图总结
一。思维导图
https://img2020.cnblogs.com/blog/2343585/202105/2343585-20210530140941486-1038053792.png
二。图
1.图的基本概念
类型:
有向图:由顶点集和弧集构成的图。
无向图:由顶点集和边集构成的图。
对有向图来说,顶点的出度:以顶点v为弧尾的弧的数目;顶点的入度:以顶点v为弧头的弧的数目; 顶点的度(TD)=出度(OD)+入度(ID)
假若顶点v和顶点w之间存在一条边,则称顶点v和w互为(邻接点 ),和顶点v关联的边的数目定义为边的(度)。
2.存储结构
(1).邻接矩阵:顶点间相邻关系的矩阵。
无向图的邻接矩阵是对称的,有向图的邻接矩阵可能是不对称的。
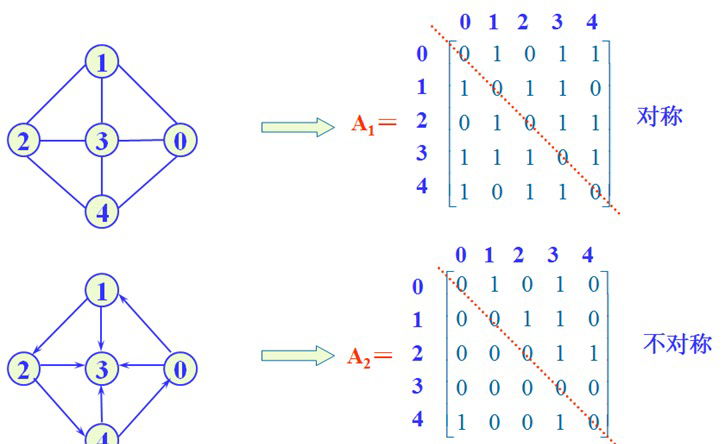
时间复杂度:O(n^2)
含有n个定点的和e条边的无向图的邻接矩阵中,零元素的个数为(n^2-2e)。
(2)邻接表:只存储图中已有的弧或边的信息。
无向图:第i个单链表中的结点表示依附于顶点vi的边。
有向图:第i个单链表中的结点表示以顶点vi为尾的弧。
逆邻接表:有向图中对每个结点建立一Vi为头的弧的单链表。
邻接表和邻接矩阵的比较:
在变稀疏的情况下,用邻接表表示图比邻接矩阵节省存储空间,当和边相关的信息较多时更是如此。
在邻接表上容易找到任何一个顶点的第一个邻接接点和下一个邻接点,但要判定任意两个顶点(v1和v2)之间是否有边或弧相连,则需要搜索第i个或第j个链表,因此,不及邻接矩阵方便。邻接表适合存无向图。
(3)十字链表:合有向图,可以看成是有向图的邻接表和逆邻接表结合起来的一种链表。

3.图的遍历
(1).深度优先遍历(DFS):只有当访问完当前结点所连接的全部结点之后才能回溯到上一层。
深度优先遍历连通图的过程类似于树的先根遍历。
图的连通性
关节点、桥。强连通分量这个概念只在有向图中有,指的是有向图的一个最大的连通子图。
连通图:任意两个顶点都相互连通的图;
极大连通子图:包含竟可能多的顶点(必须是连通的),即找不到另外一个顶点,使得此顶点能够连接到此极大连通子图的任意一个顶点;
连通分量:极大连通子图的数量;
强连通图:此为有向图的概念,表示任意两个顶点a,b,使得a能够连接到b,b也能连接到a 的图;
生成树:n个顶点,n-1条边,并且保证n个顶点相互连通(不存在环
最小生成树:此生成树的边的权重之和是所有生成树中最小的;
算法
访问顶点vi并标记顶点vi为已访问;
查找顶点v的第一个邻接顶点vj;
若顶点v的邻接顶点vj存在,则继续执行,否则算法结束;
若顶点vj尚未被访问,则深度优先遍历递归访问顶点vj;
查找顶点vi的邻接顶点vj的下一个邻接顶点,转到步骤
遍历过程
从图中某个顶点v出发,访问该顶点,然后依次从v的未被访问的邻接点出发继续深度优先遍历图中的其余顶点,直至图中所有与v有路径相通的顶点都被访问完为止。
(2)广度优先遍历(BFS):对连通图,从起始点V到其余各顶点必定存在路径。
实质:通过边或弧找到邻接点的过程。
连通图的广度优先算法:
(1)访问初始顶点v并标记顶点v为已访问;
(2)顶点v入队列;
(3)当队列非空时则继续执行,否则算法结束;
(4)出队列取得队头顶点u;
(5)查找顶点u的第一个邻接顶点w;
(6)若顶点u的邻接顶点w不存在,则转到步骤(3),否则执行后序语句。
DFS与BFS算法效率比较:
空间复杂度相同,都是O(n)(借用了堆栈或队列)
时间复杂度只与存储结构(邻接矩阵或邻接表)有关,而与搜索路径(遍历的顺序)无关
搜索路径是由存储结构与算法共同决定的
4图的应用:
(1)最小生成树
概念:将给出的所有点连接起来(即从一个点可到任意一个点),且连接路径只和最小的图。
算法:普里姆(Prim)算法; 克鲁斯卡尔(Kruskal)算法。
普里姆(Prim)算法:
基本思想:
第一步:取图中任意一个顶点 v 作为生成树的根;
第二步:往生成树上添加新的顶点 w。在添加的顶点 w 和已经在生成树上的顶点v 之间必定存在一条边, 并且该边的权值在所有连通顶点 v 和 w 之间的边 中取值最小;
第三步:继续往生成树上添加顶点,直至生成树上 含有 n 个顶点为止。
构造的最小生成树不一定唯一, 但最小生成树的权值之和一定是相同的。
算法描述
void MiniSpanTree_P(MGraph G, VertexType u) {
//用普里姆算法从顶点u出发构造网G的最小生成树
k = LocateVex ( G, u );
for (j=0; j<G.vexnum; ++j )//辅助数组初始化
if (j!=k)
closedge[j] = {u,G.arcs[k][j].adj };
closedge[k].lowcost = 0; //初始,U={u}
for (i=0; i<G.vexnum; ++i) {
继续向生成树上添加顶点;
}
k = Min(closedge);//求出加入生成树的下一个顶点k
printf(closedge[k].adjvex, G.vexs[k]); //输出生成树上一条边
closedge[k].lowcost = 0;//第k顶点并入U集
for(j = 0; j < G.vexnum; ++j)
//修改其它顶点的最小边
if (G.arcs[k][j].adj < closedge[j].lowcost)
closedge[j]={G.vexs[k], G.arcs[k][j]
克鲁斯卡尔(Kruskal)算法
基本思想:
第一步:构造一个只含n个顶点的子图 SG;
第二步:从权值最小的边开始,若它的添加不使SG 中产生回路,则在 SG 上加上这条边;
第三步:如此重复,直至加上 n-1 条边为止。
最短路径
使用Dijkstra算法求最短路径步骤:
初始时,令 S={V0},T={其余顶点},T中顶点对应的距离值:
若存在<V0,Vi>,距离值为<V0,Vi>弧上的权值 若不存在<V0,Vi>,距离值为∞
从T中选取一个其距离值为最小的顶点W, 加入S;
对T中顶点的距离值进行修改:
若加进W作中间顶点,从V0到Vi的距离值比不加W的 路径要短,则修改此距离值;
重复上述步骤,直到S中包含所有顶点,即S=V为止。
拓扑排序
一个AOV-网的拓扑序列不是唯一的。
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边<u,v>∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
关键路径
关键路径是指能影响项目整体时间的活动和事件的集合,是项目中最长的路径。
关键路径问题也即指从多个子项目中流程中找到影响项目整体运营时间的
疑难问题及解决办法
普利姆算法、克鲁斯卡尔算法和Dijkstra算法会弄混
多记忆,并反复看视频

 浙公网安备 33010602011771号
浙公网安备 33010602011771号