
spider-01 selenium模拟淘宝登录,简单爬取数据
selenium的配置什么的不多赘述
爬虫目标是搜索某个关键词的所有数据
首先初始化浏览器
browser = webdriver.Chrome() wait = WebDriverWait(browser, 10) # 显性等待10s KEYWORD = 'iPad'
观察URL,很明显可以发现规律为 .taobao.com/search?q + KEYWORD

尝试直接请求该路径,会跳转到登录页面
url = 'https://s.taobao.com/search?q=' + quote(KEYWORD) browser.get(url)
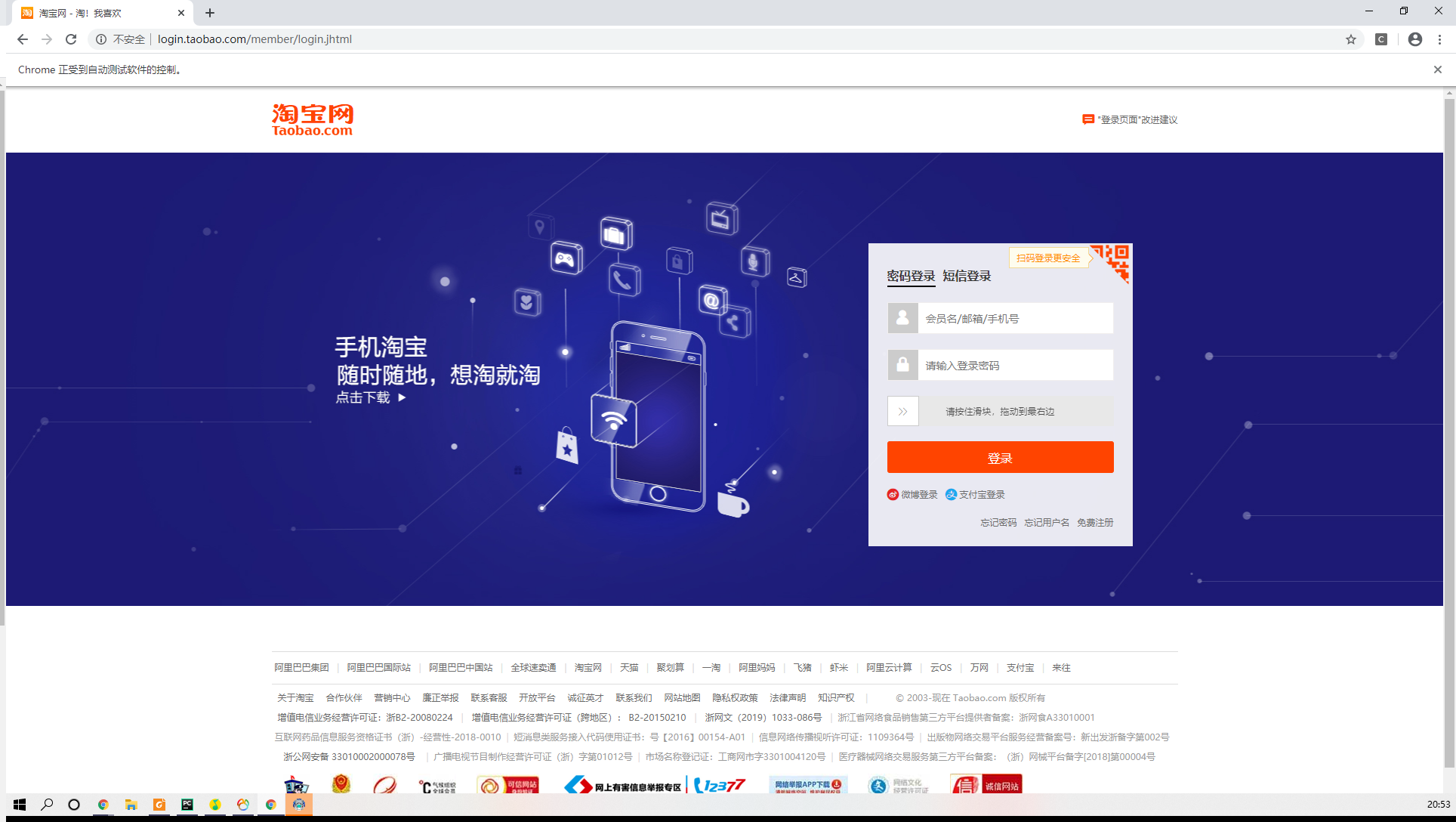
所以我们应该先模拟登录
思路就是选择两个输入框并填入一个已有的淘宝账号,然后将滑动框向右拉(模拟登陆每次都会出现,所以就偷懒不写if判断了),然后点击登录
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
def login(account, password): print('正在登录.....') try: url = 'https://login.taobao.com/member/login.jhtml' browser.get(url) # 账号框 input_account = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#fm-login-id')) ) # 密码框 input_password = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#fm-login-password')) ) # 登陆按钮 btn_login = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, 'div.fm-btn > button')) ) time.sleep(1.5) input_account.send_keys(account) time.sleep(1.5) input_password.send_keys(password) time.sleep(1.5) # 滑动框 slider = browser.find_element_by_id('nc_1_n1z') # 长度固定300,所以直接向右偏移300 webdriver.ActionChains(browser).drag_and_drop_by_offset(slider, 300, 0).perform() time.sleep(1.5) # 点击登录 btn_login.click() except TimeoutException: print('登陆超时')
登录成功后,直接请求搜索页面
def get_page(page): print(f'进入第{page}页...') try: url = 'https://s.taobao.com/search?q=' + quote(KEYWORD) # 对汉字进行URL编码 browser.get(url) if page > 1: input_obj = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager div.form > input')) ) # 页码输入框 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager div.form > span.btn.J_Submit')) ) # 跳转按钮 input_obj.clear() input_obj.send_keys(page) # 输入页码 submit.click() wait.until( EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)) ) # 如果成功跳转,该页页码会高亮,class中添加active,以此来判断是否跳转 except TimeoutException: get_page(page)
每次运行这个函数,浏览器的页面就会变为对应的页面,我们通过bs4来解析页面获取我们想要的数据
class Product: pro_name = None # 商品名 pro_price = None # 商品价格 pro_deal = None # 商品销量 pro_store = None # 商店 pro_location = None # 位置 def get_products(): print('正在获取数据...') items = [] html = browser.page_source soup = BeautifulSoup(html, 'lxml') products = soup.select('.J_MouserOnverReq') for product in products: item = Product() pro_info = product.find(class_='ctx-box J_MouseEneterLeave J_IconMoreNew') item.pro_name = pro_info.select('.J_ClickStat')[0].get_text().strip() item.pro_price = float(pro_info.select('div[class="price g_price g_price-highlight"]')[0].get_text().strip()[1:]) item.pro_deal = pro_info.select('div[class="deal-cnt"]')[0].get_text().strip() item.pro_store = pro_info.select('.shopname')[0].get_text().strip() item.pro_location = pro_info.select('div[class="location"]')[0].get_text().strip() items.append(item) return items
最后保存到mysql数据库中
def save_to_mysql(items): try: db = pymysql.connect(host='localhost', port=3306, user='user', password='password', db='spider_taobao', charset='utf8mb4') # 打开数据库连接 cursor = db.cursor() # 创建一个游标对象 for item in items: sql_insert = "INSERT INTO products(pro_name, pro_price, pro_deal, pro_store, pro_location) " \ f"VALUES ('{item.pro_name}',{item.pro_price},'{item.pro_deal}','{item.pro_store}','{item.pro_location}')" try: cursor.execute(sql_insert) db.commit() except pymysql.Error: db.rollback() db.close() print(f'插入了{len(items)}条数据') except pymysql.MySQLError as e: print(e.args) return None
整个流程就是 模拟登录-->进入页面-->获取数据-->保存数据
项目代码:


import time import pymysql from urllib.parse import quote from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # chrome_options = webdriver.ChromeOptions() # chrome_options.add_argument('--headless') browser = webdriver.Chrome() wait = WebDriverWait(browser, 10) # 显性等待10s KEYWORD = 'iPad' class Product: pro_name = None # 商品名 pro_price = None # 商品价格 pro_deal = None # 商品销量 pro_store = None # 商店 pro_location = None # 位置 def login(account, password): print('正在登录.....') try: url = 'https://login.taobao.com/member/login.jhtml' browser.get(url) # 账号框 input_account = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#fm-login-id')) ) # 密码框 input_password = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#fm-login-password')) ) # 登陆按钮 btn_login = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, 'div.fm-btn > button')) ) time.sleep(1.5) input_account.send_keys(account) time.sleep(1.5) input_password.send_keys(password) time.sleep(1.5) # 滑动框 slider = browser.find_element_by_id('nc_1_n1z') # 长度固定300,所以直接向右偏移300 webdriver.ActionChains(browser).drag_and_drop_by_offset(slider, 300, 0).perform() time.sleep(1.5) # 点击登录 btn_login.click() except TimeoutException: print('登陆超时') def save_to_mysql(items): try: db = pymysql.connect(host='localhost', port=3306, user='root', password='T85568397', db='spider_taobao', charset='utf8mb4') # 打开数据库连接 cursor = db.cursor() # 创建一个游标对象 for item in items: sql_insert = "INSERT INTO products(pro_name, pro_price, pro_deal, pro_store, pro_location) " \ f"VALUES ('{item.pro_name}',{item.pro_price},'{item.pro_deal}','{item.pro_store}','{item.pro_location}')" try: cursor.execute(sql_insert) db.commit() except pymysql.Error: db.rollback() db.close() print(f'插入了{len(items)}条数据') except pymysql.MySQLError as e: print(e.args) return None def get_products(): print('正在获取数据...') items = [] html = browser.page_source soup = BeautifulSoup(html, 'lxml') products = soup.select('.J_MouserOnverReq') for product in products: item = Product() pro_info = product.find(class_='ctx-box J_MouseEneterLeave J_IconMoreNew') item.pro_name = pro_info.select('.J_ClickStat')[0].get_text().strip() item.pro_price = float(pro_info.select('div[class="price g_price g_price-highlight"]')[0].get_text().strip()[1:]) item.pro_deal = pro_info.select('div[class="deal-cnt"]')[0].get_text().strip() item.pro_store = pro_info.select('.shopname')[0].get_text().strip() item.pro_location = pro_info.select('div[class="location"]')[0].get_text().strip() items.append(item) return items def get_page(page): print(f'进入第{page}页...') try: url = 'https://s.taobao.com/search?q=' + quote(KEYWORD) # 对汉字进行URL编码 browser.get(url) if page > 1: input_obj = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager div.form > input')) ) # 页码输入框 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager div.form > span.btn.J_Submit')) ) # 跳转按钮 input_obj.clear() input_obj.send_keys(page) # 输入页码 submit.click() wait.until( EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)) ) # 如果成功跳转,该页页码会高亮,class中添加active,以此来判断是否跳转 except TimeoutException: get_page(page) if __name__ == '__main__': login('account', 'password') # 模拟登陆 for num in range(20): get_page(num + 1) # 进入页面 product_data = get_products() # 获取页面数据 save_to_mysql(product_data) # 保存到mysql中
运行结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号