Python语法进阶(2)- 正则表达式
1.初识正则表达式
1.1.什么是正则表达式
正则表达式是一个特殊的字符序列,便于检查一个字符串是否与某种模式匹配;应用于字符串,在字符串中通过复杂的过滤筛选等操作得到我们想要的数据;
正则表达式的特点 :
- 正则表达式的语法太多,可读性差
- 正则表达式通用行很强,能够适用于很多编程语言
1.2.正则表达式的使用场景
在实际开发过程中经常会有查找符合某些复杂规则的字符串的需要,比如:手机号、邮箱、图片地址 等,这时候想匹配或者查找符合某些规则的字符串就可以使用正则表达式了。
1.3.正则表达式模块re的用法
匹配字符串需要的条件:
- 正则表达式模块--re
- 匹配查找的规则
- 被查找的字符串



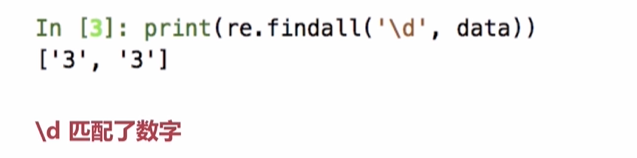
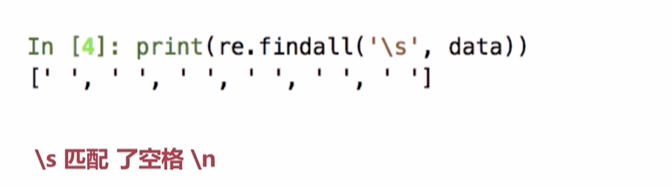
2.正则表达式的字符匹配
1 # coding:utf-8 2 3 import re 4 5 #将字符串中的数字提取出来 6 def had_number(data): 7 result=re.findall('\d',data) 8 print(result) #['3', '3', '1', '7', '5'] 9 for i in result: 10 return True 11 return False 12 13 #去掉字符串中的数字 14 def remove_number(data): 15 result=re.findall('\D',data) 16 print(result) #['m', 'y', ' ', 'n', 'a', 'm', 'e', ' ', 'i', 's', ' ', 'z', 'h', 'a', 'n', 'g', 's', 'a', 'n', ',', 'm', 'y', ' ', 'a', 'g', 'e', ' ', ',', 't', 'o', 'p', ' '] 17 return ''.join(result) 18 19 if __name__=='__main__': 20 data='my name is zhangsan,my age 33,top 175' 21 result=had_number(data) 22 print(result) #True 23 result=remove_number(data) 24 print(result) #my name is zhangsan,my age ,top1 # coding:utf-8 2 3 import re 4 5 #判断字符串以什么开头 6 def startswith(sub,data): 7 _sub='\A%s' % sub 8 result=re.findall(_sub,data) 9 for i in result: 10 return True 11 return False 12 13 #判断字符串以什么结尾 14 def endswith(sub,data): 15 _sub='%s\Z' % sub 16 result=re.findall(_sub,data) 17 if len(result) != 0: 18 return True 19 else: 20 return False 21 22 #判断字符串真实的长度 23 def real_len(data): 24 result=re.findall('\S',data) 25 print(result) #['m', 'y', 'n', 'a', 'm', 'e', 'i', 's', 'z', 'h', 'a', 'n', 'g', 's', 'a', 'n', ',', 'm', 'y', 'a', 'g', 'e', '3', '3', ',', 't', 'o', 'p', '1', '7', '5'] 26 return len(result) 27 28 if __name__=='__main__': 29 data='my name is zhangsan,my age 33,top 175' 30 #startswith 31 result=startswith('my',data) 32 result1=startswith('myw',data) 33 print(result) #True 34 print(result1) #False 35 #endswith 36 result2=endswith('75',data) 37 result3=endswith('000',data) 38 print(result2) #True 39 print(result3) #False 40 #real_len 41 result4=real_len(data) 42 print(len(data)) #37 43 print(result4) #31







3.正则表达式的量词












4.正则的综合练习
1 # coding:utf-8 2 import re 3 4 #网址匹配 5 def check_url(url): 6 result=re.findall('[a-zA-Z]{4,5}://\w*\.*\w+\.\w+',url) 7 if len(result) !=0 : 8 return True 9 else: 10 return False 11 #获取网址,通过组()获取我们过滤出来的信息 12 def get_url(url): 13 result = re.findall('http[a-zA-Z]*://(\w*\.*\w+\.\w+)', url) 14 if len(result) !=0: 15 return result[0] 16 else: 17 return '' 18 19 #检验邮箱是否正确 20 def get_email(data): 21 result=re.findall('.+@.+\.[a-zA-Z]+',data) 22 return result 23 24 #获取网页style属性信息 25 def get_html_data(data): 26 result=re.findall('style="(.*?)"',data) #?的作用:例子中筛选规则结尾的双引号找到一次就结束,而不是贪婪的找到最后一个双引号 27 return result 28 29 #获取网页所有属性的值 30 def get_all_data_html(data): 31 result=re.findall('="(.+?)"',data) 32 return result 33 34 if __name__=='__main__': 35 url = 'http://www.baidu.com' 36 emails='zhangsan@qq.com' 37 html = ('<div class="s-top-nav" style="display:none;">' 38 '</div><div class="s-center-box"></div>') 39 print(check_url(url)) #True 40 print(get_url(url)) #www.baidu.com 41 print(get_email(emails)) #['zhangsan@qq.com'] 42 print(get_html_data(html)) #['display:none;'] 43 print(get_all_data_html(html)) #['s-top-nav', 'display:none;', 's-center-box']
5.正则表达式的re模块
5.1.findall()的使用
5.2.search()的使用
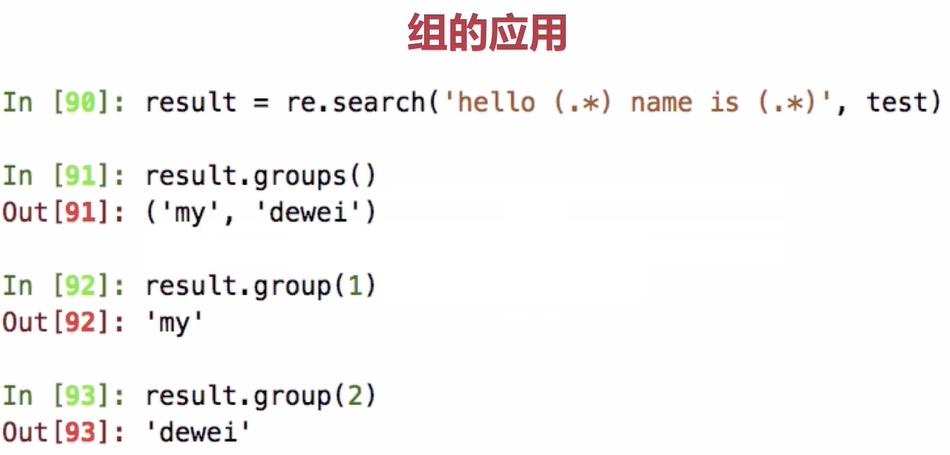
5.3.group()与groups()的使用
跟search()配合使用,search返回匹配对象;group/groups读取组的序列是从1开始
5.4.split()正则替换
根据正则规则对字符串进行切割
\W字符数字以外的字符,相当于根据图示字符串中的空格作为匹配规则,进行切割
5.5.compile的使用
5.6.match的使用
match只会匹配字符串从头开始的信息,match返回的匹配对象也可以通过group进行调用
5.7.re的额外匹配要求
1 # coding:utf-8 2 3 import re 4 5 def check_url(url): 6 re_g = re.compile('[a-zA-Z]{4,5}://\w*\.*\w+\.\w+') 7 print(re_g) #re.compile('[a-zA-Z]{4,5}://\\w*\\.*\\w+\\.\\w+') 8 result = re_g.findall(url) 9 if len(result) != 0: 10 return True 11 else: 12 return False 13 14 def get_url(url): 15 re_g = re.compile('[https://|http://](\w*\.*\w+\.\w+)') 16 result = re_g.findall(url) 17 if len(result) != 0: 18 return result[0] 19 else: 20 return '' 21 22 23 def get_email(data): 24 re_g = re.compile('.+@.+\.[a-zA-Z]+') 25 result = re_g.findall(data) 26 return result 27 28 29 html = ('<div class="s-top-nav" style="display:none;">' 30 '</div><div class="s-center-box"></div>') 31 32 33 def get_html_data(data): 34 re_g = re.compile('style="(.*?)"') 35 result = re_g.findall(data) 36 return result 37 38 def get_all_data_html(data): 39 re_g = re.compile('="(.+?)"') 40 result = re_g.findall(data) 41 return result 42 43 44 if __name__ == '__main__': 45 result = check_url('http://www.baidu.com/') 46 print(result) #True 47 result = get_url('https://www.baidu.com/') 48 print(result, 'get_url') #www.baidu.com get_url 49 result = get_email('dewei@123.net') 50 print(result) #['dewei@123.net'] 51 result = get_html_data(html) 52 print(result) #['display:none;'] 53 result = get_all_data_html(html) 54 print(result) #['s-top-nav', 'display:none;', 's-center-box'] 55 re_g = re.compile(('<div class="(.*?)" style="(.*?)">' 56 '</div><div class="(.*?)"></div>')) 57 result = re_g.search(html) 58 print(result.groups()) #('s-top-nav', 'display:none;', 's-center-box') 59 print(result.group(1)) #s-top-nav 60 print(result.group(2)) #display:none; 61 print(result.group(3)) #s-center-box 62 # print(result.group(4)) 63 re_g = re.compile('\s') 64 result = re_g.split(html) 65 print(result) #['<div', 'class="s-top-nav"', 'style="display:none;"></div><div', 'class="s-center-box"></div>'] 66 67 re_g = re.compile('<div class="(.*?)"') 68 result = re_g.match(html) 69 print(result.span()) #正则对象.span()返回对象的序列范围,(0, 22) 70 print(html[: 22]) #<div class="s-top-nav"











6.Python常见匹配案例
6.1.匹配1-100之间的数
1 import re 2 3 s = '100' # 1-100内的任意数字 4 ret = re.match(r'(100|[1-9]\d{0,1})$', s) 5 print(ret.group()) 6 # 运行结果: 7 # 100
6.2.匹配座机号码
1 import re 2 3 s = "010-12345678" 4 ret = re.search(r'^\d{3,4}-\d{7,8}$', s) 5 print(ret.group()) 6 # 运行结果: 7 # 010-12345678
6.3.匹配5-10位纯数字组成的qq号码,且不能以0开头
1 import re 2 3 s = "11010" 4 ret = re.match(r'[1-9]\d{4,9}$', s) 5 if ret != None: 6 print(ret.group()) 7 else: 8 print('匹配失败!') 9 # 运行结果: 10 # 11010
6.4.取出字符串中的所有字母
1 import re 2 3 s = "43arwer32656fafa6546jjuy#H" 4 res = re.compile(r'[a-zA-Z]+') 5 ret = res.findall(s) 6 print(ret) 7 # 运行结果: 8 # ['arwer', 'fafa', 'jjuy', 'H']
6.5.找出以字母y结尾的单词,忽略大小写
1 import re 2 3 s = 'study hard and make progress every day' 4 res = re.compile(r'\w+y\b', re.I) # \b为边界 5 ret = res.findall(s) 6 print(ret) 7 # 运行结果: 8 # ['study', 'every', 'day']
6.6.将多个重复的字母替换成&
1 import re 2 3 s = "PythondddJavauuuHTMLFFPHP" 4 res = re.compile(r'([a-zA-Z])\1+') 5 ret = res.sub('&', s) 6 print(ret) 7 # 运行结果: 8 # Python&Java&HTML&PHP
6.7.将字符串变成 '我要学Python编程
1 import re 2 3 s = "我我...我我...我要..要要...要要...学学学...学学..Python...编编编..编程..程.程...程...程" 4 res = re.sub(r'\W+', '', s) 5 ret = re.sub(r'(.)\1+', r'\1', res) 6 print(ret) 7 # 运行结果: 8 # 我要学Python编程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号