从mysql调用链接爬取章节
调用数据库小说链接进行爬取
完整链接
from bs4 import BeautifulSoup import requests import time import pymysql class DB: def __init__(self,host='',port=3306,user='',password='',db='',charset='utf8'): self.conn=pymysql.connect(host=host,user=user,port=port,password=password,database=db,charset=charset) self.cur=self.conn.cursor() def __enter__(self): return self.cur def __exit__(self, exc_type, exc_val, exc_tb): self.conn.commit() self.cur.close() self.conn.close() def dataUrl(url): # url='http://www.d3zww.com/book/5/5663/' header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52'} html = requests.get(url, headers=header) html.raise_for_status() html.encoding= html.apparent_encoding bs = BeautifulSoup(html.text, 'html.parser') return bs def dataHtml(bs, db): xname=bs.find('div',{'class':'book_info'}).find('h1').string zt=bs.find('div',{'class':"book_list"}).find_all('li')#小说名 # print(xname) # time.sleep(3) for i in zt: zname = i.find('a').get_text().strip()#章节名称 link=i.find('a')['href']#章节链接 #print(zhangjiename,zhangjielink) urll='http://www.d3zww.com/' fullUrl=urll+link # 'http://www.d3zww.com/'+抓取出的章节链接 link=fullUrl print(xname,zname,link) # print(fullUrl) # 完整的网页 para = [xname,zname,link] db.execute('insert into zhangjie(xname,zname,link) values(%s,%s,%s)', para) def main(db): db.execute('select link from xiaoshuo ') # 查询字段 result = db.fetchall() # 获取所有数据 # print(result) for s in (result): # url = (''.format#(result) x = '-'.join(s) print(x) url = x.format(s) bs = dataUrl(url) dataHtml(bs,db) time.sleep(2) if __name__ == '__main__': with DB(host='localhost',user='root',password='root',db='shixun') as db: db.execute('SET NAMES utf8') main(db)
可能会出现的错误
这是从数据库调用出来的链接
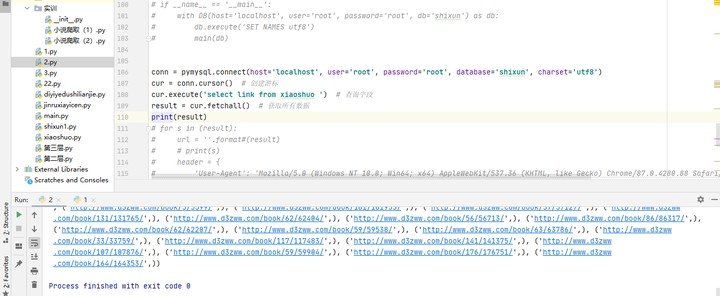
但是在运用的时候发生了下图的错误
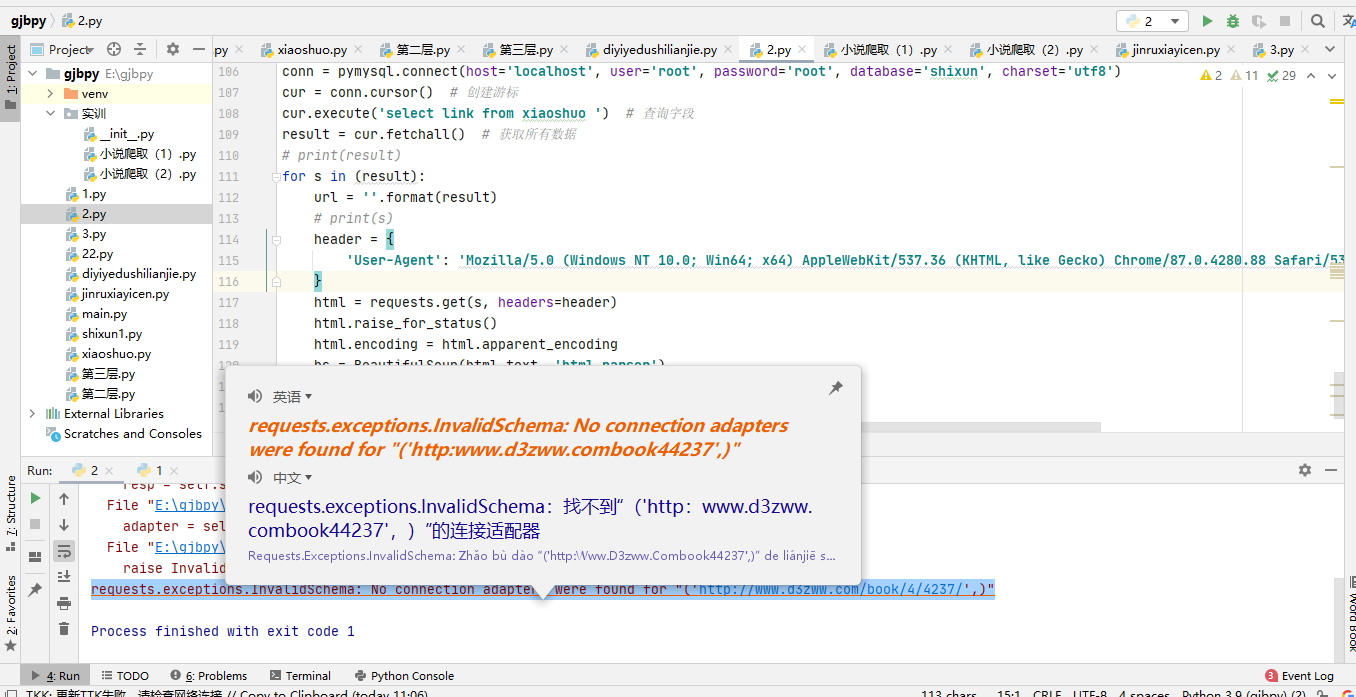
找不到连接的适配器
我们把链接拉出来单独运行
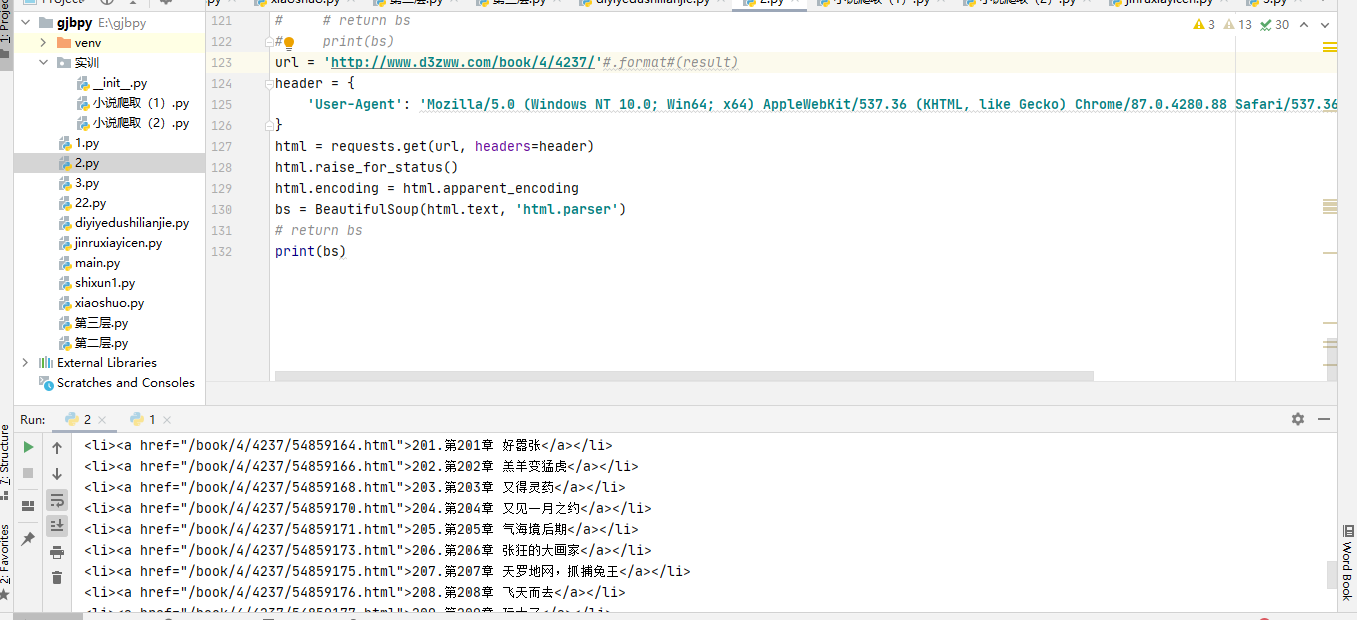
仔细观察发现从数据库导出来的链接元组都带有圆括号那么怎么去除元组带有的圆括号呢
这就需要一个join函数
一、函数说明
1、join()函数
语法: 'sep'.join(seq)
参数说明
sep:分隔符。可以为空
seq:要连接的元素序列、字符串、元组、字典
上面的语法即:以sep作为分隔符,将seq所有的元素合并成一个新的字符串
返回值:返回一个以分隔符sep连接各个元素后生成的字符串
2、os.path.join()函数
语法: os.path.join(path1[,path2[,......]])
返回值:将多个路径组合后返回
注:第一个绝对路径之前的参数将被忽略
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
#对序列进行操作(分别使用' '与':'作为分隔符) >>> seq1 = ['hello','good','boy','doiido']>>> print ' '.join(seq1)hello good boy doiido>>> print ':'.join(seq1)hello:good:boy:doiido #对字符串进行操作 >>> seq2 = "hello good boy doiido">>> print ':'.join(seq2)h:e:l:l:o: :g:o:o:d: :b:o:y: :d:o:i:i:d:o #对元组进行操作 >>> seq3 = ('hello','good','boy','doiido')>>> print ':'.join(seq3)hello:good:boy:doiido #对字典进行操作 >>> seq4 = {'hello':1,'good':2,'boy':3,'doiido':4}>>> print ':'.join(seq4)boy:good:doiido:hello #合并目录 >>> import os>>> os.path.join('/hello/','good/boy/','doiido')'/hello/good/boy/doiido' |
你学废了吗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号