CodeQL(1)
前言
开始学习使用CodeQL,做一些笔记,可供参考的资料还是比较少的,一个是官方文档,但是Google翻译过来,总觉得怪怪的,另一个就是别人的一个资源整合,其中可供参考的也不是很多,大多也是官方文档翻译过来的,要不然就是你抄我,我抄你,抄来抄去,其中有些东西就变了味。
还是需要好好学英语,直接看官方一手文档不香吗?
https://codeql.github.com/docs/
先看一篇科普文章Github安全实验室:开源代码分析引擎codeql,设漏洞奖励计划 (qq.com)防止文章失效,文章重点如下:
-
GitHub启动securitylab社区计划:https://securitylab.github.com/
-
可以在lgtm平台(类似云平台)上直接写语句分析:https://lgtm.com
-
开设了针对codeql的CTF比赛: https://securitylab.github.com/ctf ,在Research这一栏有很多研究人员挖和分析漏洞的技术经验分享
-
GitHub成为了授权的CVE编号颁发机构(CNA),这意味着它可以发布漏洞的CVE标识符。
赏金规则查看:https://securitylab.github.com/bounties
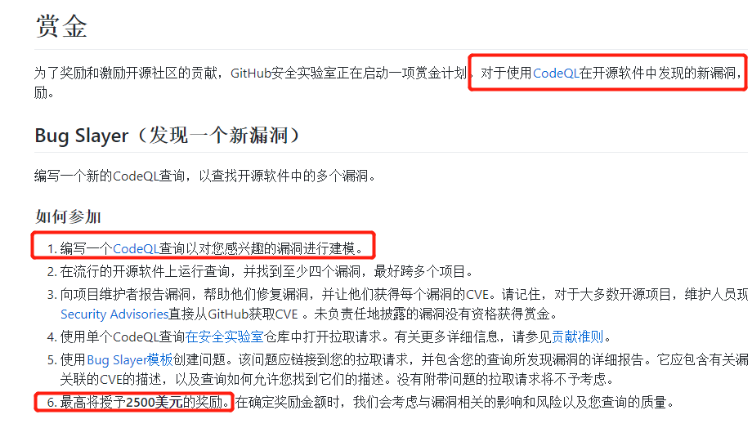
从描述来看,Github还是希望安全研究员使用CodeQL进行挖掘新漏洞,并可以提交赏金。最高获得2500美元
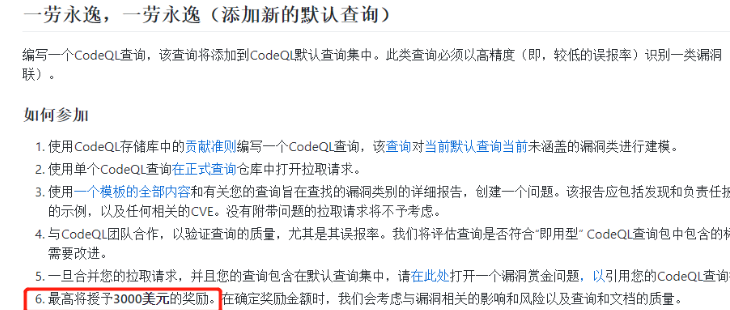
除了发现漏洞有钱之外,编写CodeQL查询,如果写的够好,也可以拿钱,最高可以拿3000美元
CodeQL
Semmle公司最早独创性的开创了一种QL语言,Semmle QL,并且运行在自家LGTM 平台上。
LGTM平台上存放的就是一些开源项目,用户可以选择分析的语言,编写ql语句进行程序安全性查询
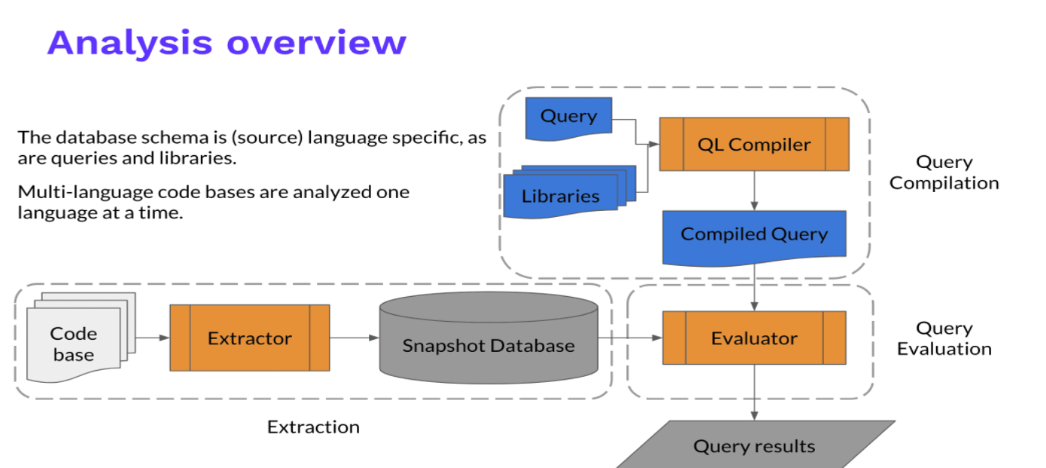
2019年,GitHub(背后是微软)收购了Semmle公司,开源了CodeQL分析引擎,来看引擎的概况图
-
将源码通过Extractor模块进行代码信息分析&提取,构建一套自己的关系型数据库
Snapshot Database。-
编译型语言:Extractor观察编译器的编译过程,捕获编译器生成的AST,语义信息(名称绑定、类型信息、运算操作等),控制流,数据流信息,外加一份源码。
-
解释型语言:Extractor直接分析源代码
-
-
Snapshot Database里面包括:源代码,关系数据
-
接下来用户输入QL语句,经过CodeQL的工具库转换为Compiled Query,参与查询
-
最终展示查询结果
这是大概的一个原理,其核心原理也可以在Academic publications--官方给出的Paper,说实话,看天书一样,中文的都看不懂,还想看英文的,洗洗睡吧,不说废话了
CodeQL 的整体思路是把源代码转化成一个可查询的数据库,通过 Extractor 模块对源代码工程进行关键信息分析提取,构成一个关系型数据库。CodeQL 的数据库并没有使用现有的数据库技术,而是一套基于文件的自己的实现。
对于编译型语言,Extractor 会监控编译过程,编译器每处理一个源代码文件,它都会收集源代码的相关信息,如:语法信息(AST 抽象语法树)、语意信息(名称绑定、类型信息、运算操作等),控制流、数据流等,同时也会复制一份源代码文件。而对于解释性语言,Extractor 则直接分析源代码,得到类似的相关信息。
关键信息提取完成后,所有分析所需的数据都会导入一个文件夹,这个就是 CodeQL database, 其中包括了源代码文件、关系数据、语言相关的 database schema(schema 定义了数据之间的相互关系)。
我们的关注点应该在于怎么样提炼出来某种类型的漏洞的规则,一句话,CodeQL,规则为王。
环境搭建
管它会不会写规则,环境先搭起来看看。
环境准备
以Java为例,Java是编译型语言,所以你需要事先安装好项目编译所需的全部环境,例如:JDK、Maven
CodeQL CLI
CodeQL CLI用来创建和分析数据库。也就是分析引擎
下载CodeQL压缩包并解压
https://github.com/github/codeql-cli-binaries/releases
将CodeQL CLI的可执行文件添加到环境变量,方便灵活调用
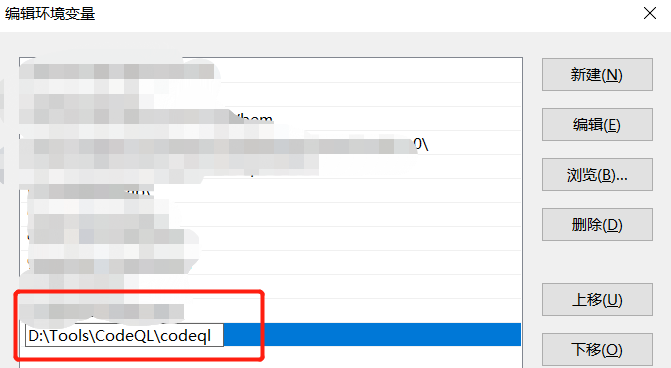
CodeQL 标准库
包含了必须的一些标准库(内置库)和一些查询样例
https://github.com/github/codeql,下载后更改文件名为ql,此时目录结构为:

注意:CodeQL解释器会按照某个规则(会查找CodeQL CLI所在目录的兄弟目录以及其子目录)寻找CodeQL标准库的位置,若是没有找到,则需要你手动将CodeQL标准库添加到VSCode的工作区中。所以我们这里直接放在同一个文件夹下。
安装VS code插件并配置
官方提供了VSCode编写CodeQL的插件作为前端来使用Codeql
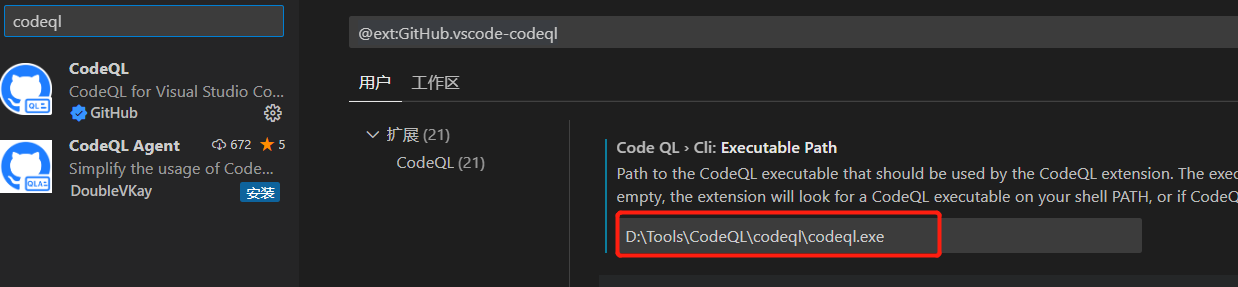
这里的路径具体到codeql.exe,windows下也可以codeql.cmd
使用
下载WebGoat
我这里以WebGoat8.1.0 为例,此版本需要Java11环境,自行配置,
创建数据库
需要已经安装Maven,因为WebGoat项目是基于Maven构建的,CodeQL在创建数据库时,会自动探测并使用对应的编译方式。
在WebGoat根目录下面执行如下命令,会自动编译并且为该项目创建一个名为webgoat-qldb的QL数据库。
codeql database create webgoat-ql -l java
因为要下载很多的依赖,生成比较慢
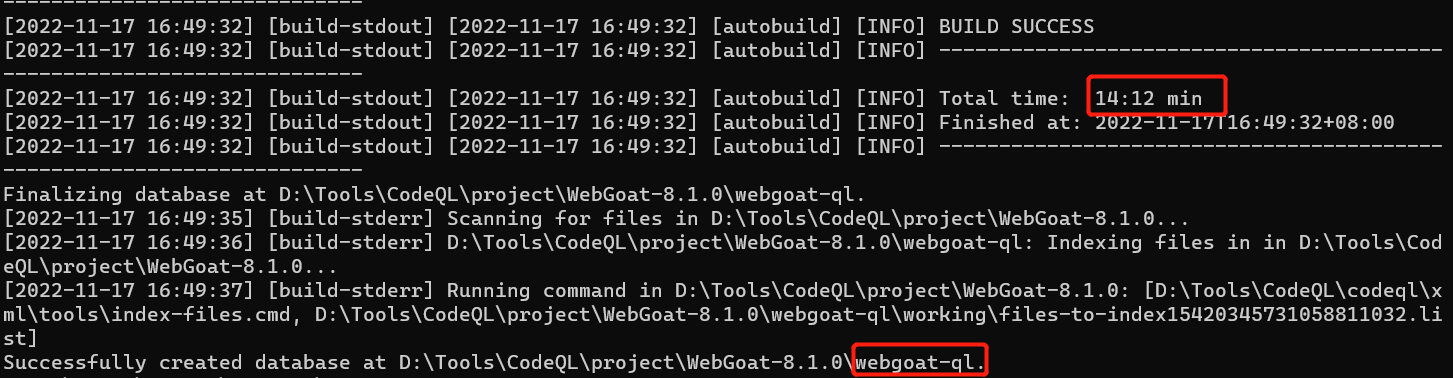
创建完该项目的数据库后,该项目的源码文件在后面几乎就用不到了(除非像更新QL数据库这种需求),CodeQL查询时主要使用的便是该项目的数据库文件
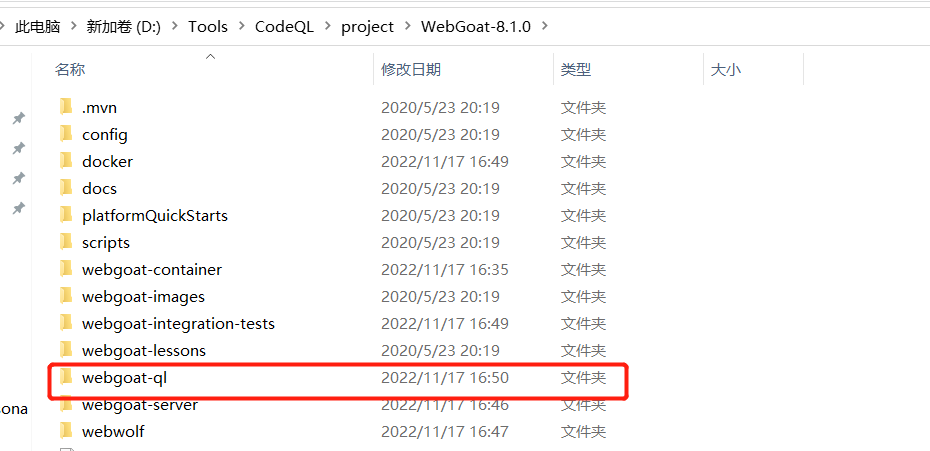
创建QL包
需要创建一个文件夹来存放后续编写的CodeQL脚本,CodeQL官方称这个文件夹为QL Pack。
例如名为query的文件夹,并在里面创建1个QL Pack的配置文件,名称固定为qlpack.yml;再创建一个ql后缀的文件,名称随意

在VSCode中打开这个文件夹
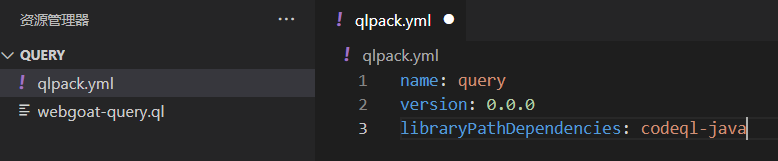
编写QL包的配置文件
将如下信息填入qlpack.yml文件
name: query
version: 0.0.0
libraryPathDependencies: codeql-java
第一行表示这个QL包的名称为query,必选,如果你在VSCode中同时打开多个QL包时,要保证这个name的值唯一不重复;
第二行表示这个QL包的版本号,必选;
第三行表示这个QL包的依赖,必选,codeql-java表示需要Java语言的QL标准库依赖
VSCode工作区增加CodeQL标准库
为了让CodeQL解释器能够访问标准库,我们需要将标准库所在文件夹也加入到加入工作区中。
VSCode - 文件 - 将文件夹加入工作区 - 选择在【环境搭建-CodeQL标准库】章节中存放CodeQL标准库的文件夹。
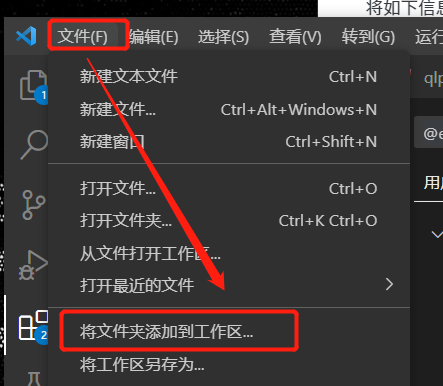
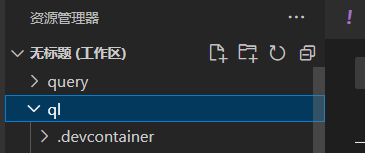
添加CodeQL数据库
在VSCode的CodeQL插件中添加之前用CodeQL创建的WebGoat的数据库。
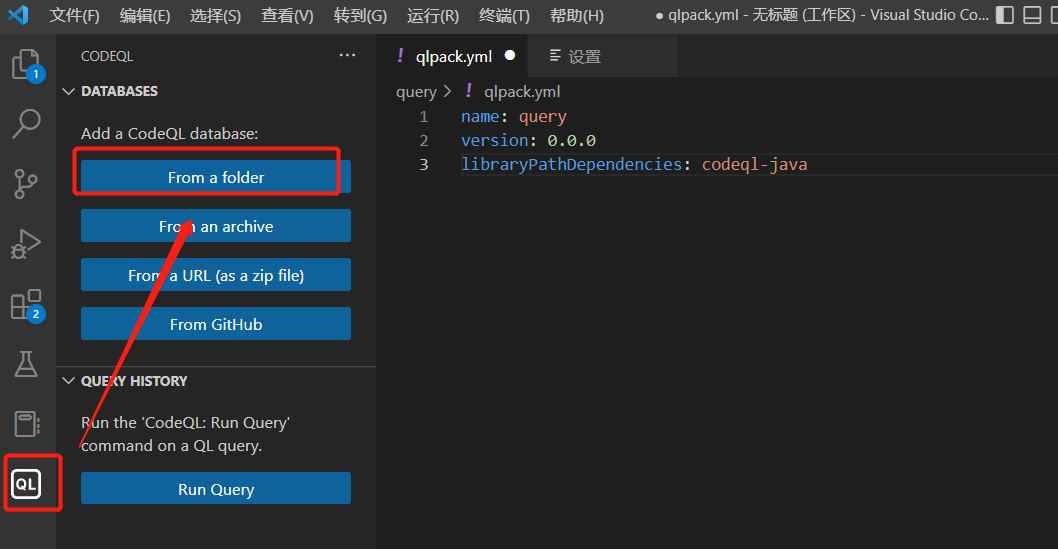
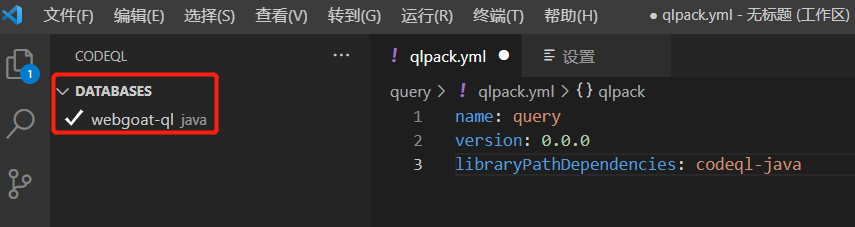
选择webgoat-ql那个文件夹。如下是添加成功后的页面
编写一个简单查询
在webgoat-queyr.ql文件中编写如下代码,用来查找WebGoat项目中所有声明的方法
import java
from Method m
select m
然后右键点击【CodeQL: Run Query 】来执行本次查询,执行完成后在右边可以看到多出一列用来显示查询结果
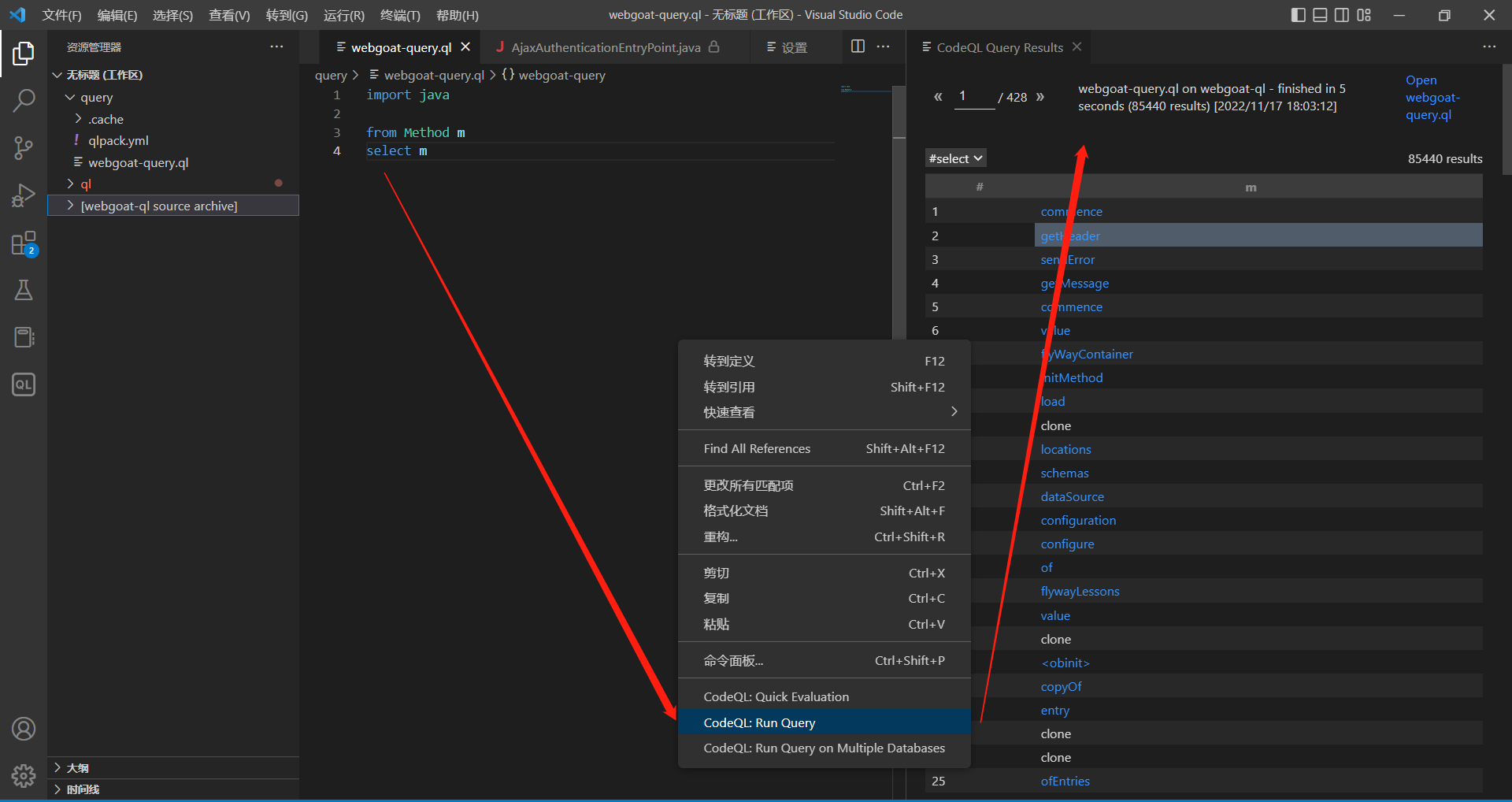
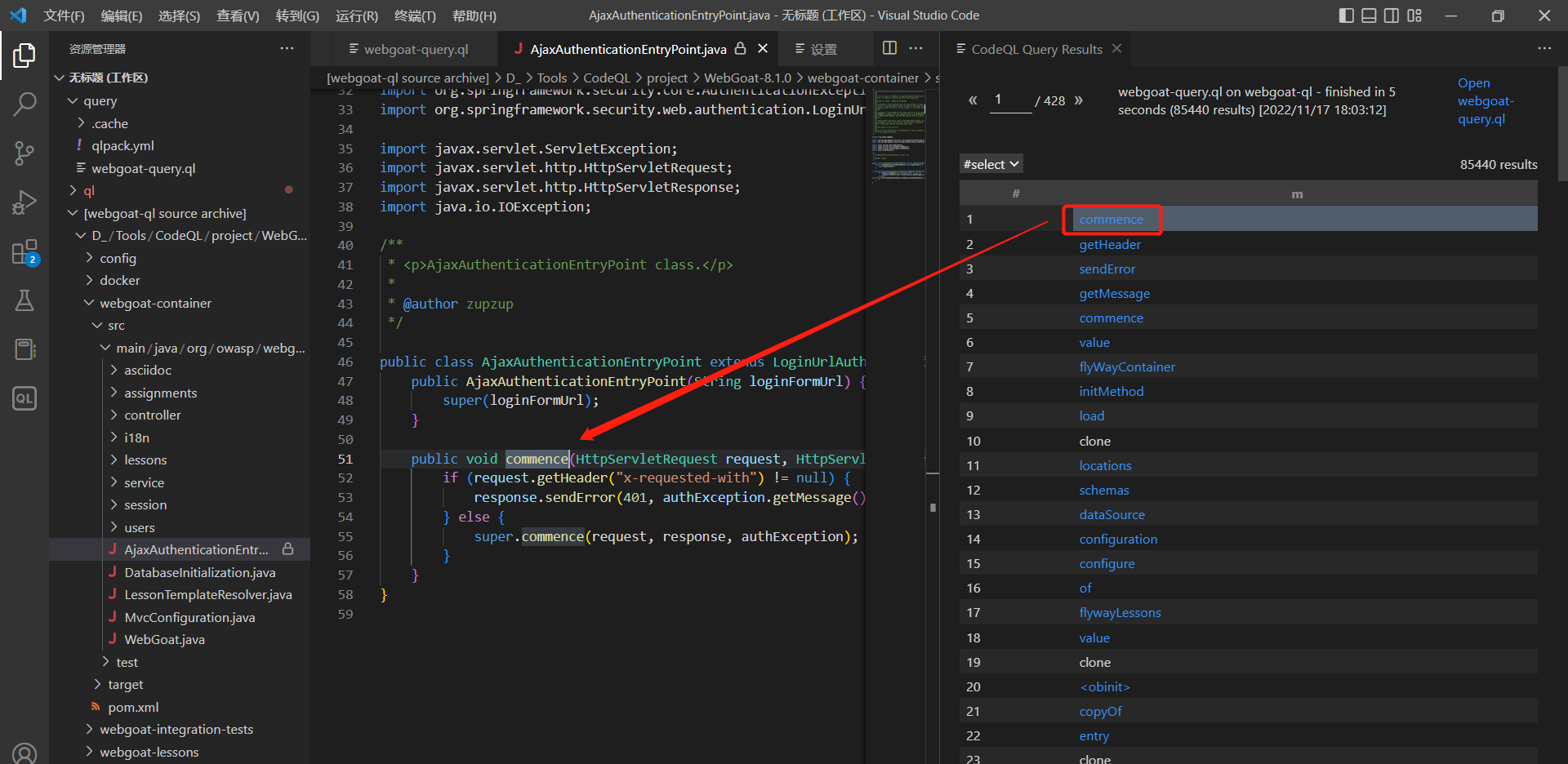
点击结果里面的任意条目,可以跳到对应的文件中:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号