
作业①
1)
1、实验题目
- 要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
- 输出信息:
| 序号 | 地区 | 日期 | 天气信息 | 温度 |
| 1 | 北京 | 7日(今天) | 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 | 31℃/17℃ |
| 2 | 北京 | 8日(明天) | 多云转晴,北部地区有分散阵雨或雷阵雨转晴 | 34℃/20℃ |
| 3 | 北京 | 9日(后台) | 晴转多云 | 36℃/22℃ |
| 4 | 北京 | 10日(周六) | 阴转阵雨 | 30℃/19℃ |
| 5 | 北京 | 11日(周日) | 阵雨 | 27℃/18℃ |
| 6...... |
2、代码
本题为代码复现
码云地址:https://gitee.com/No_mad/crawl_project/blob/master/%E5%AE%9E%E9%AA%8C%E4%BA%8C%E4%BD%9C%E4%B8%9A1
3、结果

2)心得体会
通过本题我学会了如何用python创建数据库及插入数据,也对beautifulsoup的一些使用有了更深入的了解
作业②
1)
1、实验题目
-
要求:用requests和自选提取信息方法定向爬取股票相关信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
-
输出信息:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2...... |
2、代码
2.1.创建Stock数据库,与第一题类似
def __init__(self): self.con = sqlite3.connect("stock.db") self.cursor = self.con.cursor() def openDB(self): try: self.cursor.execute( "create table stock (序号 varchar(16), 代码 varchar(16), 名称 varchar(16), 最新价 varchar(16), 涨跌幅 varchar(16), " "涨跌额 varchar(16), 成交量 varchar(16), 成交额 varchar(16), 振幅 varchar(16), 最高 varchar(16), " "最低 varchar(16),今开 varchar(16),昨收 varchar(16), " "constraint pk_weather primary key (代码))") except: self.cursor.execute("delete from stock") def closeDB(self): self.con.commit() self.con.close() def insert(self, No, Code, Name, Price, Updown, Updownnumber, Trade, Tradenumber, Swing, Highest, Lowest, Today, Yesday): try: self.cursor.execute("insert into stock (序号, 代码, 名称, 最新价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低,今开,昨收)" "values (?,?,?,?,?,?,?,?,?,?,?,?,?)", ( No, Code, Name, Price, Updown, Updownnumber, Trade, Tradenumber, Swing, Highest, Lowest, Today, Yesday)) except Exception as err: print(err) def show(self): self.cursor.execute("select * from stock") rows = self.cursor.fetchall() print("%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s" % ( "序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收")) for row in rows: print("%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s" % ( row[0], row[1], row[2], row[3], row[4], row[5], row[6], row[7], row[8], row[9], row[10], row[11], row[12]))
2.2.通过js抓包获取url
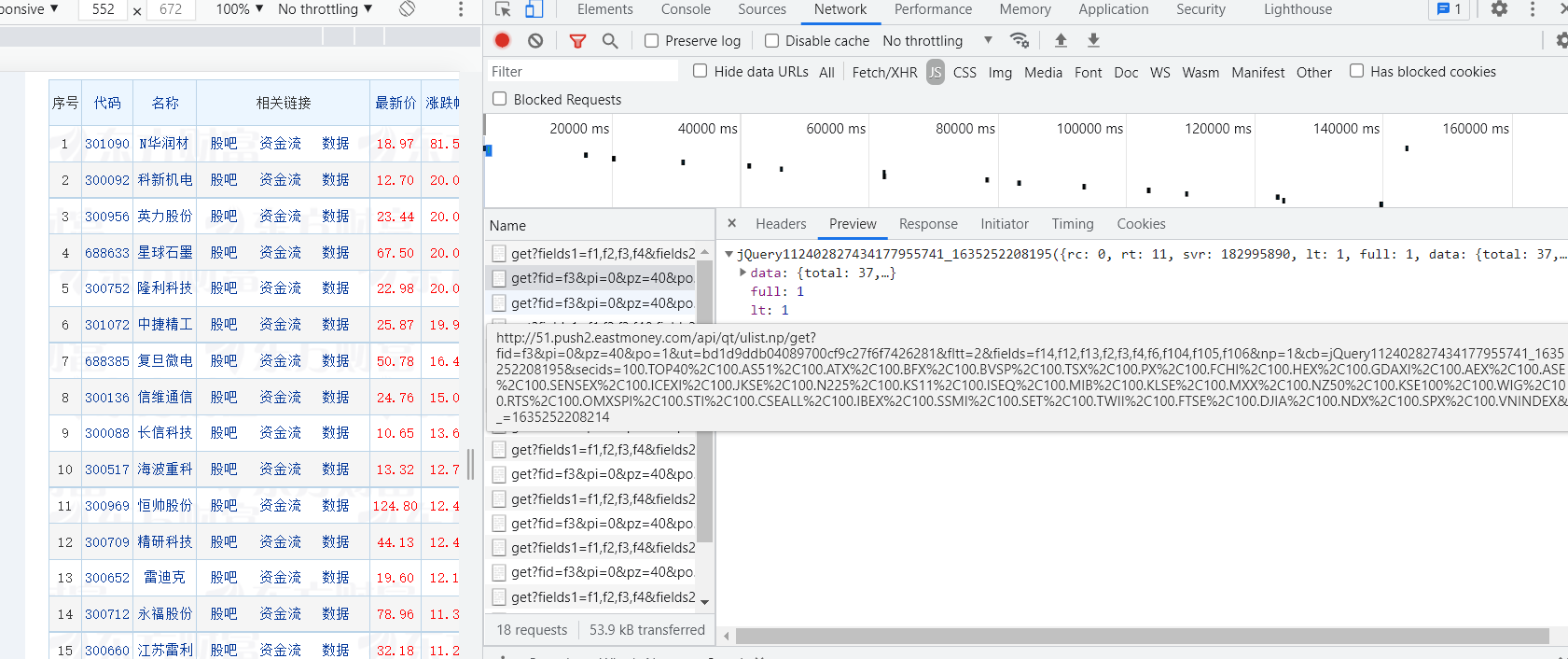
2.3.利用正则表达式匹配所需要的数据
Code = re.findall('"f12":"(.*?)"', data)[0] Name = re.findall('"f14":"(.*?)"', data)[0] Price = re.findall('"f2":(.*?),', data)[0] Updown = re.findall('"f3":(.*?),', data)[0] Updownnumber = re.findall('"f4":(.*?),', data)[0] Trade = re.findall('"f5":(.*?),', data)[0] Tradenumber = re.findall('"f6":(.*?),', data)[0] Swing = re.findall('"f7":(.*?),', data)[0] Highest = re.findall('"f15":(.*?),', data)[0] Lowest = re.findall('"f16":(.*?),', data)[0] Today = re.findall('"f17":(.*?),', data)[0] Yesday = re.findall('"f18":(.*?),', data)[0]
码云地址:https://gitee.com/No_mad/crawl_project/blob/master/%E5%AE%9E%E9%AA%8C%E4%BA%8C%E4%BD%9C%E4%B8%9A2
3、结果

数据库结果
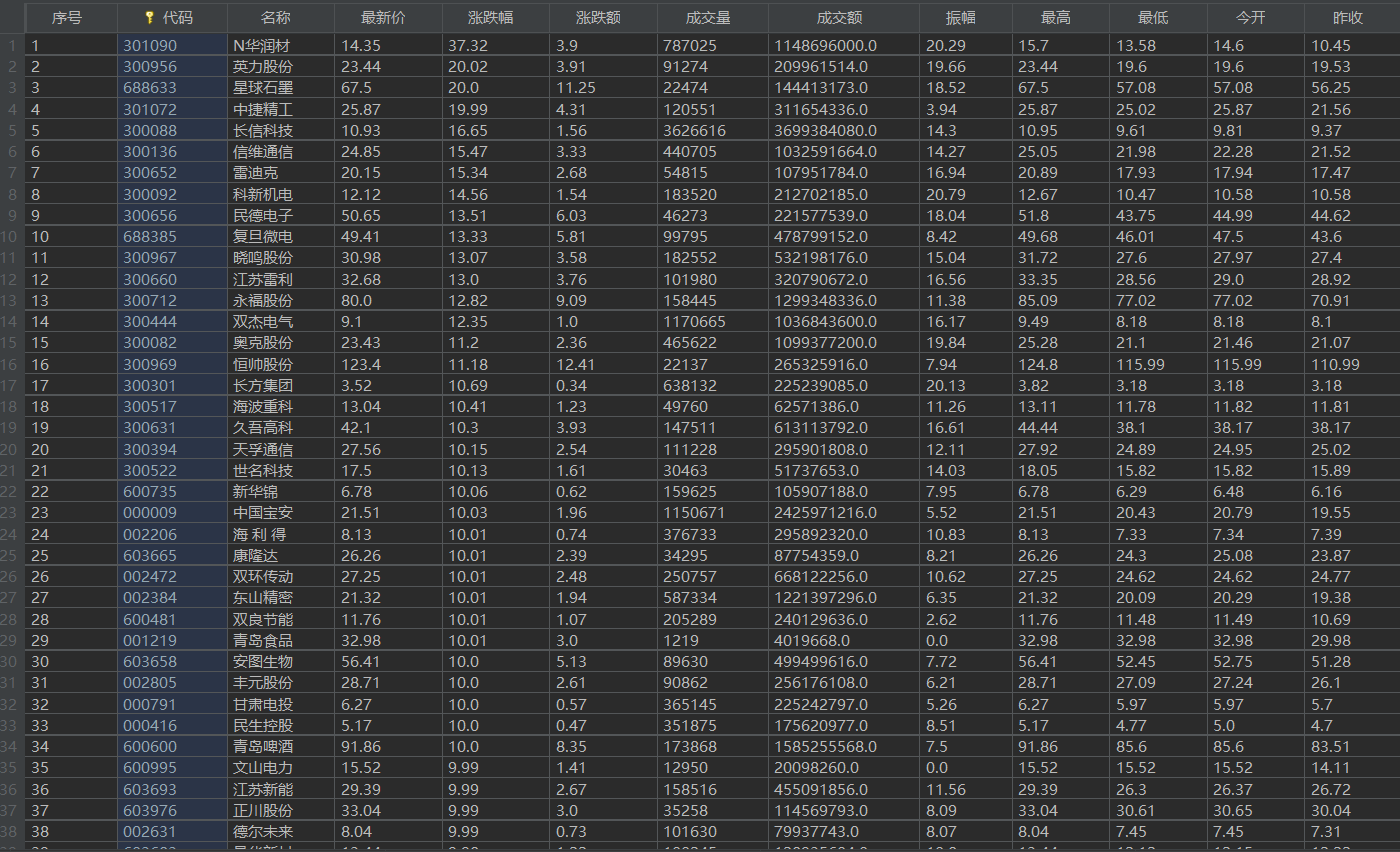
2)心得体会
通过本题我更加熟悉了数据库的创建,学会了js抓包提取网页数据以及数据库结果的展示。但是对正则表达式的使用还是不够熟练,也知道了针对一些错误的解决办法
作业③
1)
1、实验题目
- 要求: 爬取中国大学2021主榜 https://www.shanghairanking.cn/rankings/bcur/2021
所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。 - 技巧: 分析该网站的发包情况,分析获取数据的api
- 输出信息:
| 排名 | 学校 | 总分 |
|---|---|---|
| 1 | 清华大学 | 969.2 |
2、代码
2.1.创建School数据库
def openDB(self): self.con=sqlite3.connect("schools.db") self.cursor=self.con.cursor() try: self.cursor.execute("create table schools (排名 varchar(16),学校 varchar(16),总分 varchar(16),constraint pk_weather primary key (学校))") except: self.cursor.execute("delete from schools") def closeDB(self): self.con.commit() self.con.close() def insert(self, rank, name, score): try: self.cursor.execute("insert into schools (排名, 学校 ,总分) values (?,?,?)",(rank, name, score)) except Exception as err: print(err) def show(self): rows = self.cursor.fetchall() print("%-16s%-16s%-16s" % ("排名", "学校", "总分")) for row in rows: print("%-16s%-16s%-16s" % (row[0], row[1], row[2]))
2.2.通过js抓包

2.3.通过正则表达式匹配
req = requests.get(url, headers=self.headers) req.encoding = 'utf-8' #因为网页是用UTF-8编码的 pat = r'univNameCn:.*?,.*?score:.*?,' name = re.findall(r'univNameCn:"(.*?)"', str(data))[0] score = re.findall(r'score:(.*?),', data)[0]
码云地址:https://gitee.com/No_mad/crawl_project/blob/master/%E5%AE%9E%E9%AA%8C%E4%BA%8C%E4%BD%9C%E4%B8%9A3
3、结果
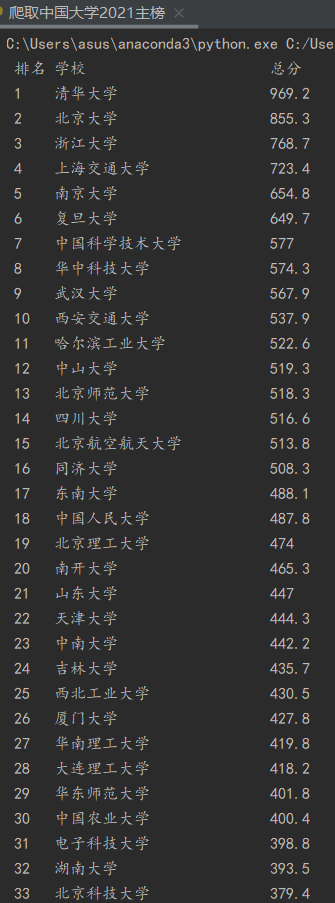
数据库结果

2)心得体会
经过前两次的实验后,这次实验就比较轻松的完成了,也使我更加熟悉了js抓包的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号