爬虫_058_urllib get请求的urlencode方法
quote方法使用的不是很经常的。
因为quote的作用是将汉字转为百分号编码后的ASCII字符串。
如果你的路径当中只有一个参数,你这样使用quote拼接一下url,这是没有问题的。
如果你的路径当中有多个参数,并且参数都是中文的,你还使用quote,就TMD懵逼了。
所以,quote方法,只需要了解一下,就可以了。
我们需要使用新的方法。
urllib.parse.urlencode()
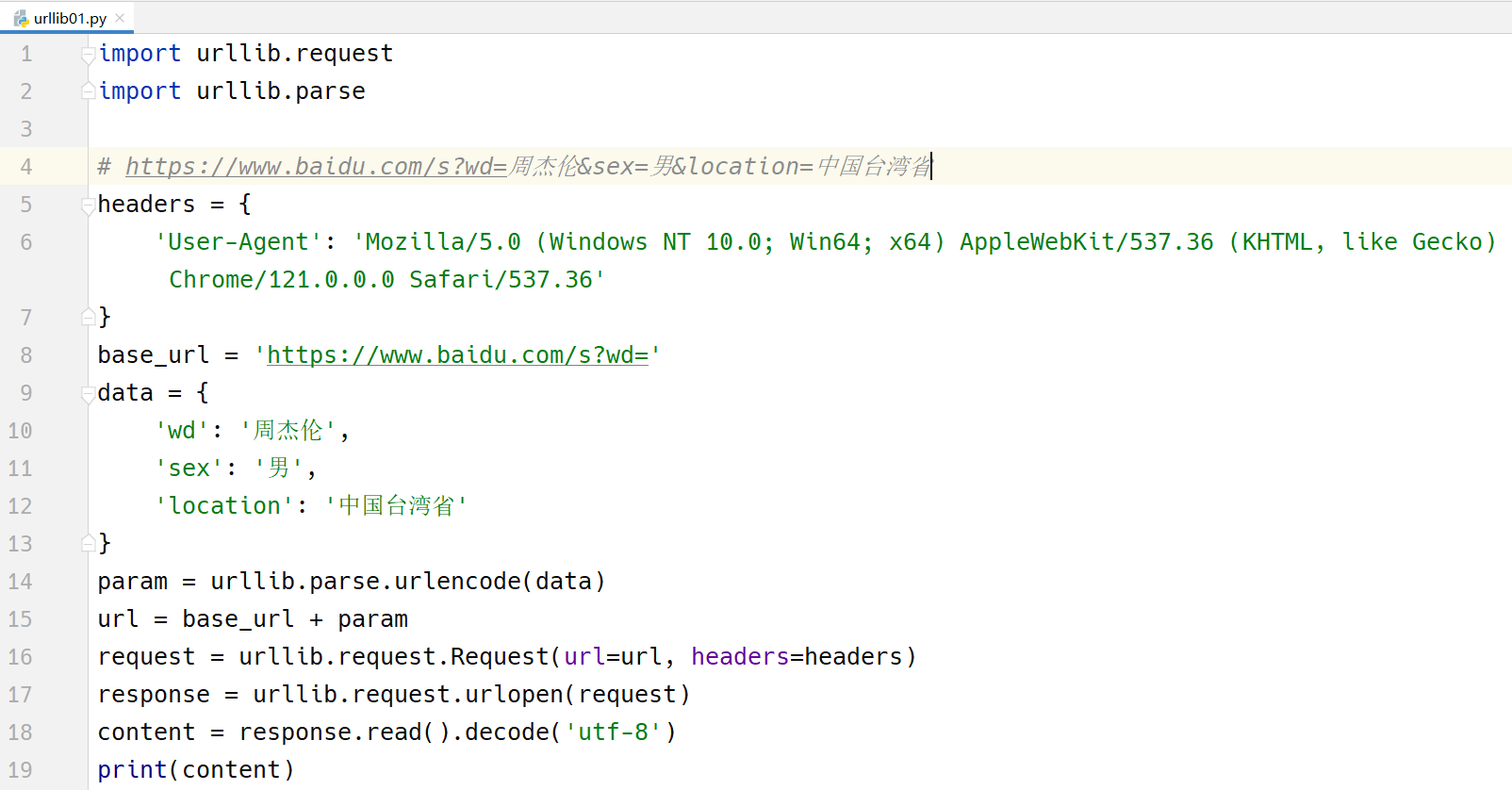
import urllib.request
import urllib.parse
# https://www.baidu.com/s?wd=周杰伦&sex=男&location=中国台湾省
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
base_url = 'https://www.baidu.com/s?wd='
data = {
'wd': '周杰伦',
'sex': '男',
'location': '中国台湾省'
}
param = urllib.parse.urlencode(data)
url = base_url + param
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)

乖乖学习,好好做事。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号