
OO第一单元实验总结报告
1.结构的迭代
总体思路是先无视未知数之类的事物,将题目先当成一个纯数字运算,并利用递归下降来解决。然后将数字用下面描述的Expr来替换,数字运算用相应重载运算符的方法替换,这样就完成了。UML图见下。
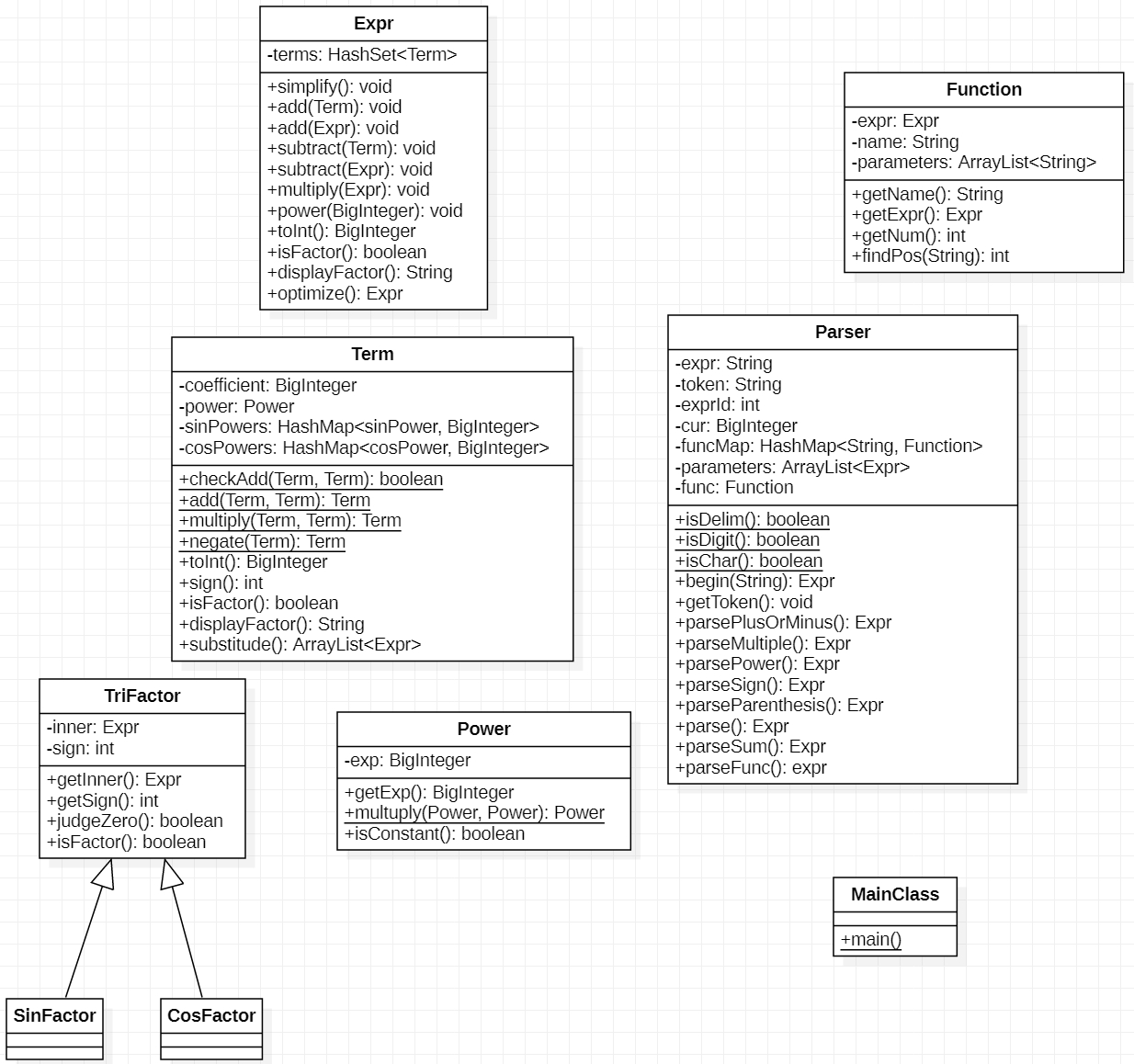
(具体使用的Parser中的方法命名改动了一下,更加便于理解了)
1.1 数据的储存
第一次作业中结果是个多项式\(\displaystyle\sum_{i=0}^na_ix^i\)的形式,每一个项由指数与系数组成。设计的结构应该能够做到方便合并同类项,而同类项的标志是指数相同,故可以将指数作为键,系数作为值来储存。
接下来的第二次作业中增加了三角函数,合并后结果形如\(\sum a_ix^i\prod\sin(\dots)^{p_j}\prod\cos(\dots)^{q_k}\)的形式,由此可见一个项应该具有系数,指数,与三角函数部分。我们可以沿用第一次作业的思路,将三角函数作为键,指数作为值来储存。这样方便与两个项的乘法。具体可以参照UML图上关于Term的部分。
而一个Expr是若干个项的代数和,我们可以用一个HashSet来储存它们。这样的好处是在重载equals的时候可以直接使用HashSet、HashMap的相应方法来判断,这样比较不需要考虑顺序的问题。
这样的结构在面对嵌套三角是很容易迭代开发,只需要在自己三角类中成员定为另一个Expr即可。这样递归的定义便可以快速解决问题。
这样我们就有了合适的储存结构,在这基础上只用为它们添加运算方法就可以将任务分解开了。我们在进行表达式解析时只需要将结果视为一个个Expr在用重载运算符的思想连接起来就行了。这样就完成了数据与功能的解耦。
1.2 数据的化简
在这一方面我可能做的不是很符合规范。一个更为解耦的思路是专门做一个用于优化的类,但我在这里偷懒的,将它做到了Expr里面的方法,这样增加了耦合度,但也为我们提供了一些方便。
首先是可以便于使用Expr里的私有成员,这样可以不用专门的get和set方法。注意到作业允许了三角函数的嵌套,这意味这如果要化简我们需要递归的在三角内部每一层化简,而现在的思路可以转变为在建立时就将三角内部化简完毕,这样buttom up的方法可以直接使结果正确(但这也会使关掉optimize开关不太可能,也算是一个取舍吧)。
接下来具体讲一下化简策略,首先是利用简单的三角恒等式
\(\sin(-x)=\sin(x), \cos(-x)=\cos(x), \cos(0)=1, \sin(0)=0\)
这些化简可以在生成时进行,在第二次作业中-x与x的取舍是显然的——正数一定更短,但在第三次作业中由于内部结构的复杂化没有简单的判断方式。我的想法很简单,直接比较内部表达式与它取反的长度,选择较小的即可。
然后是较为复杂的三角恒等式\(\sin^2(x)+\cos^2(x)=1\)
在此处我们沿用上一个优化的思路,也即暴力枚举可能性来比较。具体是将每一个Term中不小于二次的正弦和余弦直接替换为上面恒等式另一项(具体实现思考利用表达式运算来完成的)。
一些小的优化是如果三角内部不是表达式因子则可以略去一组括号,我们可以对Expr直接分析来判断是不是可以单独放置。还有就是输出时我们可以将项按它们系数大小排列,这样可以保证如果有正数,他一定是第一位。
1.3 其他
在这次作业中我们要对很多多项进行操作,是对他们修改还是新建一个对象就显得很重要了。在我完成第二次作业的过程中,我对解析的函数实参直接引用传入,导致会在过程中修改实参,一度产生了bug。在修改的过程中,我了解到了clone方法,但这个要处理异常,写起来较为繁琐,我便想直接将一个对象的成员复制到另一个对象当中即可(IDEA提示我这叫做copy constructor)。这在第三次作业当中需要类似于递归的复杂一层层的对象,但在为每个类都写了copy constructor后也是比较方便的。
2.递归下降解析
在阅读其他人的代码过程中,我发现我的递归下降写的更加复杂,将不同的运算符都设置了一个解析函数。这样的好处时比较好写,可能还规避了写一个Operator类,但可能解耦的不够彻底。这样的解析思路是明确的,只需要按照运算符有限顺序来处理token即可,比较需要注意的是当解析到一个单元token时的处理。
最为简单的是遇到一个数或者变量,这样只需基于此构造一个Expr即可。然后是加入到三角函数。当读到的token是三角函数时,需要递归调用解析的方法来将三角函数内部作为Expr来构造。
较为复杂的对sum和自定义函数的处理。遇到sum时先按顺序解析出变量与上下界,在面对最后的式子时,我是新建了一个Parser,并将对应的i传入其中,遇到i时解析为对应值即可。自定义函数的处理需要调用解析方法来依次获得相应的实参,在解析函数遇到形参时,替换为实参所对应的Expr来运算即可。
自己的写法中没有分开Lexer与Parser,这应该算一个失误(当我知道应该这么写时我已经写完了)。
3.bug fix
在第二次作业中,当我解析sum当中的上下界时,采用了一种想当然的方法,也即先读一个token,如果是符号则再读一个token。这本来是一个可行的方法,唯一的问题是我没有考虑正号的情况,在测试时也忽视了这样的样例,导致了错误。但上述方法是对上下界进行了特殊处理,在设计上是不太正确的,修复bug时我采用了一个更为自然的方法。可以将上下界当成一个表达式正常的解析,再转化为一个整数即可,这样的作法是更加减少bug的。
4.复杂度分析
4.1 方法复杂度
method |
CogC |
ev(G) |
iv(g) |
v(G) |
|---|---|---|---|---|
Parser.getToken() |
33 | 3 | 17 | 23 |
parser.parse() |
11 | 7 | 10 | 10 |
term.Expr.add(Term) |
4 | 4 | 3 | 4 |
term.Expr.toString() |
8 | 5 | 4 | 6 |
term.Power.display() |
3 | 4 | 1 | 4 |
term.Term.display() |
19 | 4 | 11 | 15 |
term.Term.displayFactor() |
18 | 7 | 19 | 19 |
term.Term.isFactor() |
7 | 4 | 11 | 14 |
term.Term.multyply(Term, Term) |
10 | 1 | 7 | 7 |
term.Term.substitude() |
12 | 1 | 7 | 7 |
- 以上列举的是部分复杂度较高的类方法。
- 可以看到Parser中两个方法因为有着很长的分支判断语句,复杂度高
- Term、Expr中因为输出需要化简,需要进行判断与分类,可以看到这部分也很高
- 用于运算的乘法是最为复杂的,然后还有化简逻辑中的替代方法,因为运算很麻烦,故复杂度高
4.2 类复杂度
Class |
OCavg |
OCmax |
WMC |
|---|---|---|---|
MainClass |
2.00 | 2 | 2 |
Function |
1.60 | 4 | 8 |
Parser |
3.00 | 16 | 51 |
term.Expr |
2.40 | 6 | 48 |
term.Term |
3.47 | 14 | 66 |
term.Power |
1.70 | 4 | 17 |
term.TriFactor |
1.70 | 5 | 17 |
term.CosPower |
1.60 | 3 | 8 |
term.SinPower |
1.60 | 3 | 8 |
- 在Term、Expr中有着较为复杂度运算逻辑与输出逻辑,复杂度高
5.Hacking
用了给自己测试用的特殊样例,在第二次与第三次中均hack掉了一个人。
第二次是sin(-1),hack的对象无法在三角函数中处理前导符号。
第三次是sum(i,-1,1,sin(i**2)),通过阅读hack对象的代码,可以发现在处理sum时他采用了直接替换i的手段而忘记添加括号,这导致替换对象是负数时会出现错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号