
人工智能学习——第四课:Tensorflow学习——梯度下降算法优化(打印Tensorflow版本、打印数据集、生成线形图)
一、案例:线性回归实验
# 导入Tensorflow模块定义别名tf
import tensorflow as tf
# 打印Tensorflow版本 print (tf.__version__) 2.19.0
问题:存在无法找到文件
方法1(推荐使用原始字符串):
data = pd.read_csv(r'D:\workspaces\Miniconda_workSpaces\datasheets\1.csv')
方法2(使用双反斜杠,特别注意最后一部分):
data = pd.read_csv('D:\\workspaces\\Miniconda_workSpaces\\datasheets\\1.csv')
方法3(使用正斜杠):
data = pd.read_csv('D:/workspaces/Miniconda_workSpaces/datasheets/1.csv')
# 第一次导入数据集文件income.csv # 报错:数据文件income.csv导入数据集报utf-8编码错误 # 报错信息:“UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 0: invalid continuation byte” # 第一次导入数据集 data = pd.read_csv('./income.csv') # 详细报错 --------------------------------------------------------------------------- UnicodeDecodeError Traceback (most recent call last) Cell In[8], line 1 ----> 1 data = pd.read_csv('./income.csv') File D:\Softwares\miniconda3\envs\Tensorflow\lib\site-packages\pandas\io\parsers\readers.py:1026, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend) 1013 kwds_defaults = _refine_defaults_read( 1014 dialect, 1015 delimiter, (...) 1022 dtype_backend=dtype_backend, 1023 ) 1024 kwds.update(kwds_defaults) -> 1026 return _read(filepath_or_buffer, kwds) File D:\Softwares\miniconda3\envs\Tensorflow\lib\site-packages\pandas\io\parsers\readers.py:620, in _read(filepath_or_buffer, kwds) 617 _validate_names(kwds.get("names", None)) 619 # Create the parser. --> 620 parser = TextFileReader(filepath_or_buffer, **kwds) 622 if chunksize or iterator: 623 return parser File D:\Softwares\miniconda3\envs\Tensorflow\lib\site-packages\pandas\io\parsers\readers.py:1620, in TextFileReader.__init__(self, f, engine, **kwds) 1617 self.options["has_index_names"] = kwds["has_index_names"] 1619 self.handles: IOHandles | None = None -> 1620 self._engine = self._make_engine(f, self.engine) File D:\Softwares\miniconda3\envs\Tensorflow\lib\site-packages\pandas\io\parsers\readers.py:1898, in TextFileReader._make_engine(self, f, engine) 1895 raise ValueError(msg) 1897 try: -> 1898 return mapping[engine](f, **self.options) 1899 except Exception: 1900 if self.handles is not None: File D:\Softwares\miniconda3\envs\Tensorflow\lib\site-packages\pandas\io\parsers\c_parser_wrapper.py:93, in CParserWrapper.__init__(self, src, **kwds) 90 if kwds["dtype_backend"] == "pyarrow": 91 # Fail here loudly instead of in cython after reading 92 import_optional_dependency("pyarrow") ---> 93 self._reader = parsers.TextReader(src, **kwds) 95 self.unnamed_cols = self._reader.unnamed_cols 97 # error: Cannot determine type of 'names' File parsers.pyx:574, in pandas._libs.parsers.TextReader.__cinit__() File parsers.pyx:663, in pandas._libs.parsers.TextReader._get_header() File parsers.pyx:874, in pandas._libs.parsers.TextReader._tokenize_rows() File parsers.pyx:891, in pandas._libs.parsers.TextReader._check_tokenize_status() File parsers.pyx:2053, in pandas._libs.parsers.raise_parser_error() UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 0: invalid continuation byte
# 第二次导数数据文件incom.csv
# 报错:没有导入pandas模块定义pd别名 # 报错信息:“NameError: name 'pd' is not defined”
# 解决办法:添加编码格式
# 第二次导入数据文件
data = pd.read_csv('./income.csv', encoding='gbk')
# 详细报错
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[1], line 1
----> 1 data = pd.read_csv('./income.csv', encoding='gbk')
NameError: name 'pd' is not defined
# 第三次导入数据文件incom.csv # 数据集更新 # 第三次导入数据文件,定义原数据gbk编码格式 data = pd.read_csv('./income.csv', encoding='gbk') # 输出数据表 data # 输出结果 number name education income 0 1 张三 20 10000 1 2 李四 12 9000 2 3 王五 34 8000 3 4 魏斌 16 12000 4 5 王红 23 10000 5 6 小新 24 10700 6 7 小玲 25 11000 7 8 小明 26 11300 8 9 小白 27 11600 9 10 小微 28 11900 # 定义x轴参数education列值
# 定义y轴参数income列值
plt.scatter(data.education, data.income)
# 输出绘图结果:
<matplotlib.collections.PathCollection at 0x2cc83e7f640>
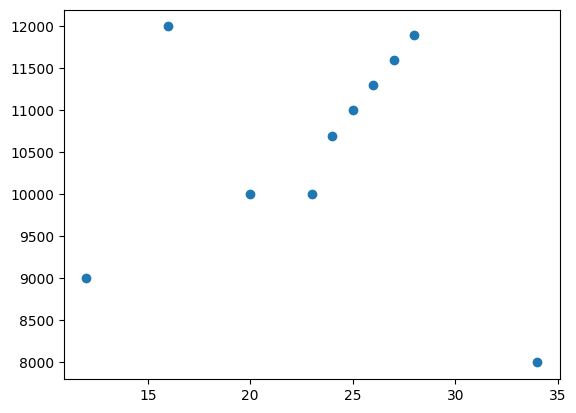
# 总结
定义x轴(表education列值)与y轴(表income列值)的线性关系,后续整理f(x)=ax+b的函数关系及优化方法。
稳步前行,只争朝夕。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号