
9 数据倾斜
数据倾斜概述
指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
Hive中的数据倾斜常出现在分组聚合和join操作的场景中,下面分别介绍在上述两种场景下的优化思路。
分组聚合导致的数据倾斜
优化说明
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
如果group by分组字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
由分组聚合导致的数据倾斜问题,有以下两种解决思路:


优化案例
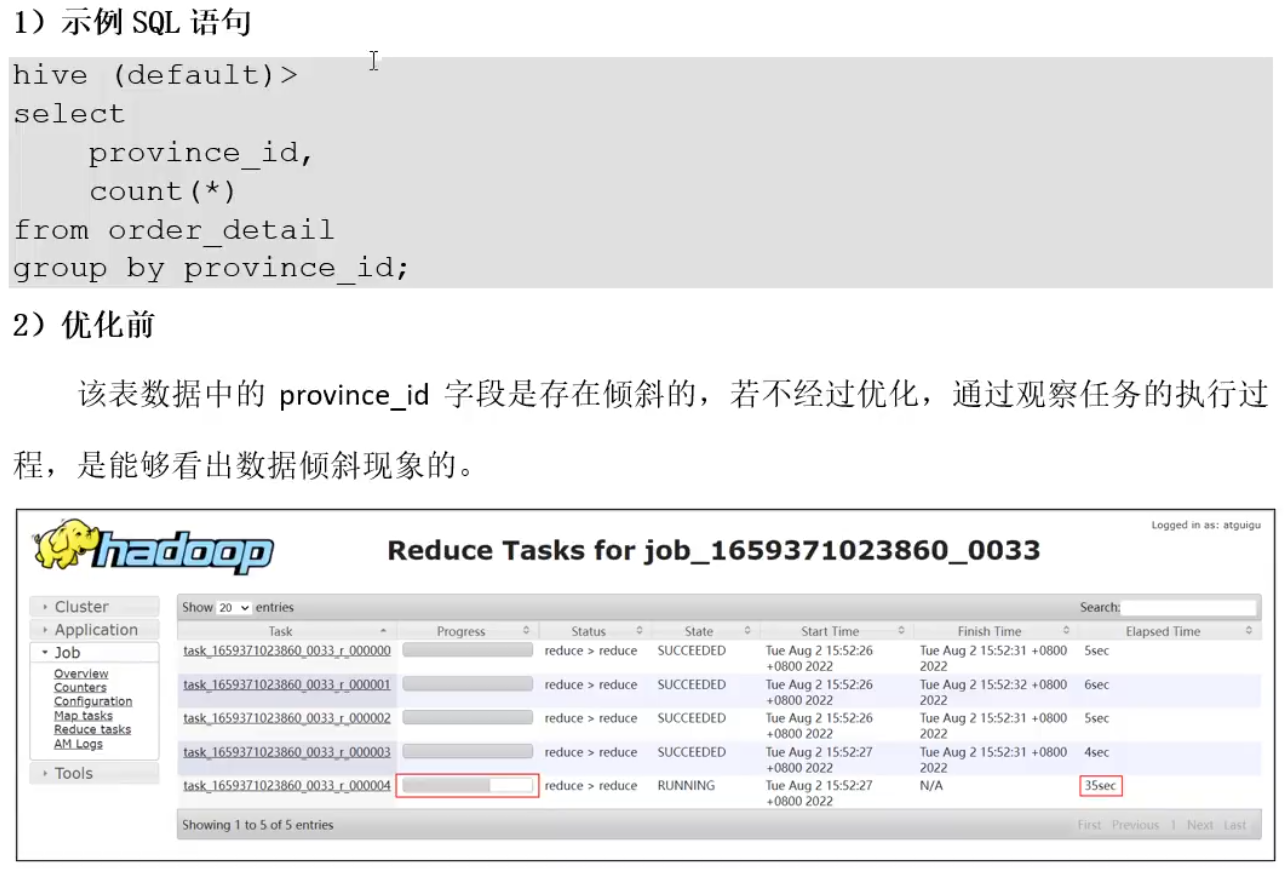
注意:在性能上map-site聚合完胜,更快。但是map-site 聚合要维护一个hash哈希表,在面临大量数据时,如果达到map端内存的阈值,就会flash一次,如果数据量很大,内存比较小,会 flash很多次。
那么数据倾斜的现象可能还会在reduce端存在。但是大部分情况下第一次可以解决。
Join导致的数据倾斜
优化说明
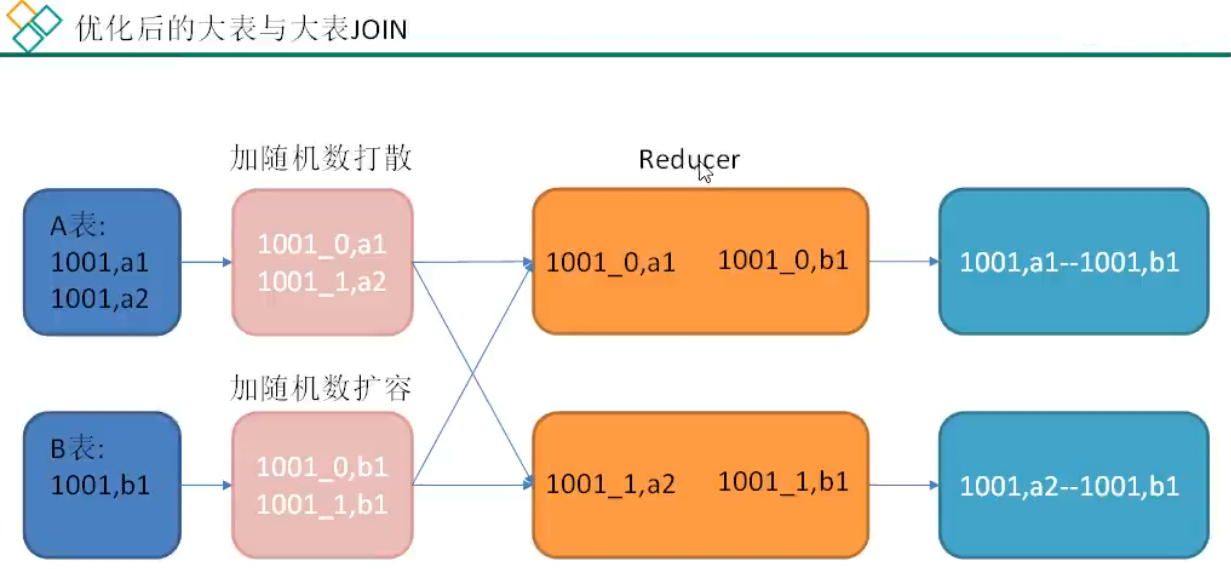
前文提到过,未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题



注意:分桶join不行,因为分桶的过程就是一个数据倾斜的过程,分桶也要用到map-reduce。
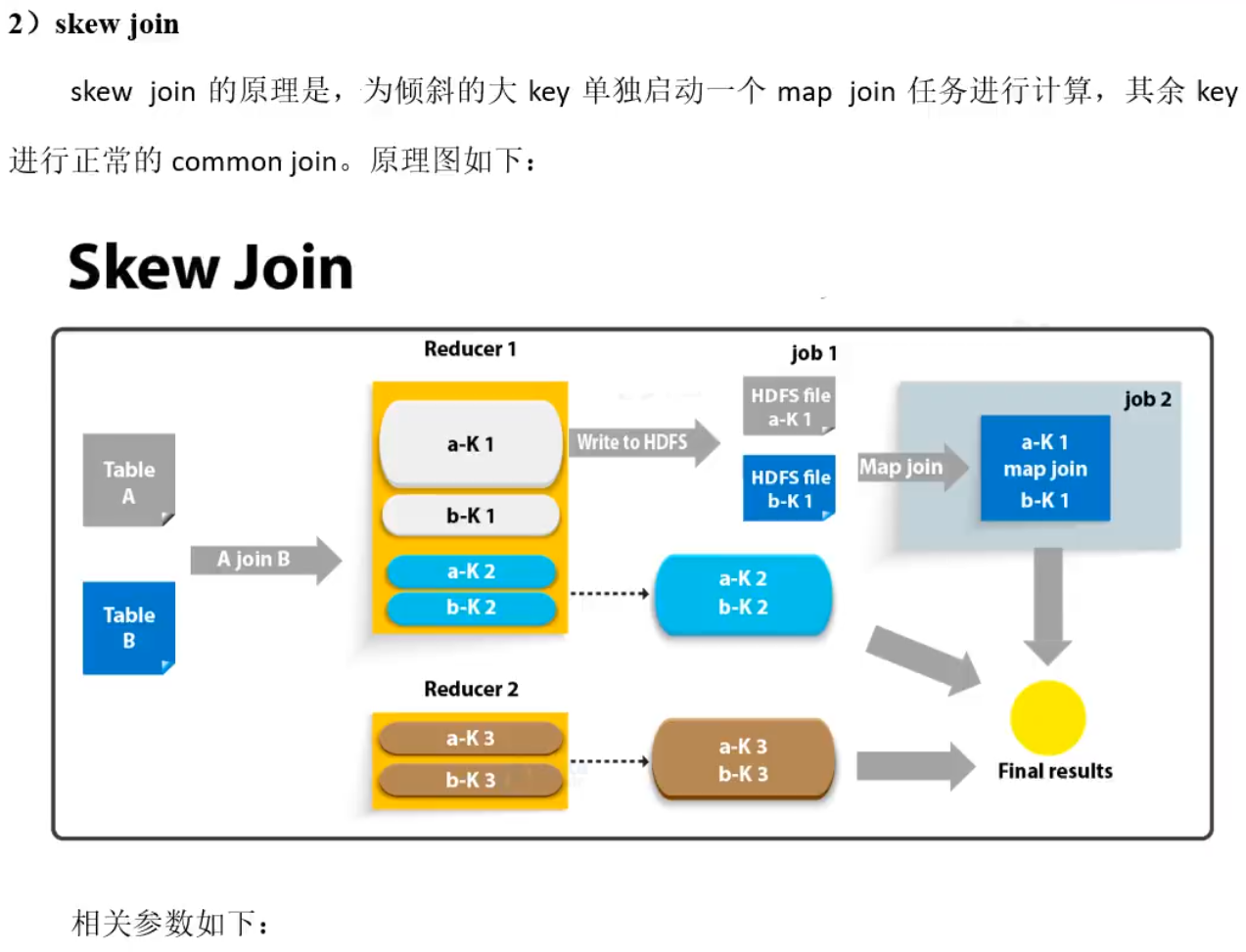

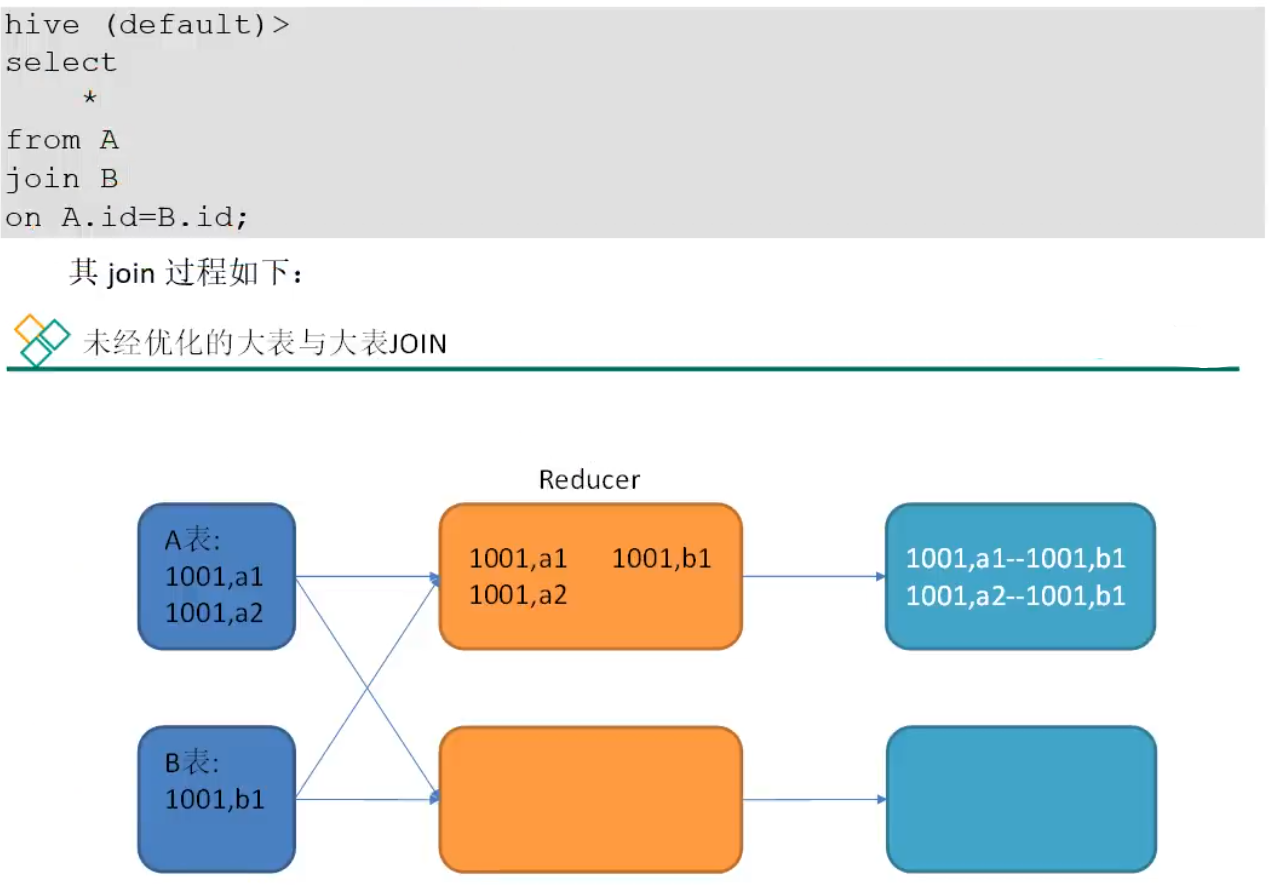
这里的1001为倾斜的大数据。
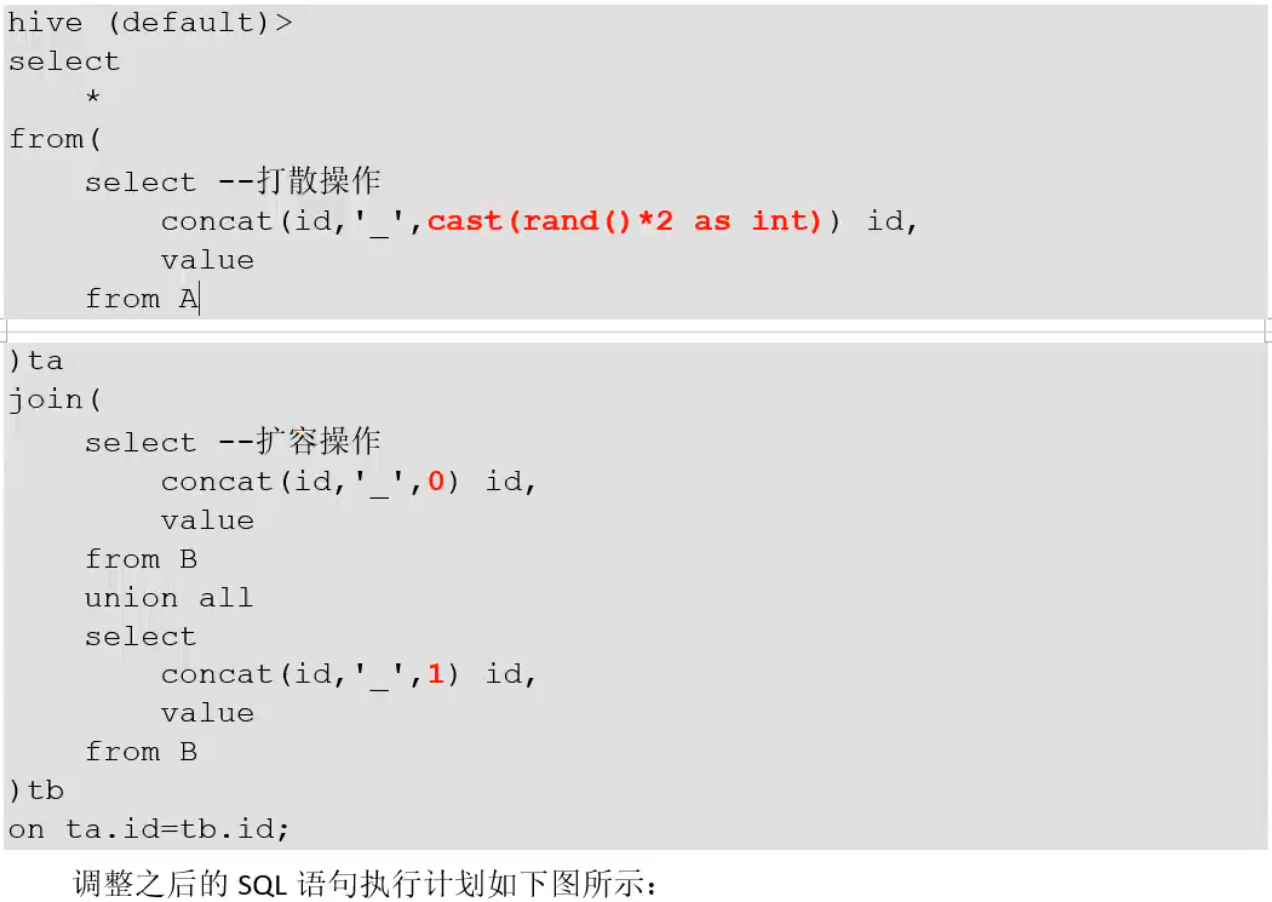
优化案例


 浙公网安备 33010602011771号
浙公网安备 33010602011771号