Linux Shell中管道的原理及C实现框架
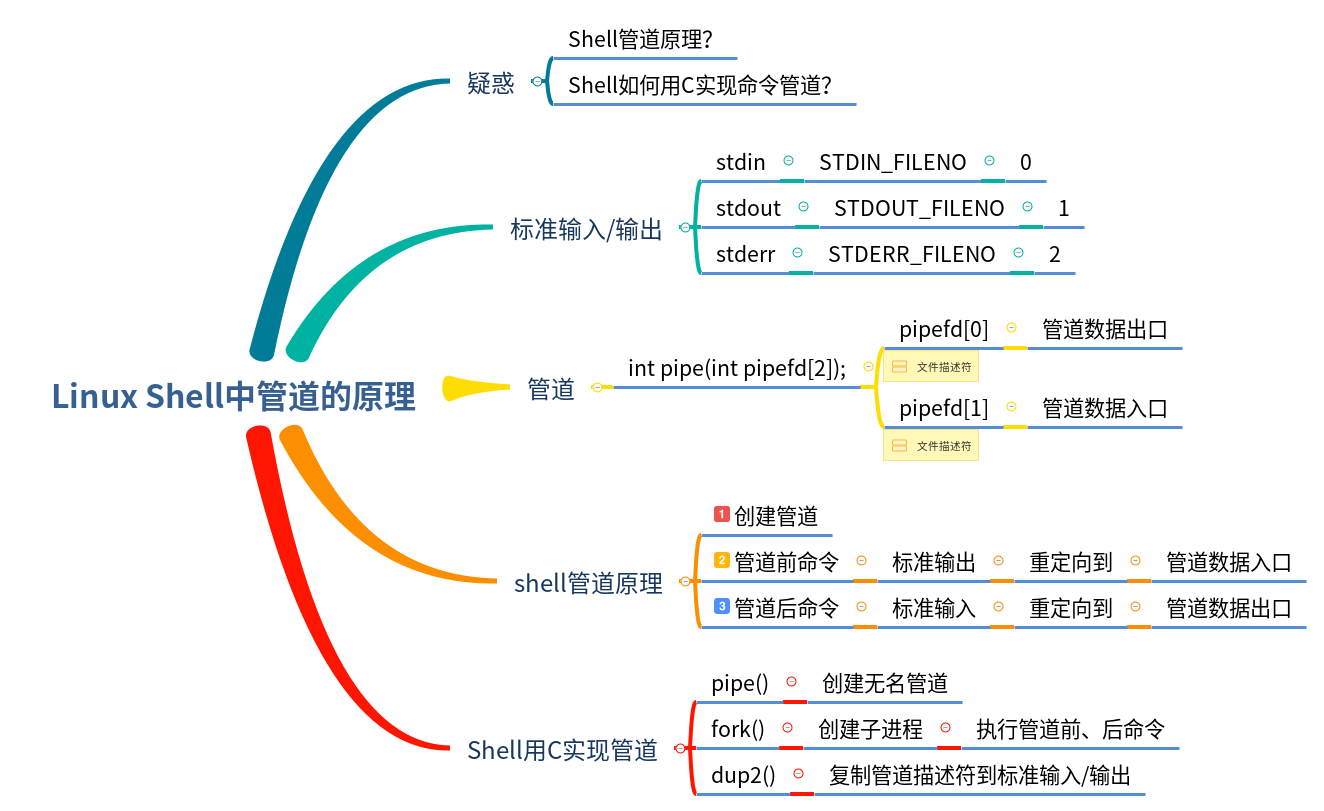
在shell中我们经常用到管道,有没考虑过Shell是怎么实现管道的呢?
cat minicom.log | grep "error"
标准输入、标准输出与管道
我们知道,每一个进程都有3个标准的输入输出文件描述符
| 描述符编号 | 简介 | 作用 |
|---|---|---|
| 0 | 标准输入 | 通用于获取输入的文件描述符 |
| 1 | 标准输出 | 通用输出普通信息的文件描述符 |
| 2 | 标准错误 | 通用输出错误信息的文件描述符 |
我们还知道,系统调用pipe可以创建无名管道
int pipe(int pipefd[2]);
pipe的作用是创建无名管道,并创建两个文件描述符
| 文件描述符 | 作用 |
|---|---|
| pipefd[0] | 管道数据出口 |
| pipefd[1] | 管道数据入口 |
Shell实现管道的原理
在上文的基础上,我们再看看Shell如何实现管道的。
Shell中通过fork+exec创建子进程来执行命令。如果是含管道的Shell命令,则管道前后的命令分别由不同的进程执行,然后通过管道把两个进程的标准输入输出连接起来,就实现了管道。
例如
grep "error" minicom.log | awk '{print $1}'
这句命名的作用非常简单,
- 通过
grep命令在minicom.log中检索含有error关键字的行 - 通过
awk命令打印grep的输出结果中每一行的第一个字段
在Shell中要实现这样的效果,有4个步骤:
- 创建pipe
- fork两个子进程执行grep和awk命令
- 把grep子进程的标准输出、标准错误重定向到管道数据入口
- 把awk子进程的标准输入重定向到管道数据出口
这样就实现了Shell管道:grep把结果输出到管道,awk从管道获取数据
Shell如何用C实现管道
我没研究过Shell的代码,但不妨碍我们从功能倒推实现,如果是我,我会怎么做呢?
int main(int argc, char **argv)
{
while(1) {
int pfds[2];
pid_t cmd1, cmd2;
if ((cmd1 = fork()) < 0) {
...
} else if (cmd1 == 0) { /* child */
/*
* dup2 把 pfds[1](管道数据入口描述符) 复制到 文件描述符1&2
* 实现把cmd1的标准输出和标准错误 输送到管道
*/
dup2(pfds[1], STDOUT_FILENO);
dup2(pfds[1], STDERR_FILENO);
close(pfds[0]);
close(pfds[1]);
exec(cmd1...);
__exit(127);
}
if ((cmd2 = fork()) < 0) {
...
} else if (cmd2 == 0) { /* child */
/*
* dup2 把 pfds[0](管道数据出口描述符) 复制到 文件描述符0
* 实现cmd2从管道中读取(cmd1的输出)数据
*/
dup2(pfds[0], STDIN_FILENO);
close(pfds[0]);
close(pfds[1]);
exec(cmd2...);
__exit(127);
}
close(pfds[0]);
close(pfds[1]);
wait(...);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号