爬虫_057_urllib get请求的quote方法
引子
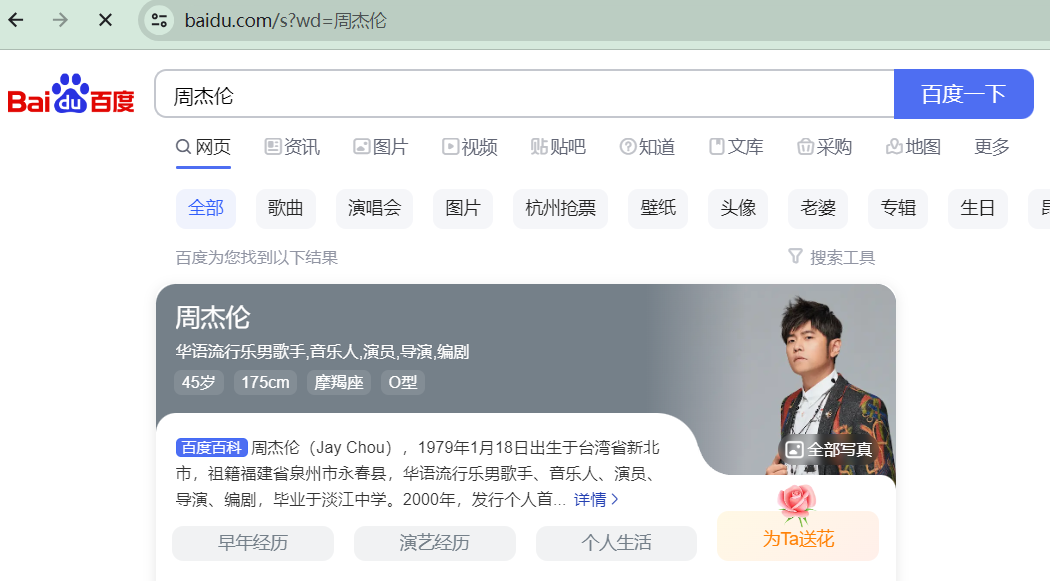
将百度搜索周杰伦的地址栏地址,复制到pycharm当中变成下面的样子:
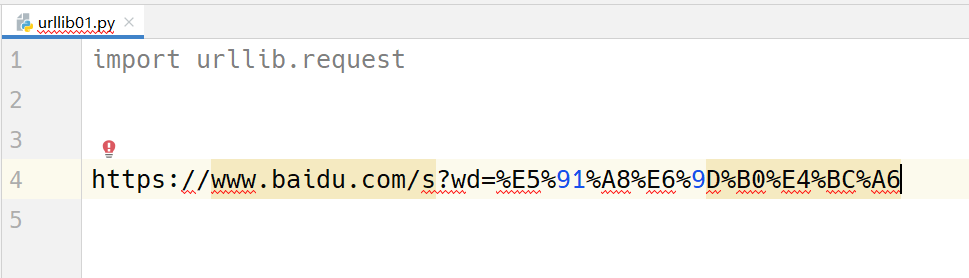
https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
编码集的演变

- ASCII编码:一个字符一个字节
- 中国:GB2312
- 日本:Shift_JIS
- 韩国:Euc-kr
- Unicode:大一统
周杰伦三个字变成了%E5%91%A8%E6%9D%B0%E4%BC%A6这是Unicode编码
需求
获取https://www.baidu.com/s?wd=周杰伦网页的源码。
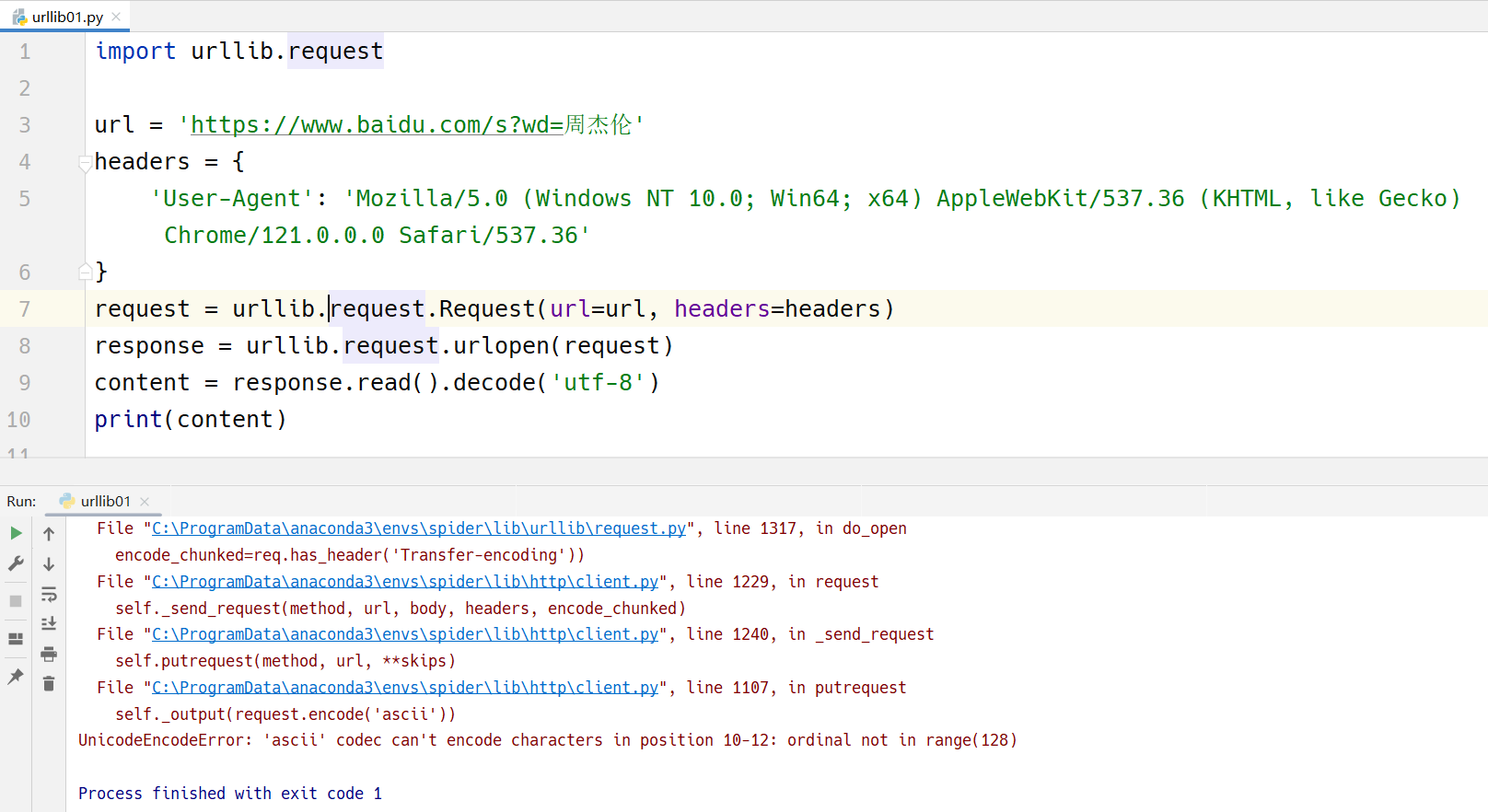
我们直接去请求的时候,就出现了上面的错误。
这个错误叫做:UnicodeEncodeError: 'ascii' codec can't encode characters in position 10-12: ordinal not in range(128)
为什么会出现这个错误呢?
这是因为有一个事实,我们没有认识到。
这个事实是什么?
这个事实是,URL当中的字符,注意,我说的是字符,必须都是ASCII码表当中的字符。
换一种更加准确的说法是,URL当中必须是ASCII字符串。
URL标准(RFC3986)最初是为ASCII字符设计的。
那么我们想要在URL当中放置非ASCII编码的字符怎么办呢?
例如上面的例子当中,我们想要放置周杰伦。
我们应该怎么办呢?
我们需要使用的方式是:百分号编码(percent-encoding)
什么是百分号编码呢?
这是一种将非ASCII编码字符转换为ASCII字符串的方法。
周杰伦三个字的UTF-8编码是:
- 周: E5 91 A8
- 杰: E6 9D B0
- 伦: E4 BB AA
所以,周杰伦三个字的UTF-8编码连接起来是:E591A8E69DB0E4BBAA。
使用百分号编码了之后,就变成了%E5%91%A8%E6%9D%B0%E4%BB%AA。
这个东西,每一个字符都是在ASCII表当中的,可以称之为ASCII字符串。
这个ASCII字符串,就可以放置在URL当中了。
知识点
通过将非ASCII字符转换为百分号编码的形式,确保了URL路径中的每个字符都在ASCII字符表中的范围内。
这样可以确保URL可以正确传输和处理,而不会引起歧义或错误解析。
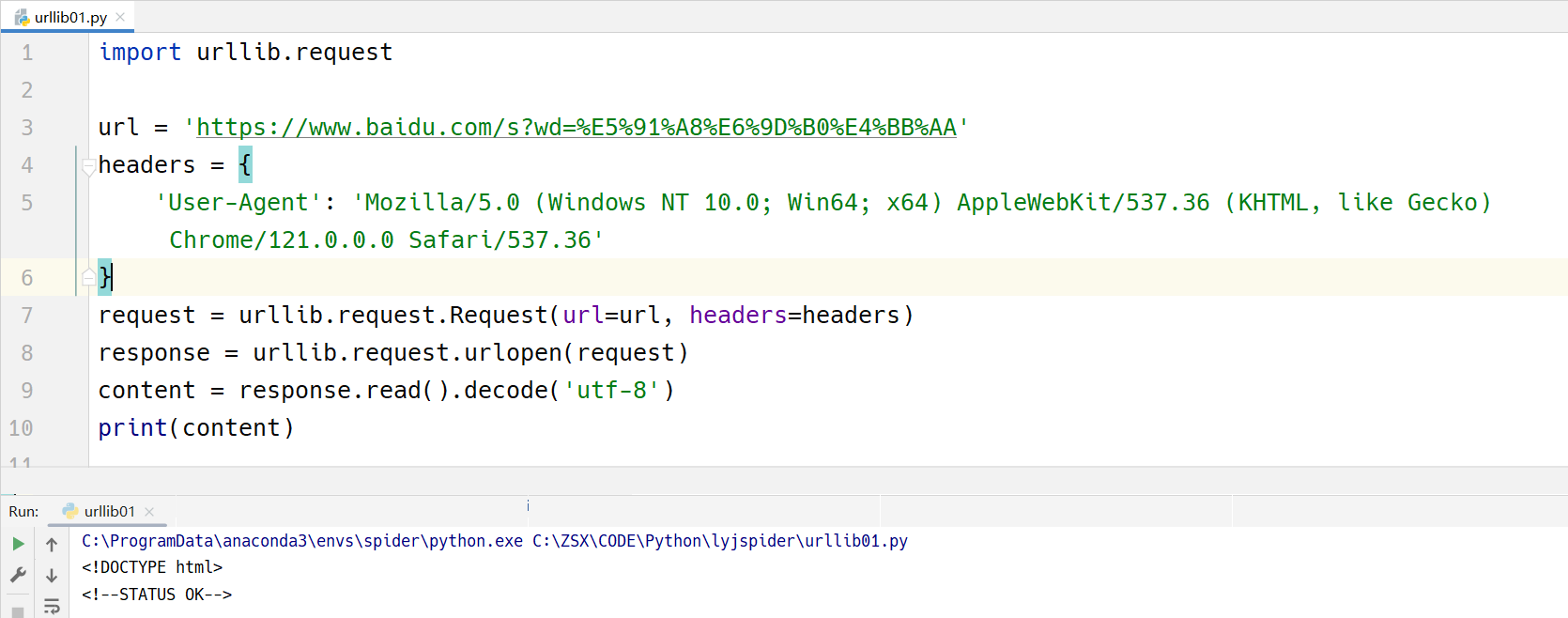
重新测试
将url当中的周杰伦三个字,换成百分号编码后的ASCII字符串,这样就成功了。
get请求方式的quote方法
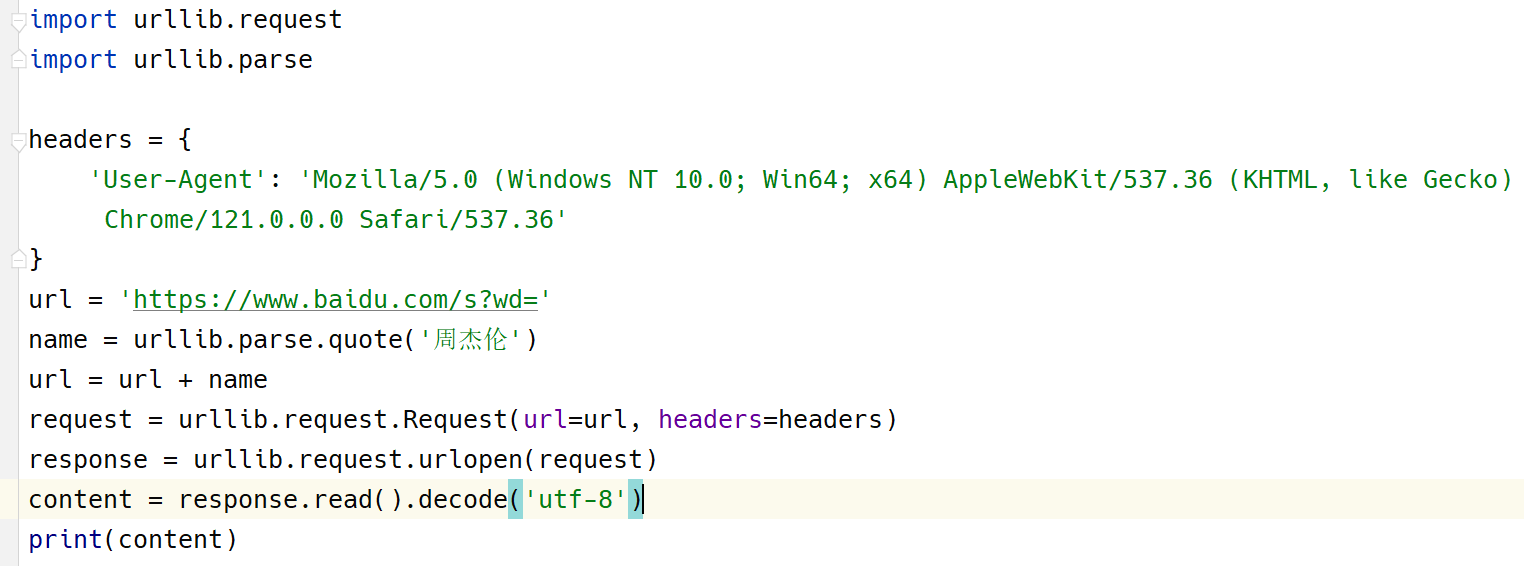
import urllib.request
import urllib.parse
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
url = 'https://www.baidu.com/s?wd='
name = urllib.parse.quote('周杰伦')
url = url + name
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号