
8 企业级调优
企业资源配置
Yarn资源配置




根据实际情况自己去调整。
MapReduce资源配置



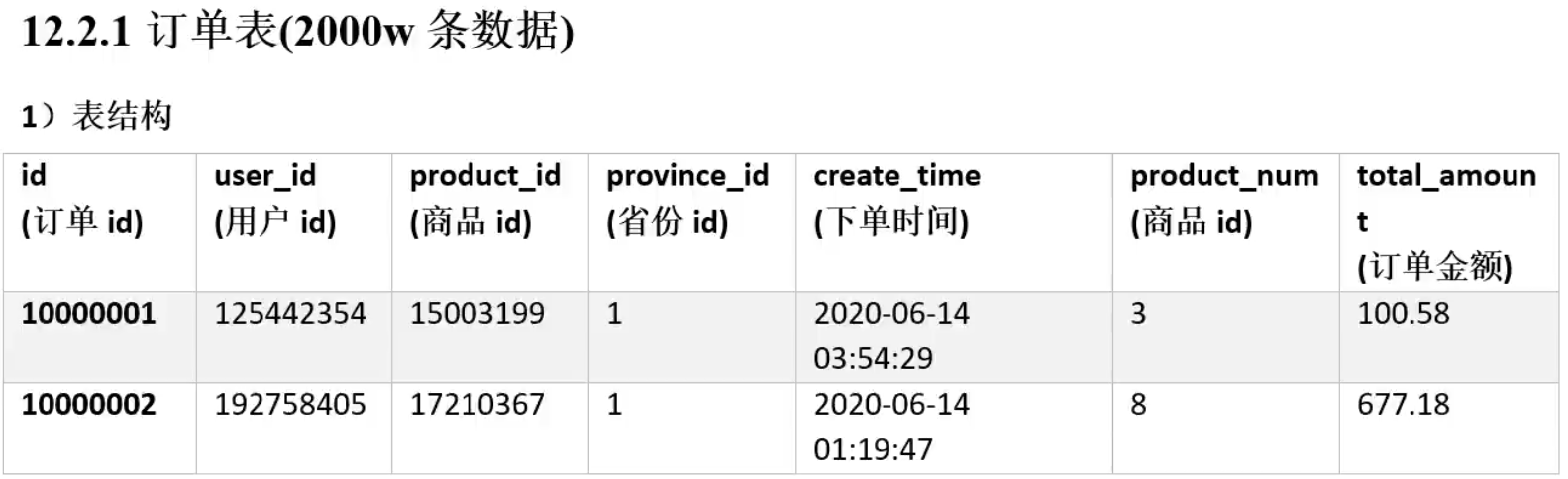
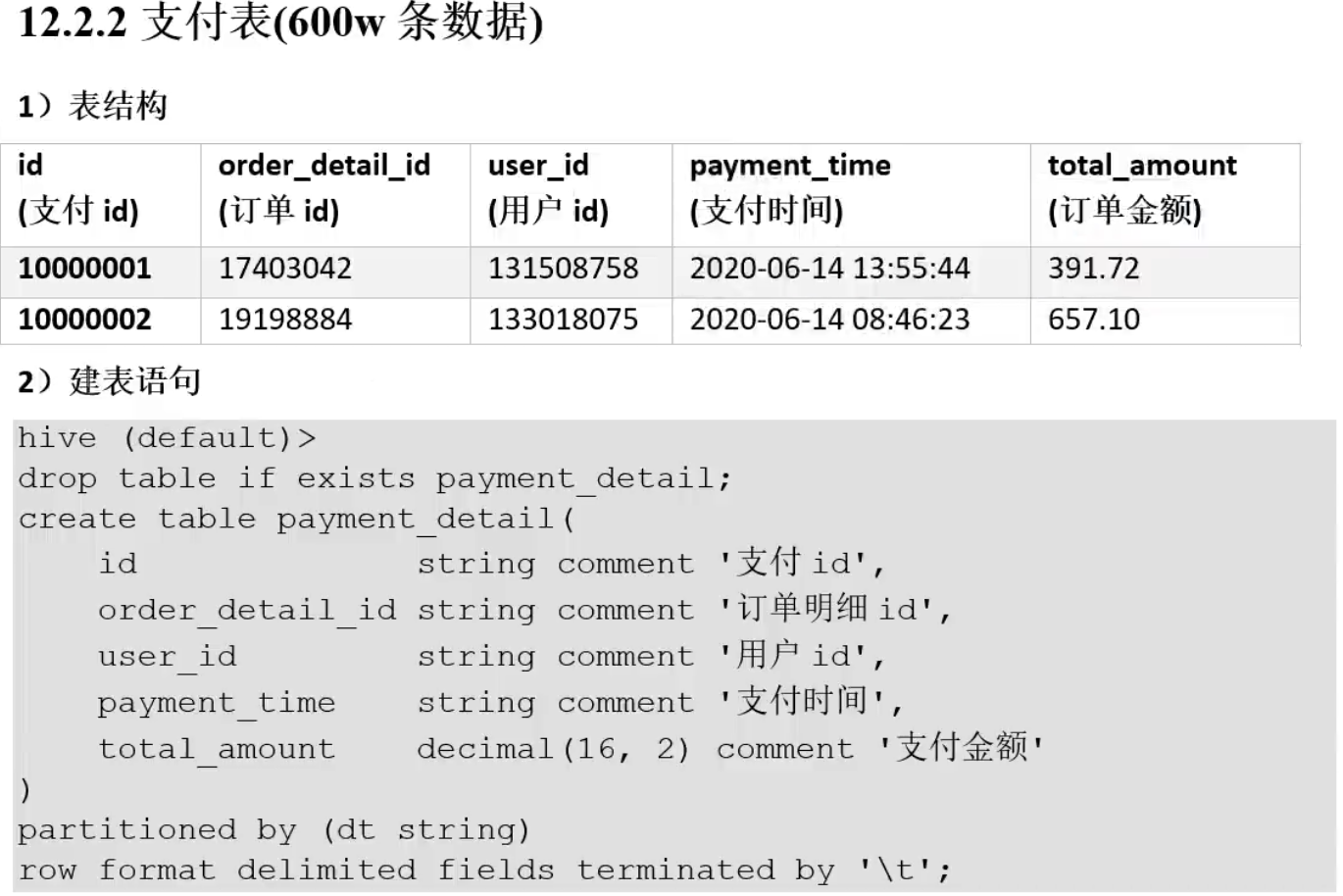
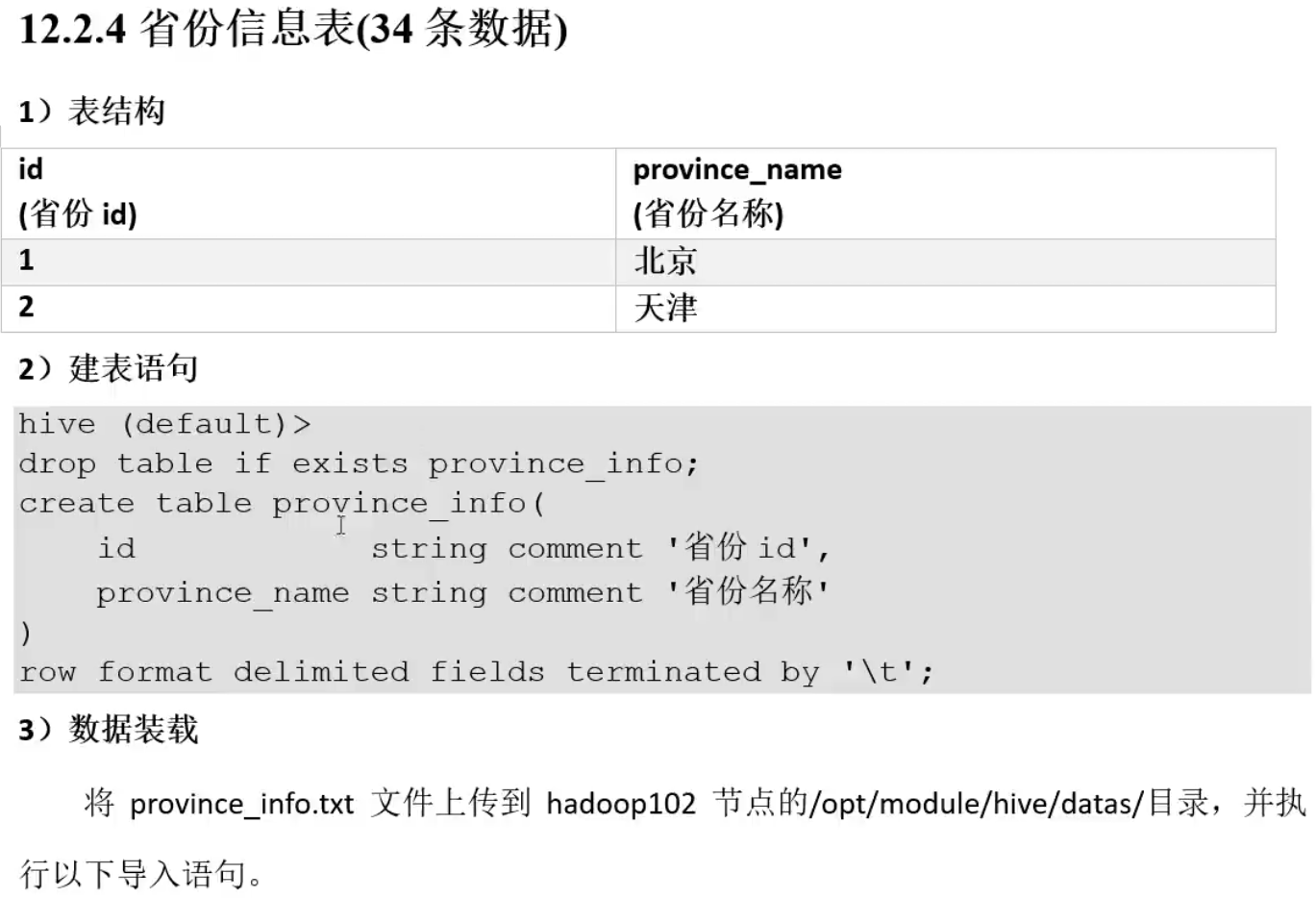
测试用表



Explain查看执行计划
Explain执行计划概述

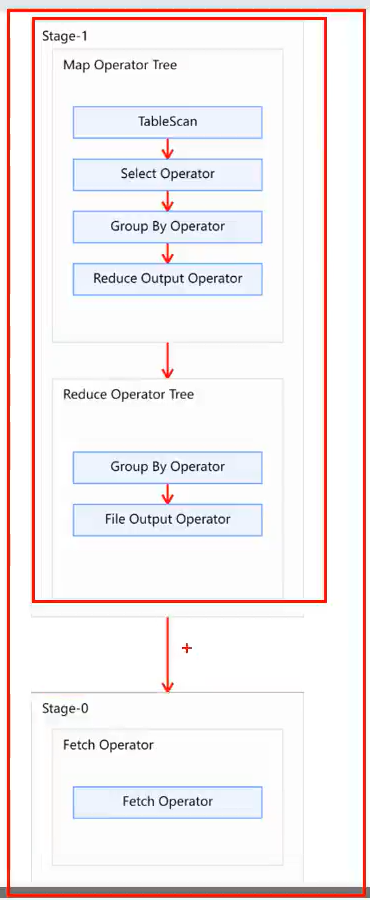

基本语法

![]()
实操案例


HQL语法优化之分组聚合优化
优化说明
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。

优化案例

HQL语法优化之Join优化
Join算法概述
Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等,下面对每种join算法做简要说明:
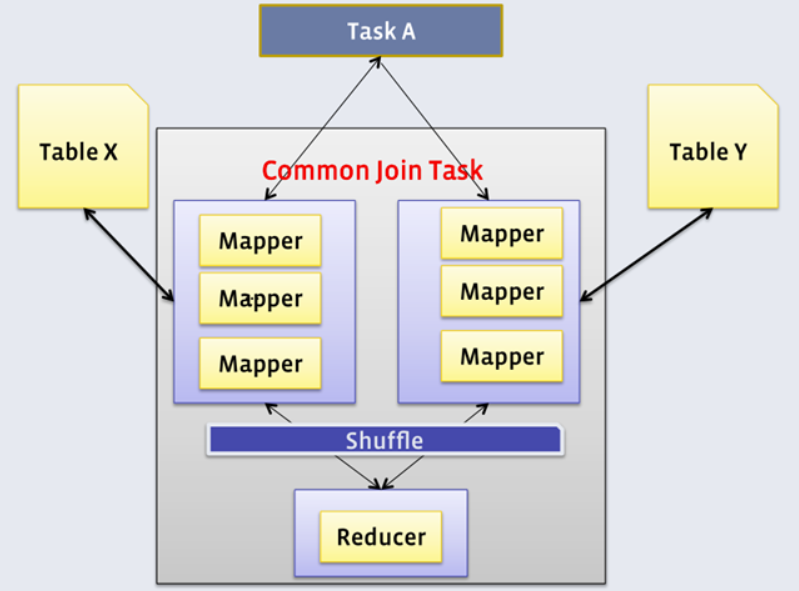
1)Common Join
Common Join是Hive中最稳定的join算法,其通过一个MapReduce Job完成一个join操作。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。


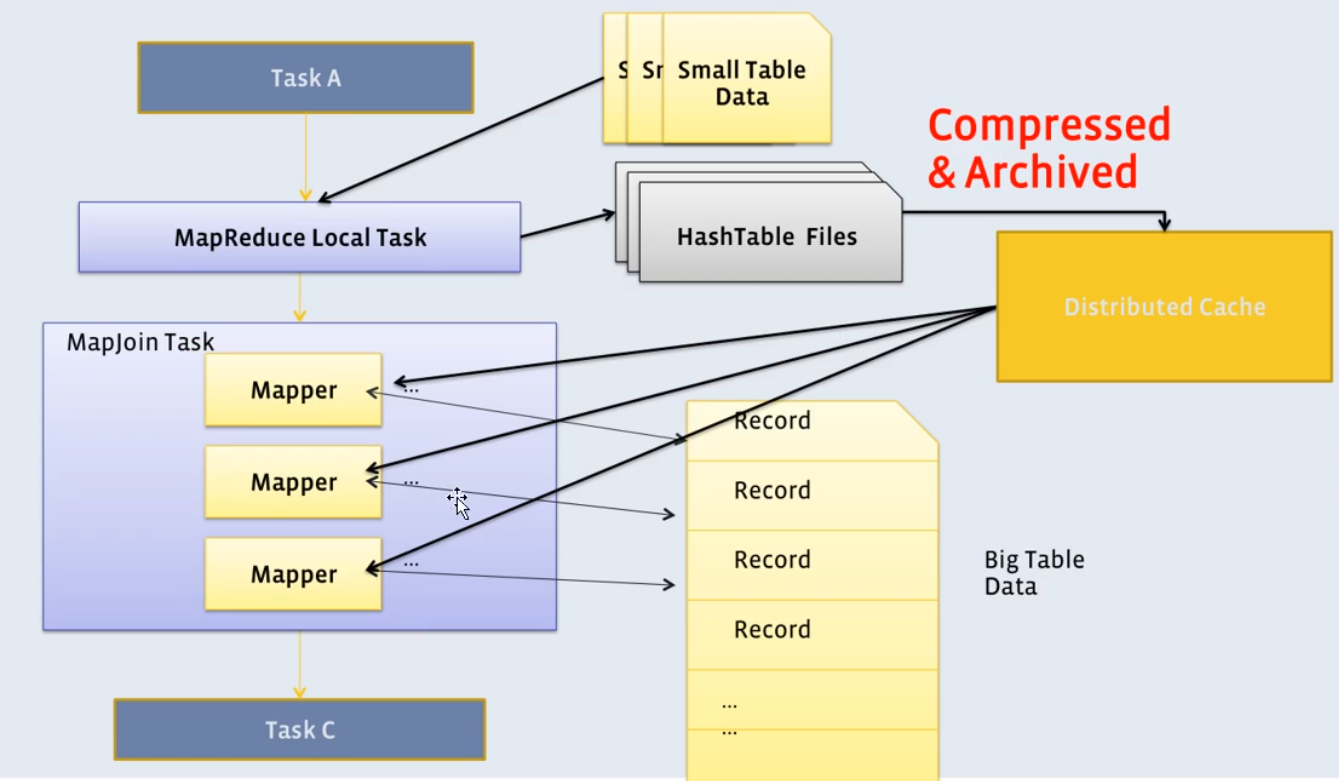
2) Map Join
Map Join算法可以通过两个只有map阶段(无reduce)的Job完成一个join操作。其适用场景为大表join小表。若某join操作满足要求,则第一个Job会读取小表数据,将其制作为hash table,并上传至Hadoop分布式缓存(本质上是上传至HDFS)。第二个Job会先从分布式缓存中读取小表数据,并缓存在Map Task的内存中,然后扫描大表数据,这样在map端即可完成关联操作。


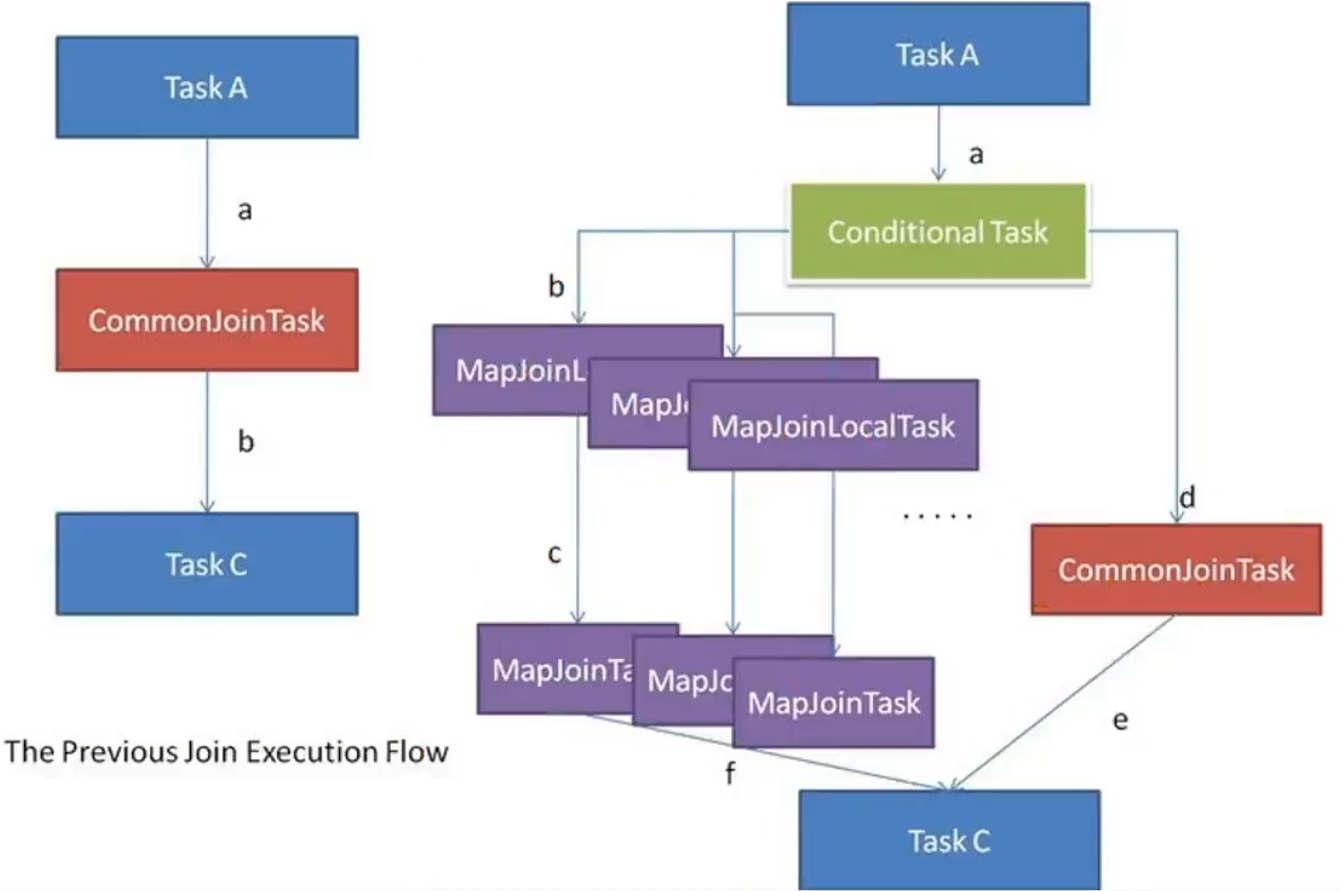
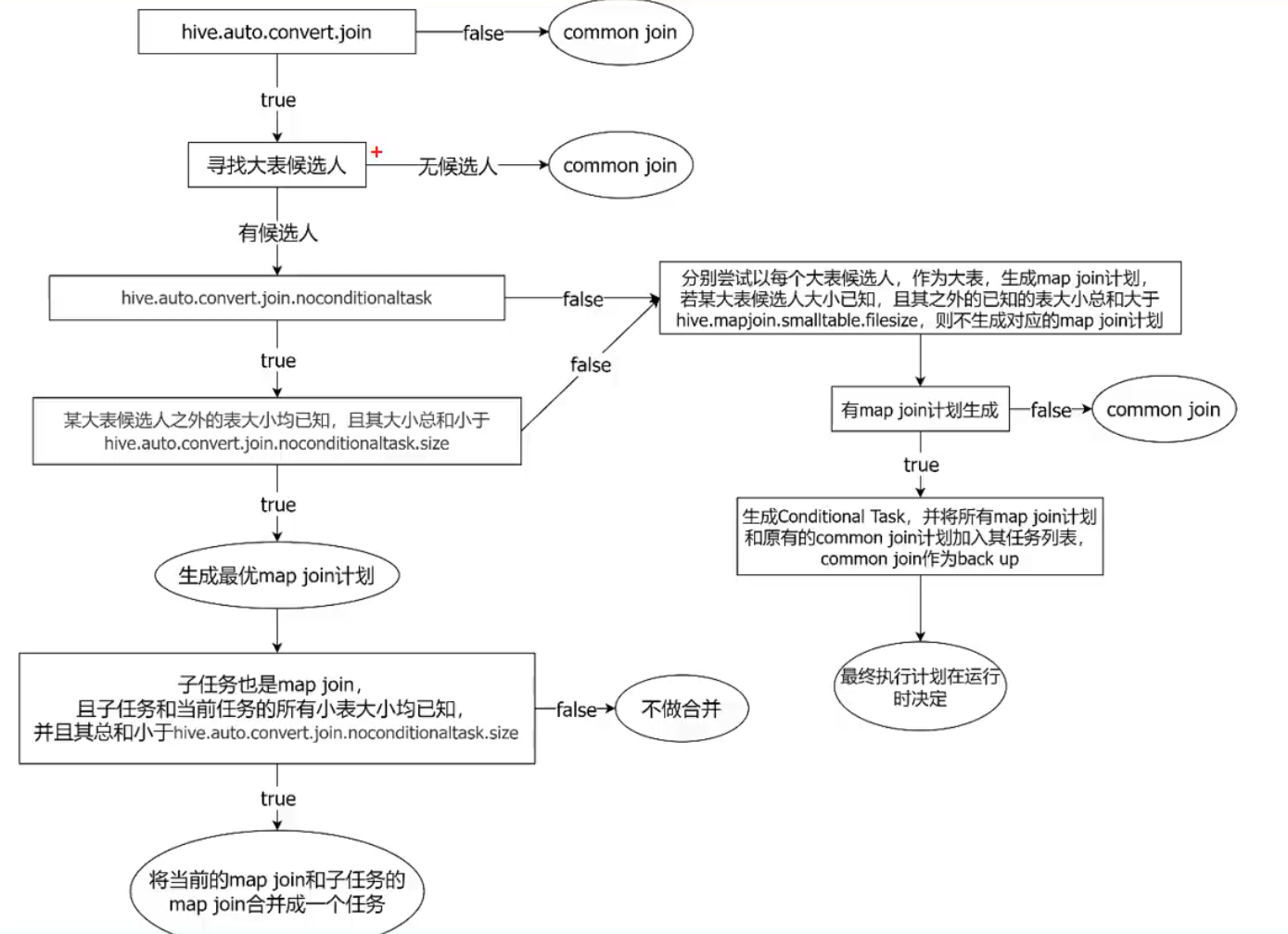

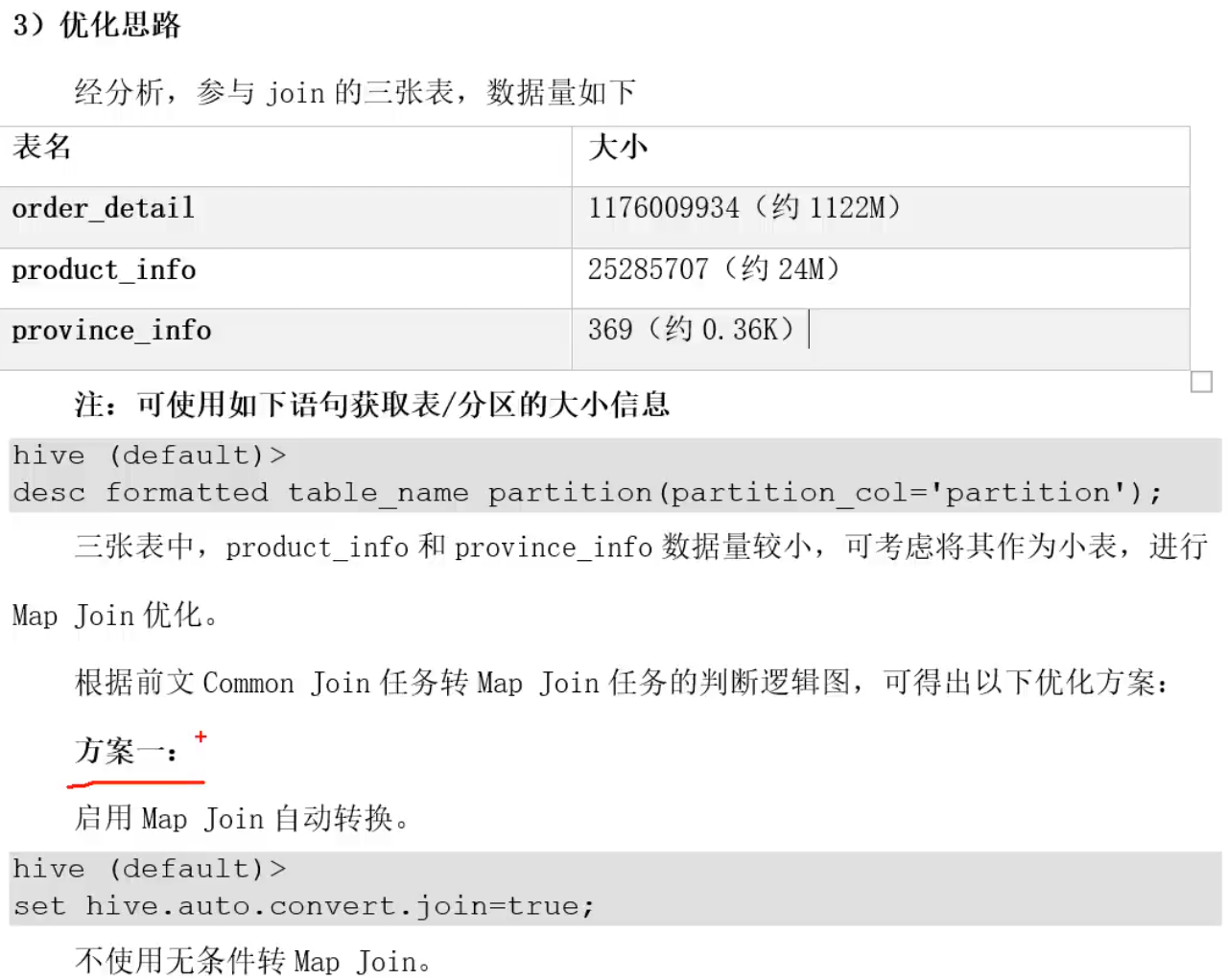
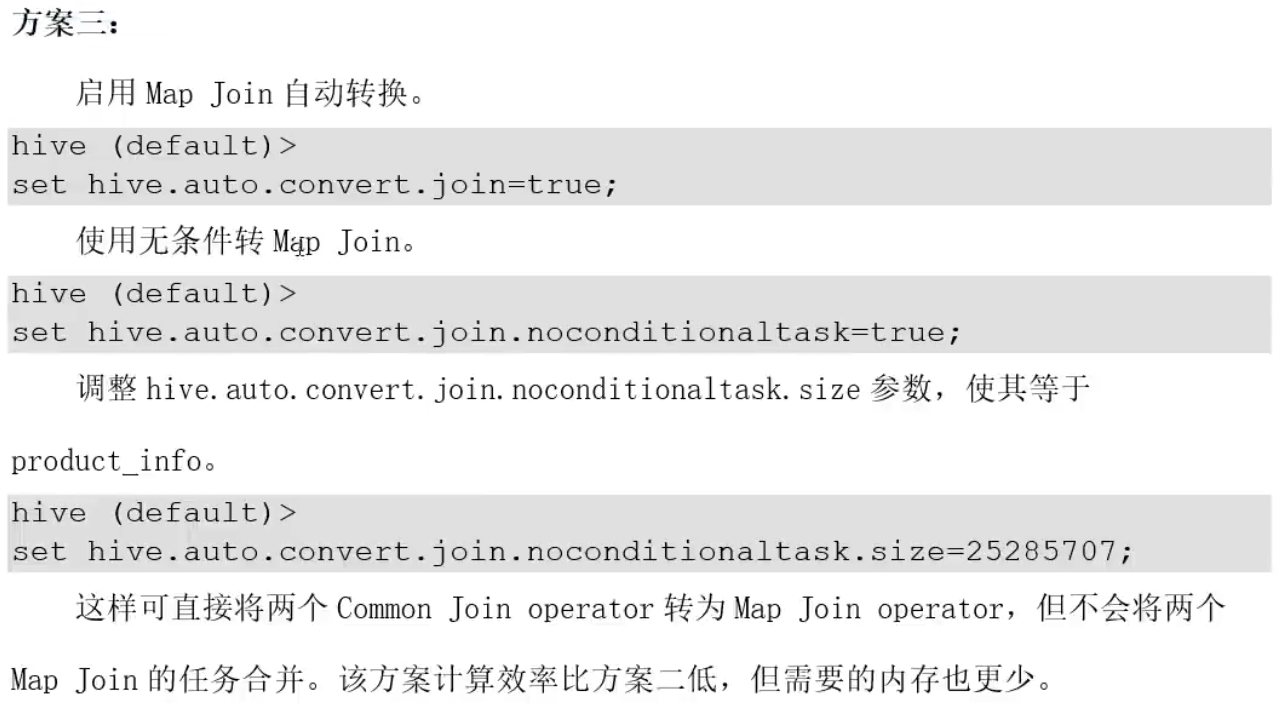
优化案例


3)Bucket Map Join

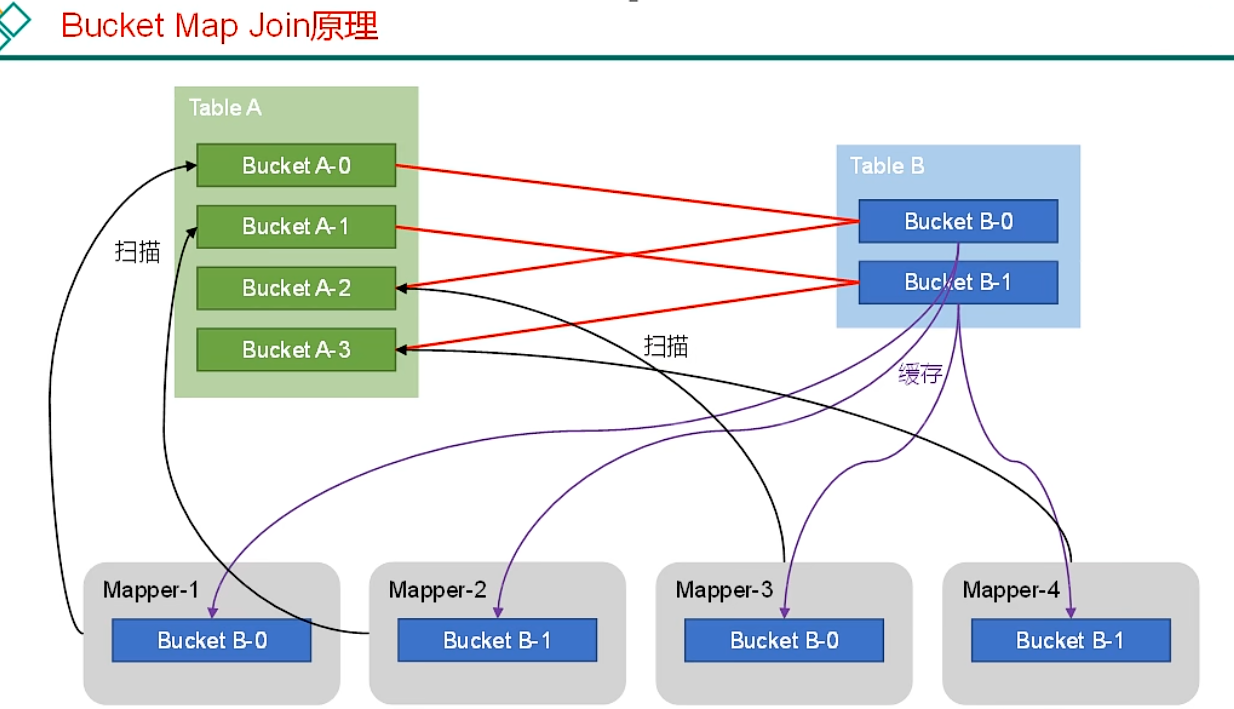
配置相关参数开启bucket map join

注意:1 都是分桶表 2 都是按照分桶字段进行关联 3 一张表的分桶数量是另一个的整数倍 4做好上面的配置设置
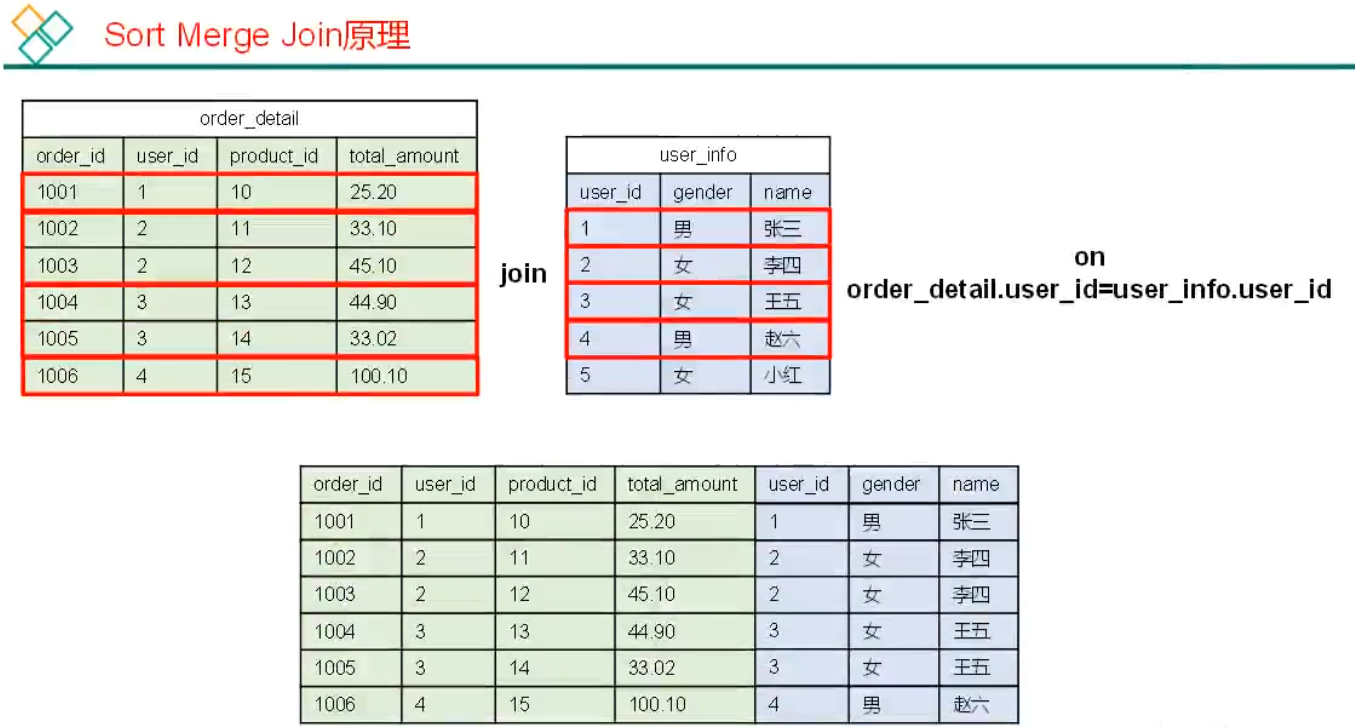
4)Sort Merge Bucket Map Join




 浙公网安备 33010602011771号
浙公网安备 33010602011771号