

作业1
1)
1、实验题目
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
-
关键词:学生可自由选择
-
输出信息:MySQL的输出信息如下
![avatar]()

2、代码
2.1.spider类
start_requests() 访问网站并爬取5页内容
def start_requests(self): for i in range(5): # 爬取5页 url = 'http://search.dangdang.com/?key=python&act=input&page_index='+str(i) headers = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"} yield scrapy.Request(url=url, callback=self.parse, headers=headers)
查看网页源码发现有的detail为空
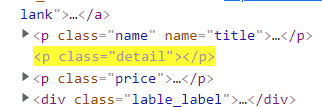
所以通过xpath匹配所需要的信息后进行如下处理
lis = response.xpath('//ul[@class="bigimg"]/li') item = BookspiderItem() # print(lis) for li in lis: # item["id"] = li.xpath('./li/@ddt-pit') title = li.xpath('./a/@title').extract_first() author = li.xpath('./p/span[1]/a/@title').extract_first() publisher = li.xpath('./p/span[3]//@title').extract_first() date = li.xpath('./p[@class="search_book_author"]/span[2]/text()').extract_first() price = li.xpath('./p[@class="price"]/span[1]/text()').extract_first() detail = li.xpath('./p[@class="detail"]/text()').extract_first() item["title"] = title.strip() if title else "" item["author"] = author.strip() if author else "" item["publisher"] = publisher.strip() if publisher else "" item["date"] = date.strip()[1:] if date else "" item["price"] = price.strip() if price else "" item["detail"] = detail.strip() if detail else "" print(item["title"], item["author"], item["publisher"], item["date"], item["price"], item["detail"]) yield item
2.2.items类
no = scrapy.Field() title = scrapy.Field() author = scrapy.Field() publisher = scrapy.Field() date = scrapy.Field() price = scrapy.Field() detail = scrapy.Field()
2.3.pipelines类
创建数据库
class BookDB: def __init__(self): self.con = sqlite3.connect("books.db") self.cursor = self.con.cursor() def openDB(self): try: self.cursor.execute( "create table books (序号 int(128),书名 varchar(128),作者 varchar(128)," "出版社 varchar(128),日期 varchar(128),价格 varchar(128),简介 varchar(256)," "constraint pk_books primary key (序号))") except: self.cursor.execute("delete from books") def closeDB(self): self.con.commit() self.con.close() def insert(self, no, title, author, publisher, date, price, detail): try: self.cursor.execute("insert into books (序号,书名,作者,出版社,日期,价格,简介) " "values (?,?,?,?,?,?,?)", (int(no), title, author, publisher, date, price, detail)) except Exception as err: print(err)
将数据存入数据库
def process_item(self, item, spider): self.count += 1 item["no"] = self.count print(self.count) self.db.insert(int(item["no"]), item["title"], item["author"], item["publisher"], item["date"], item["price"], item["detail"]) return item
码云链接:https://gitee.com/No_mad/crawl_project/blob/master/%E5%AE%9E%E9%AA%8C%E5%9B%9B%E4%BD%9C%E4%B8%9A1
3、结果
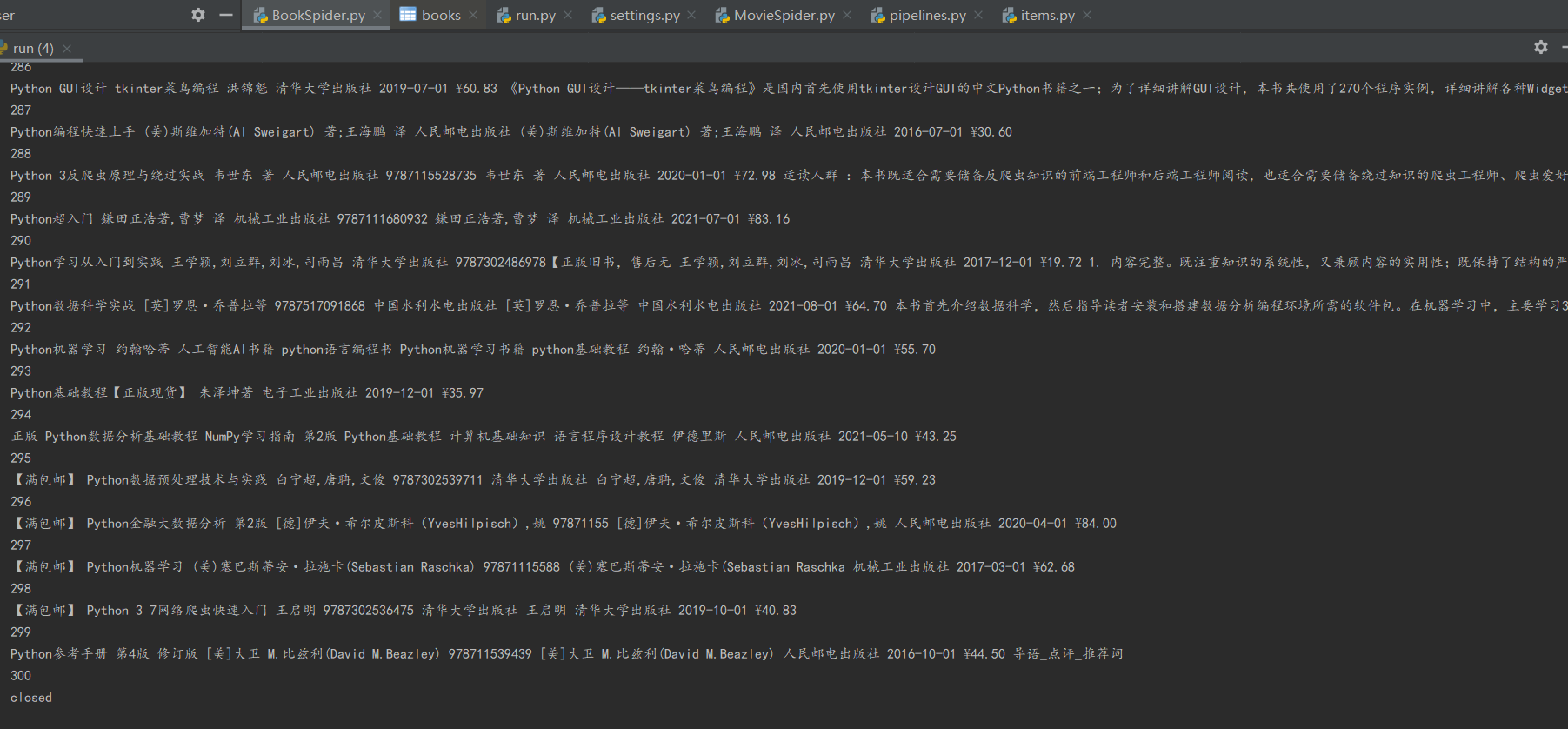
控制台输出结果
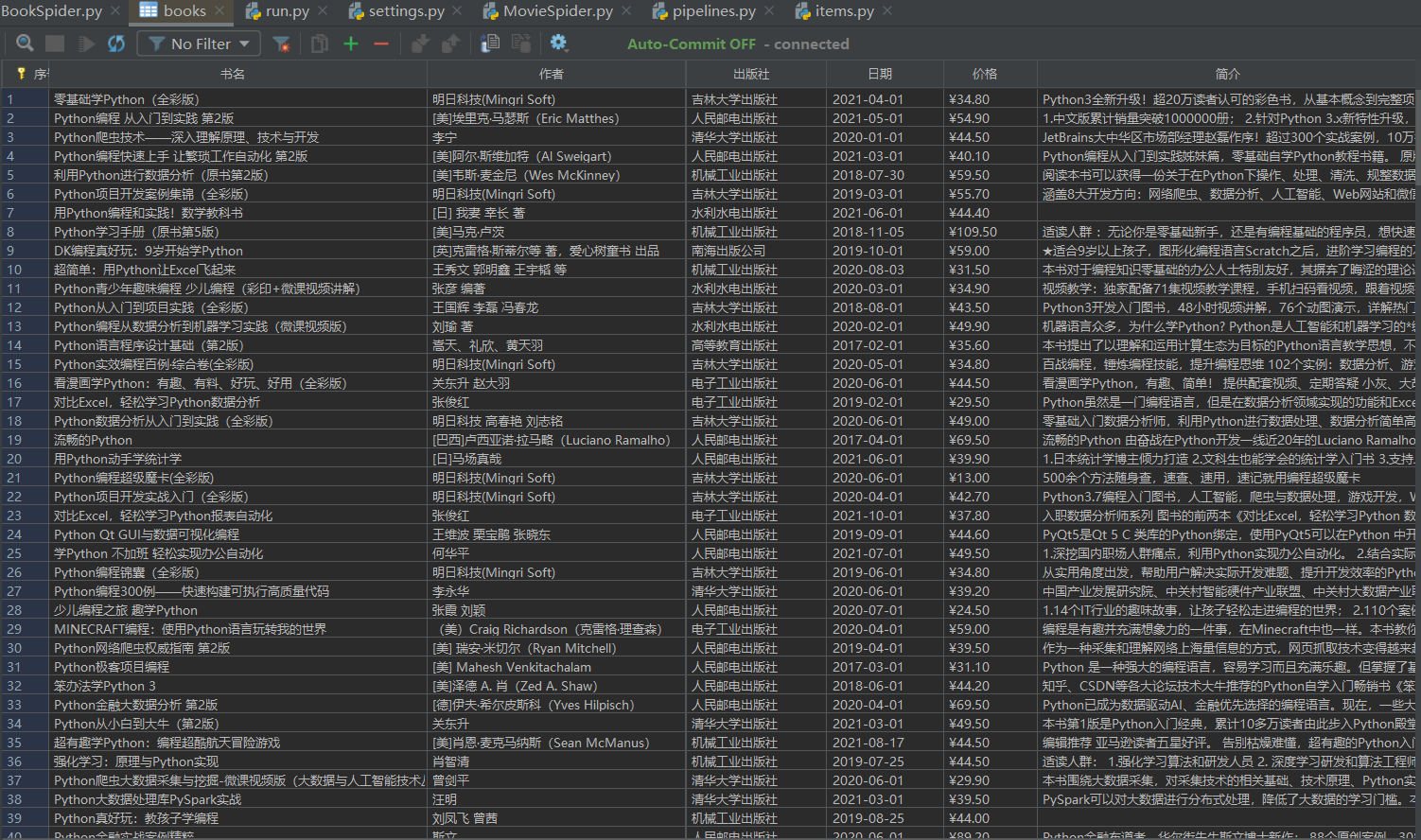
数据库
2)心得体会
熟悉了scrapy框架和xpath爬取网页的使用,熟练掌握数据库的使用
作业2
1)
1、实验题目
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/
-
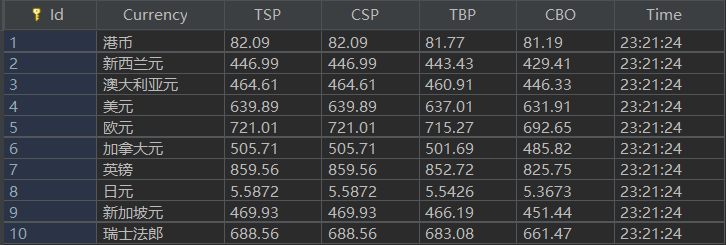
输出信息:MySQL数据库存储和输出格式
Id Currency TSP CSP TBP CBP Time 1 港币 86.60 86.60 86.26 85.65 15:36:30 2......
2、代码
2.1.查看网页源代码,找到xpath路径

2.2.因为有一列tr是标题而非所需数据,所以用如下操作避开它
trs = selector.xpath('//div[@id="realRateInfo"]/table/tr') count = 0 for tr in trs: # print(tr) if count == 0: count = count + 1 continue currency = tr.xpath("./td[1]/text()").extract_first() tsp = tr.xpath("./td[4]/text()").extract_first() csp = tr.xpath("./td[5]/text()").extract_first() tbp = tr.xpath("./td[6]/text() ").extract_first() cbp = tr.xpath("./td[7]/text()").extract_first() time = tr.xpath("./td[8]/text()").extract_first() item["currency"] = currency.strip() if currency else "" item["tsp"] = tsp.strip() if tsp else "" item["csp"] = csp.strip() if csp else "" item["tbp"] = tbp.strip() if tbp else "" item["cbp"] = cbp.strip() if cbp else "" item["time"] = time.strip() if time else "" # print(item["currency"], item["tsp"], item["csp"], item["tbp"], item["cbp"], item["time"]) yield item
其他大部分与第一题类似
详见码云:https://gitee.com/No_mad/crawl_project/blob/master/%E5%AE%9E%E9%AA%8C%E5%9B%9B%E4%BD%9C%E4%B8%9A2
3、结果
控制台输出结果
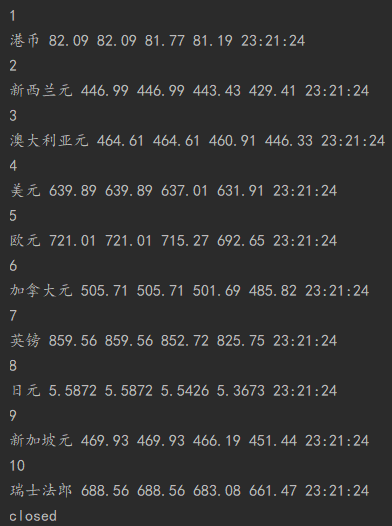
数据库结果
2)心得体会
熟练了scrapy框架和xpath的使用
作业3
1)
1、实验题目
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
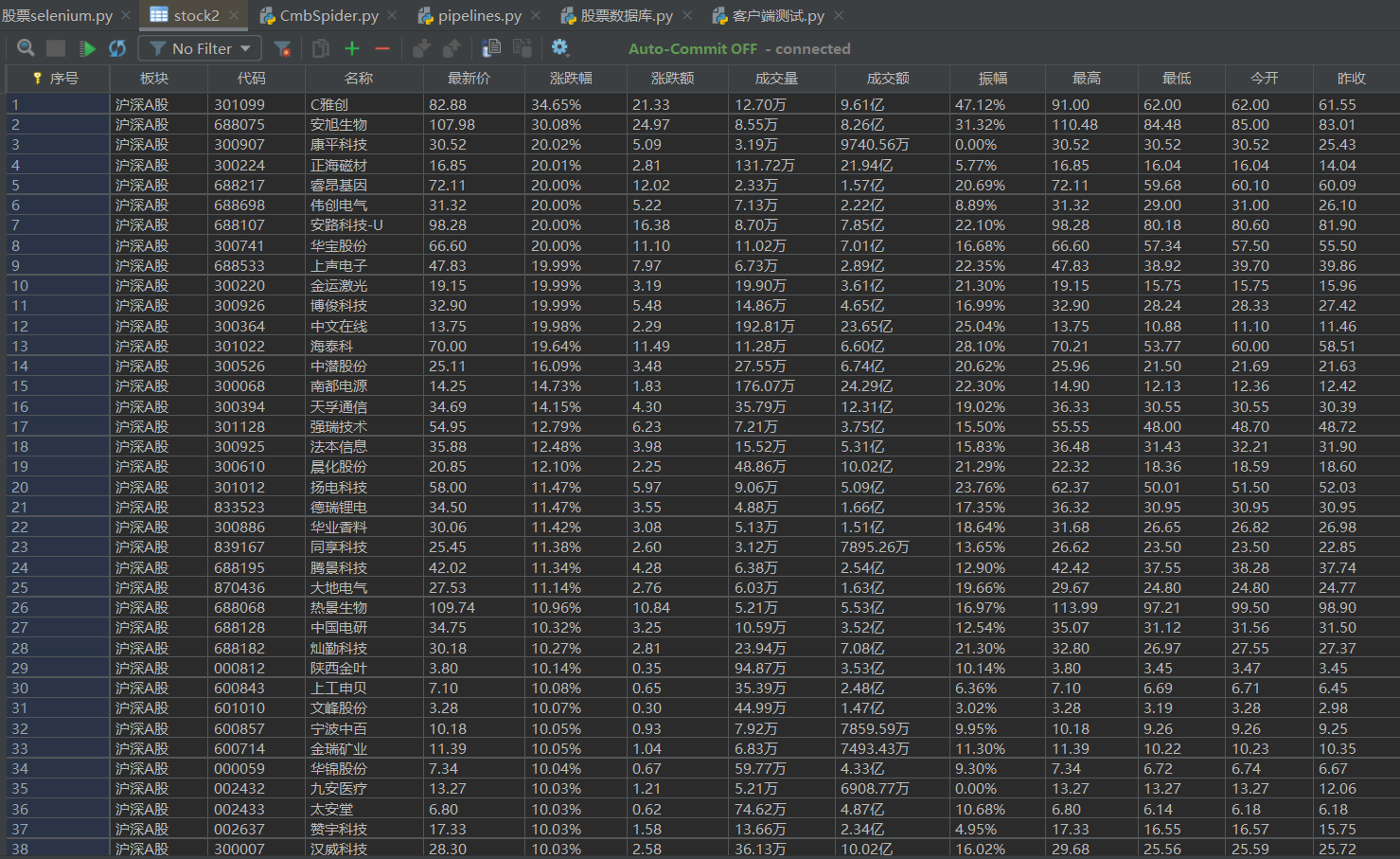
输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55 2......
2、代码
2.1.设置浏览器驱动等信息
driver = webdriver.Chrome() options = webdriver.ChromeOptions() options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2}) browser = webdriver.Chrome(options=options)
发现三个板块的转换是通过url后缀



因此设置
codes = ["hs_a_board", "sh_a_board", "sz_a_board"] names = ["沪深A股", "上证A股", "深证A股"]
2.2.建立数据库
class Stock2DB: def __init__(self): self.con = sqlite3.connect("stock2.db") self.cursor = self.con.cursor() def openDB(self): try: self.cursor.execute( "create table stock2 (序号 varchar(16), 板块 varchar(16), 代码 varchar(16), 名称 varchar(16), 最新价 varchar(16), " "涨跌幅 varchar(16), 涨跌额 varchar(16), 成交量 varchar(16), 成交额 varchar(16), 振幅 varchar(16), 最高 varchar(16), " "最低 varchar(16),今开 varchar(16),昨收 varchar(16), " "constraint pk_weather primary key (序号))") except: self.cursor.execute("delete from stock2") def closeDB(self): self.con.commit() self.con.close() def insert(self, No, Part, Code, Name, Price, Updown, Updownnumber, Trade, Tradenumber, Swing, Highest, Lowest, Today, Yesday): try: self.cursor.execute("insert into stock2 (序号, 板块, 代码, 名称, 最新价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低,今开,昨收)" "values (?,?,?,?,?,?,?,?,?,?,?,?,?,?)", ( No, Part, Code, Name, Price, Updown, Updownnumber, Trade, Tradenumber, Swing, Highest, Lowest, Today, Yesday)) except Exception as err: print(err)
2.3.此网站在之前的实验中也分析过,数据在tbody下面,tr为一行的数据
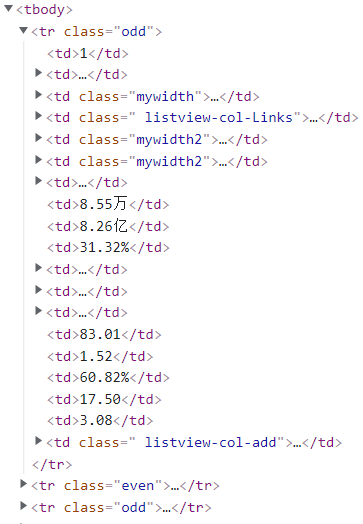
xpath匹配如下
trs = driver.find_elements('xpath', '//*[@id="table_wrapper-table"]/tbody/tr') for tr in trs: data = tr.text # print(data) data = data.split(" ") print(int(data[0]) + 40 * count, names_, data[1], data[2], data[6], data[7], data[8], data[9], data[10], data[11], data[12], data[13], data[14], data[15]) self.db.insert(int(data[0]) + 40 * count, names_, data[1], data[2], data[6], data[7], data[8], data[9], data[10], data[11], data[12], data[13], data[14], data[15])
2.4.翻页处理
try: # 翻页 next_page = WebDriverWait(driver, 3, 0.2).until( lambda x: x.find_element('xpath', '//*[@id="main-table_paginate"]/a[2]')) except Exception as e: print(e)
if temp == 2: #爬取两页 break else: next_page.click() time.sleep(1.5) webdriver.Chrome().refresh() #刷新网页 temp = temp + 1
码云:https://gitee.com/No_mad/crawl_project/blob/master/%E5%AE%9E%E9%AA%8C%E5%9B%9B%E4%BD%9C%E4%B8%9A3
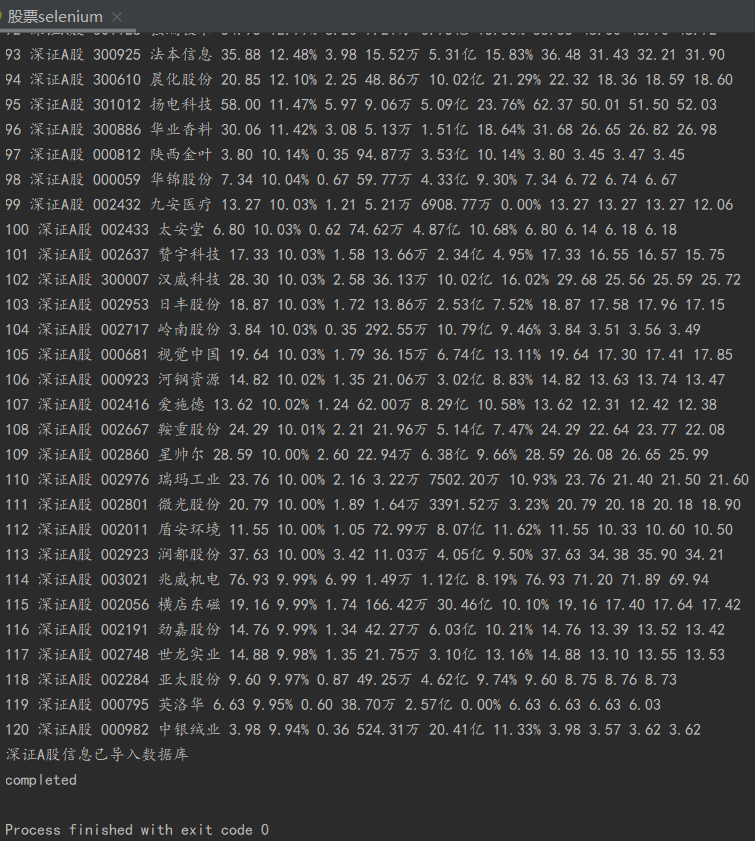
3、结果
控制台输出结果
数据库结果
2)心得体会
熟悉了selenium框架的使用和对网站自动化程序的理解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号