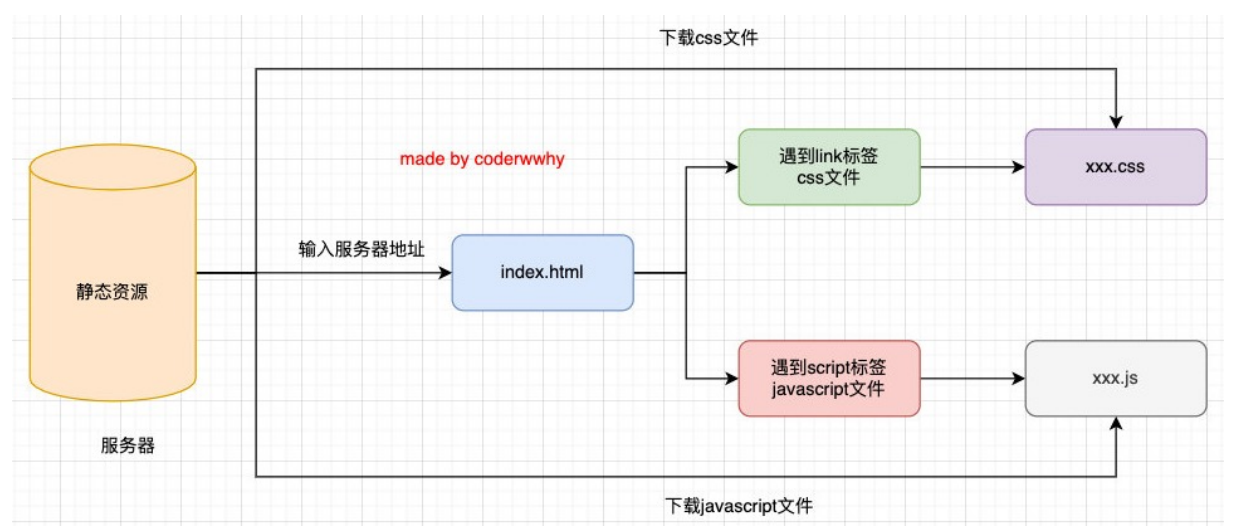
在下载完对应的文件之后,chrome浏览器中的浏览器内核和js引擎(v8引擎)会对相对应的资源文件进行解析。
浏览器内核主要进行html解析,布局和渲染等等相关的工作,html文件会通过html解析器进行解析,生成相对应的DOM树结构,同时css文件会被css解析器进行解析,生成相对应的样式规则,两者附加在一起,生成对应的render树结构,然后通过浏览器内核进行渲染和绘制。
在html解析的过程中,如果遇到了script标签,html的解析过程就会暂时中止,由js引擎去执行相关的js代码。解析完成之后,会针对DOM做出相对应的改变,生成DOM树,继续上述操作。
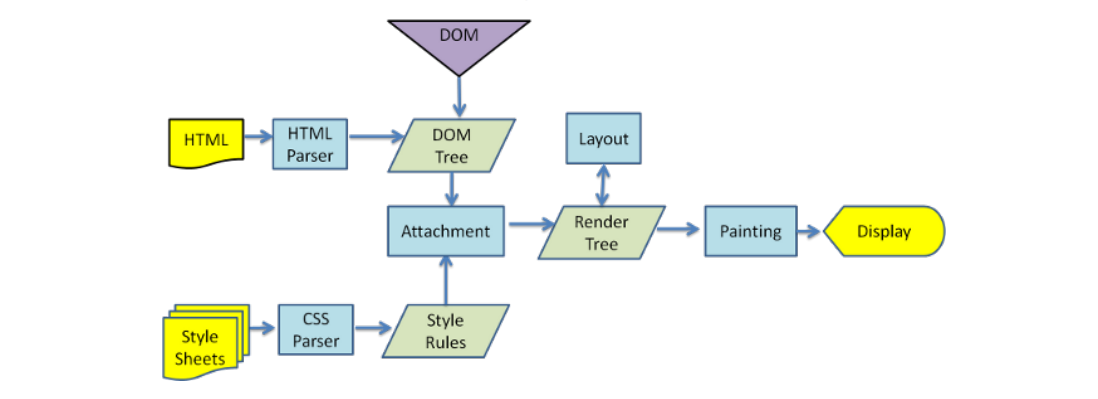
其中 ----js引擎针对js代码进行解析和运行的原理 (实质上是将 js代码转换为机器能够识别的CPU指令)
针对js源代码,v8引擎对其进行解析,通过词法分析和语法分析处理,生成对应的抽象语法树(AST)。据抽象语法树,通过ignition( 解释器 ),将其解释为byteCode(字节码,考虑到不同操作系统CPU的不同,故而转换为通用字节码 ),在这个过程中会收集TurboFan(编译器)所需要的信息,比如函数参数的类型信息等,如果这个函数就被调用一次,会被Ignition(解释器)正常转换为字节码,得到运行结果;如果这个函数被多次调用,会被Turbofan(编译器)标记为热点函数,并且针对这个函数会被转化为MachineCode(优化的机器码),进行得到运行结果。如果这个过程中,比如函数参数的类型发生了变化,跟之前的产生了不一致,MachineCode(优化的机器码)会重新转换为byteCode, 进而得到运行结果。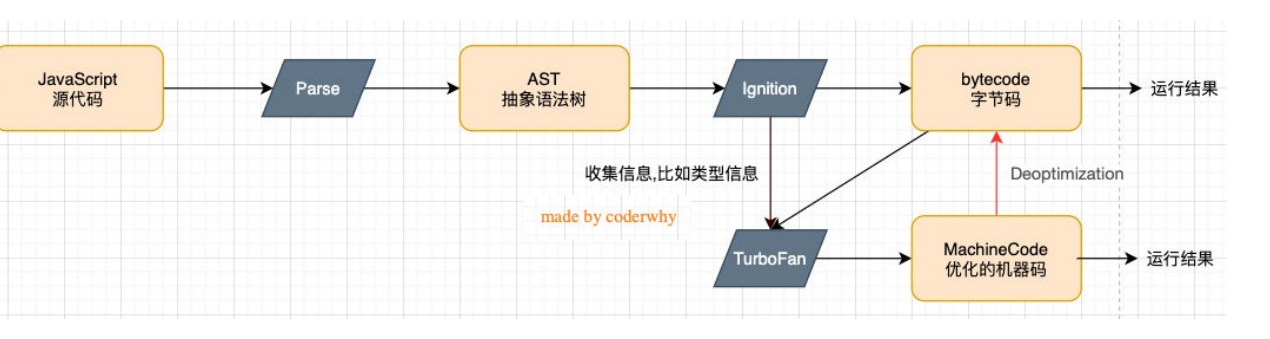
通过这个总结明确了几个问题:
1.浏览器工作原理
2.浏览器的渲染过程
3.在渲染过程中遇到了script标签,浏览器会怎么做(v8引擎针对js代码解析的工作原理)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号