

作业①
1)
1、实验题目
- 要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后4位)
- 输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
2、代码
码云地址:https://gitee.com/No_mad/crawl_project/blob/master/%E5%AE%9E%E9%AA%8C%E4%B8%89%E4%BD%9C%E4%B8%9A1
3、结果
(单线程)

(多线程)
2)心得体会
了解了单线程爬取和多线程爬取的区别,多线程的速度比单线程快很多
作业②
1)
1、实验题目
-
要求:
使用scrapy框架复现作业①。 -
输出信息:
同作业①
2、代码
2.1.Spider类
start_requests方法
def start_requests(self): start_url = "http://www.weather.com.cn/" headers = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"} yield scrapy.Request(url=start_url, callback=self.parse, headers=headers)
parse方法获取网页链接
def parse(self, response, **kwargs): urls = [] data = response.body.decode(response.encoding) selector = scrapy.Selector(text=data) links = selector.xpath('//a/@href').extract() for link in links: if link[0:7] == "http://": if link not in urls: urls.append(link) for url in urls: # print(url) if self.count <= 109: yield scrapy.Request(url=url, callback=self.img_parse)
img_parse方法爬取图片
def img_parse(self, response, **kwargs): img_urls = response.xpath('//img/@src').extract() images = [] for img_url in img_urls: if img_url[0:7] == "http://": if img_url not in images: images.append(img_url) item = WeaspiderItem() item["img_url"] = img_url item["no"] = self.count print(img_url) # print(self.count) if self.count > 109: break self.count += 1 yield item
2.2.items类
class WeaspiderItem(scrapy.Item): # define the fields for your item here like: # img = scrapy.Field() img_url = scrapy.Field() no = scrapy.Field() pass
2.3.pipelines类下载图片
class WeaspiderPipeline: def process_item(self, item, spider): no = item["no"] url = item["img_url"] try: filename = './images/%s.jpg' % no urllib.request.urlretrieve(url, filename) except Exception as err: print(err) return item
码云地址:https://gitee.com/No_mad/crawl_project/blob/master/%E5%AE%9E%E9%AA%8C%E4%B8%89%E4%BD%9C%E4%B8%9A2
3、结果

2)心得体会
熟悉了scrapy的使用,加深了对scrapy框架爬取网页数据的原理的理解
作业③
1)
1、实验题目
- 要求:
爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
- 网站:
https://movie.douban.com/top250
- 输出信息:
序号 电影名称 导演 演员 简介 电影评分 电影封面 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 希望让人自由 9.7 ./imgs/xsk.jpg 2....
2、代码
2.1.Spider类
start_requests方法实现翻页爬取
def start_requests(self): for i in range(10): headers = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"} url = 'https://movie.douban.com/top250' +"?start="+str(i*25)+"&filter=" yield scrapy.Request(url=url, callback=self.parse, headers=headers)
parse方法获取所需数据
def parse(self, response): # print(response) lis = response.xpath('//ol/li') item = MoviespiderItem() # print(lis) for li in lis: item["no"] = li.xpath("./div/div/em/text()").extract_first() item["name"] = li.xpath("./div/div/a/img/@alt").extract_first() role = li.xpath('./div/div/div/p[1]/text()[1]').extract_first() role = role.split("\xa0\xa0\xa0") item["dire"] = role[0] item["act"] = role[1] item["intro"] = li.xpath("./div/div/div/p/span/text()").extract_first() item["score"] = li.xpath('./div/div/div/div/span[@class="rating_num"]/text()').extract_first() item["pic"] = li.xpath("./div/div/a/img/@src").extract_first() print(item["name"], item["dire"], item["act"], item["intro"], item["score"]) yield item
2.2.items类
class MoviespiderItem(scrapy.Item): # define the fields for your item here like: no = scrapy.Field() name = scrapy.Field() dire = scrapy.Field() act = scrapy.Field() intro = scrapy.Field() score = scrapy.Field() pic = scrapy.Field() pass
2.3.数据库类
class MovieDB: def __init__(self): self.con = sqlite3.connect("movies.db") self.cursor = self.con.cursor() def openDB(self): try: self.cursor.execute( "create table movies (序号 int(128),电影名称 varchar(128),导演 varchar(128)," "演员 varchar(128),简介 varchar(128),电影评分 varchar(128),电影封面 varchar(128)," "constraint pk_movies primary key (序号))") except: self.cursor.execute("delete from movies") def closeDB(self): self.con.commit() self.con.close() def insert(self, no, name, dire, act, intro, score, pic): try: self.cursor.execute("insert into movies (序号,电影名称,导演,演员,简介,电影评分,电影封面) " "values (?,?,?,?,?,?,?)", (int(no), name, dire, act, intro, score, pic)) except Exception as err: print(err)
2.4.pipelines类下载文件,并将数据存入数据库中
class MoviespiderPipeline: def __init__(self): self.db = MovieDB() def open_spider(self, spider): self.db.openDB() def process_item(self, item, spider): try: url = item["pic"] file_name = item["name"] filename = './images/%s.jpg' % file_name urllib.request.urlretrieve(url, filename) self.db.insert(int(item["no"]), item["name"], item["dire"], item["act"], item["intro"], item["score"], item["pic"]) except Exception as err: print(err) return item def close_spider(self, spider): self.db.closeDB() print("closed")
码云地址:https://gitee.com/No_mad/crawl_project/blob/master/%E5%AE%9E%E9%AA%8C%E4%B8%89%E4%BD%9C%E4%B8%9A3
3、结果
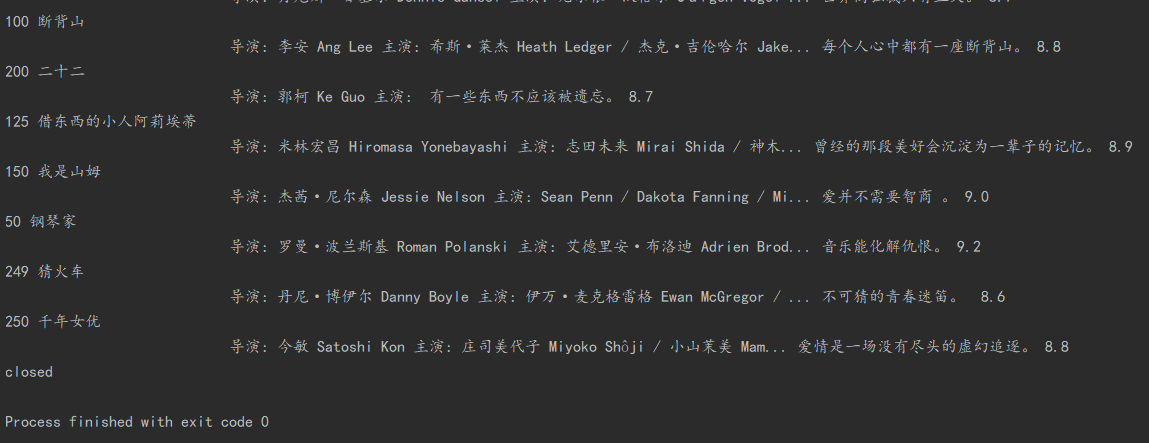
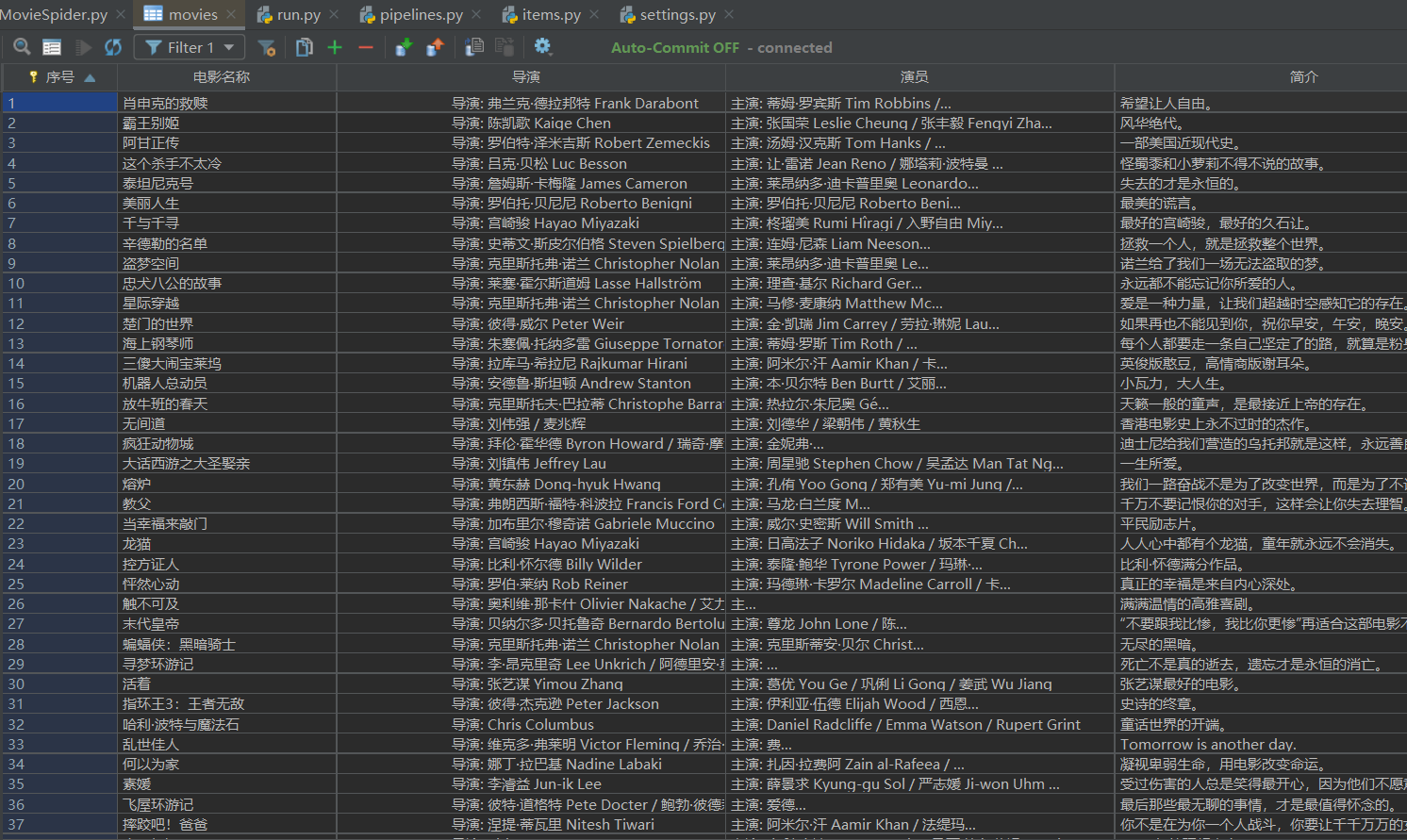
2)心得体会
学会了scrapy与数据库的联合使用,加深了对scrapy爬取网站的理解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号