HAVING 子句的用法 ——SQL的学习三
HAVING 子句是 SQL 里一个非常重要的功能;
HAVING 子句的用法,进而理解面向集合语言的第二个特性——以集合为单位进行操作。
寻找缺失的编号:
- SQL 会将多条记录作为一个集合来处理,因此如果将表整体看作一个集合,就可以像下面这样解决这个问题。
-
-- 如果有查询结果,说明存在缺失的编号 SELECT '存在缺失的编号' AS gap FROM Class_B HAVING COUNT(*) <> MAX(id);个人理解等 count(*) <> max(id) 同于 (SELECT count(0) FROM Class_B) <> (SELECT MAX(id) from Class_B)
-
-- 如果count(0)计算的结果 不等于 MAX(id)的话 查询全部 -- 即:(SELECT count(0) FROM Class_B) <> (SELECT MAX(id) from Class_B) 的值是true SELECT * FROM Class_B WHERE (SELECT count(0) FROM Class_B) <> (SELECT MAX(id) from Class_B)
- 在以前的 SQL 标准里,
HAVING子句必须和GROUP BY子句一起使用,所以到现在也有人会有这样的误解。但是,按照现在的 SQL 标准来说,HAVING子句是可以单独使用的。不过这种情况下,就不能在SELECT子句里引用原来的表里的列了,要么就得像示例里一样使用常量,要么就得像SELECT COUNT(*)这样使用聚合函数。 -
-- 查询缺失编号的最小值 SELECT MIN(seq + 1) AS gap FROM SeqTbl WHERE (seq + 1) NOT IN (SELECT seq FROM SeqTbl);
用 HAVING 子句进行子查询——求众数:
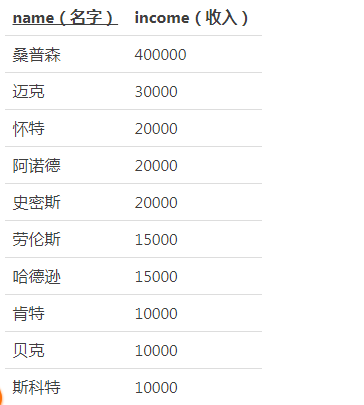
以上是毕业生收入表
- 从这个例子可以看出,简单地求平均值有一个缺点,那就是很容易受到离群值(outlier)的影响。这种时候就必须使用更能准确反映出群体趋势的指标——众数(mode)就是其中之一。它指的是在群体中出现次数最多的值,因此在日语中也被称为流行值。就上面的表 Graduates 来说,众数就是10000和20000这两个值。接下来我们思考一下如何用 SQL 语句求众数
- 思路是将收入相同的毕业生汇总到一个集合里,然后从汇总后的各个集合里找出元素个数最多的集合。
-
-- 求众数的 SQL 语句(1):使用谓词 SELECT income, COUNT(*) AS cnt FROM Graduates GROUP BY income
HAVING COUNT(*) >= ALL ( SELECT COUNT(*) FROM Graduates GROUP BY income );ALL谓词用于NULL或空集时会出现问题,可以用极值函数来代替。这里要求的是元素数最多的集合,因此可以用MAX函数。 -
-- 求众数的 SQL 语句(2):使用极值函数 SELECT income, COUNT(*) AS cnt FROM Graduates GROUP BY income
HAVING COUNT(*) >= ( SELECT MAX(cnt) FROM ( SELECT COUNT(*) AS cnt FROM Graduates GROUP BY income)TMP );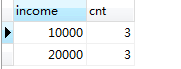
用 HAVING 子句进行自连接—求中位数:
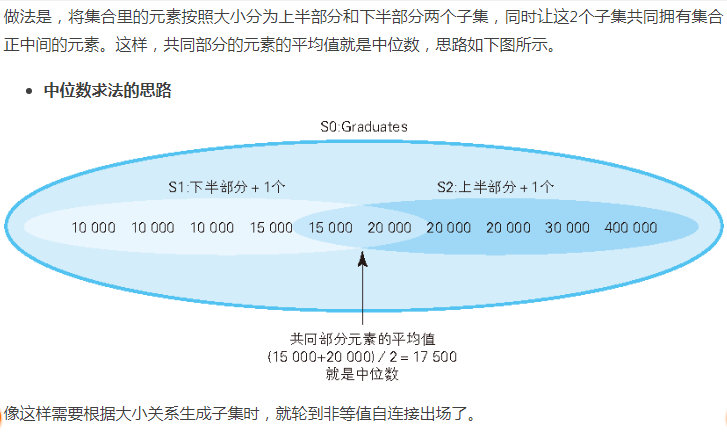
-- 求中位数的 SQL 语句:在 HAVING 子句中使用非等值自连接 SELECT AVG(DISTINCT income) FROM ( SELECT T1.income FROM Graduates T1, Graduates T2 GROUP BY T1.income HAVING SUM( CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END ) >= COUNT(*) / 2 -- S1 的条件 AND SUM( CASE WHEN T2.income <= T1.income THEN 1 ELSE 0 END ) >= COUNT(*) / 2 ) TMP; -- S2 的条件
这条 SQL 语句的要点在于比较条件“>= COUNT(*)/2”里的等号,这个等号是有意地加上的。加上等号并不是为了清晰地分开子集 S1 和 S2,而是为了让这2个子集拥有共同部分。如果去掉等号,将条件改成“>COUNT(*)/2”,那么当元素个数为偶数时,S1 和 S2 就没有共同的元素了,也就无法求出中位数了。
-
分析如下:
-
-- 自连接 有序对查询 100条 SELECT * FROM Graduates T1, Graduates T2; -- 把100条 GROUP BY T1.income后 分组成5组 SELECT T1.income, T2.income, SUM( CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END ) >= COUNT(*) / 2 , COUNT(*)/2 ,SUM( CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END ) FROM Graduates T1, Graduates T2 GROUP BY T1.income -- 最后再判断分组后的数据 是否符合查询查询条件 SELECT T1.income, T2.income, SUM( CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END ) >= COUNT(*) / 2 , COUNT(*)/2 ,SUM( CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END ) FROM Graduates T1, Graduates T2 GROUP BY T1.income
HAVING SUM( CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END ) >= COUNT(*)/2
查询不包含 NULL 的集合:
COUNT函数的使用方法有COUNT(*)和COUNT( 列名 )两种,它们的区别有两个:- 第一个是性能上的区别;
- 第二个是
COUNT(*)可以用于NULL,而COUNT( 列名 )与其他聚合函数一样,要先排除掉NULL的行再进行统计。 - (第二个区别也可以这么理解:
COUNT(*)查询的是所有行的数目,而COUNT( 列名 )查询的则不一定是。)
例一:
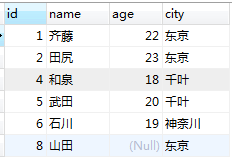
由上表举例说明:
-- 在对包含NULL 的列使用时,COUNT(*) 和 COUNT(列名) 的查询结果是不同的
SELECT COUNT(*), COUNT(age) FROM Class_B;
例二:
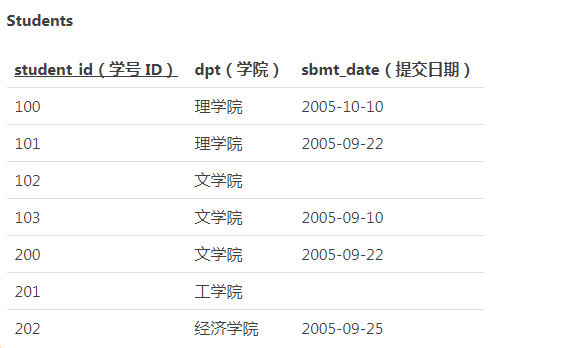
问题: 查询“提交日期”列内不包含 NULL 的学院
解法一:count(列名)
SELECT dpt FROM Students GROUP BY dpt HAVING COUNT(*) = COUNT(sbmt_date);
解法二:case
SELECT dpt FROM Students GROUP BY dpt HAVING COUNT(*) = SUM( CASE WHEN sbmt_date IS NOT NULL THEN 1 ELSE 0 END );
用关系除法运算进行购物篮分析:
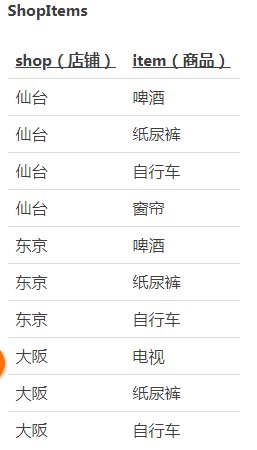

问题一:
-- 查询啤酒、纸尿裤和自行车同时在库的店铺:正确的 SQL 语句
SELECT SI.shop
FROM ShopItems SI, Items I
WHERE SI.item = I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items);
注意,如果把 HAVING 子句改成 HAVING COUNT(SI.item)=COUNT(I.item),结果就不对了。如果使用这个条件,仙台、东京、大阪这3个店铺都会被选中。这是因为,受到连接操作的影响,COUNT(I.item) 的值和表 Items 原本的行数不一样了。下面的执行结果一目了然。
-- COUNT(I.item) 的值已经不一定是3了 SELECT SI.shop, COUNT(SI.item), COUNT(I.item) FROM ShopItems SI, Items I WHERE SI.item = I.item GROUP BY SI.shop;
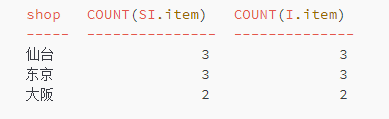
这是因为,受到连接操作的影响,COUNT(I.item) 的值和表 Items 原本的行数不一样了
问题二:
如何排除掉仙台店(仙台店的仓库中存在“窗帘”,但商品表里没有“窗帘”),让结果里只出现东京店。这类问题被称为“精确关系除法”(exact relational division),即只选择没有剩余商品的店铺(与此相对,前一个问题被称为“带余除法”(division with a remainder))。解决这个问题我们需要使用外连接。
-- 精确关系除法运算:使用外连接和 COUNT 函数
SELECT SI.shop
FROM ShopItems SI LEFT OUTER JOIN Items I
ON SI.item=I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items) -- 条件1
AND COUNT(I.item) = (SELECT COUNT(item) FROM Items); -- 条件2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号