爬虫_059_urllib post请求百度翻译
分析百度翻译找接口
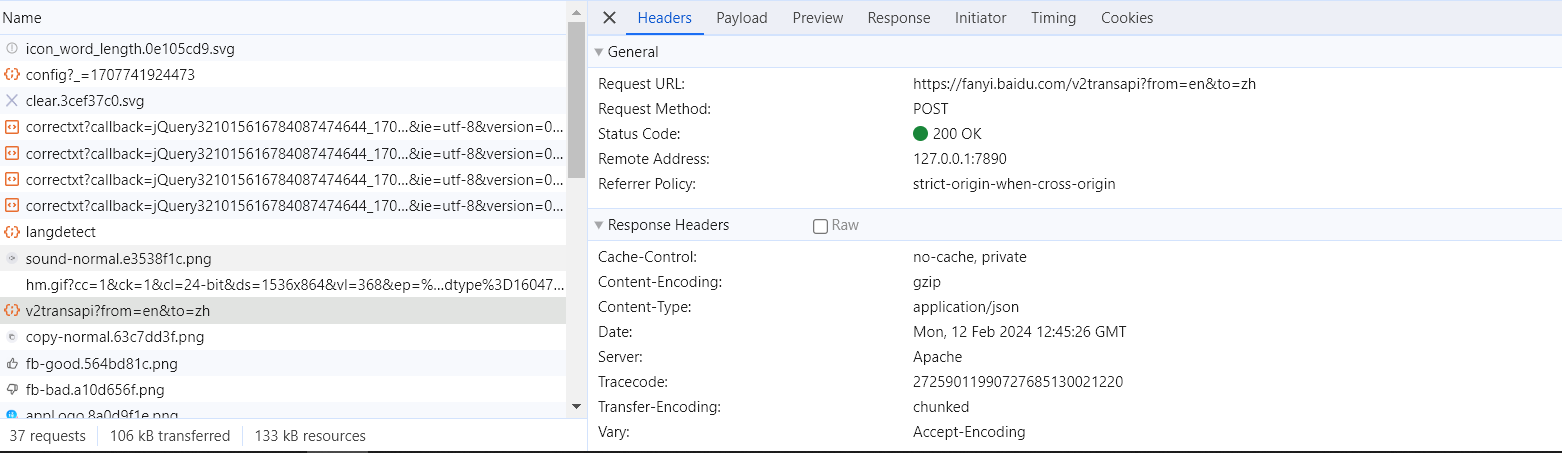
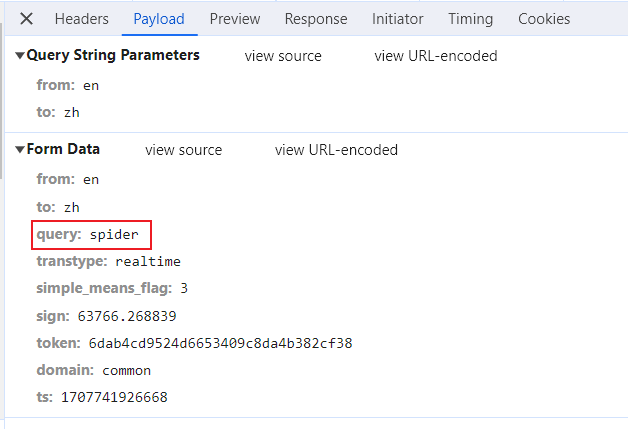
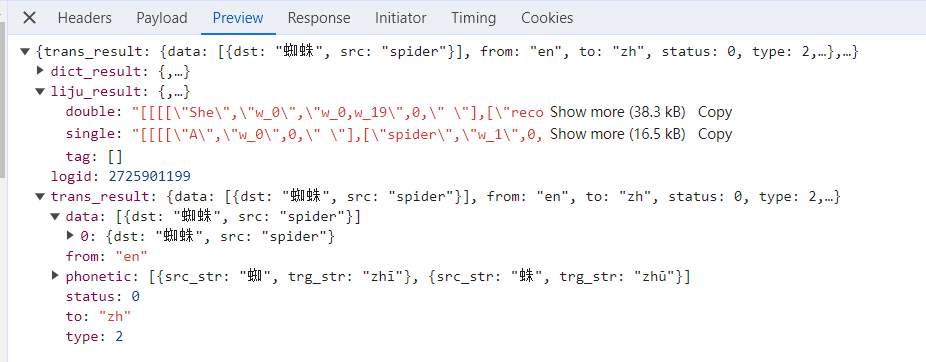
编写代码
import urllib.request
import urllib.parse
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
# post请求的参数必须要进行编码
data = {
'from': 'en',
'to': 'zh',
'query': 'spider',
'transtype': 'realtime',
'simple_means_flag': 3,
'sign': 63766.268839,
'token': '6dab4cd9524d6653409c8da4b382cf38',
'domain': 'common',
'ts': 1707741926668
}
data = urllib.parse.urlencode(data)
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
这里有没有发现一个很有意思的地方。
如果是get请求,那么就是用urllib.request.Request(url=url, headers=headers)
如果是post请求,那么就是用urllib.request.Request(url=url, data=data, headers=headers)
需要注意的点
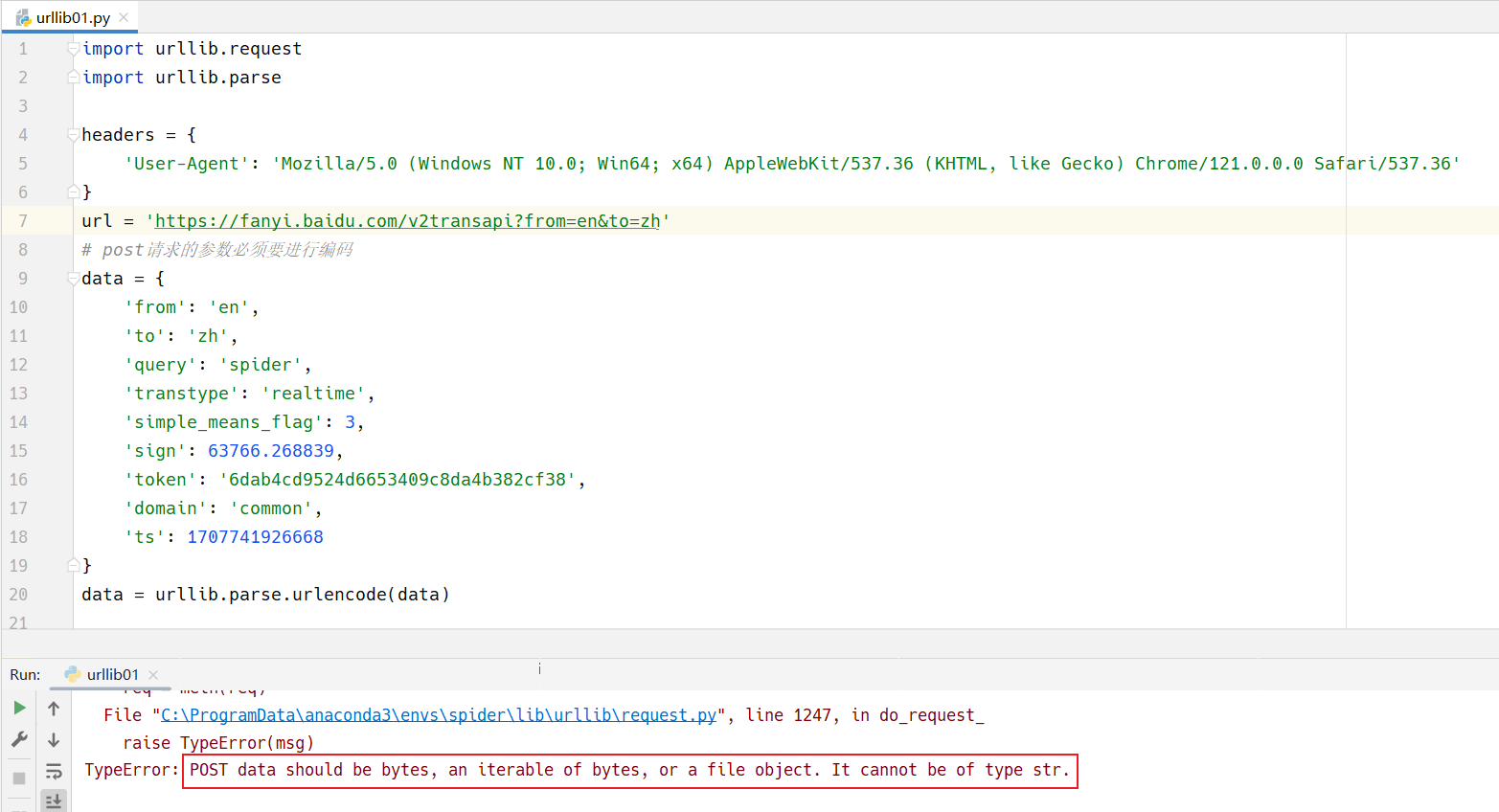
POST请求的data必须是字节,不能够是字符串。
现在我们创建了data,这是一个对象,然后我们通过urlencode将这个对象变成了字符串。
但是必须再通过编码,让它变成字节形式。
修改代码
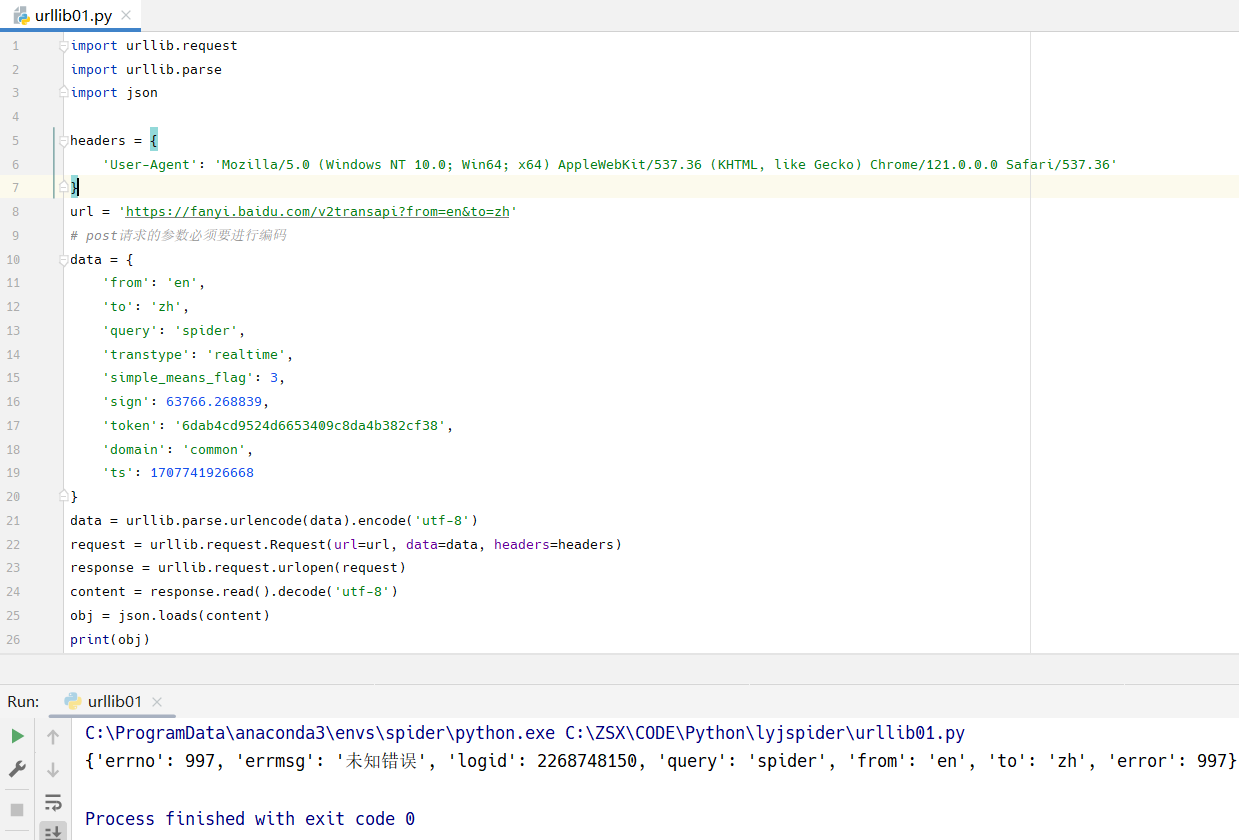
import urllib.request
import urllib.parse
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
# post请求的参数必须要进行编码
data = {
'from': 'en',
'to': 'zh',
'query': 'spider',
'transtype': 'realtime',
'simple_means_flag': 3,
'sign': 63766.268839,
'token': '6dab4cd9524d6653409c8da4b382cf38',
'domain': 'common',
'ts': 1707741926668
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
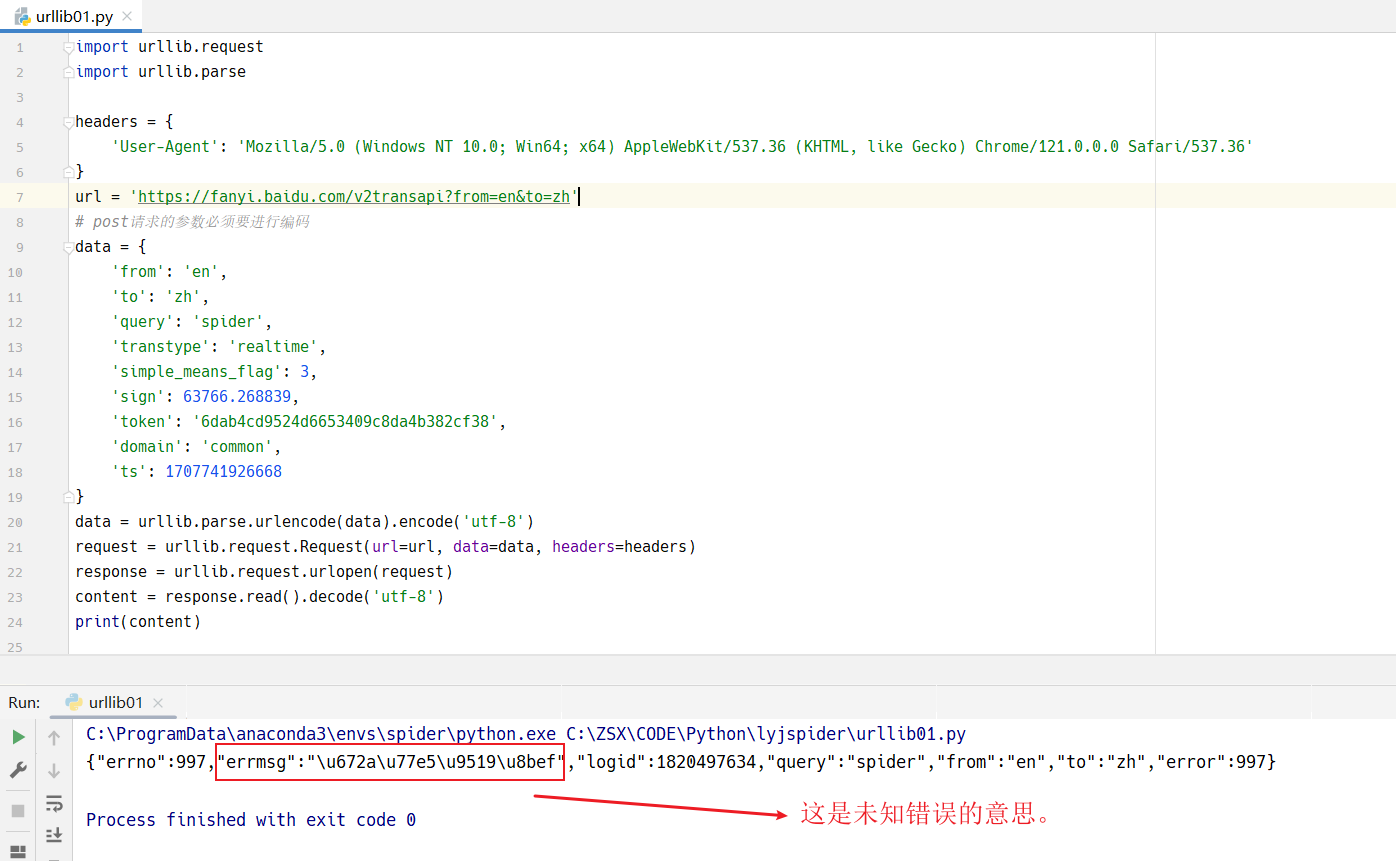
\u672a\u77e5\u9519\u8bef 是一个 Unicode 转义序列,它表示一串中文字符。
具体来说,每一个 \u 后面的四个十六进制数字代表一个 Unicode 码点,这个码点对应一个字符。
\u672a对应汉字 "未"\u77e5对应汉字 "知"\u9519对应汉字 "错"\u8bef对应汉字 "误"
所以,整个字符串 \u672a\u77e5\u9519\u8bef 转换成中文字符就是 "未知错误"。
虽然是未知错误,但是已经证明能够请求了。错误的原因,可能是header的构建,不够完整。
返回数据解析
从上面的报错中,我们可以看到返回的是一个json字符串类型的数据。
import urllib.request
import urllib.parse
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
# post请求的参数必须要进行编码
data = {
'from': 'en',
'to': 'zh',
'query': 'spider',
'transtype': 'realtime',
'simple_means_flag': 3,
'sign': 63766.268839,
'token': '6dab4cd9524d6653409c8da4b382cf38',
'domain': 'common',
'ts': 1707741926668
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
obj = json.loads(content)
print(obj)
最后的说明
我上面使用的接口,是百度翻译的详细翻译接口,不是简单翻译的接口。
其实,应该使用下面的接口:

用这个接口的话,就很容易得到结果,如下图所示:
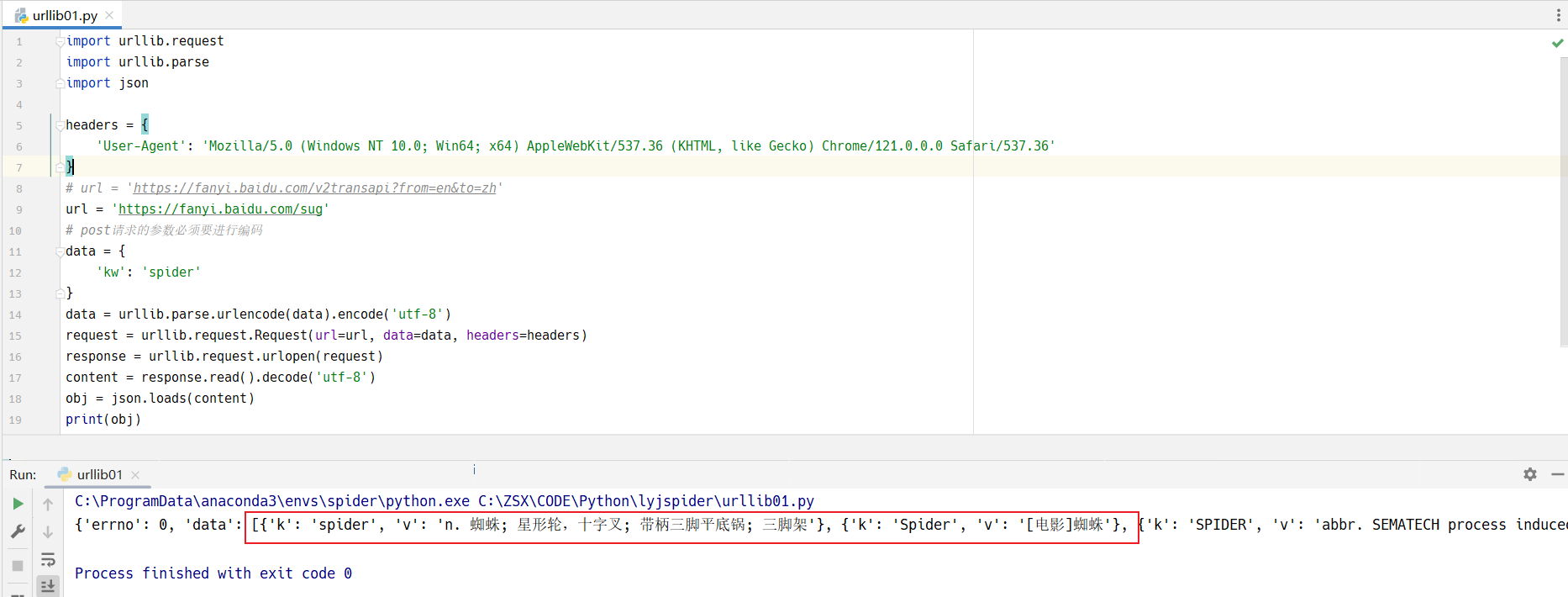
import urllib.request
import urllib.parse
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
# url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
url = 'https://fanyi.baidu.com/sug'
# post请求的参数必须要进行编码
data = {
'kw': 'spider'
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
obj = json.loads(content)
print(obj)

乖乖学习,好好做事。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号