

- 作业①:
– 要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
– 输出信息:
|
2020排名 |
2019排名 |
全部层次 |
学校类型 |
总分 |
|
1 |
2 |
前2% |
中国人民大学 |
1069.0 |
|
2...... |
|
|
|
|
1.发送请求获取网页源代码
url="https://www.shanghairanking.cn/rankings/bcsr/2020/0812" #headers={"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Mobile Safari/537.36"}
#之前的headers引用出错了,于是打算不使用headers req=urllib.request.Request(url) data=urllib.request.urlopen(req) data=data.read().decode().replace("\n","")
2.正则表达式匹配所需要的信息
reg=r'<tbody .*?>.*?</tbody>' reg=re.compile(reg,re.S) list=reg.findall(data) for item in list: reg_rank=r'<div class="ranking" data-v-68e330ae>(.*?)</div>' rank=re.findall(reg_rank, item) reg_level=r'</span></td><td data-v-68e330ae>(.*?)<!----></td>' level=re.findall(reg_level, item) reg_name=r'<a .*?>(.*?)</a>' name=re.findall(reg_name, item) reg_grade=r'</div></td><td data-v-68e330ae>(.*?)</td></tr>' grade=re.findall(reg_grade, item) #print(rank)
3.处理匹配到的信息并打印
for j in range(len(rank)): rank[j]=rank[j].strip() level[j]=level[j].strip() name.remove('') grade[j]=grade[j].strip() print("{:^10}\t{:^12}\t{:^28}\t{:^13}".format(rank[j], level[j], name[j], grade[j]))
4.运行结果
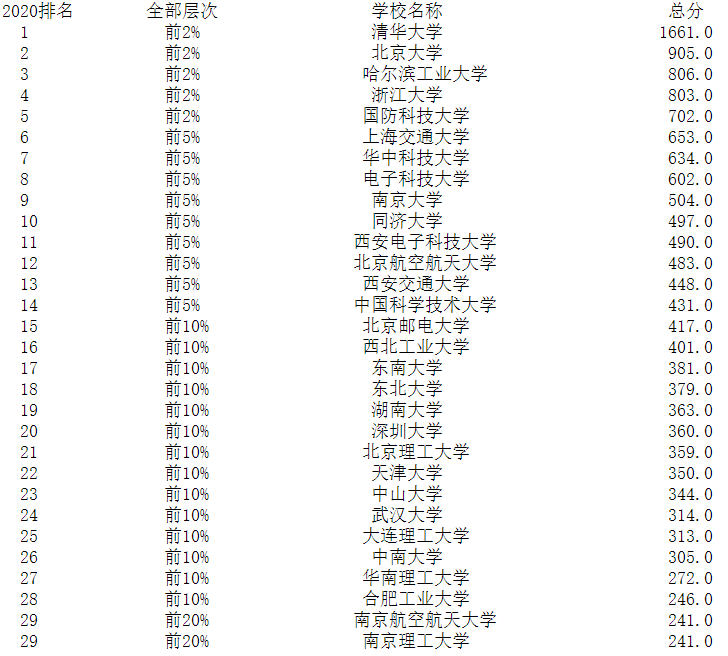
5.心得体会:作业一要求只能用urllib和re库,对于我们的正则表达式的掌握有一定的要求,通过这次实验我也更加清晰的掌握了re库以及正则表达式的用法。
• 作业②:
– 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
– 输出信息:
|
序号 |
城市 |
AQI |
PM2.5 |
SO2 |
No2 |
Co |
首要污染物 |
|
1 |
北京 |
55 |
6 |
5 |
1.0 |
225 |
— |
|
2...... |
|
|
|
|
|
|
|
1.发送请求获取网页源代码
url="https://datacenter.mee.gov.cn/aqiweb2/ " req = urllib.request.Request(url) data = urllib.request.urlopen(req) data = data.read().decode('gbk')#这里需要使用gbk
2.用bs4的BeautifulSoup创建soup对象并获取所需信息
soup = bs4.BeautifulSoup(data,"html.parser")
ulist=[] for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): tds = tr('td') ulist.append([tds[0].text.strip(), tds[1].text, tds[2].text.strip(), tds[4].text.strip(), tds[5].text.strip(), tds[6].text.strip(), tds[8].text.strip()])
3.输出
for i in range(len(ulist)): u = ulist[i] print("{:^8}\t{:^14}\t{:^10}\t{:^8}\t{:^10}\t{:^10}\t{:^10}\t{:^10}".format(i+1, u[0], u[1], u[2], u[3], u[4], u[5], u[6]))
4.结果如下
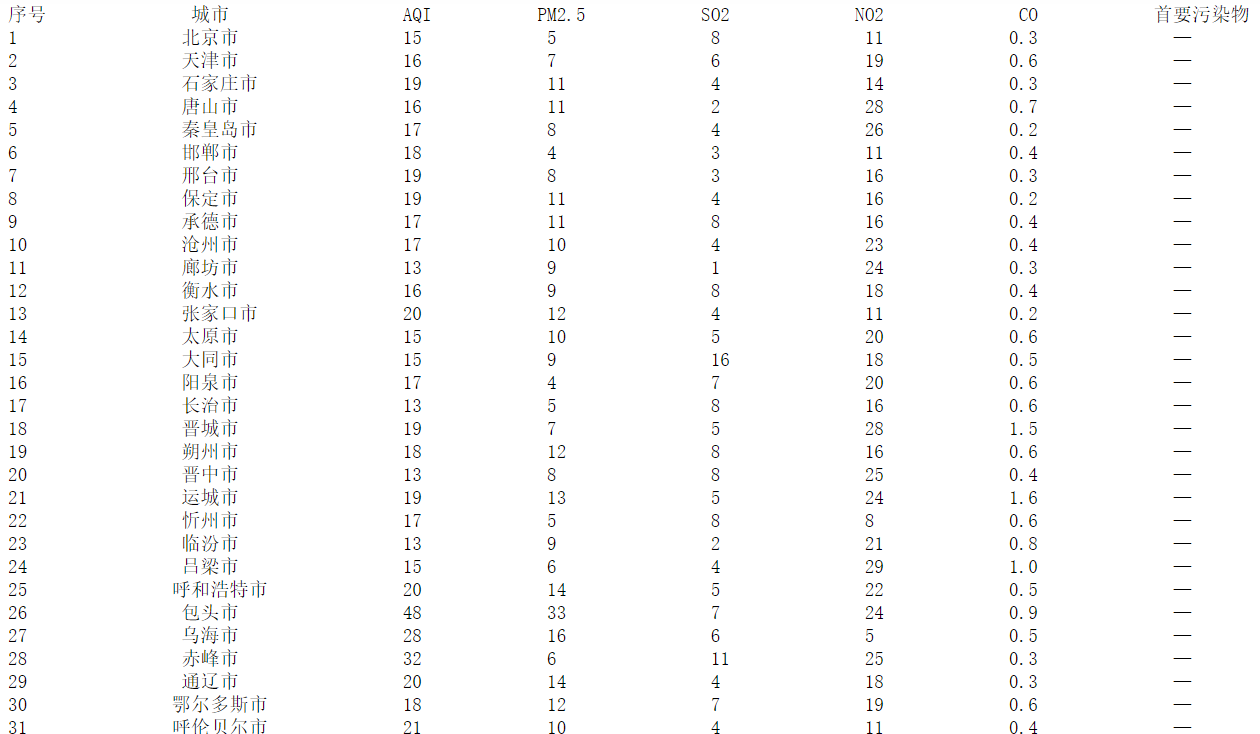

5.心得体会:作业二允许使用Beautiful Soup,我认为bs4库的使用还是相对简单的,方便快捷,这次实验也加深了对其使用的熟练度
• 作业③:
– 要求:使用urllib和requests和re爬取一个给定网页(https://news.fzu.edu.cn/)爬取该网站下的所有图片
– 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
1.发送请求获取网页源代码
url="http://news.fzu.edu.cn/" headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'} req=requests.get(url) req.encoding = req.apparent_encoding
2.利用正则表达式获取图片并下载
reg=r'img src="(.*?)"' list=re.findall(reg,data) for x,i in enumerate(list): #print(i) filename='./img/%s.jpg'%x urllib.request.urlretrieve(url+i,filename)
3.结果如下
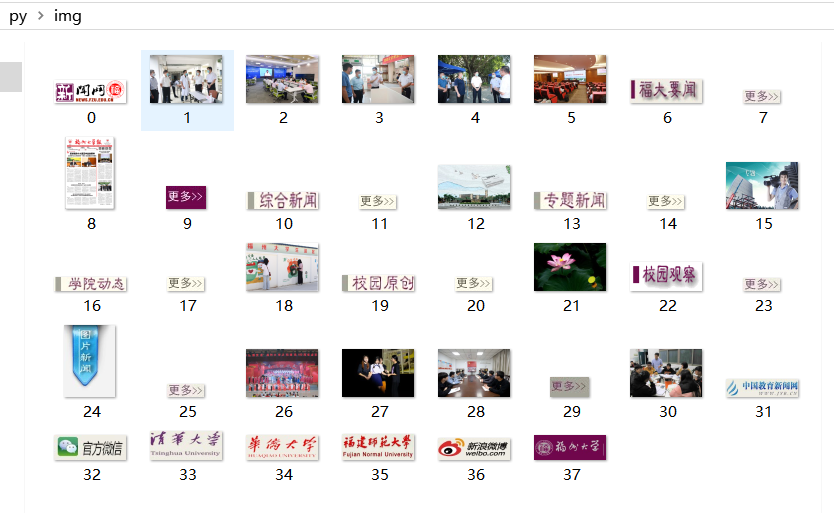
4.心得体会:作业三在作业一的使用正则表达式的基础上,还需要我们掌握网页上图片的下载,使我在以前的作业的上更进一步理解了urllib.request.urlretrieve表达式的一些含义与使用方法。
码云链接:https://gitee.com/No_mad

 浙公网安备 33010602011771号
浙公网安备 33010602011771号