这款神器能帮你在国庆更好地选择酒店
难得周末,我跑去小伙伴阿木家想拉他一块儿出去浪,却发现他还在电脑前貌似在努力地工作。这让我感到很惊讶,差点以为他又被自我幻想出来的对象抛弃然后被沉迷工作不能自拔了~
聊了一会儿得知原来是在为国庆出去游玩做准备,正在收集酒店的信息,用作数据对比,最大限度地避免踩雷。我发现他在做的事基本就是:打开网站》选择信息》复制信息》粘贴进excel表格,循环往复,到最后再来筛选,这让我想起了一个爬虫神器应该可以帮到他省很多事——Web scraper

这是一个Chrome的扩展程序,用于自动抓取网站数据的工具,可以抓取淘宝,知乎,阿里巴巴,豆瓣,简书等等网站的信息,而且基本不需要用到代码,就算是不懂程序的小白也稍微练习一下也能运用自如

当然,我说得多神奇操作多简单,阿木也以为我在吹牛,而且也没耐心学,于是我决定给他展示了一遍如何爬取携程网站的酒店名称,评分,房价和酒店联系方式

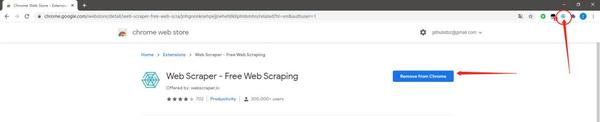
第一步,Chrome浏览器装Web scraper插件。
如果你能上外网的话,可以在浏览器直接打开Chrome应用商店,然后搜索“Web scraper”后直接点“Add to Chrome”装进浏览器里。不能上的话,可以通过装一个谷歌上网助手插件就可以上谷歌应用商店了,或者通过获取离线CRX安装包改成Zip格式,解压后加载进浏览器里。装好后就可以在右上角看到一个类似蜘蛛网的图标
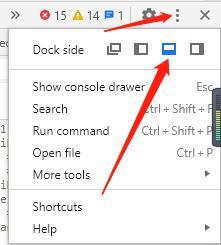
第二步,打开想要抓取数据的网站和开发者工具。
在想要爬取的携程网站上,键盘摁F12打开开发者工具。第一次打开可能显示在浏览器右侧,可以点右上角三个小点的地方,让它显示在下方方便操作
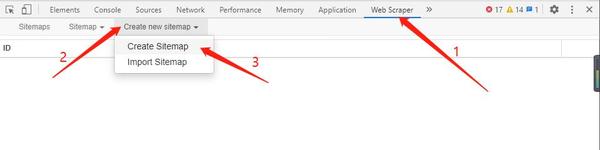
第三步,在开发者工具上的Web Scraper设置Sitemap
1,先点create new sitemap》Create Sitemap,创建一个Sitemap
2,随便填写一个Sitemap name,包括后面出现的Id名称,都是可以随便填写的,只是用于备注。再把网页的网址复制粘贴进Start URL里面后提交
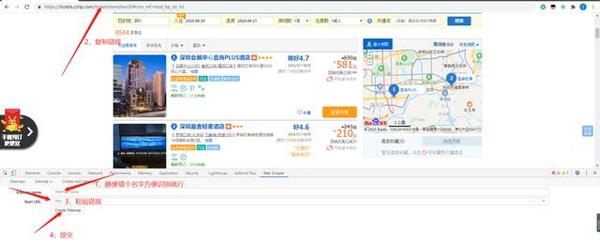
3,点Add new selector后Id部分再随便填一个,我这边命名为home,也是为了辨认
在Type里面选择的是Element。
点一下Select,将鼠标移动到其中一个酒店区域,找到能让它整个框变红的地方点一下,再将鼠标移动到紧随着的第二个酒店,同样方法点一下。
这时候后会发现页面所有酒店都变红了,点一下done selecting。
打钩Multiple后提交保存。
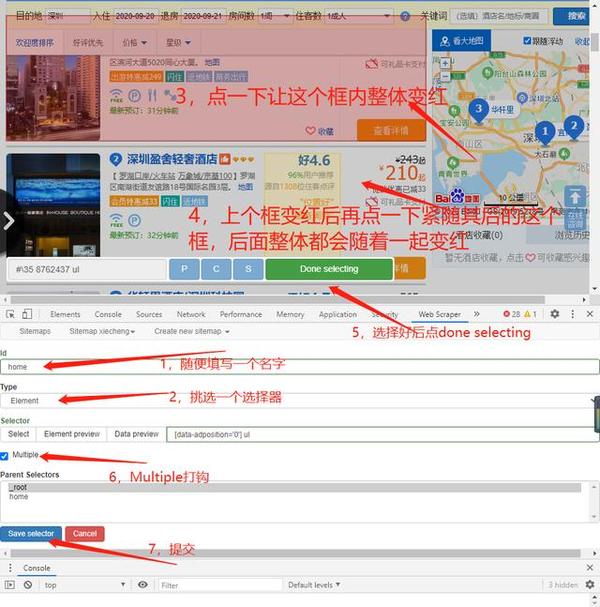
5,上面一步相当于把表格方式做好,接下来就是把信息数据放进表格。
用鼠标点进去刚刚创建的home里面,在里面点Add new selector创建子集
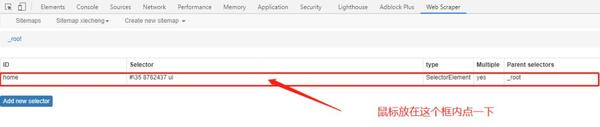
6,注意是点进去home里面后再Add new selector哦,然后填写一下Id,这次要爬取的是文本信息,所以Type选择的是Text,Multiple不用打勾,Selector直接鼠标选取想要提取的文本即可,然后保存。记得要一个一个设置,比如把采集酒店名称的参数设置好后,再在同个页面点多一次Add new selector设置采集价格的参数后保存,采集几个信息就保存几次。
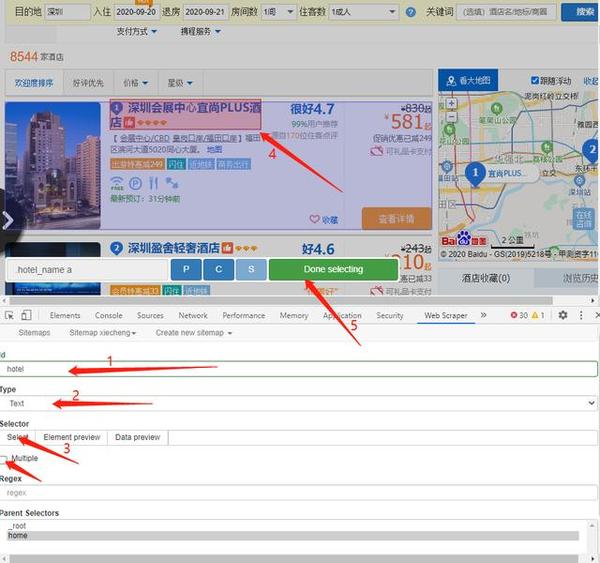
7,在这个页面可以爬取到酒店名字(Id备注为:hotel),评分(Id备注为:grade),价格(Id备注为:price)。可是联系方式需要点进去酒店到耳机页面才能看到,于是需要创建一个让它自动打开页面的方式再爬取。方法跟刚刚上面爬取酒店名字方式一样,只是Type里面的Text改为Link,然后保存用于自动打开二级界面
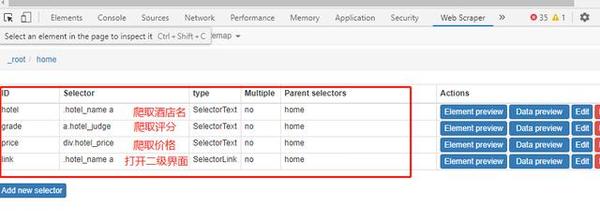
8,点进去跳转到酒店详情页面,找到联系方式,这时候我们发现,联系方式需要点一下才会显示号码,于是我们得让它还能自动帮我们点击一下,这时候可以在link里面再创建两个子集,一个用于点击显示联系方式,一个用于爬取号码
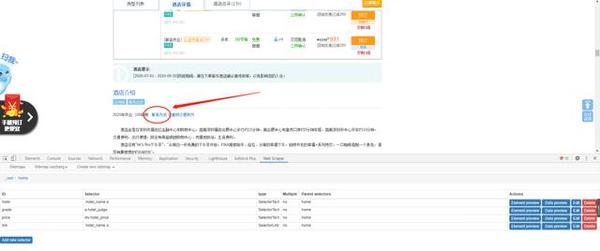
9,在有联系方式的页面摁F12》Web Scraper》xiecheng》home》点进去link里面,点Add new selector,填好Id,Type选择Element click,然后Selector和Click selector的Select都一起选择页面的联系方式后点击done selecting,(还可以点一下Data preview,测试下会不会自动显示号码出来)提交保存这个用于点开联系方式。
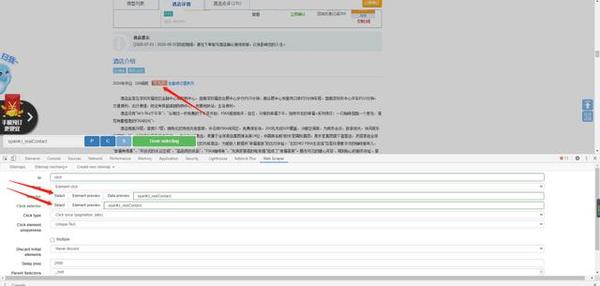
再点击一次点Add new selector,创建多一个用于爬取联系方式文本的子集,创建方法跟刚刚上面爬取标题时候的方式一样
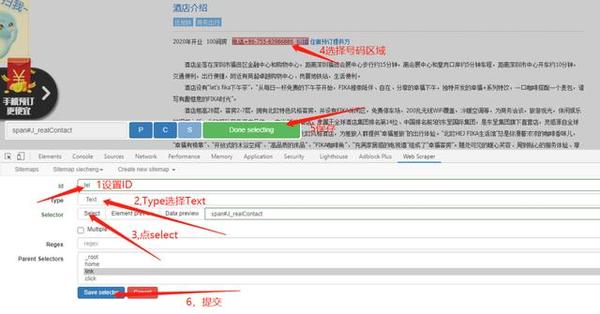
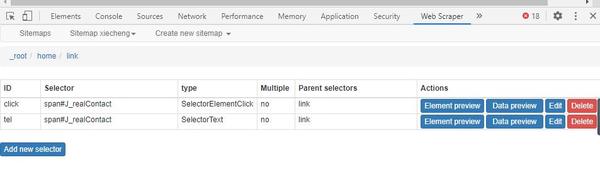
第四步,点Scrape进行开始爬取
在Sitemap xiecheng里面点Scrape,弹出的页面默认值都是2000可以不用去管它,
Request interval(ms):默认值2000ms,即每两次请求之间的间隔。
Page load delay(ms):默认值2000ms,等待页面的加载时长。
直接点start scraping,它会弹出一个窗口,不要关闭它和浏览器,我们就静静等待它自己爬取关掉结束就可以了
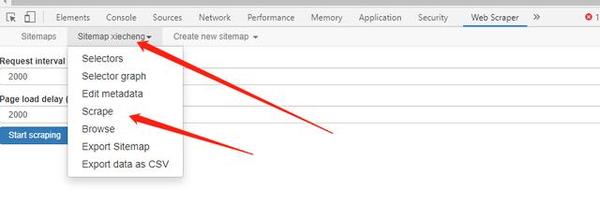
结束后它会跳出小窗口这个提醒
第五步,下载为电脑文件,用excel表格打开
在Sitemap xiecheng里面点Export data as CSV,然后点Download now!,这时候它就自己下载好在电脑里,直接点开就可以看到数据已经制作成表格,可以筛选和对比了
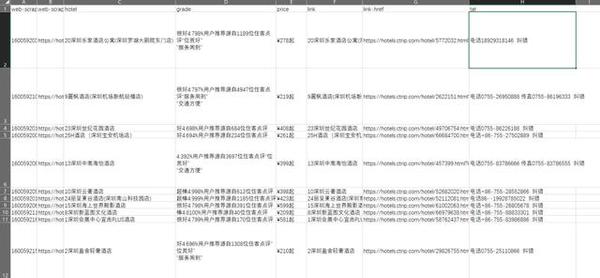
这也只是它一部分功能,还可以更多的爬取信息方法,非常的强大。阿木看完是各种目瞪口呆,赶紧尝试了一下,发现忙会一早上的东西,现在几分钟就可以自己搞定了,他好气啊,希望他能筛选到一个好酒店,国庆挤完人海能有个酒店好好休息吧
关注公众号【GitHub大宝藏】获取更多精彩

需要web scraper的教学视频或者有啥问题可以私我哟

 浙公网安备 33010602011771号
浙公网安备 33010602011771号